域名掃描工具subDomainBrute原始碼分析
SubDomainsBrute簡介
SubDomainsBrute是一款目標域名收集工具 ,用小字典遞迴地發現三級域名、四級域名、五級域名等不容易被探測到的域名。字典較為全面,小字典就包括3萬多條,大字典多達8萬條。預設使用114DNS、百度DNS、阿里DNS這幾個快速又可靠的公共DNS進行查詢,可隨時修改組態檔新增你認為可靠的DNS伺服器。自動篩選泛解析的域名,當前規則是: 超過10個域名指向同一IP,則此後發現的其他指向該IP的域名將被丟棄。整體速度還可以,每秒穩定掃描100到200個域名(10個執行緒)。
工具可從github上 獲取。
Github地址: https://github.com/lijiejie/subDomainsBrute
目錄
dict #存放dns目錄和域名字典
lib
--__init__.py
--cmdline.py #引數設定
--common_py2.py #獲取域名字典
--common_py3.py #檢查dns是否可用
--common.py #獲取字典
--consle_width.py
--scanner_py2.py #為3.5版本以下的域名掃描檔案
--scanner_py3.py #為3.5版本以上的域名掃描檔案
subDomainsBrute.py 函數入口處
執行流程
一.檢查引數和字典
獲取命令列輸入的引數
#subDomainsBrute.py
options, args = parse_args()
根據域名建立子檔案,存放子域名資訊
#subDomainsBrute.py
tmp_dir = 'tmp/%s_%s' % (args[0], int(time.time()))
if not os.path.exists(tmp_dir):
os.makedirs(tmp_dir)
呼叫common_py3.py中的load_next_sub()函數,傳入命令列輸入的引數作為函數引數,得到公共dns列表
#subDomainsBrute.py
dns_servers = load_dns_servers()
進入load_dns_servers()檢視,其中dns_servers.txt存放公共dns:如119.29.29.29是騰訊DNSPod公共DNS,還有114dns(114.114.114.114),阿里(223.5.5.5.5),百度(180.76.76.76),360(101.226.4.6),google(8.8.8.8)等 ,使用一個已經存在的域名驗證dns是否有效,
#common_py3.py
def load_dns_servers():
print_msg('[+] Validate DNS servers', line_feed=True)
dns_servers = []
servers_to_test = [] #儲存可用的dns地址
for server in open('dict/dns_servers.txt').readlines(): #遍歷dns的Ip地址
server = server.strip() #移除字串頭尾指定的字元(預設為空格或換行符)
if server and not server.startswith('#'): #檢查字串是否是以#開頭,將不以#開頭的加入
servers_to_test.append(server) #將不以#開頭的新增到列表
loop = asyncio.get_event_loop()
loop.run_until_complete(async_load_dns_servers(servers_to_test, dns_servers)) #呼叫async_load_dns_servers函數
# loop.close()
server_count = len(dns_servers)
print_msg('\n[+] %s DNS Servers found' % server_count, line_feed=True)
if server_count == 0:
print_msg('[ERROR] No valid DNS Server !', line_feed=True)
sys.exit(-1)
return dns_servers #返回公共dns列表
#進入async_load_dns_servers
async def async_load_dns_servers(servers_to_test, dns_servers): #async為非同步標誌
tasks = []
for server in servers_to_test:
task = test_server_python3(server, dns_servers) #呼叫test_server_python3函數
tasks.append(task)
await asyncio.gather(*tasks) #非同步執行
#進入test_server_python3()
async def test_server_python3(server, dns_servers):
resolver = aiodns.DNSResolver()
try:
resolver.nameservers = [server]
answers = await resolver.query('public-dns-a.baidu.com', 'A') #一個已經存在的域名
if answers[0].host != '180.76.76.76': #判斷解析是否正確
raise Exception('Incorrect DNS response')
try:
await resolver.query('test.bad.dns.lijiejie.com', 'A') #嘗試一個不存在的域名
with open('bad_dns_servers.txt', 'a') as f:
f.write(server + '\n') #解析失敗,dns無效寫入bad_dns_servers.txt檔案
print_msg('[+] Bad DNS Server found %s' % server)
except Exception as e:
dns_servers.append(server) #解析正確判斷為有效dns,加入列表
