分散式事務模型與常見解決方案
1. 背景
首先丟擲一個問題,如果在一臺機器上,資料庫是如何解決事務問題的?很容易想到,資料庫的ACID四個特性來保證的,原子性、一致性、隔離性和永續性。
- 原子性(Atomicity):一個事務內的所有操作看成一個原子操作,要麼全部執行,要麼都不執行。
- 一致性(Consistency): 指在事務開始之前和事務結束以後,資料滿足完整性約束,比如A、B兩人各有一千元,無論怎麼轉賬,兩人最終餘額加起來的總額保持2000不變。
- 隔離性(Isolation):指多個事務並行執行,互不干擾,也不影響最終結果。
- 永續性(Durability):指的是一個事務完成了之後資料就被永遠儲存下來。
拿mysql為例,資料先寫紀錄檔檔案,後寫資料檔案,如果寫紀錄檔檔案成功,並提交,發現資料檔案沒有,就做redo log,隨後做redo操作讓資料刷盤;如果紀錄檔檔案沒提交,需要寫undo log,用於回滾,AD特性是紀錄檔檔案保證的,CI特性是鎖保證的。
而在分散式系統中,事務是由多個系統對應的多個資料庫組成,涉及跨系統與跨庫操作,本地資料庫事務無能為力,需要引入分散式事務來保持資料的一致性。
下面給出本篇要討論的分散式事務的概覽,會重點分析幾種常見的實現方案與原理。

2. 二階段模型
引入原因
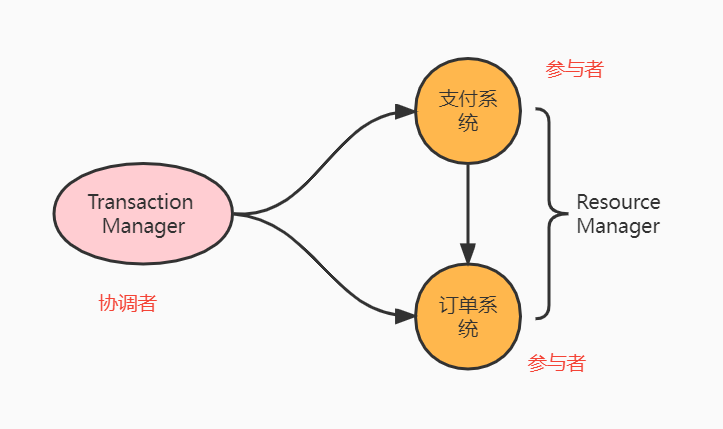
兩階段也叫做2pc,在分散式系統中,每個系統節點能感知自己的服務成功與失敗,但是無法感知其他節點的服務是否成功,就需要引入一個協調者來掌控所有節點的操作結果,這些節點叫做參與者,協調者控制所有節點的邏輯滿足ACID特性。
舉個例子來說,電商場景中,支付系統支付完成後,呼叫訂單系統更新訂單狀態。事務管理器Transaction Manager簡稱TM,充當協調者角色,Resource Manager簡稱RS,充當參與者角色。
