SQL Server關於AlwaysOn的理解-讀寫分離的誤區(一)
前言
很多人認為AlwaysOn在同步提交模式下資料是實時同步的,也就是說在主副本寫入資料後可以在輔助副本立即查詢到。因此期望實現一個徹底的讀寫分離策略,即所有的寫語句在主副本上,所有的唯讀語句分離到輔助副本上。這是一個認知誤區,本文通過原理和測試進行解釋。
實現原理
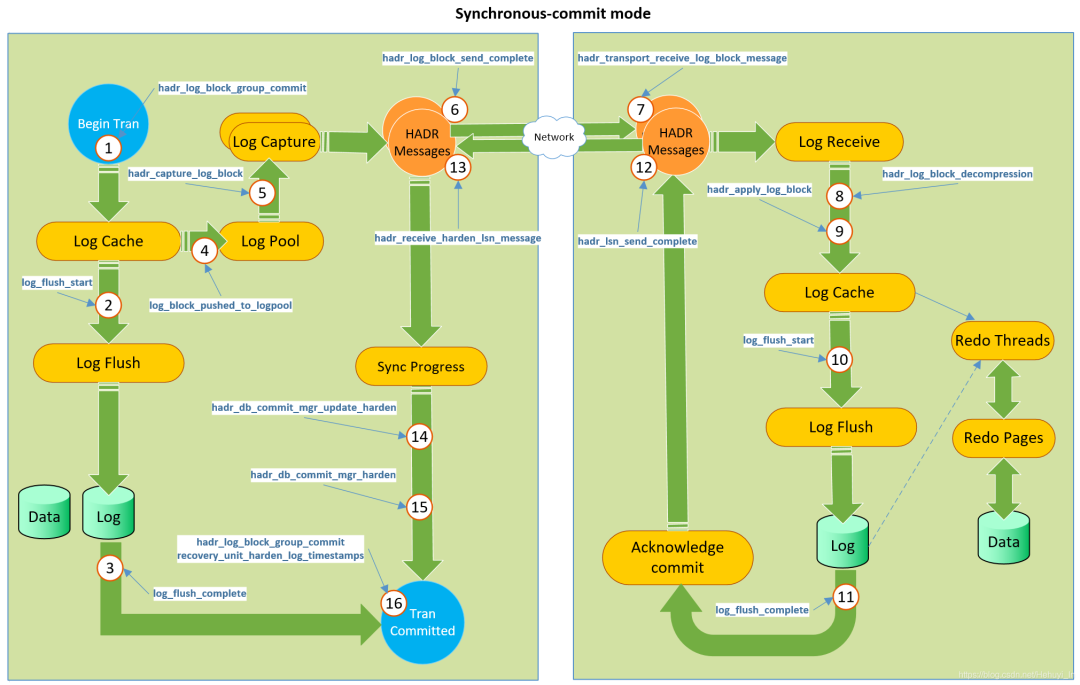
從下圖可以看到,在同步提交模式下,主副本產生的紀錄檔被同步並固化到輔助副本的紀錄檔檔案後,主副本的事務就會提交。輔助副本再通過非同步的REDO執行緒把紀錄檔轉換為資料,因此資料在輔助節點是有滯後的。
要強調的是,這種實現原理是為了對主副本上的寫入操作的效能影響最小化,並不會導致資料丟失。當主副本出現故障後,輔助副本切換成主副本時有一個資料庫恢復階段,用來把非同步REDO執行緒沒有處理完的紀錄檔轉換成資料,完成後資料和原主副本是一致的。因此不會丟失資料,只是稍微增加了一點故障轉移的時間。
測試
