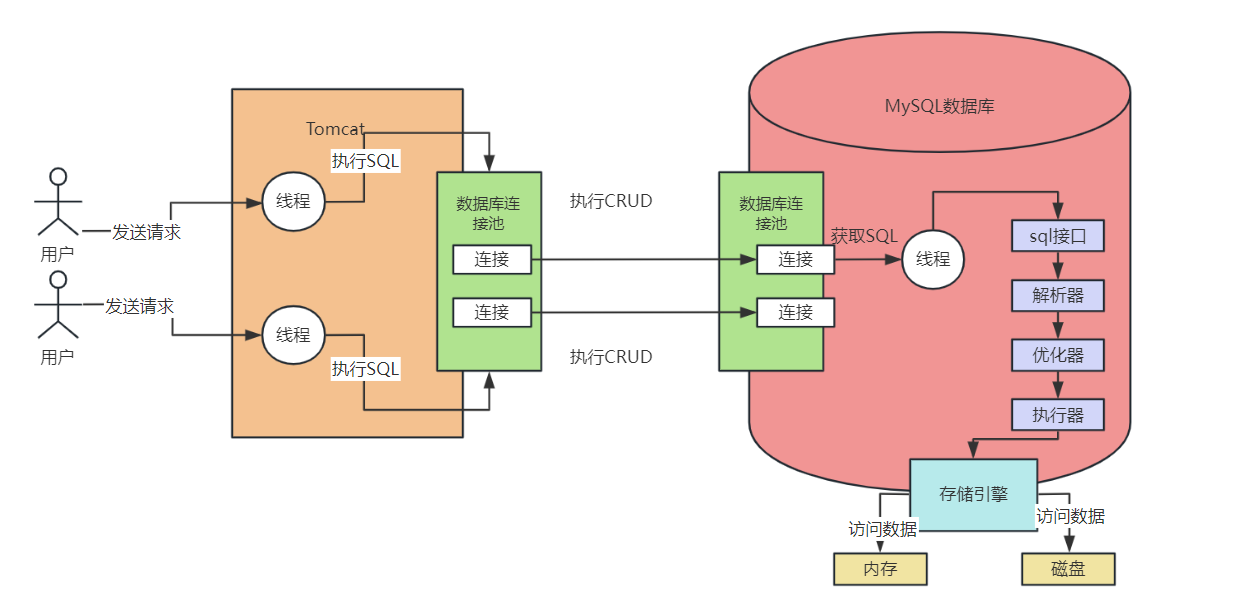
MySQL體系架構
1. 背景
剛入行時,大部分Java工程師對MySQL停留在一個黑盒的認識,包括我自己。最近一段時間,這幾年通過專案實踐與不斷反思,對MySQL的新認知提升到一個新層次,供大家分享。
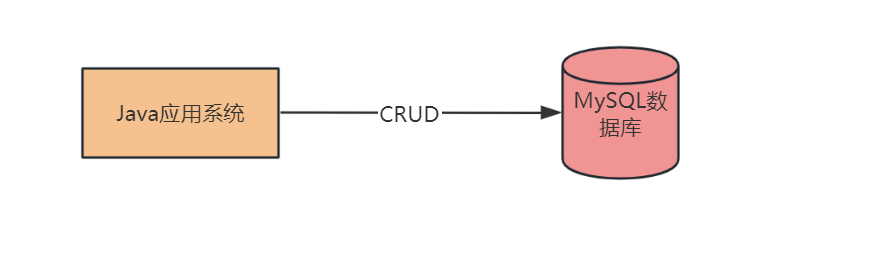
下圖是初始階段的認識,就是對資料庫建庫、建表、建索引,然後執行增刪改查操作。
2. 資料庫驅動
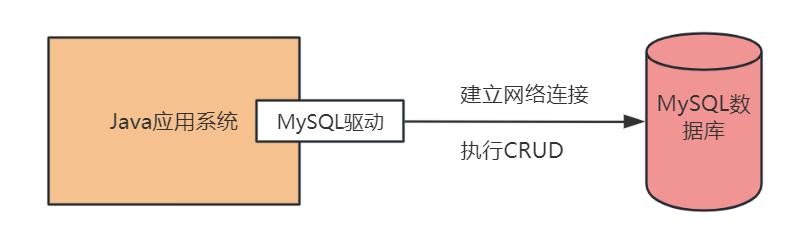
大家都知道,我們如果要在Java系統中去存取一個MySQL資料庫,必須得在系統的依賴中加入一個MySQL驅動,有了這個MySQL驅動,才能跟MySQL資料庫建立連線,然後執行各種SQL語句。下面這段maven設定中就引入了一個MySQL驅動。這裡的mysql-connector-java就是面向Java語言的MySQL驅動。
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>
