一次性全講透GaussDB(DWS)鎖的問題
本文分享自華為雲社群《GaussDB(DWS)鎖問題全解》,作者: yd_211043076。
一、gaussdb有哪些鎖
1、常規鎖:常規鎖主要用於業務存取資料庫物件的加鎖,保護並行操作的物件,保持資料一致性;常見的常規鎖有表鎖(relation)和行鎖(tuple)。
表鎖:當對錶進行DDL、DML操作時,會對操作的物件表加鎖,在事務結束釋放。
行鎖:使用select for share語句時持有該模式鎖,後臺會對tuple加5級鎖;使用select for update, delete, update等操作時,後臺會對tuple加7級鎖(ExclusiveLock)。
2、輕量級鎖:輕量級鎖主要用於資料庫內部共用資源存取的保護,比如記憶體結構、共用記憶體分配控制等。
二、鎖衝突矩陣
1、常規鎖按照粒度可分為8個等級,各操作對應的鎖等級及鎖衝突情況參照下表:
|
鎖編號 |
鎖模式 |
對應操作 |
衝突的鎖編號 |
|
1 |
ACCESS SHARE |
SELECT |
8 |
|
2 |
ROW SHARE |
SELECT FOR UPDATE、SELECT FOR SHARE |
7,8 |
|
3 |
ROW EXCLUSIVE |
INSERT、DELETE、UPDATE |
5,6,7,8 |
|
4 |
SHARE UPDATE EXCLUSIVE |
VACUUM、ANALYZE |
4,5,6,7,8 |
|
5 |
SHARE |
CREATE INDEX |
3,4,6,7,8 |
|
6 |
SHARE ROW EXCLUSIVE |
- |
3,4,5,6,7,8 |
|
7 |
EXCLUSIVE |
- |
2,3,4,5,6,7,8 |
|
8 |
ACCESS EXCLUSIVE |
DROP TABLE、ALTER TABLE、REINDEX、CLUSTER、VACUUM FULL、TRUNCATE |
1,2,3,4,5,6,7,8 |
2、幾種鎖衝突的場景:
ACCESS SHARE與ACCESS EXCLUSIVE鎖衝突例子:session 1 在事務內對錶進行truncate,且lockwait_timeout引數設定為10s;session 2 查詢該表,此時會一直等到session 1 釋放鎖,直到等鎖超時。
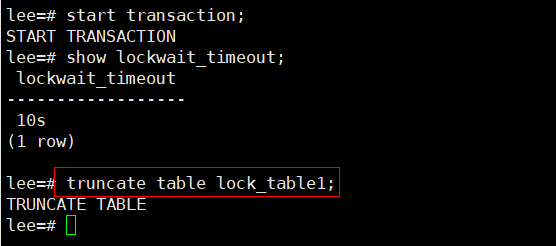

ROW SHARE(行鎖衝突的例子):並行insert/update/copy;session 1在事務內對有主鍵約束的行存表進行更新;session 2對同一主鍵的行進行更新,會一直等待session 1釋放鎖,直到行鎖超時;
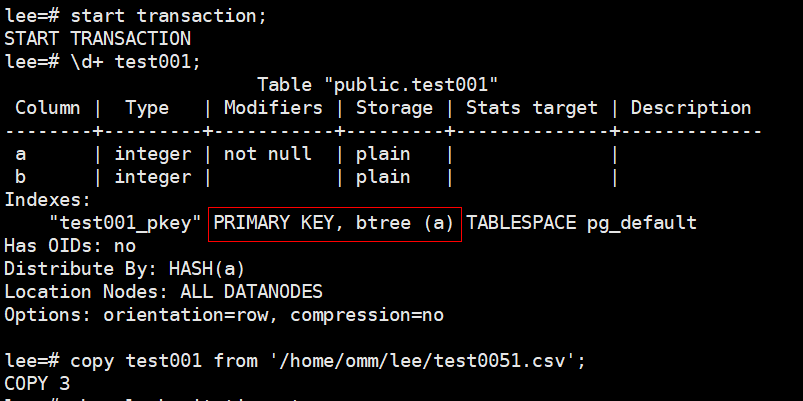

並行更新列存表出現等鎖超時,該現象一般為並行更新同一CU造成的;