流程
第一階段:預提交階段
- 預提交請求:協調者會詢問所有的參與者結點,是否可以執行提交操作;
- 鎖定資源:各個參與者開始事務執行的準備工作,如為資源上鎖,預留資源,寫undo/redo log……
- 返回響應:參與者響應協調者,如果事務的準備工作成功,返回yes,否則返回no。
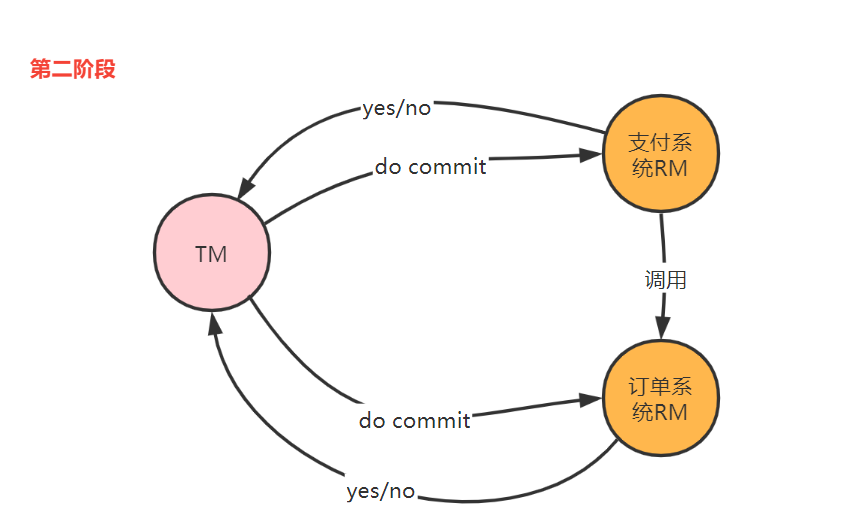
第二階段:執行事務提交
- 正式提交請求:當協調者收到的所有節點都返回yes時,協調者向所有參與者節點傳送提交請求;
- 節點事務提交:參與者正式完成提交操作,並釋放整個事務期間佔用的資源;
- 返回響應:參與者向協調者返回事務完成結果;
- 事務完成:協調者收到所有節點返回yes後,完成事務。
以上是兩階段的正常流程,如果參與者在第一階段返回no,或者TM在第一階段詢問請求超時,無法獲得響應結果,事務就會中斷事務,並向所有參與者節點發起回滾請求,參與者節點利用之前寫的undo紀錄檔進行回滾,並釋放所佔資源;TM收到所有回滾完成結果後,取消事務。

二階段思想採用的是先投票(vote),後執行(do commit),典型的例子就是西式教堂裡的結婚場景,牧師詢問新郎新娘,你是否願意.....,當各自回答願意後(鎖定一生資源),牧師會宣佈:宣佈你們正式成為夫妻,......,正式結婚(事務提交)。
二階段的問題
- 同步阻塞鎖資源:二階段是一種儘量保證強一致性的分散式事務,同步阻塞導致長時間資源鎖定,效能低。
- 超時:如果第一階段中,RM沒有收到詢問請求,導致請求超時,或是TM沒有收到響應,導致響應超時;導致此場景的原因要麼TM故障,要麼節點故障導致。
- 資料不一致:如果TM單點故障,在第一階段沒問題,在第二階段,有些節點提交完了,有些還沒提交故障,導致資料不一致。