如果我們要存取資料庫,必須得跟資料庫建立一個網路連線,那麼這個連線由誰來建立呢?其實答案就是這個MySQL驅動,他會在底層跟資料庫建立網路連線,有網路連線,接著才能去傳送請求給資料庫伺服器!我們看下圖。
3. 資料庫連線池
一個Java系統難道只會跟資料庫建立一個連線嗎?這個肯定是不行的,假設我們用Java開發了一個Web系統,是部署在Tomcat中的,那麼Tomcat本身肯定
是有多個執行緒來並行的處理同時接收到的多個請求的,我們看下圖
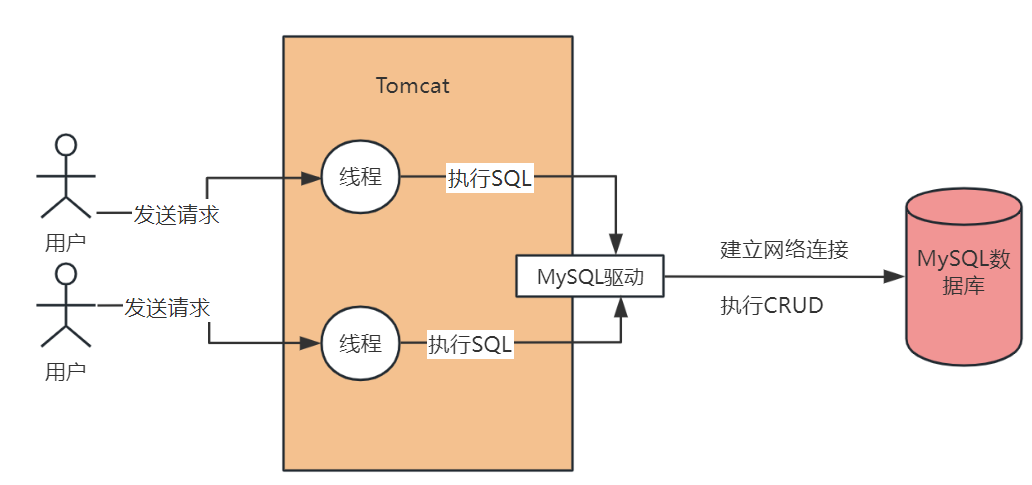
這個時候,如果Tomcat中的多個執行緒並行處理多個請求的時候,都要去搶奪一個連線去存取資料庫的話,那效率肯定是很低的,那麼如果Tomcat中的每個執行緒在每次存取資料庫的時候,都基於MySQL驅動去建立一個資料庫連線,然後執行SQL語句,再銷燬這個資料庫連線,這是否可行呢?因為每次建立一個資料庫連線都很耗時,好不容易建立好了連線,執行完了SQL語句,你還把資料庫連線給銷燬了,下一次再重新建立資料庫連線,那肯定是效率很低下的!