建立一個AlwaysOn可用性組,2個同步提交的副本,Node1為主副本,N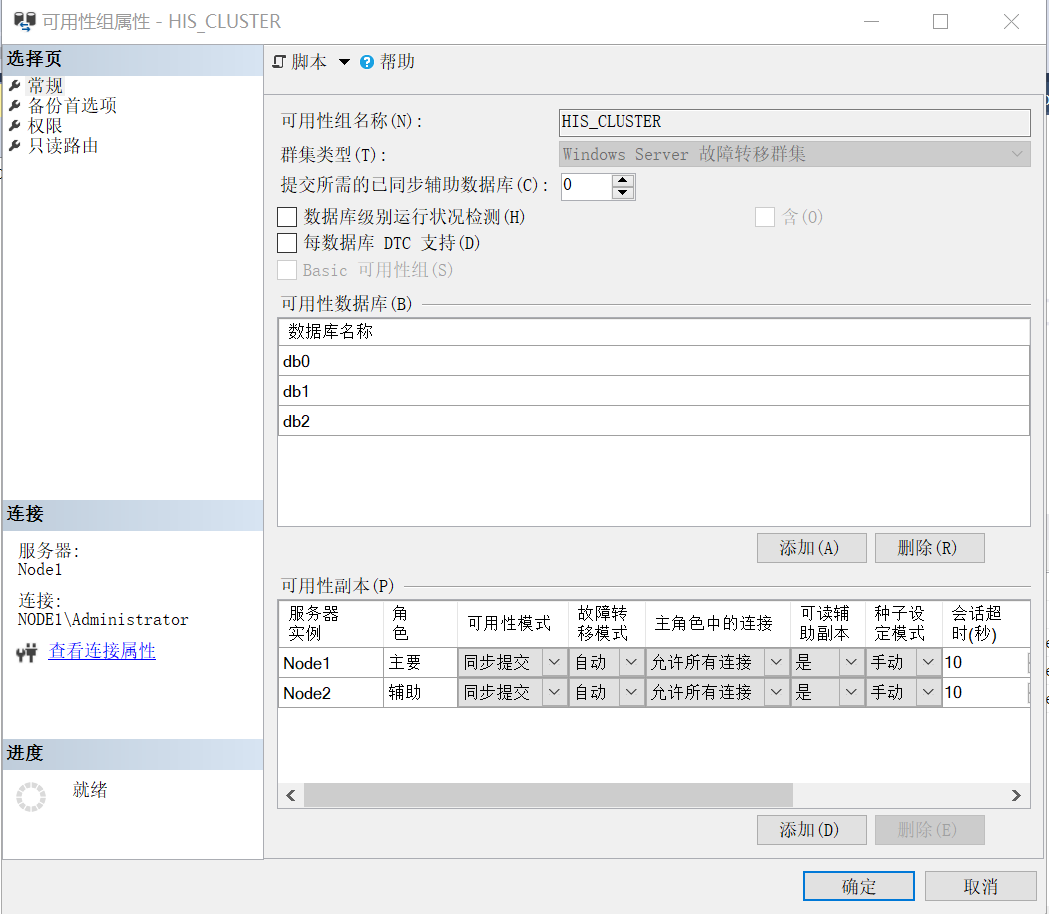
在資料庫db1中建立一張表。
1 SET ANSI_NULLS ON 2 GO 3 4 SET QUOTED_IDENTIFIER ON 5 GO 6 7 CREATE TABLE [dbo].[tbl_always_on_test]( 8 [id] [int] IDENTITY(1,1) NOT NULL, 9 [a] [nvarchar](50) NOT NULL, 10 CONSTRAINT [PK_tbl_always_on_test] PRIMARY KEY CLUSTERED 11 ( 12 [id] ASC 13 )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] 14 ) ON [PRIMARY] 15 GO
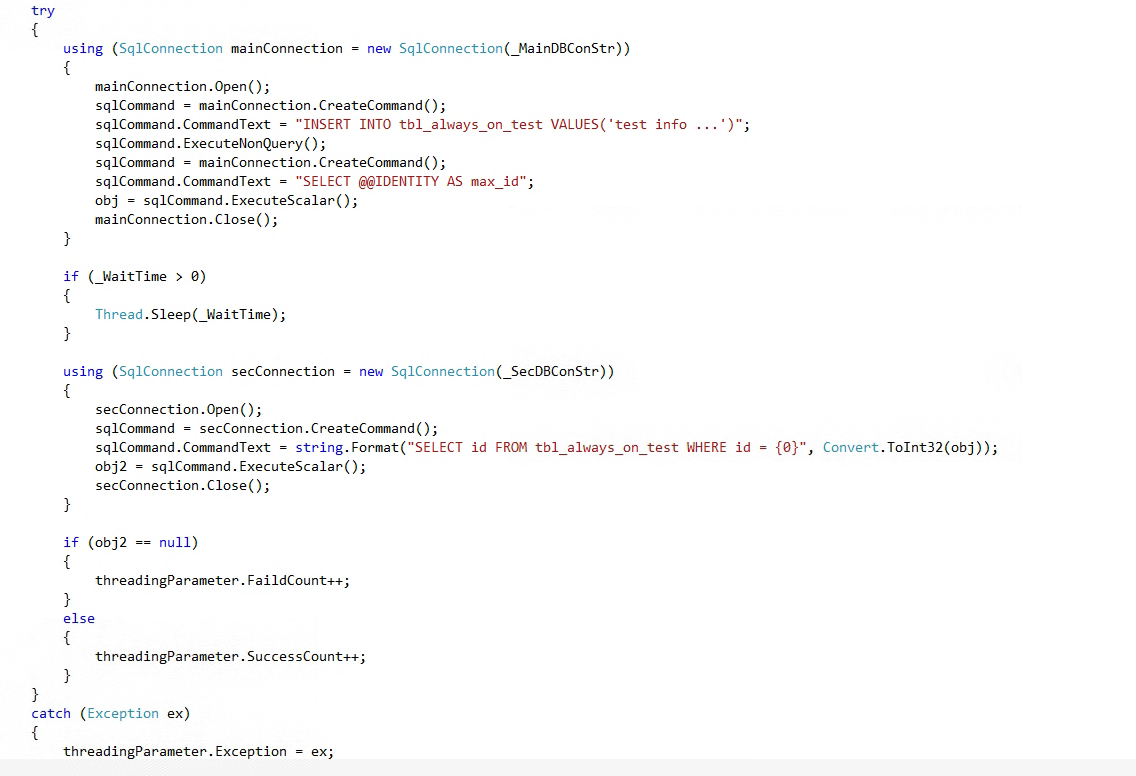
