xv6 程序切換中的鎖:MIT6.s081/6.828 lectrue12:Coordination 以及 Lab6 Thread 心得
引言
這節課和上一節xv6程序切換是一個完整的的程序切換專題,上一節主要討論程序切換過程中的細節,而這一節主要討論程序切換過程中鎖的使用,所以本節的兩大關鍵詞就是"Coordination"(協調)和 "lost wakeup"
Coordination 就是有關出讓CPU,直到等待的事件發生再恢復執行。人們發明了很多不同的 Coordination 的實現方式,但是與許多Unix風格作業系統一樣,xv6 使用的是 Sleep&Wakeup 這種方式。而幾乎所有的Coordination機制都需要處理 lost wakeup 的問題。
"busy wait" vs "coordination"
busy wait 其實和 lectrue10中講過的 spin lock 思想是一樣的,在一個程序執行期間,可能會遇到一寫需要等待的場景:
- 等待從磁碟上讀取資料
- 讀取 pipe 中的資料,但是 pipe 為空了,需要等待 pipe 中再次來資料
- unix 中經典的 wait 函數(父程序使用 wait 函數來等待子程序 exit)
典型的 busy wait 模型如下:
while(事件未發生) {
; // 空語句,表示事件未發生就一直迴圈等待
}
busy wait 很明顯是一種"笨辦法",因為如果等待的事件不能很快發生,那麼該程序在等待期間程序還是一直佔用著 cpu,直到期待的事件發生,這對於追求高效的計算機來說有些無法忍受,畢竟現代的主流計算機在 1ms 內都可以執行上百萬條指令。
與 busy wait 相對的就是 Coordination,即程序發現自己在等待,就讓主動出讓 cpu,當等待的事件發生時,再恢復執行。Coordination 是一個很大的話題,這一節只討論主流的一種實現 Coordination 的方式:Sleep&Wakeup
所以這裡的關鍵技術點有三個:
- 怎麼發現自己在等待?
- 怎麼出讓?
- 怎麼恢復執行?
會在下面給出範例以及說明。
一個設計良好的 Sleep&Wakeup 範例
以 Robert 教授重寫的uartwrite()和 uartintr()函數為例:

如果需要往 console 中寫字元,需要呼叫uartwrite()函數,這個函數會在迴圈中將 buf 中的字元一個一個的向UART硬體寫入,UART硬體一次只能接受一個字元的傳輸,所以在兩個字元之間的等待時間可能會很長,所以這裡就採用了 sleep&wakeup 的方式:
- 先將 buf 中的一個字元寫入THR 暫存器中,然後將標誌位 tx_done 置為 0(初始值為 1),開始迴圈,檢查 tx_done 是否為 1(傳送完成),若未傳送完成則 sleep,出讓 cpu
- THR 暫存器中的資料會由 uart 硬體寫入到 console 中,uart 硬體會在完成傳輸一個字元后,觸發中斷,從而進入中斷處理程式,在中斷處理程式中將 tx_done 設定為完成,並且 wakeup 之前
uartwrite()中 sleep 的程序 - 接著寫下一個字元
以上就是 Sleep&Wakeup 工作的方式,這裡需要注意 sleep 和 wakeup 共同的引數:tx_chan,這是一個64bit的值,用來標識這個 sleep 以及 wakeup 是一對,或者說 wakeup 會喚醒具有相同標識的 sleep。
Sleep&Wakeup 原理
sleep 和 wakeup 的原理也很簡單,尤其是學了上一節課程之後:sleep 修改程序的狀態為 SLEEPING,然後將程序打上 sleep channel 的標籤,最後呼叫 sched 切換到排程器執行緒,由排程器選擇其他合適的程序執行。
// Atomically release lock and sleep on chan.
// Reacquires lock when awakened.
void
sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc();
// Must acquire p->lock in order to
// change p->state and then call sched.
// Once we hold p->lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup locks p->lock),
// so it's okay to release lk.
acquire(&p->lock); //DOC: sleeplock1
release(lk);
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
// Tidy up.
p->chan = 0;
// Reacquire original lock.
release(&p->lock);
acquire(lk);
}
wakeup 就更簡單了,根據程序的 state 以及 sleep channel 的數值就可以尋找到之前 sleep 的程序,將其狀態修改為 RUNABLE,以便排程器隨時呼叫。
// Wake up all processes sleeping on chan.