所以一般我們必須要使用一個資料庫連線池,也就是說在一個池子裡維持多個資料庫連線,讓多個執行緒使用裡面的不同的資料庫連線去執行SQL語句,然後執行完SQL語句之後,不要銷燬這個資料庫連線,而是把連線放回池子裡,後續還可以繼續使用。基於這樣的一個資料庫連線池的機制,就可以解決多個執行緒並行的使用多個資料庫連線去執行SQL語句的問題,而且還避免了資料庫連線使用完之後就銷燬的問題,我們看下圖的說明。
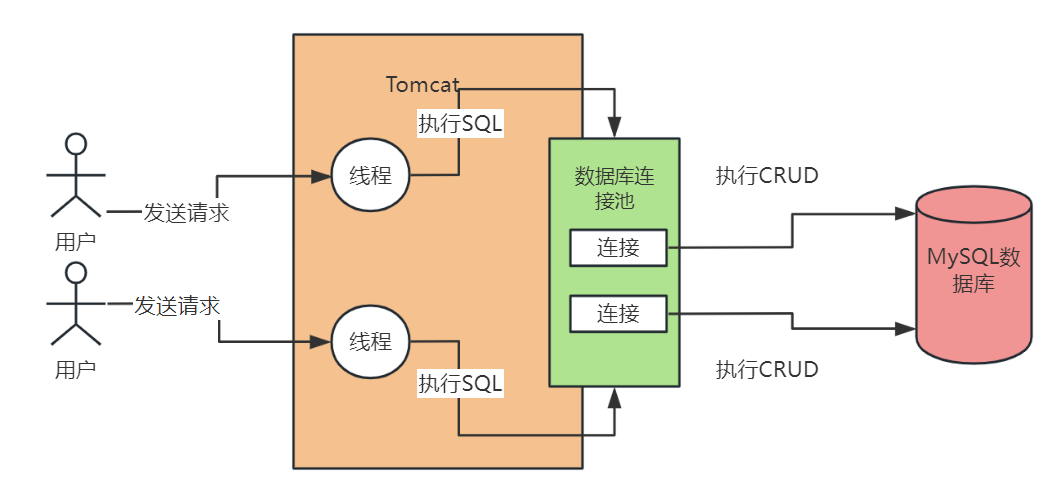
常見的資料庫連線池有DBCP,C3P0,Druid。其實不光是Java系統,如果你是一個Python、Ruby、.NET、PHP的程式設計師,這個系統與資料庫的互動本質都是一樣的,都是基於資料庫連線池去與資料庫進行互動。
4. MySQL資料庫的連線池
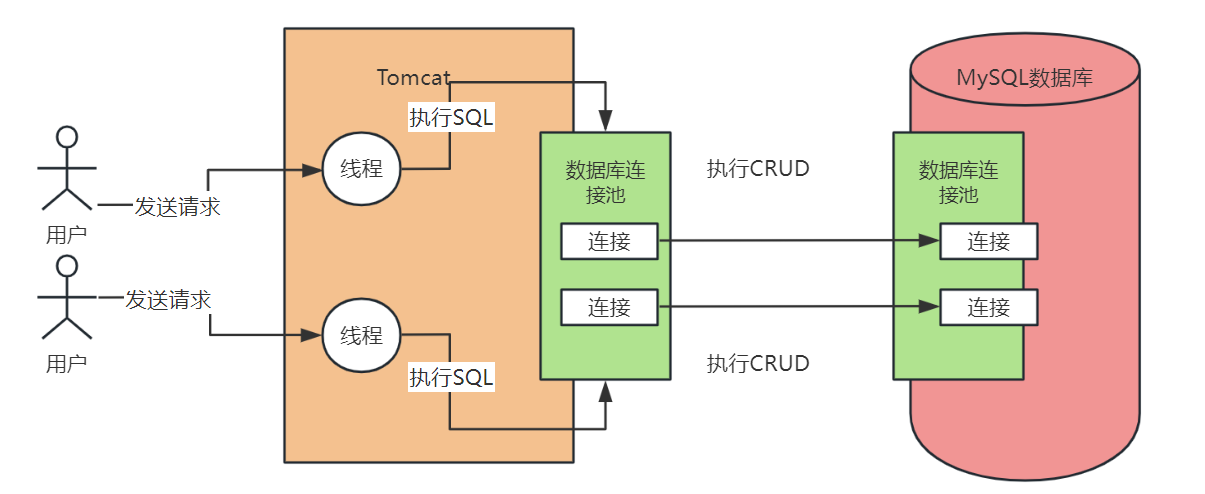
現在我們已經知道,我們任何一個系統都會有一個資料庫連線池去存取資料庫,也就是說這個系統會有多個資料庫連線,供多執行緒並行的使用。同時我們可能會有多個系統同時去存取一個資料庫,這都是有可能的。
所以當我們把目光轉移到MySQL的時候,我們要來思考一個問題,那就是肯定會有很多系統要與MySQL資料庫建立很多個連線,那麼MySQL也必然要維護與系統之間的多個連線,所以MySQL架構體系中的第一個環節,就是連線池。
我們看下面的圖,實際上MySQL中的連線池就是維護了與系統之間的多個資料庫連線。除此之外,你的系統每次跟MySQL建立連線的時候,還會根據你傳遞過來的賬號和密碼,進行賬號密碼的驗證,庫表許可權的驗證。
6. 資料庫執行緒
現在假設我們的資料庫伺服器的連線池中的某個連線接收到了網路請求,假設就是一條SQL語句,那麼大家先思考一個問題,誰負責從這個連線中去監聽網路請求?誰負責從網路連線裡把請求資料讀取出來?網路連線必須得分配給一個執行緒去進行處理,由一個執行緒來監聽請求以及讀取請求資料,比如從網路連線中讀取和解析出來一條我們的系統傳送過去的SQL語句。
7. SQL介面