seata實現
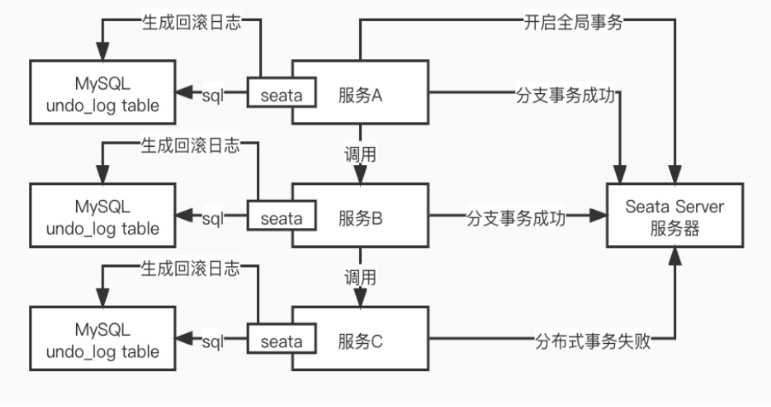
seata阿里開源的分散式事務,預設方式實現兩階段提交,流程如下:
- 服務A向seata server註冊全域性事務id,開啟全域性事務,管理分支事務,同時將正逆操作繫結在一個本地事務裡,undo_log表存放逆向運算元據;
- 服務B與C跟A一樣,執行自己的分支事務,分支事務成功後提交,失敗後回滾,並通知Seata Server,
- 全部分支成功後,全域性事務提交,事務執行成功,如果有一個分支事務執行失敗,Seata Server通知已成功的分支事務執行逆向操作回滾
mysql實現
mysql的redo log就是兩階段提交的典型例子,因為binlog屬於邏輯紀錄檔,redo log屬於物理紀錄檔,redo log紀錄檔保證修改的資料不丟失,可以基於紀錄檔恢復,而binlog記錄了做了哪些sql操作,兩個紀錄檔同時保證資料一致性。
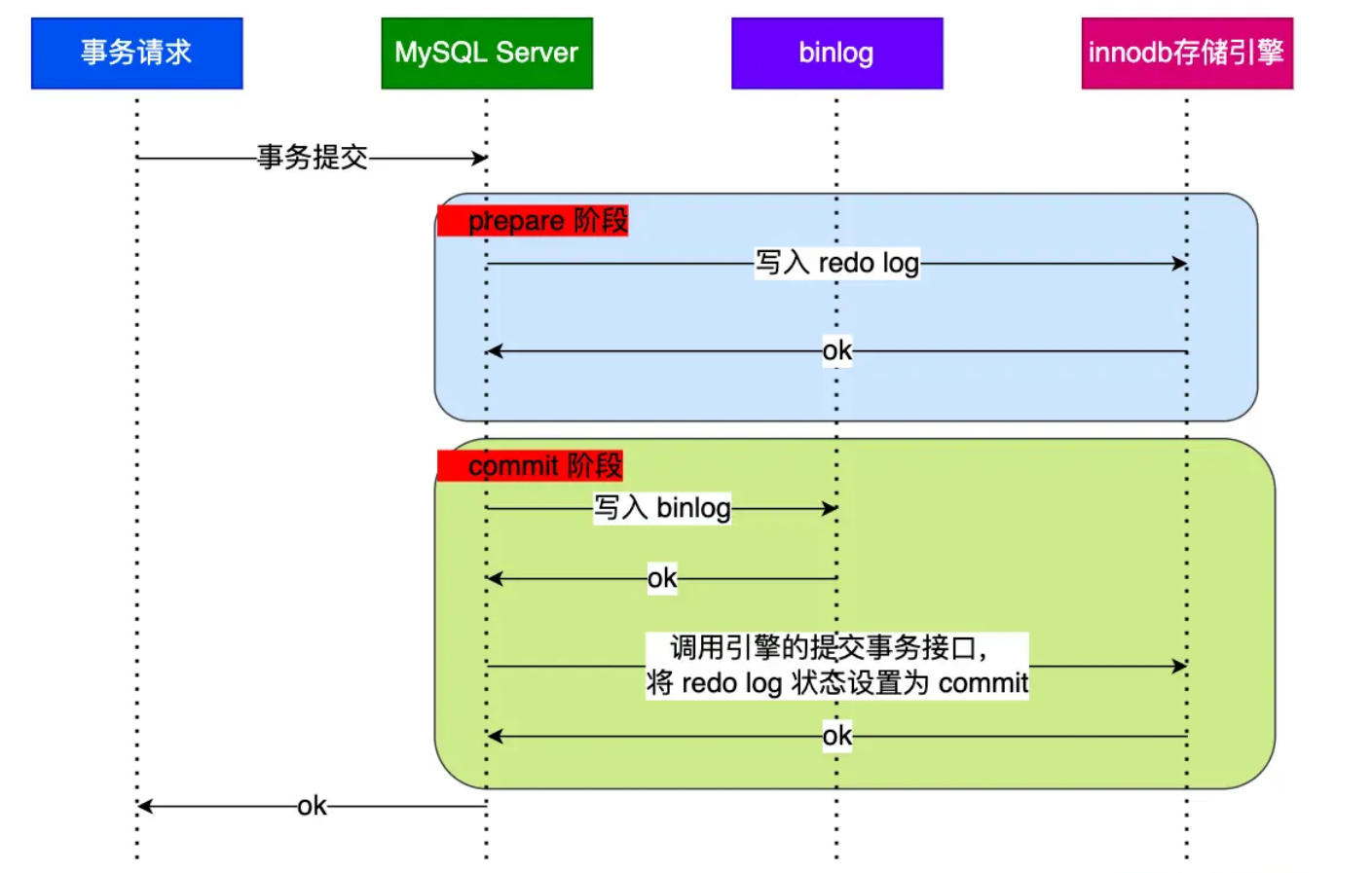
從圖中可看出,事務的提交過程有兩個階段,就是將 redo log 的寫入拆成了兩個步驟:prepare 和 commit,中間再穿插寫入binlog,具體如下:
prepare 階段:將 XID(內部 XA 事務的 ID) 寫入到 redo log,同時將 redo log 對應的事務狀態設定為 prepare,然後將 redo log 持久化到磁碟;
commit 階段:把 XID 寫入到 binlog,然後將 binlog 持久化到磁碟,接著呼叫引擎的提交事務介面,將 redo log 狀態設定為 commit,此時該狀態並不需要持久化到磁碟,只需要 write 到檔案系統的 page cache 中就夠了,因為只要 binlog 寫磁碟成功,就算 redo log 的狀態還是 prepare 也沒有關係,一樣會被認為事務已經執行成功。