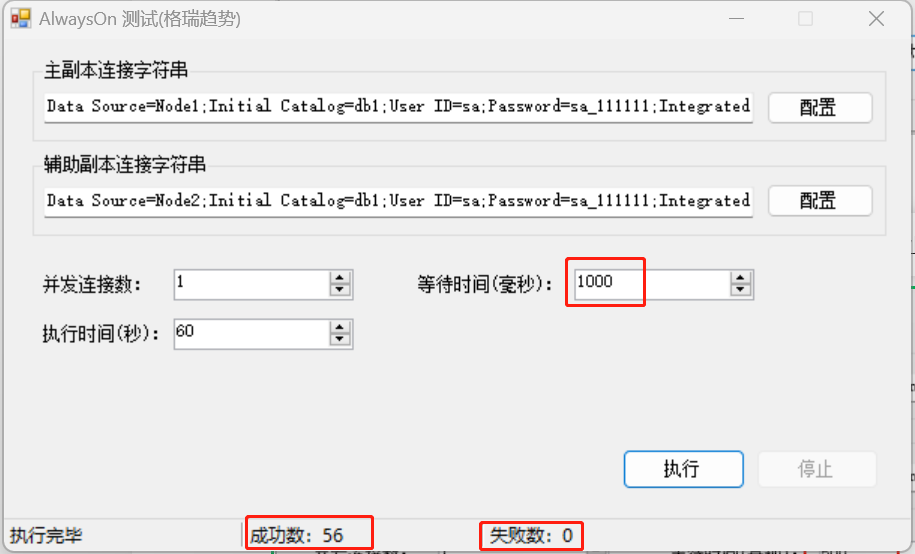
寫一個測試工具,首先建立到主副本資料庫的連線,插入一行資料並獲取新插入行的自增列的值,然後根據設定的等待時間進行執行緒等待,最後建立到輔助副本資料庫的連線,查詢新插入的這條資料是否已經存在,如存在成功數加1,不存在失敗數加1。
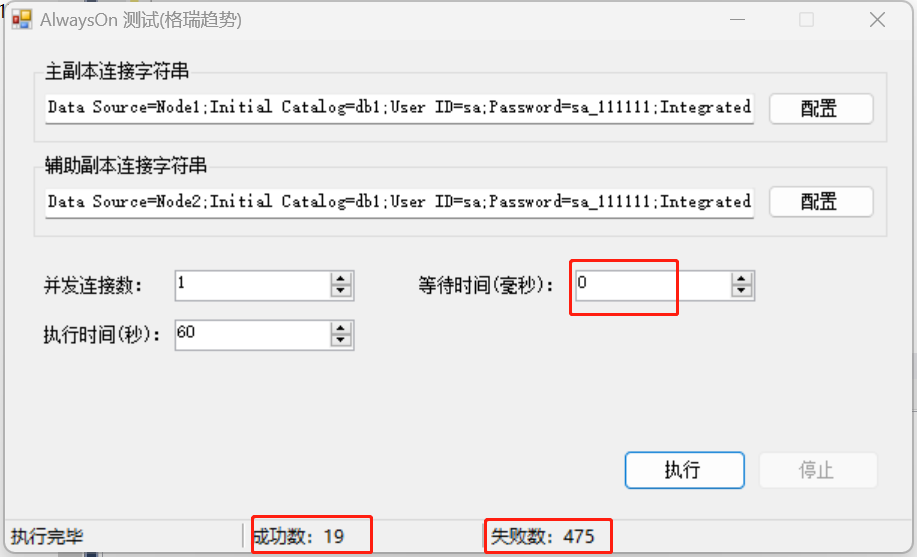
設定等待時間為0,也就是在主副本插入完資料後立即到輔助副本去查詢,可以看到成功的非常少,絕大多數都是查不到的。
把等待時間增加到500毫秒,還有一半失敗的。

直到增加到1000毫秒,才會全部成功。
總結
通過原理和測試,我們理解到資料在輔助副本是有滯後的,而且滯後時間是不確定的,和硬體環境、紀錄檔大小、並行數等都有關係。同一個查詢語句在主副本和輔助副本的查詢結果可能是不同的,導致對資料實時性非常敏感的業務邏輯出現問題。因此很多人所期望的徹底的讀寫分離策略(寫操作在主副本上,唯讀查詢全部分離到輔助副本上)是不能實現的。我們不能制定簡單粗暴的讀寫分離策略,只有對資料時效性不敏感的查詢才能被分離。
再說一下我認為的讀寫分離, 我更願意叫「報表分離」,在資料庫中也遵循「二八定律」,即數量上佔20%的SQL語句帶來80%的效能問題,例如效能消耗、鎖表導致阻塞等。這類語句大多數都是列表、統計、報表、資料抽取等查詢語句,並且對資料時效性是不敏感的。因此把這20%的查詢語句分離到輔助副本上, 即能從效能上分離走80%的壓力,又能解決執行期間導致的阻塞,而且改造應用程式的成本很小。
通過連結「https://learn.microsoft.com/zh-cn/previous-versions/sql/sql-server-2012/ff877884(v=sql.110)」瞭解更多關於AlwaysOn的資料。
北京格瑞趨勢科技有限公司是聚焦於資料服務的高新技術企業,成立於2008年,創始團隊及核心技術人員來自微軟和雅虎。微軟資料平臺金牌合作伙伴。通過產品+服務雙輪驅動的業務模式,15年間累計服務4000+客戶,覆蓋網際網路、市政、交通、電信、醫療、教育、電力、製造業等各個領域。