print_msg('[+] Server %s < OK > Found %s' % (server.ljust(16), len(dns_servers)))
except Exception as e:
print_msg('[+] Server %s <Fail> Found %s' % (server.ljust(16), len(dns_servers)))
回到入口程式,然後呼叫了common_py3.py中的load_next_sub()函數,得到子域名字典,進入load_next_sub()檢視
#subDomainsBrute.py
next_subs = load_next_sub(options)
#common_py3.py
def load_next_sub(options):
next_subs = []
_file = 'dict/next_sub_full.txt' if options.full_scan else 'dict/next_sub.txt' #根據引數判斷使用哪個字典
with open(_file) as f:
for line in f:
sub = line.strip() #移除每行頭尾空格和換行
if sub and sub not in next_subs: #判斷是否在next_subs中重複
tmp_set = {sub}
while tmp_set:
item = tmp_set.pop()
if item.find('{alphnum}') >= 0:
for _letter in 'abcdefghijklmnopqrstuvwxyz0123456789':
tmp_set.add(item.replace('{alphnum}', _letter, 1))
elif item.find('{alpha}') >= 0:
for _letter in 'abcdefghijklmnopqrstuvwxyz':
tmp_set.add(item.replace('{alpha}', _letter, 1))
elif item.find('{num}') >= 0:
for _letter in '0123456789':
tmp_set.add(item.replace('{num}', _letter, 1))
elif item not in next_subs:
next_subs.append(item) #多次判斷是否存在{alphnum}、{alpha}、{num}進行替換,替換後加入到子域名列表中
return next_subs #返回子域名列表
使用multiprocessing多程序共用資料。i代表型別為int整數,0代表初始值
#subDomainsBrute.py
scan_count = multiprocessing.Value('i', 0)
found_count = multiprocessing.Value('i', 0)
queue_size_array = multiprocessing.Array('i', options.process)
multiprocessing.Value(typecode_or_type, *args, lock=True) #共用單個資料,其值通過value屬性存取。
typecode_or_type:陣列中的資料型別,為代表資料型別的類或者str。比如,'i'表示int,'f'表示float。 args:可以設定初始值。比如:multiprocessing.Value('d',6)生成值為6.0的資料。 lock:bool,是否加鎖。
判斷w引數不存在時,主程式呼叫wildcard_test()函數,進入wildcard_test()檢視, 和test_server相似 ,萬用字元測試失敗後建議使用引數-w強制掃描
#subDomainsBrute.py
if not options.w:
domain = wildcard_test(args[0], dns_servers)
else:
domain = args[0]
#common_py2.py
def wildcard_test(domain, dns_servers, level=1):
try:
r = dns.resolver.Resolver(configure=False)
r.nameservers = dns_servers
answers = r.query('lijiejie-not-existed-test.%s' % domain)
ips = ', '.join(sorted([answer.address for answer in answers]))
if level == 1:
print('any-sub.%s\t%s' % (domain.ljust(30), ips))
wildcard_test('any-sub.%s' % domain, dns_servers, 2)
elif level == 2:
print('\nUse -w to enable force scan wildcard domain')
sys.exit(0)
except Exception as e:
return domain
然後呼叫get_sub_file_path(),將字典相對路徑返回並賦值
#subDomainsBrute.py
options.file = get_sub_file_path(options)
#common_py2.py
def get_sub_file_path(options):
if options.full_scan and options.file == 'subnames.txt':
sub_file_path = 'dict/subnames_full.txt' #判斷使用引數--full和subnames.txt才使用subnames.txt字典
else:
if os.path.exists(options.file):
sub_file_path = options.file
elif os.path.exists('dict/%s' % options.file):
sub_file_path = 'dict/%s' % options.file
else:
print_msg('[ERROR] Names file not found: %s' % options.file)
exit(-1)
return sub_file_path #返回字典的具體路徑
