線上問診 Python、FastAPI、Neo4j — 建立藥品節點
2023-09-12 18:01:17
線上問診 Python、FastAPI、Neo4j — 建立節點
Neo4j 節點的標籤可以理解為 Java 中的實體。
根據常規流程:首先有什麼症狀,做哪些對應的檢查,根據檢查診斷什麼疾病,需要用什麼藥物治療,服藥期間要注意哪些飲食,需要做哪些執行
線上問診大概建立:症狀、檢查專案、疾病、藥品、飲食、運動 這幾個物件
前提條件
基於 Python FastAPI 獲取 Neo4j 資料 :https://www.cnblogs.com/vipsoft/p/17687070.html
建立節點 Demo
通過 這個Demo 理解 Neo4j Driver for Python ,建立節點
test_create_node.py
import logging
from utils.neo4j_provider import driver
logging.root.setLevel(logging.INFO)
''' 建立知識圖譜實體節點型別schema '''
def create_drug(tx, name):
query = (
"CREATE (n:Drug {name: $name})"
"RETURN id(n)"
)
result = tx.run(query, name=name)
return result.single()[0]
if __name__ == "__main__":
with driver.session() as session:
session.execute_write(create_drug, "扶他林")
driver.close()
logging.info("建立成功")
驗證
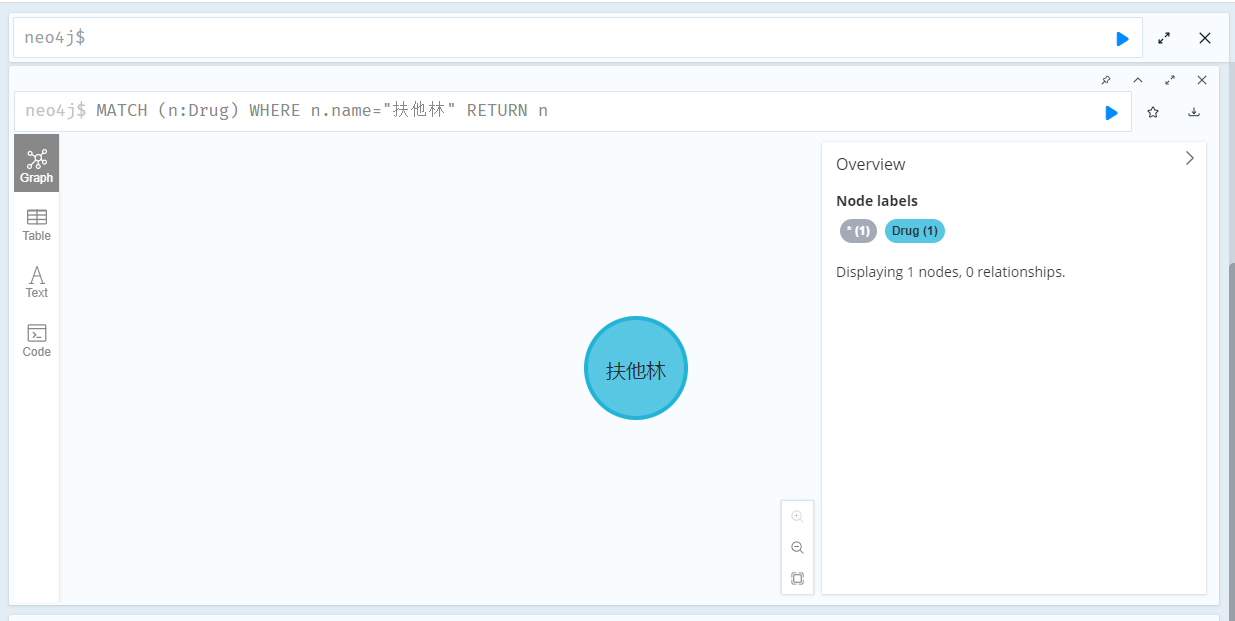
# 檢視建立後的結果
MATCH (n:Drug) WHERE n.name="扶他林" RETURN n
# 刪除節點
MATCH (n:Drug) WHERE n.name="扶他林" DELETE n
準備資料
採用 CSV 格式,CSV 是一種純文字形式儲存資料,好處可以記事本開啟預覽,也可用 excel 開啟,將來資料來源都過爬蟲或者NLP處理,比處理Excel要方便得多
Excel編輯 CSV 就亂碼了,不知道為啥

建立藥品標籤節點
建立藥品標籤節點
build_drugs.py
import logging
import csv
from utils.neo4j_provider import driver