通過這種兩階段提交的方案,就能夠確保redo-log、bin-log兩者的紀錄檔資料是相同的。
3. 三階段模型
為了降低二階段問題發生的概率,引入了三階段模型,也叫3PC。三階段在二階段之前加入了詢問環節,詢問不鎖定資源。3PC 包含了三個階段,分別是準備階段、預提交階段和提交階段,對應的英文就是:CanCommit、PreCommit 和 DoCommit。
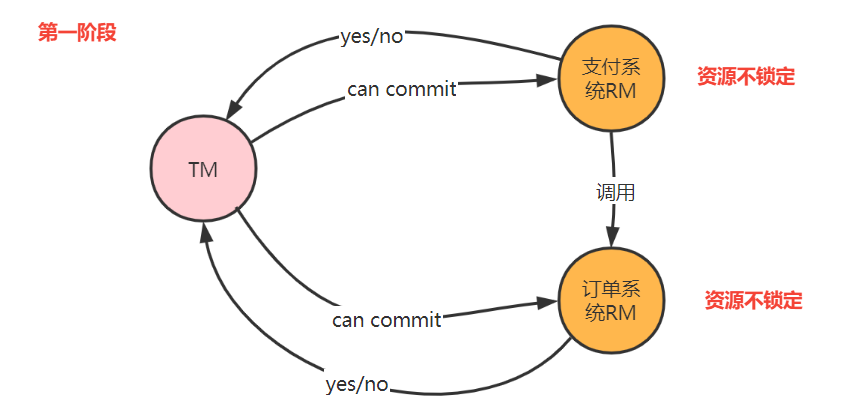
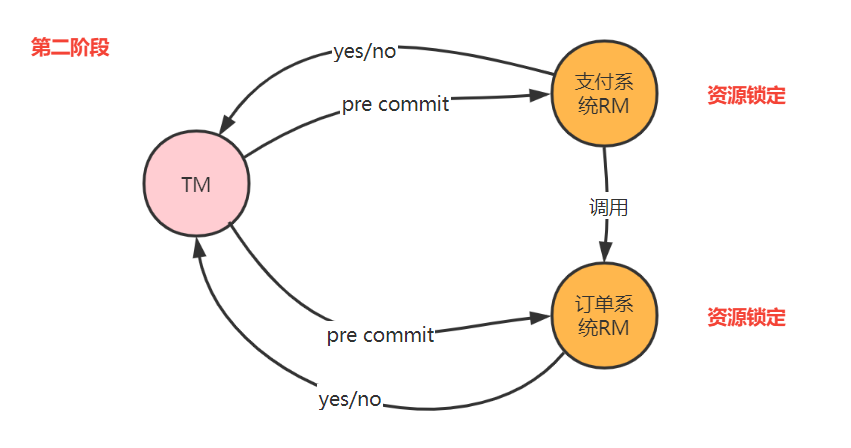
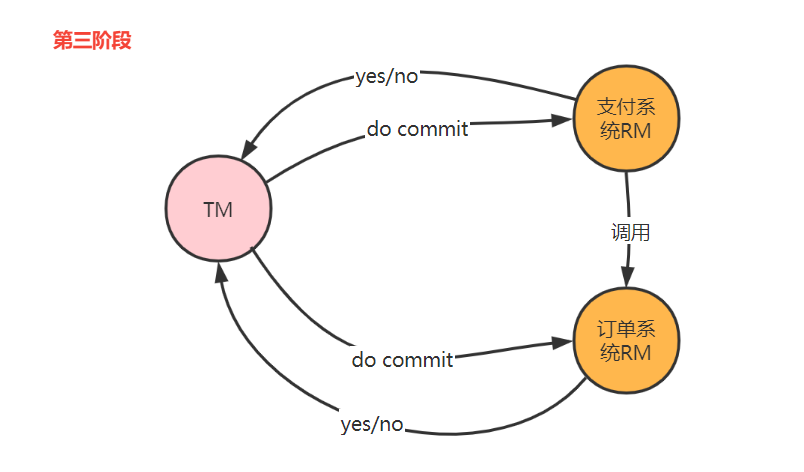
三階段的改善
- 增加了詢問環節,減少資源鎖定的時間。
- 引入了超時機制,減少資源鎖定概率。當TM未收到響應,給RM發中斷事務命令;當RM在三階段沒收到do commit請求,RM自動提交。
- 通過超時對應的處理機制,增加了資料一致性的概率。
4. 基於訊息佇列、定時任務與本地事件表的方案
在分散式系統中,資料的狀態在多個系統中流轉,通過訊息佇列、定時任務與本地事件表可以有效的處理分散式事務的資料一致性。假設有如下場景,有支付系統與訂單系統兩個子系統,具體流程如下:

step1: 支付系統通過第三方回撥完成本地支付流水狀態更新,同時在事件表中新增一條記錄;
step2: 定時任務掃描事件表裡的新增記錄,將事件表裡的支付流水狀態更新為已傳送,然後傳送一條訊息到訊息中介軟體,如果傳送失敗,本地事務可以回滾;
step3: 訂單系統中的消費者監聽訊息,將訊息與對應的狀態插入事件表;
step4:定時任務讀取本地事務表,執行本地業務,更新訂單表狀態,最後將事件表的狀態再更新為終態。