// Must be called without any p->lock.
void
wakeup(void *chan)
{
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
if(p != myproc()){
acquire(&p->lock);
if(p->state == SLEEPING && p->chan == chan) {
p->state = RUNNABLE;
}
release(&p->lock);
}
}
}
lost wakeup
注意上一節的 sleep 函數有兩個引數,一個是 void *chan,也就是標識 sleep-wakeup 對的 slep channel,另一個引數是一把鎖,:struct spinlock *lk。第一個引數好理解,必須要有一個標識來把 sleep 和 wakeup 對應起來,以確保 wakeup 喚醒的是爭取的程序;但是第二個引數看上去就有點"醜陋了",怎麼會把鎖傳入 sleep 函數中呢?
要解釋這件事情,最好是使用反證法,假如我們的 sleep 函數的引數中沒有這個鎖,程式執行是否會出問題?答案是肯定的,而且出的問題就是 lost wakeup。
通俗第解釋一下什麼是 lost wakeup,比如一個程序在 sleep channel 為 233 的數值上 sleep 了,然後呼叫函數 wakeup(233),就可以喚醒這個特定的程序,這是正常的 sleep-wakeup 使用方式,但是如果由於編碼的疏漏,造成 wakeup(233)在 sleep(233) 之前執行了,這樣 