二.域名獲取
根據輸入的程序數設定程序數,新增到程序池中,並設定了run_process()函數
#subDomainsBrute.py
all_process = []
for process_num in range(options.process):
p = multiprocessing.Process(target=run_process,
args=(domain, options, process_num, dns_servers, next_subs,scan_count, found_count, queue_size_array, tmp_dir))
all_process.append(p)
p.start()
到run_process()中檢視
#subDomainsBrute.py
def run_process(*params):
signal.signal(signal.SIGINT, user_abort)
s = SubNameBrute(*params) #定義該類
s.run()
#scanner_py2.py
class SubNameBrute(object):
def __init__(self, *params): #SubNameBrute類中首先執行函數
self.domain, self.options, self.process_num, self.dns_servers, self.next_subs, self.scan_count, self.found_count, self.queue_size_array, tmp_dir = params #傳入引數
/*
... #預設引數賦值
*/
self.outfile = open('%s/%s_part_%s.txt' % (tmp_dir, self.domain, self.process_num), 'w') #定義輸出檔案
self.normal_names_set = set()
self.load_sub_names() #呼叫自身的load_sub_names函數
self.lock = RLock()
self.threads_status = ['1'] * self.options.threads
def load_sub_names(self): #返回測試域名列表作為字典
normal_lines = []
wildcard_lines = []
wildcard_set = set()
regex_list = []
lines = set()
with open(self.options.file) as inFile:
for line in inFile.readlines():
sub = line.strip()
if not sub or sub in lines: #排除sub為空和sub重複的情況
continue
lines.add(sub)
brace_count = sub.count('{') #檢測{萬用字元}數量進行替換
if brace_count > 0:
wildcard_lines.append((brace_count, sub))
sub = sub.replace('{alphnum}', '[a-z0-9]')
sub = sub.replace('{alpha}', '[a-z]')
sub = sub.replace('{num}', '[0-9]')
if sub not in wildcard_set:
wildcard_set.add(sub)
regex_list.append('^' + sub + '$')
else:
normal_lines.append(sub)
self.normal_names_set.add(sub)
if regex_list:
pattern = '|'.join(regex_list)
_regex = re.compile(pattern)
for line in normal_lines:
if _regex.search(line):
normal_lines.remove(line)
for _ in normal_lines[self.process_num::self.options.process]:
self.queue.put((0, _)) # priority set to 0
for _ in wildcard_lines[self.process_num::self.options.process]:
self.queue.put(_)
def run(self):
threads = [gevent.spawn(self.scan, i) for i in range(self.options.threads)]
gevent.joinall(threads)
def scan(self, j):
self.resolvers[j].nameservers = [self.dns_servers[j % self.dns_count]] + self.dns_servers
while True:
try:
if time.time() - self.count_time > 1.0:
self.lock.acquire()
self.scan_count.value += self.scan_count_local
self.scan_count_local = 0
self.queue_size_array[self.process_num] = self.queue.qsize()
if self.found_count_local:
self.found_count.value += self.found_count_local
self.found_count_local = 0
self.count_time = time.time()
self.lock.release()
brace_count, sub = self.queue.get_nowait()
self.threads_status[j] = '1'
if brace_count > 0:
brace_count -= 1
if sub.find('{next_sub}') >= 0:
for _ in self.next_subs:
self.queue.put((0, sub.replace('{next_sub}', _)))