接著我們來思考一下,當MySQL內部的工作執行緒從一個網路連線中讀取出來一個SQL語句之後,此時會如何來執行這個SQL語句呢?
其實SQL是一項偉大的發明,他發明了簡單易用的資料讀寫的語法和模型,哪怕是個產品經理,或者是運營專員,甚至是銷售員,即使他不會技術,他也能輕鬆學會使用SQL語句,因此MySQL的工作執行緒接收到SQL語句之後,就會轉交給SQL介面去執行。
8. 查詢解析器
接著下一個問題來了,SQL介面怎麼執行SQL語句呢?你直接把SQL語句交給MySQL,他能看懂和理解這些SQL語句嗎?比如我們來舉一個例子,現在我們有這麼一個SQL語句:select id,name,age from users where id=1這個SQL語句,我們用人腦是直接就可以處理一下,只要懂SQL語法的人,立馬大家就知道他是什麼意思,但是MySQL自己本身也是一個系統,是一個資料庫管理系統,他沒法直接理解這些SQL語句!所以此時有一個關鍵的元件要出場了,那就是查詢解析器。所謂的SQL解析,就是按照既定的SQL語法,對我們按照SQL語法規則編寫的SQL語句進行解析,然後理解這個SQL語句要幹什麼事情
9. 查詢優化器
當我們通過解析器理解了SQL語句要幹什麼之後,接著會找查詢優化器(Optimizer)來選擇一個最優的查詢路徑。所以查詢優化器大概就是幹這個的,他會針對你編寫的幾十行、幾百行甚至上千行的複雜SQL語句生成查詢路徑樹,然後從裡面選擇一條最優的查詢路徑出來。相當於他會告訴你,你應該按照一個什麼樣的步驟和順序,去執行哪些操作,然後一步一步的把SQL語句就給完成了。
10. 執行器
執行器會根據我們的優化器生成的一套執行計劃,然後不停的呼叫儲存引擎的各種介面去完成SQL語句的執行計劃,大致就是不停的更新或者提取一些資料出來。
11. 儲存引擎
最後一步,就是把查詢優化器選擇的最優查詢路徑,也就是你到底應該按照一個什麼樣的順序和步驟去執行這個SQL語句的計劃,把這個計劃交給底層的儲存引擎去真正的執行。這個儲存引擎是MySQL的架構設計中很有特色的一個環節。
12. 邏輯架構
現在把上述元件綜合起來看得到如下架構與流程圖。