wakeup(233)不會喚醒任何程序,因為對應的程序還沒有 sleep,之後再執行 sleep(233) ,但是這一次,不會有 wakeup 來喚醒了,該程序就會一直 sleep,這就是 lost wakeup 的問題
首先看一下原始的、正確的 uartwrite()函數和 uartintr()函數:
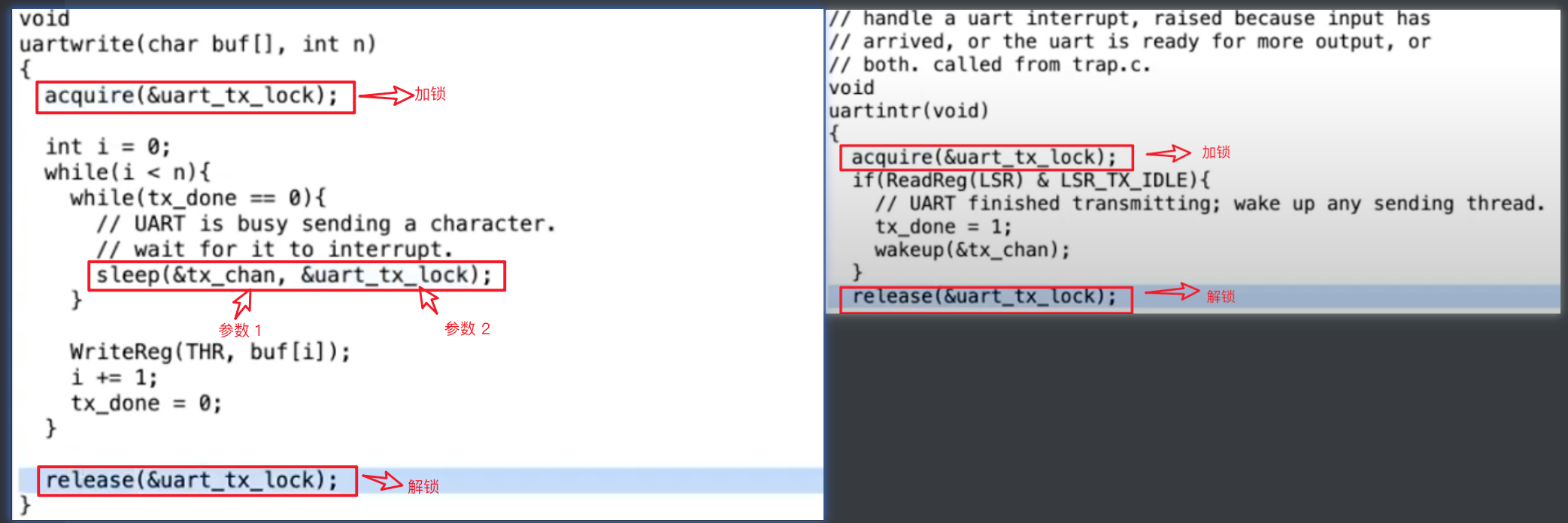
接著,我們想象去掉 sleep 函數的中的 lock 引數,這個程式碼要怎麼修改:
- 首先,鎖肯定還是需要的,因為
uartwrite()函數和uartintr()函數都操作了變數 tx_done,而這兩個函數是可能被不同的 cpu core 執行的,所以為了保護共用資料的正確性,鎖還是需要的 - 其次,需要在
uartwrite()函數中、sleep 函數之前新增解鎖語句,因為如果 sleep 函數之前沒有解鎖的語句的話,一旦執行uartwrite函數的程序帶著鎖 sleep 了,即使之後成功寫入資料、發生了中斷,也會因為沒辦法獲取鎖而卡在uartintr()函數開頭,從而無法修改tx_done的值為 1,也無法 wakeup 之前 sleep 的程序,所以還是需要在uartwrite()函數中新增加解鎖語句,修改後的uartwrite()函數程式碼如下:
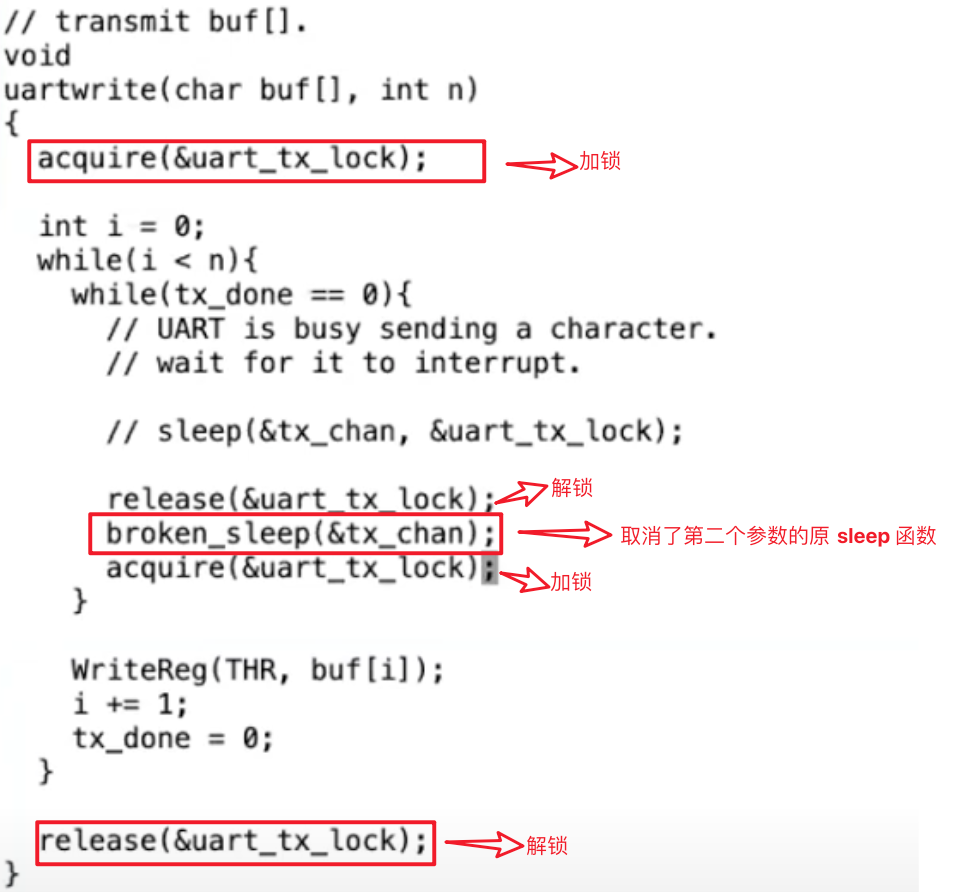
好了,現在我們為了優雅,或者說為了探究 sleep 函數為什麼要傳入 lock 引數,把程式碼修改為了更容易理解的版本,那麼現在問題就出來了,為什麼會造成 lost wakeup 的問題呢?