優點
- 擴張性強:如果後續要通知積分系統、倉庫系統、物流系統等,可以直接通過訊息中介軟體解耦,訂單系統只需完成步驟一的操作即可。
- 保證冪等性:傳送訊息,可以用事件id、事件型別、事件內容組成的資料包文傳送,保證每一個事件id在資料庫中只插入一次,如果有重複處理,資料庫拋異常,本地事務將回滾。
缺點
- 不適合用在資料量太大的場景,如果資料量太大,頻繁插入對資料庫效能要求較高;
- 事件表資料會越來越多,已處理完的資料需要考慮遷移到歷史庫,分離冷熱資料。
注意事項
生產環境中,如果多臺機器部署的話,需要考慮分散式定時任務,或者定時任務配合分散式鎖來操作,保證同一時刻只有一條記錄被定時掃描並執行。
5. LCN方案
背景
LCN框架在2017年6月份釋出第一個版本,從開始的1.0,已經發展到了5.0版本。
LCN名稱是由早期版本的LCN框架命名,在設計框架之初的1.0 ~ 2.0的版本時框架設計的步驟是如下,各取其首字母得來的LCN命名。
LCN全稱分別對應如下解釋:
鎖定事務單元(lock)
確認事務模組狀態(confirm)
通知事務(notify)
5.0以後由於框架相容了LCN、TCC、TXC三種事務模式,為了避免區分LCN模式,特此將LCN分散式事務改名為TX-LCN分散式事務框架。
TX-LCN由兩大模組組成, TxClient、TxManager,TxClient作為模組的依賴框架,提供TX-LCN的標準支援,TxManager作為分散式事務的控制方。事務發起方或者參與反都由TxClient端來控制。
核心步驟
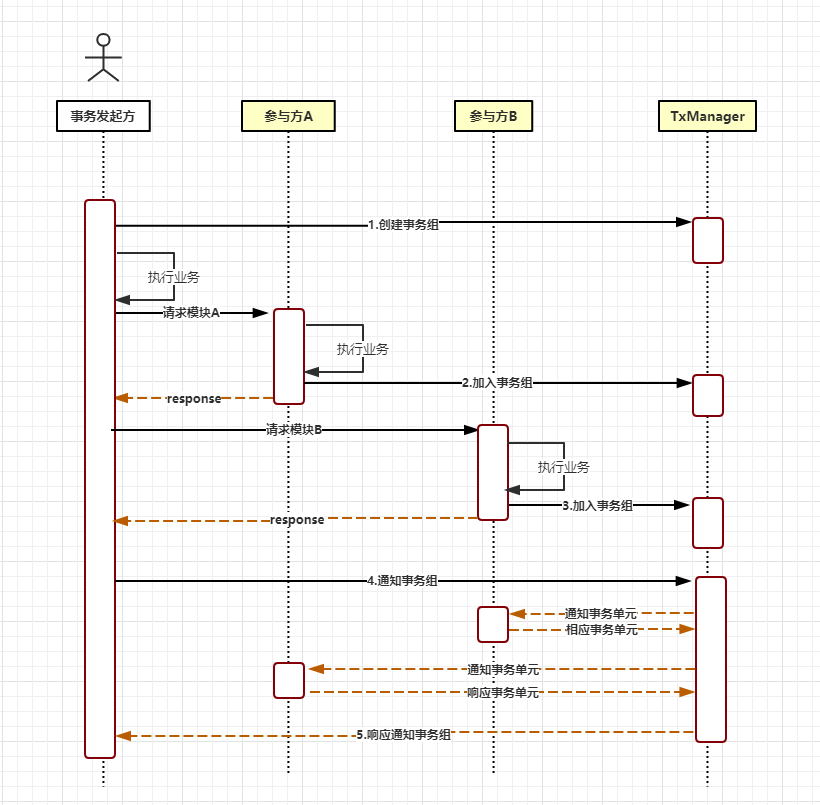
- 建立事務組
是指在事務發起方開始執行業務程式碼之前先呼叫TxManager建立事務組物件,然後拿到事務標示GroupId的過程。
- 加入事務組
