vivo資料中心網路鏈路質量監測的探索實踐
作者:vivo 網際網路伺服器團隊- Wang Shimin
網路質量監測中心是一個用於資料中心網路延遲測量和分析的大型系統。通過部署在伺服器上的Agent發起5次ICMP Ping以獲取端到端之間的網路延遲和丟包率並推播到儲存與分析模組進行聚合和分析與儲存。控制器負責分發PingList並通過資料中心內部訊息通道將PingList下發至每臺伺服器上的Agent,而PingList就是每個Agent需要發起Ping的目標伺服器列表。
一、概述
資料中心的建設是一個從無到有從小到大的過程,在資料中心建設初期,由於量級很小,我們想要了解網路狀況是比較輕鬆的,在兩臺伺服器上獲取其網路延遲簡直輕而易舉,輸入Ping命令和IP地址便可以隨時獲取網路延遲。然而,當業務滾雪球式的增長,資料中心隨之擴容或新建,伺服器數量達千級、萬級、十萬級甚至更多時,想要隨時獲取機房各鏈路的網路延遲以定位網路故障原因就變得十分具有挑戰性。我們開始思考如何建立一個用於大規模資料中心網路延遲測量和分析的系統,以便於更高效、快捷的維護資料中心。
二、背景
經典的資料中心網路架構有三層,分為核心層(網路的高速交換主幹)、匯聚層(提供基於策略的連線)、接入層 (將工作站接入網路),在龐大的資料中心網路中,難免在某些時刻某些業務出現問題。那麼如何確定問題是否是網路問題?如何定位一個網路故障?如何提前預測網路故障,確保資料中心基礎網路的可用性(SLA)不受影響?由於分散式系統龐大、可延伸、依賴多的性質,許多故障顯示為「網路」問題,例如,某些元件故障,端到端對接時由於某一端CPU負載突然增加導致響應延遲,或者網路擁塞導致的排隊延遲,又或者封包丟失也會增加使用者感知的網路延遲。其中一部分問題其實並不是所謂的「網路」問題,然而要判斷這些問題是否是由網路故障引起的,或者定位網路故障的原因,是一個費時費力的過程。 為了應對這些挑戰和簡化網路運維繁複的工作,我們的網路質量監測中心就應運而生。
三、什麼是網路質量監測中心
網路質量監測中心是一個用於資料中心網路延遲測量和分析的大型系統。通過部署在伺服器上的Agent發起5次ICMP Ping以獲取端到端之間的網路延遲和丟包率並推播到儲存與分析模組進行聚合和分析與儲存。控制器負責分發PingList(需要相互執行Ping的IP列表)並通過資料中心內部訊息通道將PingList下發至每臺伺服器上的Agent,而PingList就是每個Agent需要發起Ping的目標伺服器列表。
3.1 Agent
