每日一題:吃透大檔案上傳問題(附可執行的前後端原始碼)
大檔案上傳
前言
在日常開發中,檔案上傳是常見的操作之一。檔案上傳技術使得使用者可以方便地將本地檔案上傳到Web伺服器上,這在許多場景下都是必需的,比如網路硬碟上傳、頭像上傳等。
但是當我們需要上傳比較大的檔案的時候,容易碰到以下問題:
- 上傳時間比較久
- 中間一旦出錯就需要重新上傳
- 一般伺服器端會對檔案的大小進行限制
這兩個問題會導致上傳時候的使用者體驗是很不好的,針對存在的這些問題,我們可以通過分片上傳來解決,這節課我們就在學習下什麼是切片上傳,以及怎麼實現切片上傳。
原理介紹
分片上傳的原理就像是把一個大蛋糕切成小塊一樣。
首先,我們將要上傳的大檔案分成許多小塊,每個小塊大小相同,比如每塊大小為2MB。然後,我們逐個上傳這些小塊到伺服器。上傳的時候,可以同時上傳多個小塊,也可以一個一個地上傳。上傳每個小塊後,伺服器會儲存這些小塊,並記錄它們的順序和位置資訊。
所有小塊上傳完成後,伺服器會把這些小塊按照正確的順序拼接起來,還原成完整的大檔案。最後,我們就成功地上傳了整個大檔案。
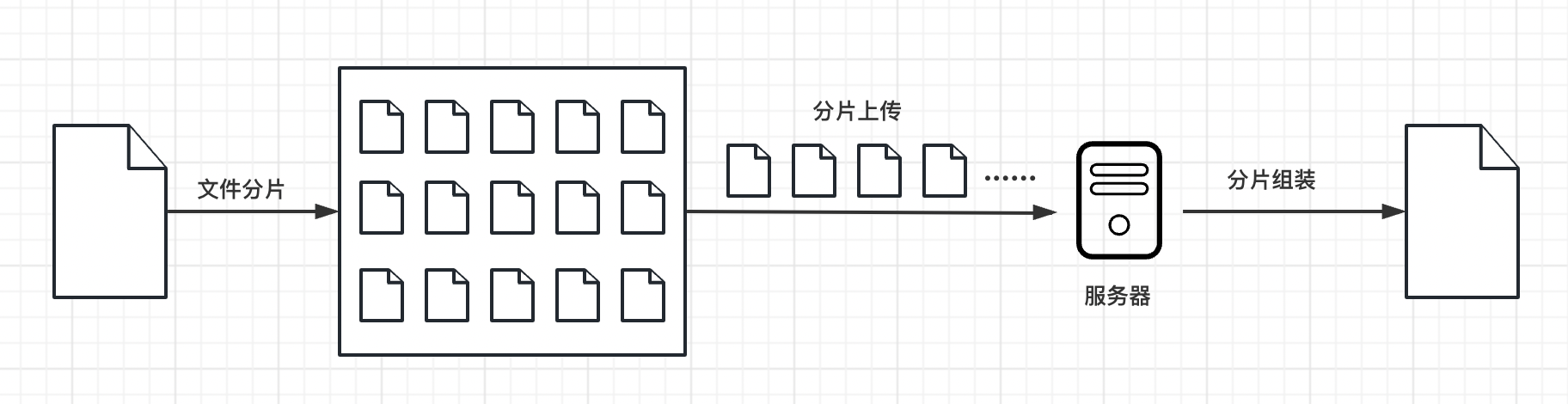
分片上傳的好處在於它可以減少上傳失敗的風險。如果在上傳過程中出現了問題,只需要重新上傳出錯的那個小塊,而不需要重新上傳整個大檔案。
此外,分片上傳還可以加快上傳速度。因為我們可以同時上傳多個小塊,充分利用網路的頻寬。這樣就能夠更快地完成檔案的上傳過程。
實現
專案搭建
要實現大檔案上傳,還需要後端的支援,所以我們就用nodejs來寫後端程式碼。
前端:vue3 + vite
後端:express 框架,用到的工具包:multiparty、fs-extra、cors、body-parser、nodemon
讀取檔案
通過監聽 input 的 change 事件,當選取了本地檔案後,可以在回撥函數中拿到對應的檔案:
const handleUpload = (e: Event) => {
const files = (e.target as HTMLInputElement).files
if (!files) {
return
}
// 讀取選擇的檔案
console.log(files[0]);
}
檔案分片
檔案分片的核心是用Blob物件的slice方法,我們在上一步獲取到選擇的檔案是一個File物件,它是繼承於Blob,所以我們就可以用slice方法對檔案進行分片,用法如下:
let blob = instanceOfBlob.slice([start [, end [, contentType]]]};
start 和 end 代表 Blob 裡的下標,表示被拷貝進新的 Blob 的位元組的起始位置和結束位置。contentType 會給新的 Blob 賦予一個新的檔案型別,在這裡我們用不到。接下來就來使用slice方法來實現下對檔案的分片。
const createFileChunks = (file: File) => {
const fileChunkList = []
let cur = 0
while (cur < file.size) {
fileChunkList.push({
file: file.slice(cur, cur + CHUNK_SIZE),
})
cur += CHUNK_SIZE // CHUNK_SIZE為分片的大小
}
return fileChunkList
}
hash計算
先來思考一個問題,在向伺服器上傳檔案時,怎麼去區分不同的檔案呢?如果根據檔名去區分的話可以嗎?
答案是不可以,因為檔名我們可以是隨便修改的,所以不能根據檔名去區分。但是每一份檔案的檔案內容都不一樣,我們可以根據檔案的內容去區分,具體怎麼做呢?
可以根據檔案內容生產一個唯一的 hash 值,大家應該都見過用 webpack 打包出來的檔案的檔名都有一串不一樣的字串,這個字串就是根據檔案的內容生成的 hash 值,檔案內容變化,hash 值就會跟著發生變化。我們在這裡,也可以用這個辦法來區分不同的檔案。而且通過這個辦法,我們還可以實現秒傳的功能,怎麼做呢?
就是伺服器在處理上傳檔案的請求的時候,要先判斷下對應檔案的 hash 值有沒有記錄,如果A和B先後上傳一份內容相同的檔案,所以這兩份檔案的 hash 值是一樣的。當A上傳的時候會根據檔案內容生成一個對應的 hash 值,然後在伺服器上就會有一個對應的檔案,B再上傳的時候,伺服器就會發現這個檔案的 hash 值之前已經有記錄了,說明之前已經上傳過相同內容的檔案了,所以就不用處理B的這個上傳請求了,給使用者的感覺就像是實現了秒傳。
那麼怎麼計算檔案的hash值呢?可以通過一個工具:spark-md5,所以我們得先安裝它。