if sub.find('{alphnum}') >= 0:
for _ in 'abcdefghijklmnopqrstuvwxyz0123456789':
self.queue.put((brace_count, sub.replace('{alphnum}', _, 1)))
elif sub.find('{alpha}') >= 0:
for _ in 'abcdefghijklmnopqrstuvwxyz':
self.queue.put((brace_count, sub.replace('{alpha}', _, 1)))
elif sub.find('{num}') >= 0:
for _ in '0123456789':
self.queue.put((brace_count, sub.replace('{num}', _, 1)))
continue
except gevent.queue.Empty as e:
self.threads_status[j] = '0'
gevent.sleep(0.5)
if '1' not in self.threads_status:
break
else:
continue
try:
if sub in self.found_subs:
continue
self.scan_count_local += 1
cur_domain = sub + '.' + self.domain #子域名和域名拼接成當前域名
answers = self.resolvers[j].query(cur_domain) #請求dns進行解析當前域名
if answers: #返回解析存在執行if塊
self.found_subs.add(sub) #新增到列表中
ips = ', '.join(sorted([answer.address for answer in answers])) #使用,分隔解析的ip字串
if ips in ['1.1.1.1', '127.0.0.1', '0.0.0.0', '0.0.0.1']: #排除非正常ip
continue
if self.options.i and is_intranet(answers[0].address): #呼叫is_intranet判斷ip不是內網地址時加入陣列
continue
try:
self.scan_count_local += 1
answers = self.resolvers[j].query(cur_domain, 'cname') #根據cname記錄查詢新的域名別名
cname = answers[0].target.to_unicode().rstrip('.') #分隔新域名別名
if cname.endswith(self.domain) and cname not in self.found_subs: #判斷當與原域名不同且不在發現的域名列表中時新增到域名列表中
cname_sub = cname[:len(cname) - len(self.domain) - 1]
if cname_sub not in self.normal_names_set:
self.found_subs.add(cname)
self.queue.put((0, cname_sub))
except Exception as e:
pass
first_level_sub = sub.split('.')[-1]
max_found = 20
if self.options.w:
first_level_sub = ''
max_found = 3
if (first_level_sub, ips) not in self.ip_dict:
self.ip_dict[(first_level_sub, ips)] = 1
else:
self.ip_dict[(first_level_sub, ips)] += 1
if self.ip_dict[(first_level_sub, ips)] > max_found:
continue
self.found_count_local += 1
self.outfile.write(cur_domain.ljust(30) + '\t' + ips + '\n')
self.outfile.flush()
try:
self.scan_count_local += 1
self.resolvers[j].query('lijiejie-test-not-existed.' + cur_domain)
except (dns.resolver.NXDOMAIN, ) as e: # dns.resolver.NoAnswer
if self.queue.qsize() < 50000:
for _ in self.next_subs:
self.queue.put((0, _ + '.' + sub))
else:
self.queue.put((1, '{next_sub}.' + sub))
except Exception as e:
pass
except (dns.resolver.NXDOMAIN, dns.resolver.NoAnswer) as e:
pass
except dns.resolver.NoNameservers as e:
self.queue.put((0, sub)) # Retry
except dns.exception.Timeout as e:
self.timeout_subs[sub] = self.timeout_subs.get(sub, 0) + 1
if self.timeout_subs[sub] <= 1:
self.queue.put((0, sub)) # Retry
except Exception as e:
import traceback
traceback.print_exc()
with open('errors.log', 'a') as errFile:
errFile.write('[%s] %s\n' % (type(e), str(e)))
其中呼叫的is_intranet()函數如下,將10,172.16~31,192.168開頭的判定為內網地址
#common.py
def is_intranet(ip):
ret = ip.split('.')