新增事務組是指參與方在執行完業務方法以後,將該模組的事務資訊通知給TxManager的操作。
- 通知事務組
是指在發起方執行完業務程式碼以後,將發起方執行結果狀態通知給TxManager,TxManager將根據事務最終狀態和事務組的資訊來通知相應的參與模組提交或回滾事務,並返回結果給事務發起方。
LCN事務模式
LCN模式是通過代理Connection的方式實現對本地事務的操作,然後在由TxManager統一協調控制事務。當本地事務提交回滾或者關閉連線時將會執行假操作,該代理的連線將由LCN連線池管理。
所以該模式的本質是:TM代理了資料來源機制,保持了請求與連線的對應關係。RM假釋放資源,LCN並不生產事務,LCN只是本地事務的協調工。
如下圖:
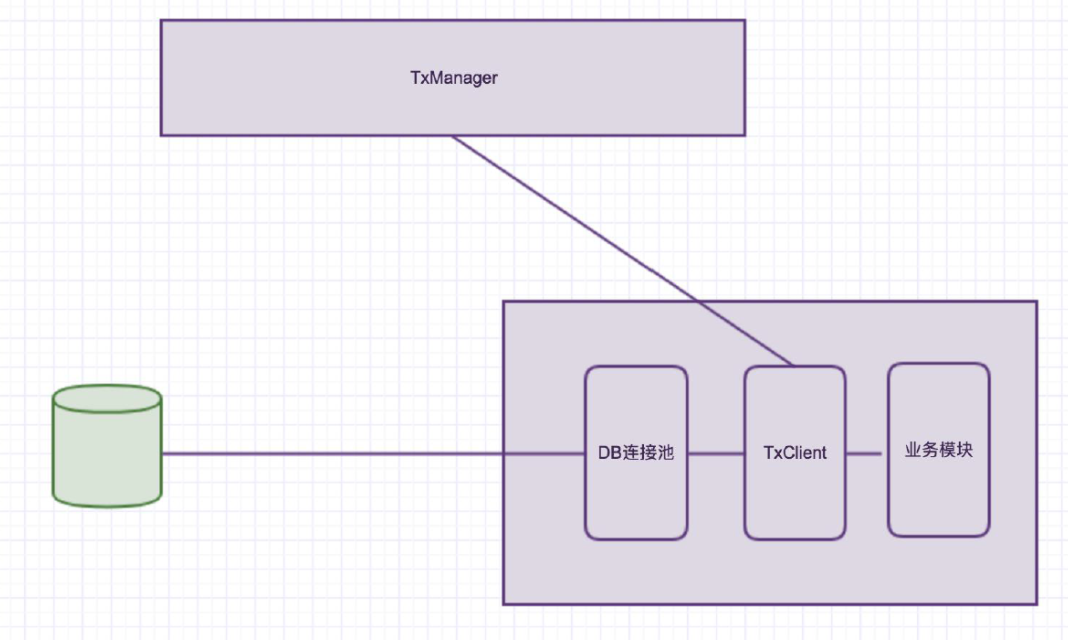
假設服務已經執行到關閉事務組的過程,那麼接下來作為一個模組執行通知給TxManager,然後告訴他本次事務已經完成。
那麼如圖中Txmanager 下一個動作就是通過事務組的id,獲取到本次事務組的事務資訊;然後檢視一下對應有那幾個模組參與,如果是有A/B/C 三個模組;
那麼對應的對三個模組做通知:提交、回滾。
那麼提交的時候是提交給誰呢?
是提交給了我們的TxClient 模組。然後TxCliient 模組下有一個連線池,就是框架自定義的一個連線池(如圖DB 連線池);這個連線池其實就是在沒有通知事務之前一直佔有著這次事務的連線資源,就是沒有釋放。但是他在切面裡面執行了close 方法。在執行close的時候。
如果需要(TxManager)分散式事務框架的連線。他被叫做假關閉,也就是沒有關閉,只是在執行了一次關閉方法。實際的資源是沒有釋放的。這個資源是掌握在LCN 的連線池裡的。
當TxManager 通知提交或事務回滾的時候呢?