Agent是整個專案的資料採集器,負責接收來自控制器下發的PingList,PingList中有該Agent需要發出Ping目標的IP地址,最後將探測資料上報儲存與分析模組。Agent要覆蓋所有機房的絕大多數物理機,才能保證探測資料彙總後的有效性和真實性,所以,在Agent對PingList中的目標IP進行Ping操作時,Agent所佔用的CPU資源不能超過5%,是Agent設計時要保證的核心要點。Agent由機房內部訊息通道統一分發部署、更新、啟動和停止。
3.2 控制器
控制器是整個網路質量監測中心的任務排程器,決定了伺服器應該如何相互探測,負責PingList生成演演算法與下發通知,以及網路拓撲的定時更新。
3.3 儲存與分析模組
儲存與分析模組負責收集Agent上報的ICMP Ping資料並儲存,同時負責資料的聚合與分析以及告警輸出,根據不同條件對資料進行各種維度的視覺化。
四、設計與實現
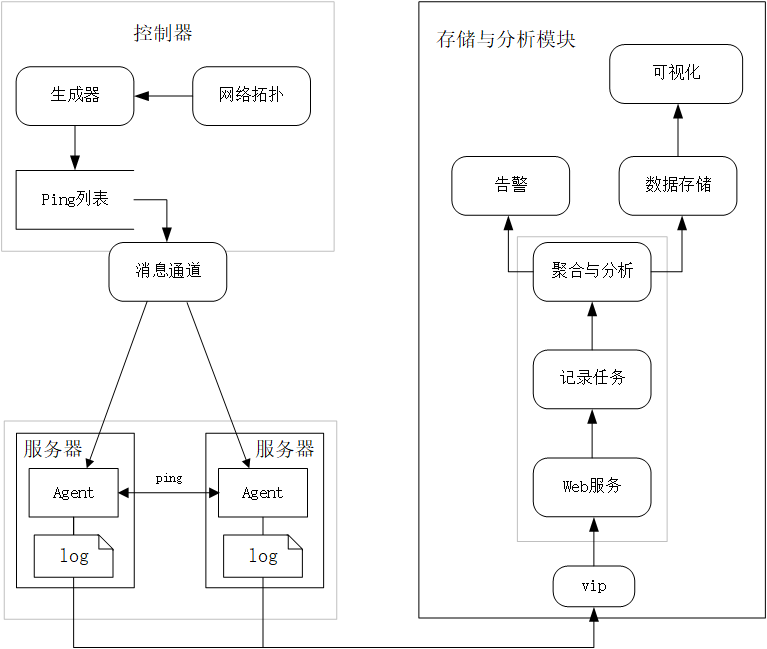
圖1 網路質量監測中心架構
4.1 PingList 生成原則
由於Agent執行在所有的伺服器上,而我們關注的維度其實是ToR(Top of Rack),所以伺服器維度完整圖既不是必要的也不是可行的,因為單臺伺服器需要探測n-1臺伺服器(n是參與探測的伺服器數量),這樣會產生非常龐大且冗餘度非常高的探測資料。在資料中心中,伺服器可以達到數百上千個。此外,伺服器維度完整圖不是必需的,因為數十臺伺服器通過相同的ToR交換機連線到其他ToR至伺服器。因此控制器為了避免過量開銷,調整了原n²-n的Ping策略。
-
在ToR內部,隨機選取兩臺伺服器互相Ping。
-
在ToR之間,則每個ToR選取兩臺伺服器Ping其它ToR的伺服器,保證每個ToR下至少有一臺機器發出或接收Ping。
-
在資料中心之間,則選擇不同的資料中心的幾個不同的核心ToR下的伺服器來相互發起Ping。
4.2 控制器的構成
控制器由Timer,Watcher,Producer,Consumer和Topology Keeper構成。
-
Timer是個定時器,負責在指定時間對Watcher發出更新網路拓撲的指令或更新PingList的指令;
-
Watcher接收到Timer的更新PingList指令後,立即查詢各資料中心的網路拓撲後設資料,分資料中心對Producer發出生成新PingList指令;
-
Producer接收到Watcher的網路拓撲資料後,根據網路拓撲中各層級的ToR給予不同的權重,根據此權重以隨機抽取的方式選取其下轄的伺服器,最終組成PingList並交由Consumer下發;
