如何實現一個資料庫的 UDF?圖資料庫 NebulaGraph UDF 功能背後的設計與思考
大家好,我是來自 BOSS直聘的趙俊南,主要負責安全方面的圖儲存相關工作。作為一個從 v1.x 用到 v3.x 版本的忠實使用者,在見證 NebulaGraph 發展的同時,也和它一起成長。
BOSS直聘和 NebulaGraph
關於 NebulaGraph 在 BOSS直聘的應用場景,大家可以看看之前文洲老師的文章(圖資料庫 NebulaGraph 在 BOSS直聘的應用),從那時候文洲老師構建的行為圖發展到了安全場景的業務主圖、演演算法推理圖、職位相似度圖譜等業務,現在更是支援了數倉同學的資料血緣及搜尋同學的實時搜尋召回場景,單圖的規模達到了數千億。
在圖計算方面,BOSS 直聘基於 LPA 和 Louvain 的單度團、多維團,以及基礎的離線特徵,在安全生產環境中廣泛應用圖技術。相信未來圖在 BOSS直聘還會有更為寬廣的舞臺。
UDF 的萌生
隨著 NebulaGraph 在 BOSS直聘業務上的廣泛應用,相對應的對內部技術人員的要求也越來越高。如果技術人員僅僅停留在使用層面,就無法滿足從功能到效能很多需求。所以,學習原始碼成為了必然。
而後遷移 Neo4j->NebulaGraph 過程中,發現業務對 Neo4j 的 UDF 包有所依賴,我本萌生了實現 NebulaGraph UDF 功能的念頭。
UDF 設計和實現原理
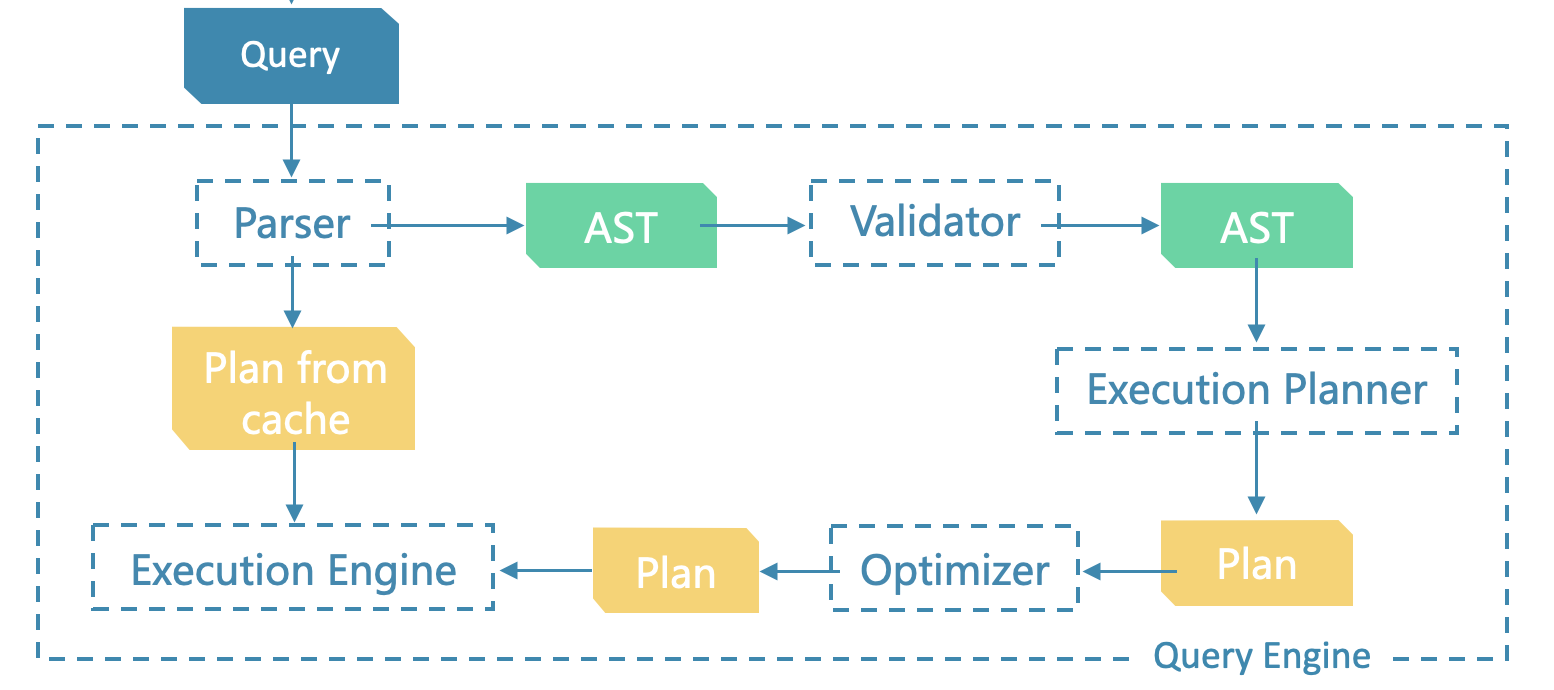
上圖是一條完整 nGQL 語句的執行過程,而 UDF 實現原理同 nGQL 的執行流程相關,大致如下:
graphd 接收到語句 -> Bison 詞法解析(切詞) -> Flex 語法解析建立 Sentence -> Validator 校驗並生成AstContext(抽象語法樹) -> toPlan 生成執行計劃 Planner -> Optimizer 優化器優化 -> Executor 執行器執行。
在詞法語法解析階段,Function 會被單獨解析出來。FunctionManager 作為原生的內建函數管理者,負責函數的定義、載入、呼叫等操作,從而管理函數的整個生命週期。呼叫語句通過 FunctionManager 查詢到的函數最終會被執行器呼叫執行。
NebulaGraph 的 UDF 實現基於函數的呼叫執行流程,增加了 FunctionUdfManager:
static std::unordered_map<std::string, Value::Type> udfFunReturnType_;
static std::unordered_map<std::string, std::vector<std::vector<nebula::Value::Type>>>
udfFunInputType_;
std::unordered_map<std::string, FunctionManager::FunctionAttributes> udfFunctions_;
class FunctionUdfManager {
public:
typedef GraphFunction *(create_f)();
typedef void(destroy_f)(GraphFunction *);
static StatusOr<Value::Type> getUdfReturnType(const std::string functionName,
