線上問診 Python、FastAPI、Neo4j — 建立症狀節點
2023-09-14 12:00:24
電子病歷中,患者主訴對應的相關檢查,得出的診斷以及最後的用藥情況。症狀一般可以從主訴中提取。
症狀資料
symptom_data.csv
CSV 中,沒有直接一行一個症狀,主要想後面將 症狀 => 疾病 做關聯,最後會在一個 Excel 中表達
所以每行實際對應一個症病,但在建立節點時,會轉化成 N個節點(每個 | 號一個節點)
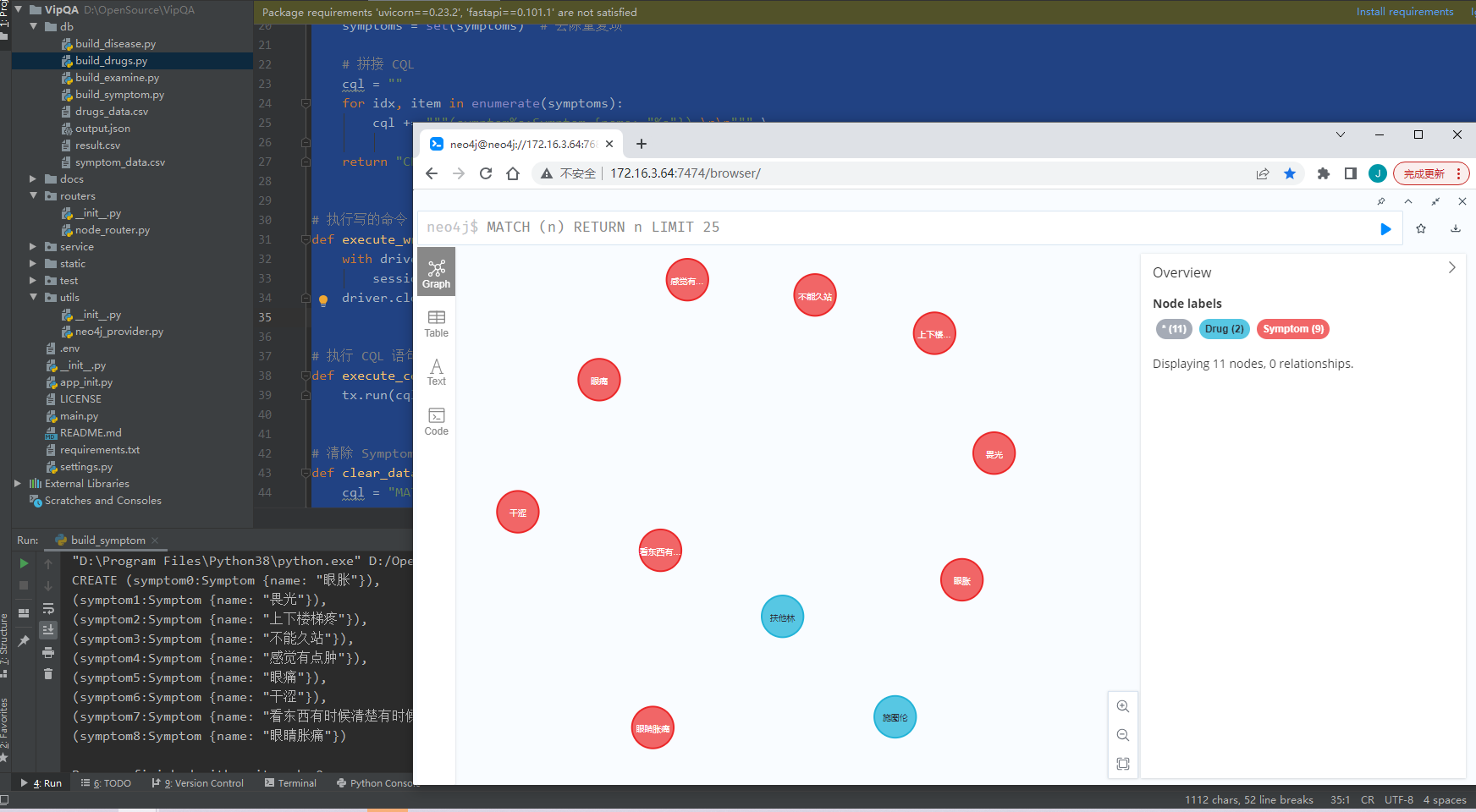
症狀
"上下樓梯疼,不能久站,感覺有點腫"
"眼睛脹痛,乾澀,畏光,眼脹,眼痛,看東西有時候清楚有時候不清楚"
建立節點
參考 建立藥品 節點。
import logging
import csv
from utils.neo4j_provider import driver
import pandas as pd
logging.root.setLevel(logging.INFO)
# 並生成 CQL
def generate_cql() -> str:
# cql = """
# CREATE (symptom1:Symptom {name: "膝蓋疼"}),
# (symptom2:Symptom {name: "眼睛酸脹"})
# """
df = pd.read_csv('symptom_data.csv')
symptoms = []
for each in df['症狀']:
symptoms.extend(each.split(',')) # 按,號分割成陣列,並將每行資料到一個佇列裡面
symptoms = set(symptoms) # 去除重複項
# 拼接 CQL
cql = ""
for idx, item in enumerate(symptoms):
cql += """(symptom%s:Symptom {name: "%s"}),\r\n""" \
% (idx, item)
return "CREATE %s" % (cql.rstrip(",\r\n")) # 刪除最後一個節點的 逗號
# 執行寫的命令
def execute_write(cql):
with driver.session() as session:
session.execute_write(execute_cql, cql)
driver.close()
# 執行 CQL 語句
def execute_cql(tx, cql):
tx.run(cql)
# 清除 Symptom 標籤資料
def clear_data():
cql = "MATCH (n:Symptom) DETACH DELETE n"
execute_write(cql)
if __name__ == "__main__":
clear_data()
cql = generate_cql()
print(cql)
execute_write(cql)
附學習
陣列 append、extend 區別
import pandas as pd
df = pd.read_csv('../db/symptom_data.csv')
symptoms_extend = []
symptoms_append = []
for idx, each in enumerate(df['症狀']):
sp = each.split(',')
symptoms_extend.extend(sp) # 在末尾追加序列的值 結果為 => [X1,X2,X3,X4]
symptoms_append.append(sp) # 在末尾追加對接,附加在裡面 結果為 => [[X1,X2],[X3,X4]]
print("%s sp => %s" % (idx, sp))
print("%s extend => %s" % (idx, symptoms_extend))
print("%s append => %s" % (idx, symptoms_append))
print('--' * 20)
print("extend => %s" % (symptoms_extend))
print("append => %s" % (symptoms_append))

本文來自部落格園,作者:VipSoft 轉載請註明原文連結:https://www.cnblogs.com/vipsoft/p/17699002.html