-
Consumer負責接收Producer生成的PingList並對接資料中心內部訊息通道,經由訊息通道將PingList下發至伺服器上的Agent;
-
Topology Keeper通過SNMP(Simple Network Management Protocol)自主探尋網路拓撲,為網路拓撲展示提供資料來源。
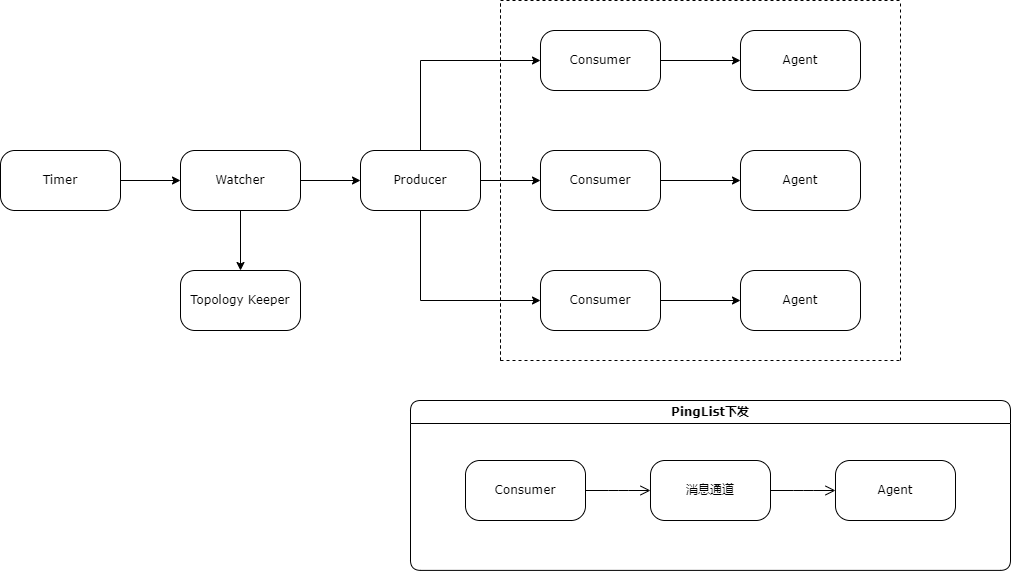
圖2 網路質量監測中心控制器
五、延遲與丟包資料分析
儲存與分析模組將Agent上報的所有Ping資料儲存,隨後根據10分鐘粒度、一小時粒度的時間範圍對資料進行匯聚與分析,根據分析結果,對異常鏈路進行持續跟蹤。
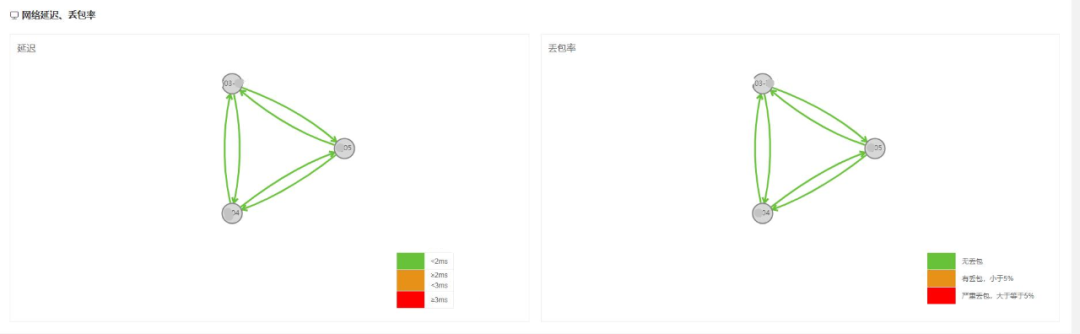
圖3 資料中心維度延遲與丟包率總覽
圖3顯示了多個資料中心之間的實時網路延遲以及丟包率的總覽,資料延遲為4分鐘。由於資料中心之間的相互探測是由核心交換機下轄伺服器發起的,在某些時刻如果資料中心之間的網路延遲陡增,則可以迅速的定位探測端與被探測端的鏈路,極大的縮小問題定位的範圍。

圖4 實時網路延遲矩陣圖
圖4反應了同機房不同Pod(規劃的一個網路區域)間的實時延遲分佈資訊,我們很快就能發現,其中一組ToR出現延遲問題,那麼很有可能雙向鏈路都會反應高延遲情況,同樣也可能在丟包率的矩陣中反應出來。圖中的每一個點都包含了一組ToR的資料,若以ToR為單位畫點陣圖,則會導致資料量過於龐大而無法使用。而實際使用中,完整的ToR粒度的矩陣圖也不是必須的,所以如何選擇匯聚維度成為一個問題。
在我們的設計中,只有伺服器會執行Ping操作,即伺服器是資料來源,ToR則可以看成一個虛擬節點。一個資料中心擁有數個Pod,如果矩陣圖以Pod維度聚合那麼顯然我們得不到想要的效果,一個Pod下轄制若干ToR,我們的矩陣圖中每個點都含有最新的延遲與掉包資料,若以ToR為單位,則矩陣圖所承載的資料量過於龐大而導致整個矩陣的邊長遠超頁面的邊界,影響視覺化的預期效果,所以矩陣圖既不能以Pod維度聚合,也不能以ToR作為單位,最後我們採取了折中方案,在Pod與ToR之間加了一層組級關係,以這層關係為維度進行矩陣圖的繪製,初步達到了專案設計目標。
如此一來,繪製矩陣圖便可達到預期效果,當發生網路故障時,檢視矩陣圖可以輔助快速定位出現問題的服務是否是由網路延遲導致的。
圖5是同機房當前延遲top趨勢圖,時間粒度是2分鐘,反應了當前機房中延遲最大的鏈路在過去的一段時間裡的網路延遲情況。