const std::vector<Value::Type> &argsType);
static StatusOr<const FunctionManager::FunctionAttributes> loadUdfFunction(
std::string functionName, size_t arity);
static FunctionUdfManager &instance();
FunctionUdfManager();
private:
static create_f *getGraphFunctionClass(void *func_handle);
static destroy_f *deleteGraphFunctionClass(void *func_handle);
void addSoUdfFunction(char *funName, const char *soPath, size_t i, size_t i1, bool b);
void initAndLoadSoFunction();
};
它主要做以下幾件事:
- 和 FunctionManager 一起初始化,initAndLoadSoFunction 開啟定時掃描,掃描
--udf_path路徑下檔案; - loadUdfFunction載入
.so檔案,範例化函數方法,以函數名為 key 儲存在 Map 中; - 在啟用 UDF 功能的情況下,FunctionManager 未查詢函數時,查詢並呼叫 FunctionUdfManager Map 中的函數。
實現比較簡單,可以說是取巧了,有需要的話 UDAF 也可用類似方式實現。
UDF 使用方法
下面來講講 NebulaGraph UDF 的具體使用,如果你是用 NebulaGraph v3.5.0+ 版本的話,就可以按照以下方式使用 UDF 功能了。如果你是 v3.4.x 及以下版本,UDF 功能是暫不支援的,你也可以 cherry-pick 這個 pr 自行編譯使用 UDF 功能。
第一步,在 graphd 組態檔中開啟 UDF 功能並指定包目錄
# enable udf, c++ only
--enable_udf=true
# set the directory where the .so of udf are stored
--udf_path=/home/foobar/dev/nebula/udf/
第二步,編寫自定義函數程式碼,繼承 GraphFunction。GraphFunction 的結構如下:
class GraphFunction;
extern "C" GraphFunction *create();
extern "C" void destroy(GraphFunction *function);
class GraphFunction {
public:
virtual ~GraphFunction() = default;
virtual char *name() = 0;
virtual std::vector<std::vector<nebula::Value::Type>> inputType() = 0;
virtual nebula::Value::Type returnType() = 0;
virtual size_t minArity() = 0;
virtual size_t maxArity() = 0;