在上一步獲取到了檔案的所有切片,我們就可以用這些切片來算該檔案的 hash 值,但是如果一個檔案特別大,每個切片的所有內容都參與計算的話會很耗時間,所有我們可以採取以下策略:
-
第一個和最後一個切片的內容全部參與計算
-
中間剩餘的切片我們分別在前面、後面和中間取2個位元組參與計算
這樣就既能保證所有的切片參與了計算,也能保證不耗費很長的時間
/**
* 計算檔案的hash值,計算的時候並不是根據所用的切片的內容去計算的,那樣會很耗時間,我們採取下面的策略去計算:
* 1. 第一個和最後一個切片的內容全部參與計算
* 2. 中間剩餘的切片我們分別在前面、後面和中間取2個位元組參與計算
* 這樣做會節省計算hash的時間
*/
const calculateHash = async (fileChunks: Array<{file: Blob}>) => {
return new Promise(resolve => {
const spark = new sparkMD5.ArrayBuffer()
const chunks: Blob[] = []
fileChunks.forEach((chunk, index) => {
if (index === 0 || index === fileChunks.length - 1) {
// 1. 第一個和最後一個切片的內容全部參與計算
chunks.push(chunk.file)
} else {
// 2. 中間剩餘的切片我們分別在前面、後面和中間取2個位元組參與計算
// 前面的2位元組
chunks.push(chunk.file.slice(0, 2))
// 中間的2位元組
chunks.push(chunk.file.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2))
// 後面的2位元組
chunks.push(chunk.file.slice(CHUNK_SIZE - 2, CHUNK_SIZE))
}
})
const reader = new FileReader()
reader.readAsArrayBuffer(new Blob(chunks))
reader.onload = (e: Event) => {
spark.append(e?.target?.result as ArrayBuffer)
resolve(spark.end())
}
})
}
檔案上傳
前端實現
前面已經完成了上傳的前置操作,接下來就來看下如何去上傳這些切片。
我們以1G的檔案來分析,假如每個分片的大小為1M,那麼總的分片數將會是1024個,如果我們同時傳送這1024個分片,瀏覽器肯定處理不了,原因是切片檔案過多,瀏覽器一次性建立了太多的請求。這是沒有必要的,拿 chrome 瀏覽器來說,預設的並行數量只有 6,過多的請求並不會提升上傳速度,反而是給瀏覽器帶來了巨大的負擔。因此,我們有必要限制前端請求個數。
怎麼做呢,我們要建立最大並行數的請求,比如6個,那麼同一時刻我們就允許瀏覽器只傳送6個請求,其中一個請求有了返回的結果後我們再發起一個新的請求,依此類推,直至所有的請求傳送完畢。
上傳檔案時一般還要用到 FormData 物件,需要將我們要傳遞的檔案還有額外資訊放到這個 FormData 物件裡面。
const uploadChunks = async (fileChunks: Array<{file: Blob}>) => {
const data = fileChunks.map(({ file }, index) => ({
fileHash: fileHash.value,
index,
chunkHash: `${fileHash.value}-${index}`,
chunk: file,
size: file.size,
}))
const formDatas = data
.map(({ chunk, chunkHash }) => {
const formData = new FormData()
// 切片檔案
formData.append('chunk', chunk)
// 切片檔案hash
formData.append('chunkHash', chunkHash)
// 大檔案的檔名
formData.append('fileName', fileName.value)
// 大檔案hash
formData.append('fileHash', fileHash.value)
return formData
})
let index = 0;
const max = 6; // 並行請求數量
const taskPool: any = [] // 請求佇列
while(index < formDatas.length) {