場景構造:session 1在事務內對列存表進行更新,不提交事務;session 2同樣對列存表更新,會等鎖超時;(只有更新的為同一CU時才會出現此場景)
列存表並行等鎖原理:https://bbs.huaweicloud.com/blogs/255895 ;
三、鎖相關檢視
pg_locks檢視儲存各開啟事務所持有的鎖資訊,需關注的欄位:locktype(被鎖定物件的型別)、relation(被鎖定物件關係的OID)、pid(持鎖或等鎖的執行緒ID)、mode(持鎖或等鎖模式)、granted(t:持鎖,f:等鎖)。

pgxc_lock_conflicts檢視提供叢集中有衝突的鎖的資訊(適合鎖衝突現場還在是使用),目前只收集locktype為relation、partition、page、tuple和transactionid的鎖的資訊,需要關注的欄位nodename(被鎖定物件節點的名字)、queryid(申請鎖的查詢ID)、query(申請鎖的查詢語句)、pid、mode、granted。
pgxc_deadlock檢視獲取導致分散式死鎖產生的鎖等待資訊,只收集locktype為relation、partition、page、tuple和transactionid的鎖等待資訊。
四、鎖相關引數介紹
lockwait_timeout:控制單個鎖的最長等待時間。當申請的鎖等待時間超過設定值時,系統會報錯,即等鎖超時,一般預設值為20min。
deadlock_timeout:死鎖檢測的超時時間,當申請的鎖超過該設定值仍未獲取到時,觸發死鎖檢測,系統會檢查是否產生死鎖,一般預設值為1s。
update_lockwait_timeout:允許並行更新引數開啟時,控制並行更新同一行單個鎖的最長等待時間,超過該設定值,會報錯,一般預設值為2min。
以上引數的單位均為毫秒,請保證deadlock_timeout的值大於lockwait_timeout,否則將不會觸發死鎖檢測。
五、鎖等待超時排查
https://bbs.huaweicloud.com/blogs/280354
六、為什麼會死鎖(單節點死鎖)
1、死鎖:兩個及以上不同的程序實體在執行時因為競爭資源而陷入僵局,除非外力作用,否則雙發都無法繼續推進;而資料庫事務可針對資源按照任意順序加鎖,就有一定機率因不同的加鎖順序而產生死鎖。
2、死鎖場景模擬:
鎖表順序不同,常見於儲存過程中
|
session 1 |
session 2 |
|
begin; |
begin; |
|
truncate table lock_table2; |
truncate table lock_table1; |
|
select * from lock_table1; |
select * from lock_table2; |
第一時刻:session 1:先拿到lock_table2的8級鎖,此時session 2拿到lock_table1的8級鎖;第二時刻:session 1:再嘗試申請lock_table1的1級鎖; session 2 :嘗試申請lock_table2的1級鎖;兩個對談都持鎖並等待對方手裡的鎖釋放。
GaussDB(DWS)會自動處理單點死鎖,當單節點死鎖發生時,資料庫會自動回滾其中一條事務,以消除死鎖現象。

3、一些死鎖場景
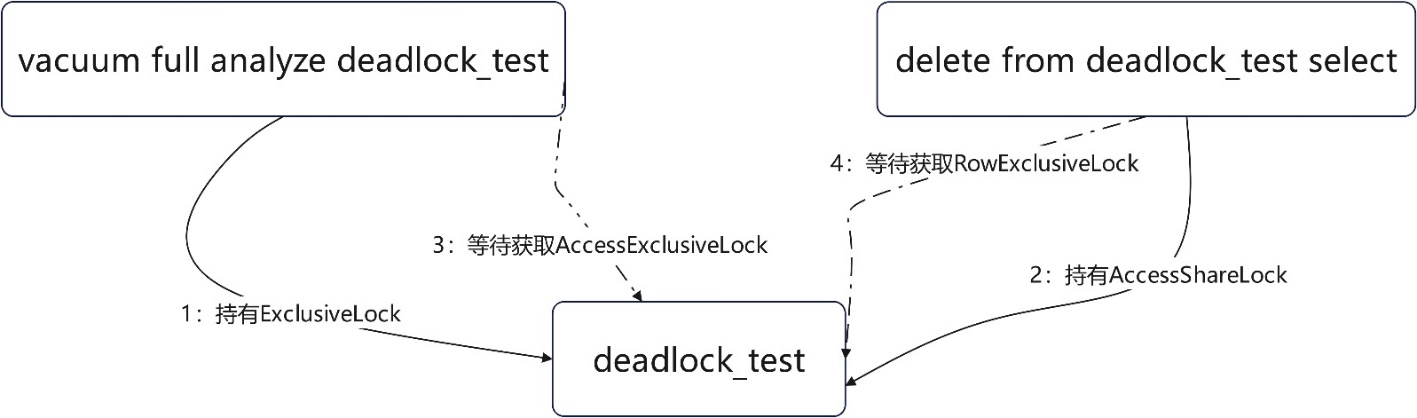
vacuum full 與delete select語句造成的死鎖(等同一物件的不同鎖);部分業務場景下,存在查詢時間窗在白天,而業務跑批刪除只能在晚上執行,同樣為了保證查詢效率降低髒頁率,對業務表的vacuum full操作也在晚上,時間窗重合,升鎖過程便可能產生死鎖;