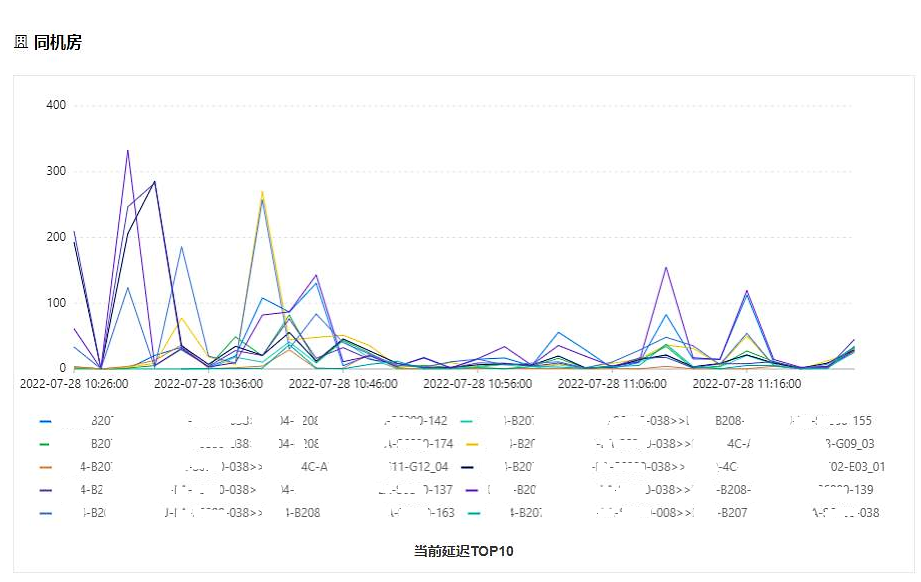
圖5 資料中心內當前延遲top10趨勢圖
六、面臨的問題
從專案上線開始,Agent的灰度持續進行,最初制定的目標是灰度覆蓋每個機房的所有物理機,但在實際執行過程中,總會遇到各種各樣的問題,比如負載均衡叢集的流程承載節點所在的伺服器由於常年處於滿負載狀態,Agent執行的Ping延遲總是非常高,探測到的資料並無實際意義。又如巨量資料和部分隔離區的伺服器並不適合Agent的部署與執行。此時已經限制了網路質量監測中心資料的覆蓋範圍,如何優化選擇伺服器演演算法讓探測的Ping資料更具有代表性和真實性是目前面臨的第一個挑戰。
Agent將延遲資料通過標準Web API上報給儲存與分析模組,因為Agent持續線上的性質,這種方式首先面臨的是持續高並行以及資料消費速度瓶頸,隨著資料中心規模持續擴大,瓶頸會愈發明顯。
控制器和儲存與分析模組工作在應用層,這就意味著若網路質量監測中心的元件依賴出現問題,那麼其所有工作都將癱瘓。
網路質量監測中心儘管目前能收集到ICMP Ping資料,但無法準確定位網路故障鏈路,在資料視覺化方面還需要增加視覺化方向與維度以充分使用這些資料。
七、後續優化
網路質量監測中心優化的空間還很大,後續將在技術架構以及功能場景方面著重下功夫。
在功能支撐方面,可以豐富探測場景和優化資料來源,目前僅支援ICMP Ping場景,後續的優化中,需要強化Agent以支撐UDP,TCP等不同場景。完善Agent主動上報和健康檢查機制,及時更新PingList,保證資料來源的實時性與可靠性。生成PingList的演演算法目前以隨機抽取為主,缺乏針對性,後續將對伺服器和網路裝置後設資料進行維護以區分高優先順序和低優先順序ToR,為高優先順序和低優先順序分類生成PingList。完善監控指標及其閾值設定,差異化設定告警規則,多模式多功能多維度的圖表處理等。
在技術架構方面,由於接收資料的分析伺服器端並行壓力很大,為應對未來資料多樣性帶來的更高的並行量,需要優化服務部署方式,調整Agent上報資料的處理機制,以資料中心為單位建立訊息管道接收Agent的上報資料增加穩定性。為了應對資料快速增長,將對當前技術架構進行整體升級,提升服務效能和吞吐量。
網路鏈路質量監測求索之路漫漫,希望通過不斷的打磨與學習完善我們的專案,力求網路質量監測中心在網路故障自主發現、故障預警以及故障定位的征途上不斷的成長壯大,最終能夠持續提高網路質量。