const task = fetch('http://127.0.0.1:3000/upload', {
method: 'POST',
body: formDatas[index],
})
task.then(() => {
taskPool.splice(taskPool.findIndex((item: any) => item === task))
})
taskPool.push(task);
if (taskPool.length === max) {
// 當請求佇列中的請求數達到最大並行請求數的時候,得等之前的請求完成再回圈下一個
await Promise.race(taskPool)
}
index ++
percentage.value = (index / formDatas.length * 100).toFixed(0)
}
await Promise.all(taskPool)
}
後端實現
後端我們處理檔案時需要用到 multiparty 這個工具,所以也是得先安裝,然後再引入它。
我們在處理每個上傳的分片的時候,應該先將它們臨時存放到伺服器的一個地方,方便我們合併的時候再去讀取。為了區分不同檔案的分片,我們就用檔案對應的那個hash為資料夾的名稱,將這個檔案的所有分片放到這個資料夾中。
// 所有上傳的檔案存放到該目錄下
const UPLOAD_DIR = path.resolve(__dirname, 'uploads');
// 處理上傳的分片
app.post('/upload', async (req, res) => {
const form = new multiparty.Form();
form.parse(req, async function (err, fields, files) {
if (err) {
res.status(401).json({
ok: false,
msg: '上傳失敗'
});
}
const chunkHash = fields['chunkHash'][0]
const fileName = fields['fileName'][0]
const fileHash = fields['fileHash'][0]
// 儲存切片的臨時資料夾
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
// 切片目錄不存在,則建立切片目錄
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir)
}
const oldPath = files.chunk[0].path;
// 把檔案切片移動到我們的切片資料夾中
await fse.move(oldPath, path.resolve(chunkDir, chunkHash))
res.status(200).json({
ok: true,
msg: 'received file chunk'
});
});
});
寫完前後端程式碼後就可以來試下看看檔案能不能實現切片的上傳,如果沒有錯誤的話,我們的 uploads 資料夾下應該就會多一個資料夾,這個資料夾裡面就是儲存的所有檔案的分片了。
檔案合併
上一步我們已經實現了將所有切片上傳到伺服器了,上傳完成之後,我們就可以將所有的切片合併成一個完整的檔案了,下面就一塊來實現下。
前端實現
前端只需要向伺服器傳送一個合併的請求,並且為了區分要合併的檔案,需要將檔案的hash值給傳過去
/**
* 發請求通知伺服器,合併切片
*/
const mergeRequest = () => {
// 傳送合併請求
fetch('http://127.0.0.1:3000/merge', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
size: CHUNK_SIZE,
fileHash: fileHash.value,
fileName: fileName.value,
}),
})
.then((response) => response.json())
.then(() => {
alert('上傳成功')
})
}
後端實現
在之前已經可以將所有的切片上傳到伺服器並儲存到對應的目錄裡面去了,合併的時候需要從對應的資料夾中獲取所有的切片,然後利用檔案的讀寫操作,就可以實現檔案的合併了。合併完成之後,我們將生成的檔案以hash值命名存放到對應的位置就可以了。
// 提取檔案字尾名
const extractExt = filename => {
return filename.slice(filename.lastIndexOf('.'), filename.length)
}
/**
* 讀的內容寫到writeStream中
*/