virtual bool isPure() = 0;
virtual nebula::Value body(
const std::vector<std::reference_wrapper<const nebula::Value>> &args) = 0;
};
- create、destroy 是函數的建立銷燬方法;
- name 呼叫時的函數名;
- inputType、returnType 輸入輸出型別;
- minArity、maxArity 引數數量;
- isPure 函數是否有狀態;
- body 函數的實現。
第三步,編寫好的函數打包成(.so)檔案,放到組態檔 --udf_path 設定的對應目錄下,graphd 服務會定時(5 分鐘)掃描該路徑下的包,載入到函數庫中。之後,就可以在自己的語句中呼叫對應的函數了。
⚠️ 注意:由於 graphd 只掃描本地路徑下的函數包,想讓多個 graphd 都生效,必須都在本地路徑下有相應的包。
這裡要 cue 下思為老師,感謝他補充的完整使用檔案和編譯環境:https://github.com/vesoft-inc/nebula/pull/4804 。
UDF 尚未解決的問題
雖然目前 UDF 是能用,但是它還存在部分優化問題。比如:
- so 包位置只支援掃描本地;
- 函數只在 graphd 層,無法下推到儲存;
- 使用麻煩,需要使用者編碼。
當然這些問題和一開始的設計息息相關:開發 UDF 之初,其實是想相容 C++ 的 so 包和 Java 的 jar 包,但測試了 C++ Jni 呼叫 Java 的效能,發現基本上無法用於大規模的生產。
下圖便是當時的效能測試:
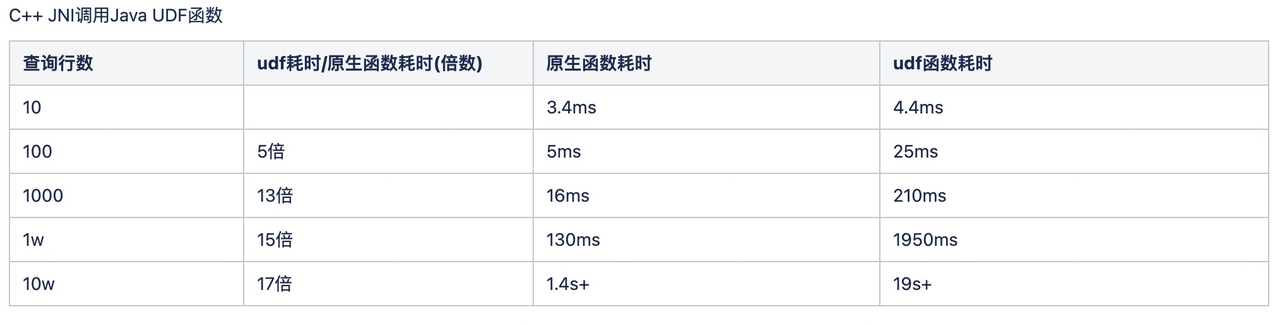
因為實現實在是效能堪憂,於是就放棄了一開始的設計。
當然還有一些未來規劃上的事情,主要是希望 NebulaGraph 開發團隊一起合作完成:
- 個別的大查詢語句和深度查詢,容易把 storaged 的記憶體打滿影響叢集整體效能。是否可以考慮通過查詢時間超時或記憶體監控自動 kill 對應的查詢,釋放掉記憶體。其實對於類似的語句,基本上已經很難拿到結果了,更多的可能是想降低語句帶來的影響
- 叢集的容錯性,多副本情況下某個節點的非正常下線會影響整體叢集,由於環境的複雜性具體定位分析也比較困難,盼望儘可能增強叢集健壯性。
開發 UDF 的意外收穫
前面說過,UDF 其實是閱讀 NebulaGraph 原始碼的產物。這裡我想談談我對原始碼閱讀感受:整體的 NebulaGraph 原始碼給我最直觀的感受就是層次、結構清晰,程式碼優雅。在配合官方部落格提供的核心講解系列文章,對我這種跨語言學習的選手難度都大大降低了。
希望 UDF 能幫你解決一些問題,以及我的分享能給你帶來一絲啟發。
謝謝你讀完本文 (///▽///)
如果你想嚐鮮圖資料庫 NebulaGraph,記得去 GitHub 下載、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 使用者一起交流圖資料庫技術和應用技能,留下「你的名片」一起玩耍呀~
2023 年 NebulaGraph 技術社群年度徵文活動正在進行中,來這裡領取華為 Meta 60 Pro、Switch 遊戲機、小米掃地機器人等等禮品喲~ 活動連結:https://discuss.nebula-graph.com.cn/t/topic/13970