比起復雜的語言解釋,下面這幅圖更加清晰,如果按照圖中 1~14 的順序執行程式碼,就會發生 lost wakeup 的情況,因為第 1 步 release 解鎖後,可能立即發生中斷,然後執行uartintr()函數,並執行 wakeup,所以這裡 wakeup 就會在第 5 步執行,而 broken_sleep 則在第 11 步執行,wakeup 發生在了 sleep 之前,即 lost wakeup 的情況:

所以這也回答了為什麼 sleep 函數第 2 個引數是 lock,因為不傳入這個 lock,在 sleep 外加解鎖的話,會發生 lost wakeup 的情況。
解決 lost wakeup
明白了 lost wakeup 是如何發生的,結局方案似乎就有一些眉目了,我們需要把 lock 傳入 sleep 函數中,想一個辦法確保 sleep 發生在 wakeup 之前,現在來仔細分析" sleep 發生在 wakeup 之前 "的含義,我們之所以想讓 sleep 發生在 wakeup 之前,是因為可能存在以下執行順序:
- sleep 中先
release(tx_lock) uartintr()中acquire(tx_lock),然後呼叫 wakeup 修改p->state = RUNNABLE- sleep 中繼續
p->chan = chan; p->state = SLEEPING
由於 p->state = RUNNABLE發生在 p->chan = chan; p->state = SLEEPING 之前,所以就有了 lost wakeup,所以現在的問題就轉換成了怎麼保證以上三步驟中第 1 步和第 3 步之間的原子性;或者說保證共用資料 p->state的安全性,答案就很明顯了,我們還需要一把鎖,而且這把鎖 xv6 已經實現了,就是每個程序自帶的程序鎖p->lock,用來保護程序自身的資料安全,加鎖方式見下圖:
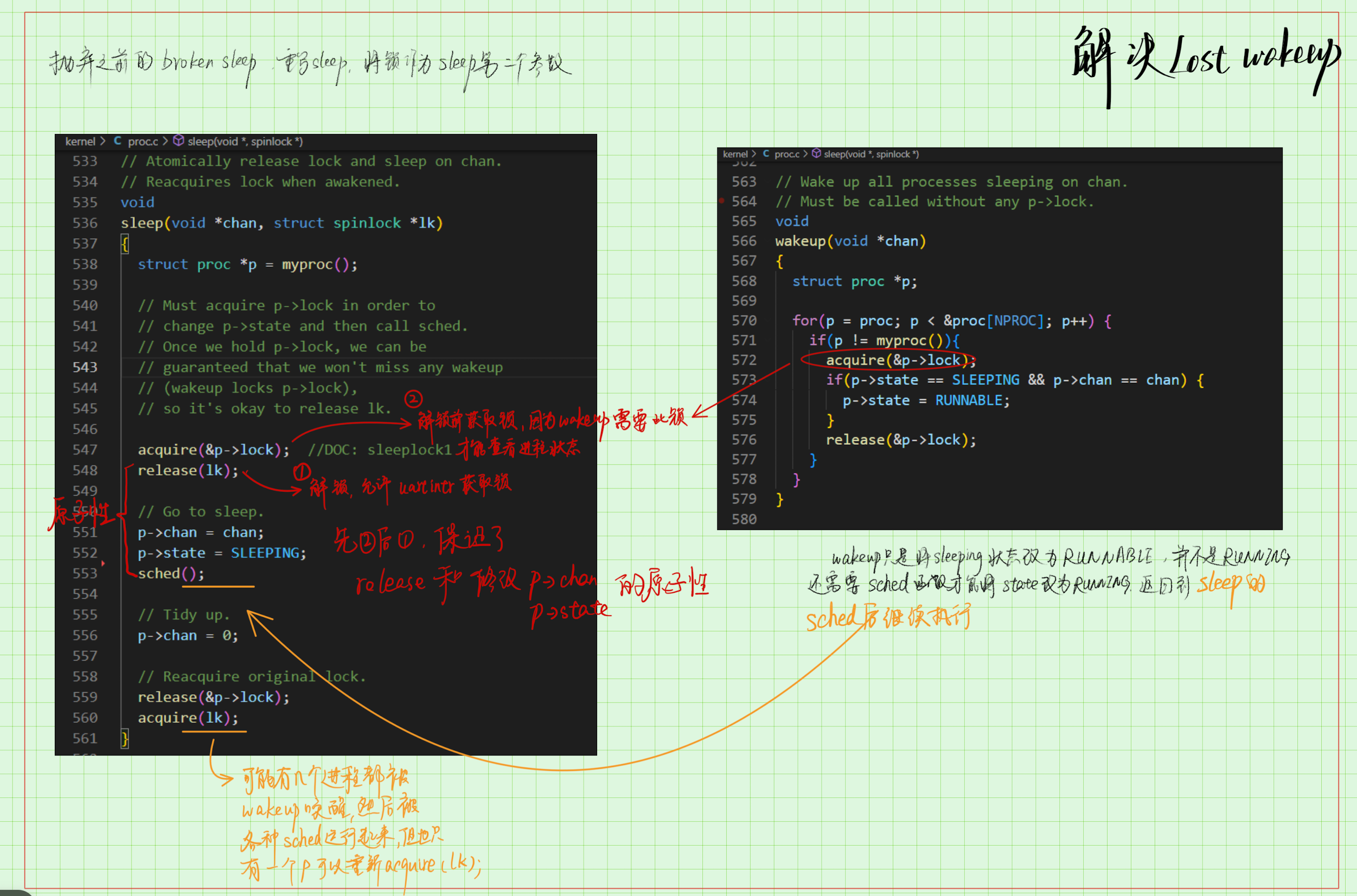
所以總結來看,要想進入 wakeup 函數修改 p->state的狀態,需要獲取兩把鎖,一把是 tx_lock,用來進入uartintr()函數、保護 tx_done,一把是 p->lock,用來保護 p->state,這裡巧妙地方在於釋放 tx_lock之前需要先獲取p->lock,頗有一種"交換人質"的感覺(在放你之前先把他抓過來 23333)
lab6 Thread 心得
lab6 的前兩個 part 見上一篇部落格
Barrier
這個 lab 但是挺有趣的,可以瞭解到了計算機中同步屏障機制是如何實現的。
簡單來說,一段程式碼被多個執行緒執行,如何保證多個執行緒都到了其中某一點之後,才能繼續往下執行?或者說如何"攔住"執行的較快的執行緒,讓他們都到達 barrier 之後再繼續?
題目的 hint 已經給出了重要的工具:pthread,尤其是以下兩個函數:
pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
pthread_cond_broadcast(&cond); // wake up every thread sleeping on cond
童鞋們,考驗英語水平的時候來了!檢視 unix 中關於pthread_cond_wait的描述:
This functions atomically release mutex and cause the calling thread to block on the condition variable cond; atomically here means "atomically with respect to access by another thread to the mutex and then the condition variable". That is, if another thread is able to acquire the mutex after the about-to-block thread has released it, then a subsequent call to pthread_cond_signal() or pthread_cond_broadcast() in that thread behaves as if it were issued after the about-to-block thread has blocked.
我先來直譯一下:
這個函數(pthread_cond_wait)原子地釋放互斥鎖,並在條件變數 cond 上阻塞呼叫執行緒;這裡的原子性指的是「相對於另一個執行緒對互斥鎖和條件變數的存取而言是原子的」。也就是說,如果另一個執行緒能夠在即將阻塞的執行緒釋放互斥鎖後獲取互斥鎖,那麼在該執行緒中對pthread_cond_signal()或pthread_cond_broadcast()的後續呼叫的行為就像它是在即將阻塞的執行緒阻塞後發出的一樣。
看完這段直譯是不是 cpu 有點發燙?我來把他翻譯為人話:
- pthread_cond_wait 接收兩個引數,第一個引數是條件變數,第二個引數是保護條件變數的鎖,呼叫 pthread_cond_wait 的執行緒一定要提前持有了該條件變數的鎖(官方要求,否則會發生未定義的行為)。
- 進入 pthread_cond_wait 函數後,在 pthread_cond_wait 中可以原子性地釋放鎖:因為 pthread_cond_wait 做的主要工作就是阻塞當前執行緒,但是由於當前執行緒還持有條件變數的鎖,所以 pthread_cond_wait 還應該負責釋放該鎖,這樣其他執行緒才能操作該條件變數。所以 pthread_cond_wait 中要做兩件事:
- 要釋放鎖
- 還要阻塞執行緒
- 那麼是先釋放鎖?還是先阻塞執行緒呢?