TxManager 會通知我們的TxClient 端。然後TxClient 會去執行相應的提交或回滾。
提交或回滾之後再去關閉連線。這就是LCN 的事務協調機制。說白了就是代理DataSource 的機制;相當於是攔截了一下連線池,控制了連線池的事務提交。
特點:
- 該模式對程式碼的嵌入性為低。
- 該模式僅限於本地存在連線物件且可通過連線物件控制事務的模組。
- 該模式下的事務提交與回滾是由本地事務方控制,對於資料一致性上有較高的保障。
- 該模式缺陷在於代理的連線需要隨事務發起方一共釋放連線,增加了連線佔用的時間。
TCC事務模式
TCC事務機制相對於傳統事務機制(X/Open XA Two-Phase-Commit),其特徵在於它不依賴資源管理器(RM)對XA的支援,而是通過對(由業務系統提供的)業務邏輯的排程來實現分散式事務。主要由三步操作,Try: 嘗試執行業務、 Confirm:確認執行業務、 Cancel: 取消執行業務。
如圖所示:
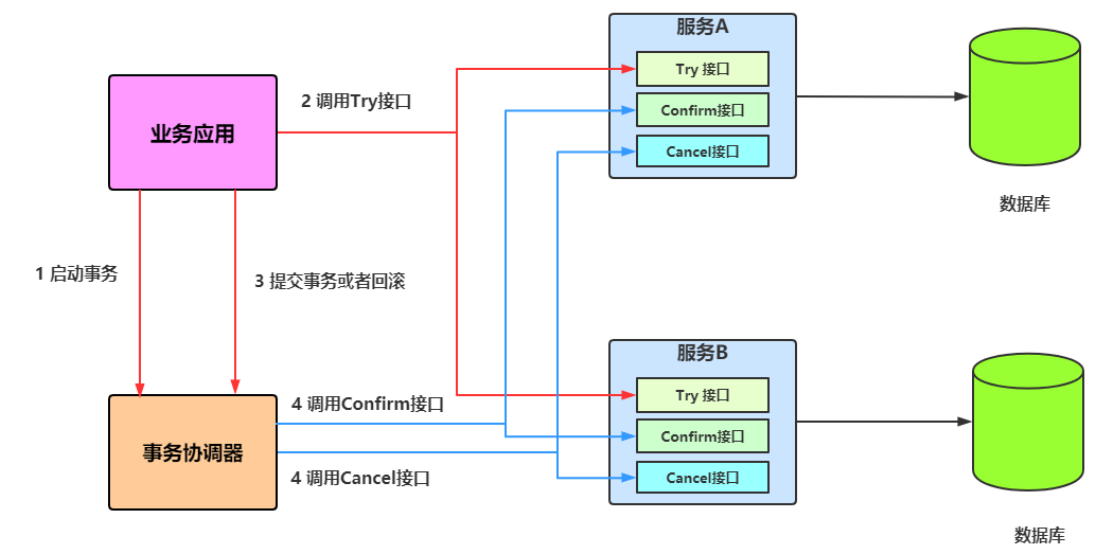
特點:
- 該模式對程式碼的嵌入性高,要求每個業務需要寫三種步驟的操作。
- 該模式對有無本地事務控制都可以支援使用面廣。
- 資料一致性控制幾乎完全由開發者控制,對業務開發難度要求高。
6. TCC方案
TCC方案分為Try、Confirm、Cancel三個階段,屬於補償性分散式事務。
Try:嘗試待執行的業務
這個過程並未執行業務,只是完成所有業務的一致性檢查,並預留好執行所需的全部資源;
Confirm:執行業務
這個過程真正開始執行業務,由於Try階段已經完成了一致性檢查,因此本過程直接執行,而不做任何檢查。並且在執行的過程中,會使用到Try階段預留的業務資源。
Cancel:取消執行的業務,如果任何一個服務的業務方法執行出錯,那麼這裡就需要進行補償。
這種TCC方案適用於一致性要求極高的系統中,比如金錢交易相關的系統中,不過可以看出,其基於補償的原理,因此,需要編寫大量的補償事務的程式碼,比較冗餘。不過現有開源的TCC框架,比如TCC-transaction。一般來說跟錢相關的,跟錢打交道的,支付、交易相關的場景,我們會用TCC,嚴格保證分散式事務要麼全部成功,要麼全部自動回滾,嚴格保證資金的正確性,保證在資金上不會出現問題。