logging.root.setLevel(logging.INFO)
# 從CSV 中讀取資料,並生成 CQL
def generate_cql() -> str:
with open('drugs_data.csv', 'r', encoding='utf-8') as csv_file:
csv_reader = csv.DictReader(csv_file)
cql = ""
for idx, row in enumerate(csv_reader):
cql += """(drug%s:Drug {name: "%s",generic_name: "%s",english_name: "%s",indications: "%s",contraindications: "%s",adverse_reactions: "%s",toxicology: "%s",attention: "%s",usage_dosage: "%s",images_url: "%s"}),\r\n""" \
% (idx, row['商品名'], row['通用名'], row['英文名稱'], row['適應症'], row['禁忌'], row['不良反應'], row['藥理毒理'], row['注意事項'], row['用法用量'], row['圖片地址'])
return "CREATE %s" % (cql.rstrip(",\r\n"))
data = [row for row in csv_reader]
# 執行寫的命令
def execute_write(cql):
with driver.session() as session:
session.execute_write(execute_cql, cql)
driver.close()
# 執行 CQL 語句
def execute_cql(tx, cql):
tx.run(cql)
# 清除 Drug 標籤資料
def clear_data():
cql = "MATCH (n:Drug) DETACH DELETE n"
execute_write(cql)
if __name__ == "__main__":
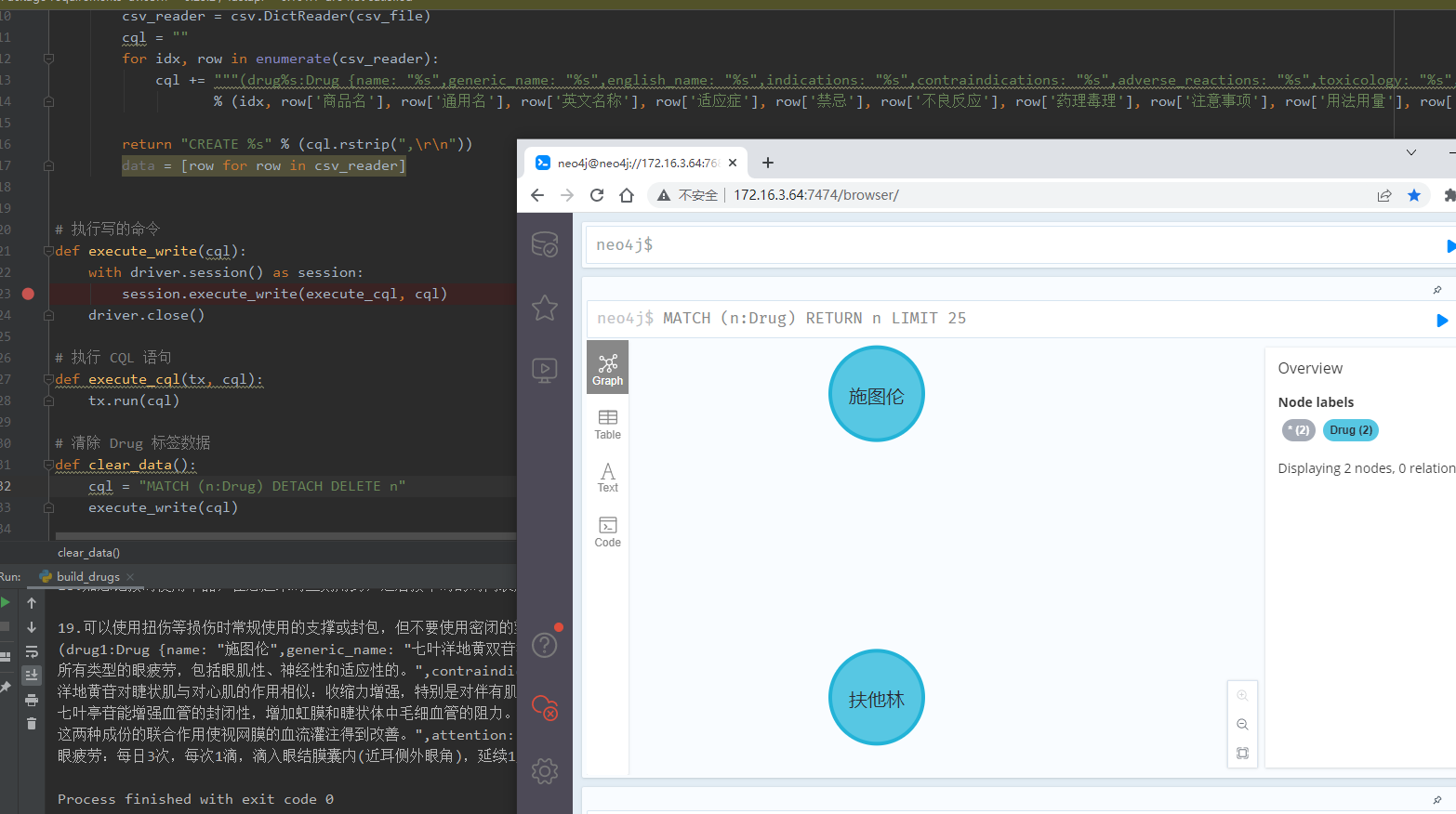
clear_data()
cql = generate_cql()
print(cql)
execute_write(cql)
本文來自部落格園,作者:VipSoft 轉載請註明原文連結:https://www.cnblogs.com/vipsoft/p/17687480.html