if len(ret) != 4:
return True
if ret[0] == '10':
return True
if ret[0] == '172' and 16 <= int(ret[1]) <= 31:
return True
if ret[0] == '192' and ret[1] == '168':
return True
return False
三.資料輸出
之後主程式根據程序活躍情況繪製進度條
#subDomainsBrute.py
char_set = ['\\', '|', '/', '-'] #進度條顯示的字元
count = 0
while all_process:
for p in all_process:
if not p.is_alive():
all_process.remove(p)
groups_count = 0
for c in queue_size_array:
groups_count += c
msg = '[%s] %s found, %s scanned in %.1f seconds, %s groups left' % (
char_set[count % 4], found_count.value, scan_count.value, time.time() - start_time, groups_count)
print_msg(msg)
count += 1
time.sleep(0.3)
之後呼叫get_out_file_name()函數獲取輸出檔名,將域名資料存放到檔案中
#subDomainsBrute.py
out_file_name = get_out_file_name(domain, options)
all_domains = set()
domain_count = 0
with open(out_file_name, 'w') as f:
for _file in glob.glob(tmp_dir + '/*.txt'):
with open(_file, 'r') as tmp_f:
for domain in tmp_f:
if domain not in all_domains:
domain_count += 1
all_domains.add(domain) # cname query can result in duplicated domains
f.write(domain)
函數呼叫關係圖
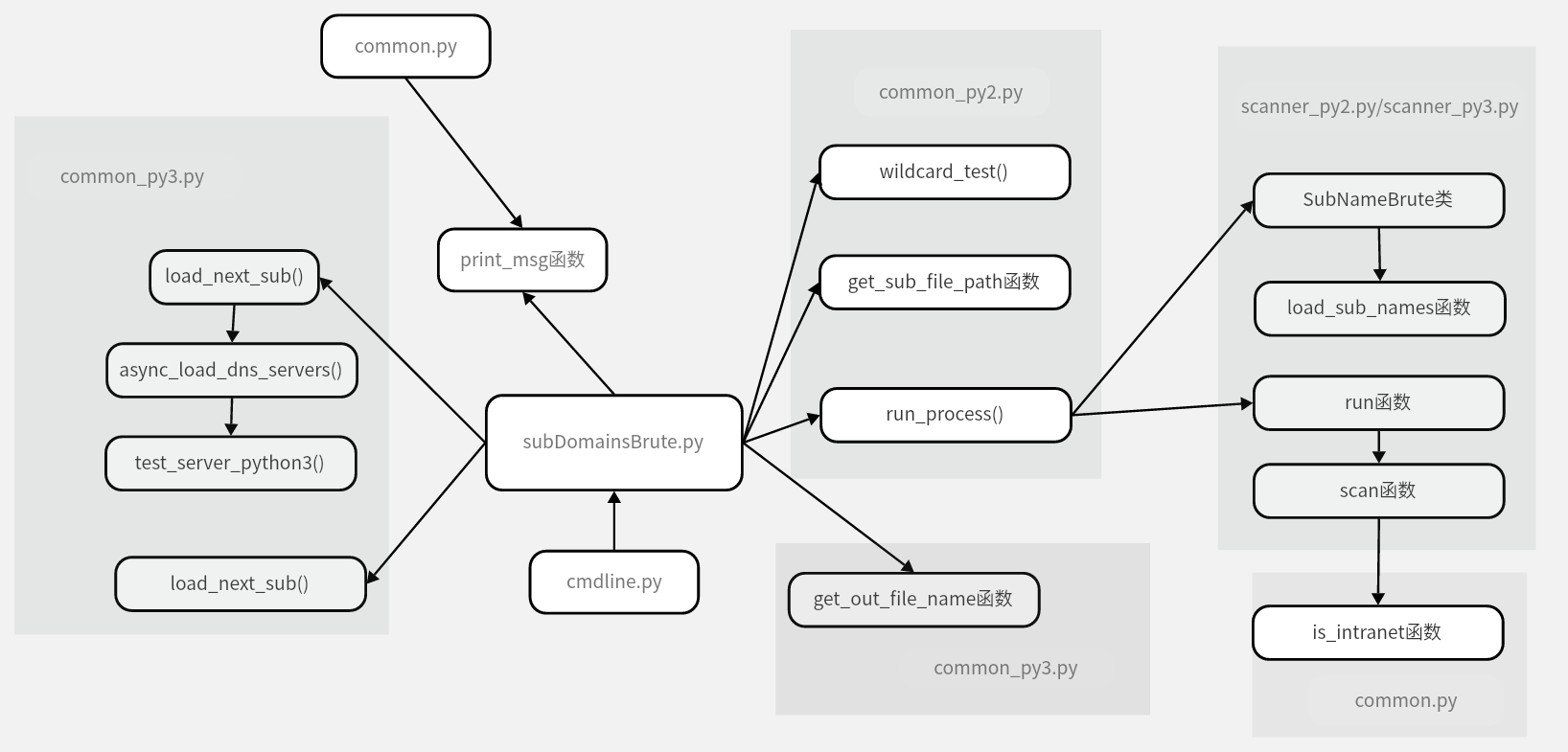
參考:
SubDomainsBrute原始碼分析 | 碼農家園 (codenong.com)