const pipeStream = (path, writeStream) => {
return new Promise((resolve, reject) => {
// 建立可讀流
const readStream = fse.createReadStream(path)
readStream.on('end', async () => {
fse.unlinkSync(path)
resolve()
})
readStream.pipe(writeStream)
})
}
/**
* 合併資料夾中的切片,生成一個完整的檔案
*/
async function mergeFileChunk(filePath, fileHash, size) {
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
const chunkPaths = await fse.readdir(chunkDir)
// 根據切片下標進行排序
// 否則直接讀取目錄的獲得的順序可能會錯亂
chunkPaths.sort((a, b) => {
return a.split('-')[1] - b.split('-')[1]
})
const list = chunkPaths.map((chunkPath, index) => {
return pipeStream(
path.resolve(chunkDir, chunkPath),
fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size
})
)
})
await Promise.all(list)
// 檔案合併後刪除儲存切片的目錄
fse.rmdirSync(chunkDir)
}
// 合併檔案
app.post('/merge', async (req, res) => {
const { fileHash, fileName, size } = req.body
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)
// 如果大檔案已經存在,則直接返回
if (fse.existsSync(filePath)) {
res.status(200).json({
ok: true,
msg: '合併成功'
});
return
}
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
// 切片目錄不存在,則無法合併切片,報異常
if (!fse.existsSync(chunkDir)) {
res.status(200).json({
ok: false,
msg: '合併失敗,請重新上傳'
});
return
}
await mergeFileChunk(filePath, fileHash, size)
res.status(200).json({
ok: true,
msg: '合併成功'
});
});
到這裡,我們就已經實現了大檔案的分片上傳的基本功能了,但是我們沒有考慮到如果上傳相同的檔案的情況,而且如果中間網路斷了,我們就得重新上傳所有的分片,這些情況在大檔案上傳中也都需要考慮到,下面,我們就來解決下這兩個問題。
秒傳&斷點續傳
我們在上面有提到,如果內容相同的檔案進行hash計算時,對應的hash值應該是一樣的,而且我們在伺服器上給上傳的檔案命名的時候就是用對應的hash值命名的,所以在上傳之前是不是可以加一個判斷,如果有對應的這個檔案,就不用再重複上傳了,直接告訴使用者上傳成功,給使用者的感覺就像是實現了秒傳。接下來,就來看下如何實現的。
前端實現
前端在上傳之前,需要將對應檔案的hash值告訴伺服器,看看伺服器上有沒有對應的這個檔案,如果有,就直接返回,不執行上傳分片的操作了。
/**
* 驗證該檔案是否需要上傳,檔案通過hash生成唯一,改名後也是不需要再上傳的,也就相當於秒傳
*/
const verifyUpload = async () => {
return fetch('http://127.0.0.1:3000/verify', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
fileName: fileName.value,
fileHash: fileHash.value
})
})
.then((response) => response.json())
.then((data) => {
return data; // data中包含對應的表示伺服器上有沒有該檔案的查詢結果
});
}
// 點選上傳事件
const handleUpload = async (e: Event) => {
// ...
