一款釋放資料價值的專案,開源了!

在巨量資料和 AI 的時代背景下,資料已經成為了重要財富,大到政務資料、企業核心資料,小到個人資訊、銀行卡餘額,這些資料無一例外都是「隱私資料」,如果在使用和流轉時發生洩漏都會造成巨大的損失。
那有沒有什麼方法,可以在不暴露資料隱私的前提下,讓資料流動起來發揮更大的價值呢?在這個問題的驅使下我們找到了今天的主角——隱私計算。
一、什麼是隱私計算?
隱私計算是指在不洩露資料本身的情況下,實現資料分析和計算的技術,具有「資料可用不可見」的特點,讓資料安全合規地流動起來。
下面用一個經典的百萬富翁問題,來幫助理解什麼是「資料可用不見」。

假設有兩個百萬富翁,他們都想知道誰更富有,但又不想讓對方或者第三方,知道自己具體有多少錢。
- 資料本身:具體的財富值(資料)
- 計算:比大小(可用)
- 不洩露:對方或第三方(不可見)
按照常理,進行比大小的計算是需要知道兩個數是多少,才能比較大小,但這裡不知道具體的數位。所以上面這個問題在普通人看來是無解的,但其實這是一個密碼學問題,也被稱為「多方安全計算」(MPC)問題,由姚期智院士在 1982 提出,並給出瞭解決方案——混淆電路,實現了資料的可用不可見。
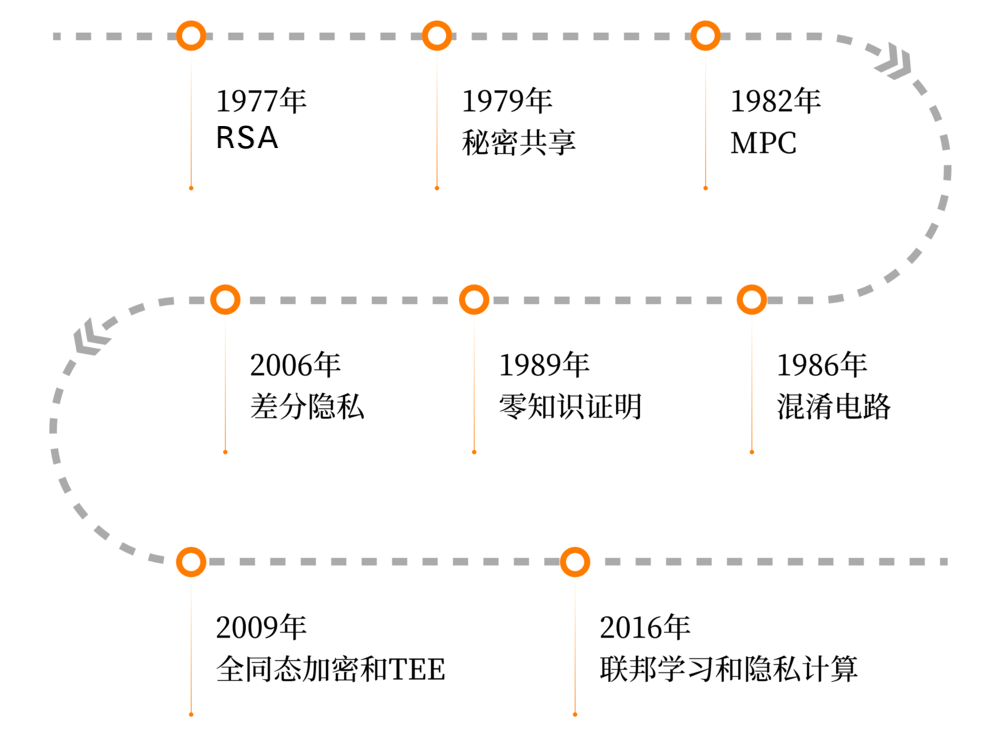
從隱私計算的技術發展時間線,我們不難看出隱私計算還是一個比較「新」的技術。隨著零知識證明、差分隱私、全同態加密、聯邦學習等技術的相繼問世,目前已形成三大應用技術路線多方安全計算(MPC)、聯邦學習(FL)、可信執行環境(TEE),隱私計算作為資料流通的重要技術已應用於金融、醫療、政務、廣告等領域。
- 金融:聯合反洗錢、銀(行)證(券)資料共用等
- 醫療和健康:流行病接觸者追蹤等
- 政務:案件調查、人口普查等
隨著歐盟 2018 年生效的《通用資料保護法案》,Google、Facebook 等科技巨頭都收到了鉅額罰單。近兩年,我國也相繼出臺了 《資料安全法》 和 《個人資訊保護法》。因此,如何讓資料安全地流通起來,已經不再是一道附加題而是一道必答題。
如果我們把上面的「百萬富翁」換成企業/機構的話,就可以很容易得出隱私計算技術就是資料安全流通的答案