上述場景下vacuum full語句申請1:ExclusiveLock並持有,後續delete from語句申請2:cessShareLock並持有;vacuum full升級鎖3:AccessExclusiveLock失敗;delete from升級鎖4:RowExclusiveLock失敗;兩個語句形成死鎖。
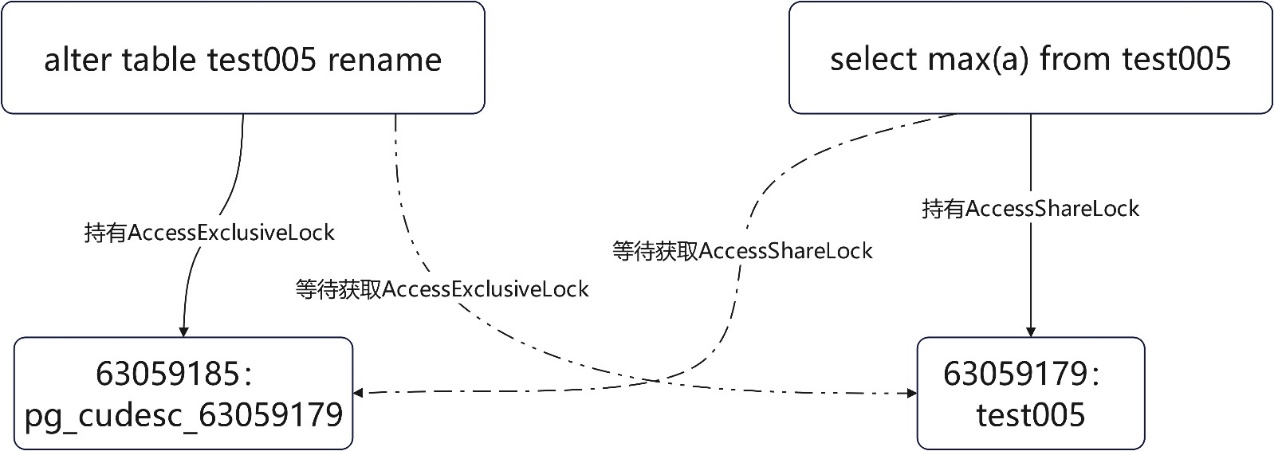
ater列存表與select max(a)的死鎖,兩條語句只涉及一張表,但仍舊會產生死鎖,列存表有CUdesc表及delta表,語句在行時拿鎖順序不同,便可能產生死鎖

列存表查詢max(col)時,儘管並沒有開啟delta表,也會獲取delta表的鎖,alter table也一樣,此時同一個操作物件變存在兩個獨立的資源(主表與delta表,其實還應該包含CUdesc表),不同拿鎖順序變產生這種兩個語句操作同一張表死鎖的現象。
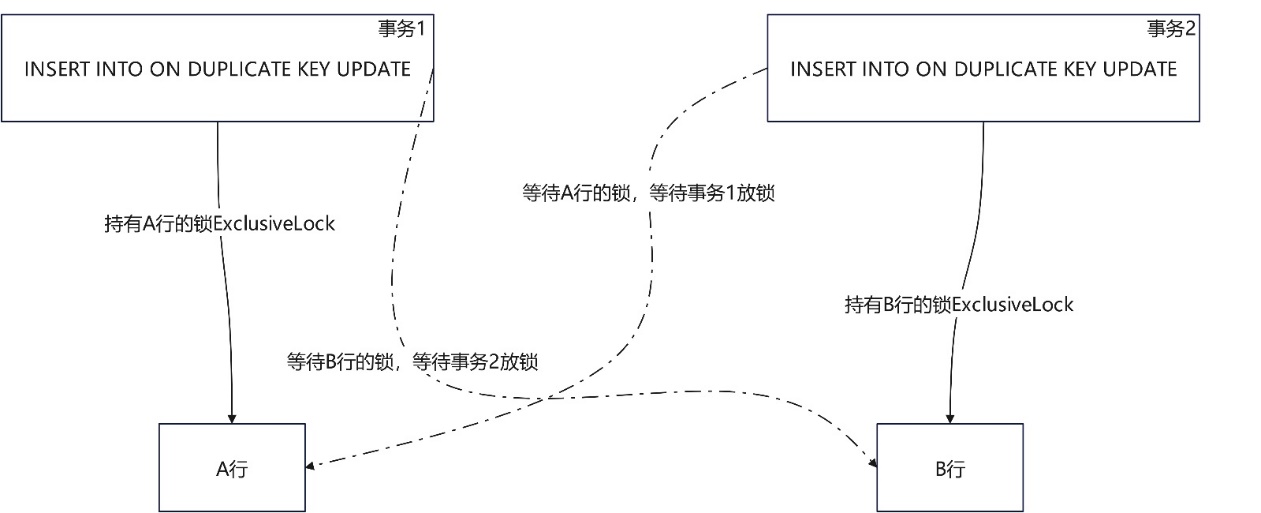
upsert的死鎖現象:行存帶主鍵約束或列存表場景下並行upsert,並行更新重複的資料,且不同事務內部更新的相同資料的順序不同;
該場景主要為分別從兩個資料來源做並行導數(upsert方式)時,時間窗未區分開,且資料也存在重複的可能性,此時便可能存在以不同的順序分別更新相同資料(行)的現象,就會引發死鎖現象,導致某一次導數任務失敗,可選擇業務側將兩個任務區分到不同時間窗去執行來規避該死鎖現象。
七、分散式死鎖
DWS的share nothing結構,使得一條語句可能在不同的節點上執行,在這些節點上都要對操作物件申請鎖,且同樣存在以不同順序申請鎖的可能,因此便存在分散式死鎖的場景
1、如何排查分散式死鎖:
先構造一個分散式死鎖場景,如下圖,session 1 在CN 1上開啟事務並先查詢lock_table1;此時session 2在CN 2上開啟事務並查詢lock_table1,然後兩個對談分別執行truncate表:
|
session 1-CN 1 |
session 2-CN 2 |
|
begin; |
begin; |
|
select * from lock_table1; |
select * from lock_table1; |
|
truncate table lock_table1; |
truncate table lock_table1; |
通過查詢分散式死鎖檢視:select * from pgxc_deadlock order by nodename,dbname,locktype,nspname,relname;