- 假如先阻塞執行緒,那麼鎖就無法被釋放了,因為執行緒一旦被阻塞,就失去了 cpu 的控制權,只能被動等待 schedule,所以不能先阻塞執行緒
- 假如先釋放鎖,那麼就會發生 lost wakeup 的情況,因為存在這樣的順序:A 執行緒呼叫了 pthread_cond_wait,然後先釋放了鎖,B 執行緒拿到鎖,執行一些業務邏輯後發現 cond 滿足要求,於是呼叫 pthread_cond_broadcast 喚醒了所有執行緒,最後 A 執行緒進入才進入 wait (sleep)階段
- 所以不管先釋放鎖、先阻塞執行緒都有問題啊,但不用擔心,這就是 pthread_cond_wait 存在的意義,他可以原子性地釋放鎖
- 這裡的原子性就是指,一旦 B 執行緒有機會拿到鎖,就意味著 A 執行緒已經阻塞完成了,作為 pthread_cond_wait 的使用者,你不必考慮A 執行緒是先釋放鎖還是先阻塞執行緒,你只需要知道 pthread_cond_wait 可以原子性地釋放鎖就好
- 所以 pthread_cond_wait 作為 UNIX 提供的工具(其實是 POSIX 要求 UNIX 實現的介面規範),和本節講的 xv6 的 Sleep&Wakeup 一樣,也是一種實現 Coordination 的方式,也解決了 lost wakeup 的問題。
瞭解了 pthread_cond_wait 後,pthread_cond_broadcast 就更簡單了,是用來 unblocked的,當條件變數滿足時,就主動呼叫這個函數解除阻塞。
所以有了 pthread_cond_wait 和 pthread_cond_broadcast 這兩個這麼好用的工具,寫出 Barrier 函數是很簡單的:
struct barrier {
pthread_mutex_t barrier_mutex;
pthread_cond_t barrier_cond;
int nthread; // Number of threads that have reached this round of the barrier
int round; // Barrier round
} bstate;
static void
barrier()
{
// YOUR CODE HERE
//
// Block until all threads have called barrier() and
// then increment bstate.round.
//
pthread_mutex_lock(&bstate.barrier_mutex); // line 16
bstate.nthread++;
if(bstate.nthread < nthread){
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
} else {
bstate.nthread = 0;
// printf("round=%d\n", bstate.round);
pthread_cond_broadcast(&bstate.barrier_cond);
bstate.round++;
}
pthread_mutex_unlock(&bstate.barrier_mutex); // line 26
}
這裡再次強調,上方程式碼註釋中 line16 和 line 26 的程式碼,他們可不是一對對應的加解鎖啊!因為在 pthread_cond_wait 中會先解鎖再加鎖, 這其實是兩對加解鎖,虛擬碼如下,其中的 A1&A2 和 B1&B2 才是正確的兩對加解鎖,A1 和 B2 只是表面上像一對而已:
static void
barrier()
{
pthread_mutex_lock(&bstate.barrier_mutex); // 加鎖----------A1
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex) {
// 原子性解鎖------------------------------------------A2
// some code
// 再次加鎖------------------------------------------B1
}
pthread_mutex_unlock(&bstate.barrier_mutex); // 解鎖------B2
}
總結
ok,以上就是 MIT6.s081 中關於程序的 scheduling 的所有內容了,在課程中一共佔據兩節內容,第一節是細節繁多的程序切換過程,主要是 swtch 函數中對於 ra 的巧妙使用使得程序之間完成切換,第二節是關於 lost wakeup 問題的解決,雖然把鎖作為引數傳入 sleep 函數是一個比較醜陋的實現,是效果卻很好,而且也是一種通用的寫法~教授也提到有一些更加優雅的解決如 semaphore,無需知道任何鎖的資訊,但使用場景有限。
對了,我目前在尋找工作機會,本人計算機基礎比較紮實,獨立完成了 CSAPP(計算機組成)、MIT6.s081(作業系統)、MIT6.824(分散式)、Stanford CS144 NetWorking(計算機網路)、CMU15-445(資料庫基礎,leaderboard 可查) 等硬核課程的所有 lab,如果有內推名額的大佬可私信我,我來發簡歷。
獲得更好的閱讀體驗,這裡是我的部落格,歡迎存取:byFMH - 部落格園
所有程式碼見:我的GitHub實現(記得切換到相應分支)