// uploadedList已上傳的切片的切片檔名稱
const res = await verifyUpload()
const { shouldUpload } = res.data
if (!shouldUpload) {
// 伺服器上已經有該檔案,不需要上傳
alert('秒傳:上傳成功')
return;
}
// 伺服器上不存在該檔案,繼續上傳
uploadChunks(fileChunks)
}
後端實現
因為我們在合併檔案時,檔名時根據該檔案的hash值命名的,所以只需要看看伺服器上有沒有對應的這個hash值的那個檔案就可以判斷了。
// 根據檔案hash驗證檔案有沒有上傳過
app.post('/verify', async (req, res) => {
const { fileHash, fileName } = req.body
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)
if (fse.existsSync(filePath)) {
// 檔案存在伺服器中,不需要再上傳了
res.status(200).json({
ok: true,
data: {
shouldUpload: false,
}
});
} else {
// 檔案不在伺服器中,就需要上傳
res.status(200).json({
ok: true,
data: {
shouldUpload: true,
}
});
}
});
完成上面的步驟後,當我們再上傳相同的檔案,即使改了檔名,也會提示我們秒傳成功了,因為伺服器上已經有對應的那個檔案了。
上面我們解決了重複上傳的檔案,但是對於網路中斷需要重新上傳的問題沒有解決,那該如何解決呢?
如果我們之前已經上傳了一部分分片了,我們只需要再上傳之前拿到這部分分片,然後再過濾掉是不是就可以避免去重複上傳這些分片了,也就是隻需要上傳那些上傳失敗的分片,所以,再上傳之前還得加一個判斷。
前端實現
我們還是在那個 verify 的介面中去獲取已經上傳成功的分片,然後在上傳分片前進行一個過濾
const uploadChunks = async (fileChunks: Array<{file: Blob}>, uploadedList: Array<string>) => {
const formDatas = fileChunks
.filter((chunk, index) => {
// 過濾伺服器上已經有的切片
return !uploadedList.includes(`${fileHash.value}-${index}`)
})
.map(({ file }, index) => {
const formData = new FormData()
// 切片檔案
formData.append('file', file)
// 切片檔案hash
formData.append('chunkHash', `${fileHash.value}-${index}`)
// 大檔案的檔名
formData.append('fileName', fileName.value)
// 大檔案hash
formData.append('fileHash', fileHash.value)
return formData
})
// ...
}
後端實現
只需要在 /verify 這個介面中加上已經上傳成功的所有切片的名稱就可以,因為所有的切片都存放在以檔案的hash值命名的那個資料夾,所以需要讀取這個資料夾中所有的切片的名稱就可以。
/**
* 返回已經上傳切片名
* @param {*} fileHash
* @returns
*/
const createUploadedList = async fileHash => {
return fse.existsSync(path.resolve(UPLOAD_DIR, fileHash))
? await fse.readdir(path.resolve(UPLOAD_DIR, fileHash)) // 讀取該資料夾下所有的檔案的名稱
: []
}
// 根據檔案hash驗證檔案有沒有上傳過
app.post('/verify', async (req, res) => {
const { fileHash, fileName } = req.body
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)
if (fse.existsSync(filePath)) {
// 檔案存在伺服器中,不需要再上傳了
res.status(200).json({
ok: true,
data: {
shouldUpload: false,
}
});
} else {
// 檔案不在伺服器中,就需要上傳,並且返回伺服器上已經存在的切片
res.status(200).json({
ok: true,
data: {
shouldUpload: true,
uploadedList: await createUploadedList(fileHash)
}
});
}
});