根據查詢結果,可以看出在構造的該場景下:

CN_5001的truncate語句執行緒號為:139887210493696;在等待執行緒號為:139887432832768的truncate語句釋放lock_table1的AccessShareLock(事務中select語句持有的鎖),同時該執行緒:139887210493696,持有lock_table1的AccessExclusiveLock;
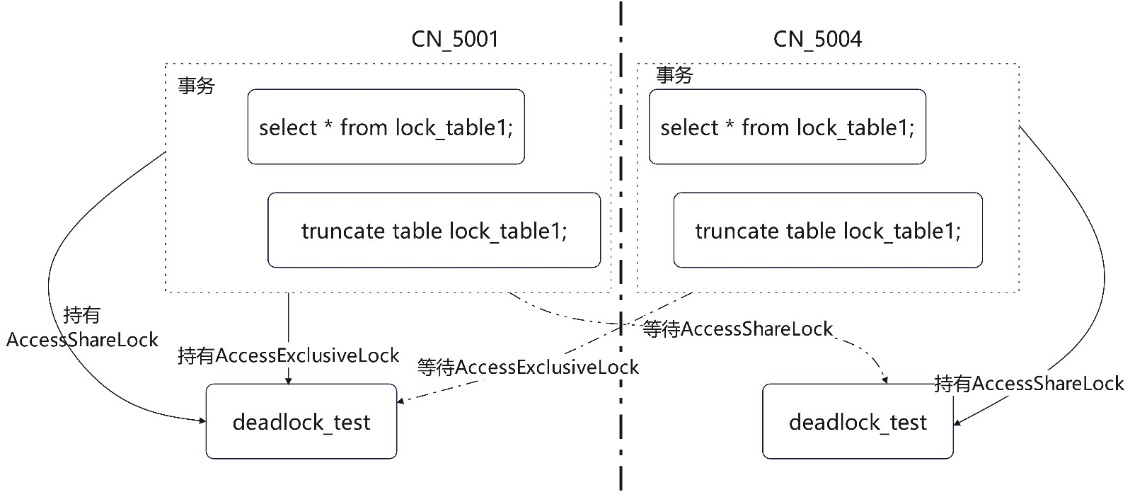
CN_5004的truncate語句執行緒號為:139887432832768;在等待執行緒號為:139887210493696的truncate語句釋放lock_table1的AccessExclusiveLock;同時該執行緒:139887432832768持有lock_table1的AccessShareLock;這種 場景下在不同範例上分散式的等待關係,便形成了分散式死鎖。
2、消除分散式死鎖:
對於分散式死鎖的場景,一般在一個事務因為等鎖超時後事務回滾,另一個未超時的事務便能繼續進行下去;人為干預的情況,則需要呼叫select pg_terminate_backend(pid),查殺掉一個持鎖語句,破壞環形等待條件,便可讓另一個事務繼續執行下去。