7. 可靠訊息最終一致性方案
本方案,乾脆不用原生的訊息表了,直接基於MQ 來實現事務。比如阿里的RocketMQ 就支援訊息事務。
流程如下:
- A 系統先傳送一個 prepared 訊息到 mq,如果這個 prepared 訊息傳送失敗那麼就直接取消操作別執行了;
- 如果這個訊息傳送成功過了,那麼接著執行本地事務,如果成功就告訴 mq 傳送確認訊息,如果失敗就告訴 mq 回滾訊息;
- 如果傳送了確認訊息,那麼此時 B 系統會接收到確認訊息,然後執行原生的事務;
- mq 會自動定時輪詢所有 prepared 訊息回撥你的介面,問你,這個訊息是不是本地事務處理失敗了,所有沒傳送確認的訊息,是繼續重試還是回滾?一般來說這裡你就可以查下資料庫看之前本地事務是否執行,如果回滾了,那麼這裡也回滾吧。所以mq輪詢,就是避免可能本地事務執行成功了,而確認訊息卻傳送失敗了。
- 這個方案裡,要是系統 B 的事務失敗了咋辦?重試咯,自動不斷重試直到成功,如果實在是不行,要麼就是針對重要的資金類業務進行回滾,比如 B 系統本地回滾後,想辦法通知系統 A 也回滾;或者是傳送報警由人工來手工回滾和補償。
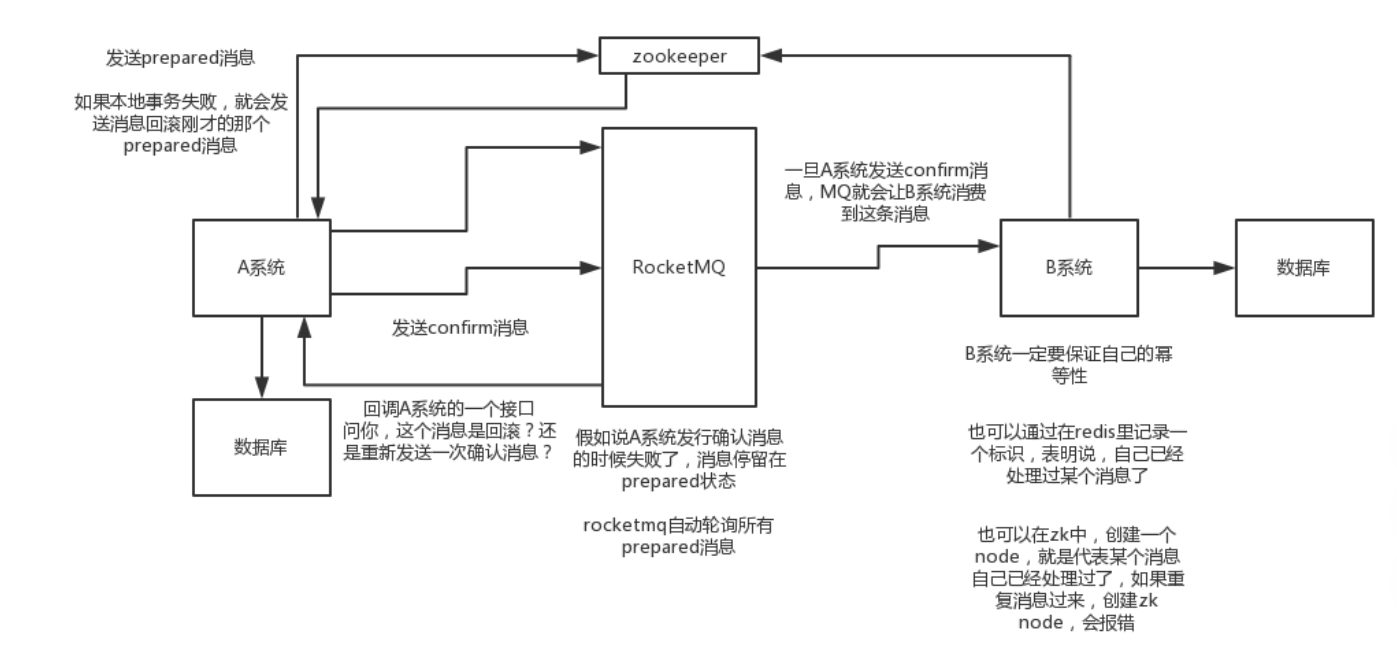
上圖是早期RocketMQ的實現,依賴zookeeper,因為RocketMQ想追求AP模型,後期版本因為想更輕量化,將zookeeper去掉了。
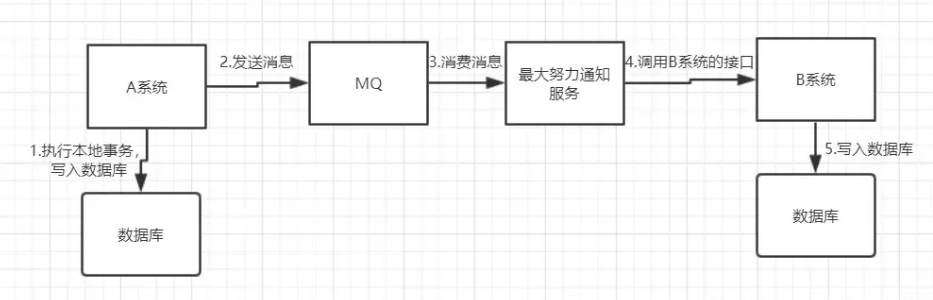
7. 最大努力型通知方案
1.系統 A 本地事務執行完之後,傳送個訊息到 MQ;
2.這裡會有個專門消費 MQ 的最大努力通知服務,這個服務會消費 MQ 然後寫入資料庫中記錄下來,或者是放入個記憶體佇列也可以,接著呼叫系統 B 的介面;
3.要是系統 B 執行成功就 ok 了;要是系統 B 執行失敗了,那麼最大努力通知服務就定時嘗試重新呼叫系統 B,反覆 N 次,最後還是不行就放棄。