HiAI Foundation助力端側音視訊AI能力,高效能低功耗釋放雲側成本
過去三年是端側AI高速發展的幾年,華為在2020年預言了端側AI的發展潮流,2021年通過提供端雲協同的方式使我們的HiAI Foundation應用性更進一個臺階,2022年提供視訊超分端到端的解決方案,在2023HDC大會上,HiAI Foundation基於硬體能力的開放,提供更多場景高效能的解決方案。
華為HiAI Foundation提供了高效能AI運算元和豐富的AI特性的介面,App直接對應HiAI Foundation的DDK。今年完整支援了HarmonyOS NEXT,開發者無需修改任何程式碼,只需按照HarmonyOS NEXT的要求重新編譯即可執行。同時,在開發者聯盟網站有HarmonyOS NEXT指導檔案,在Gitee上也開源了對應的Demo,降低大家的整合成本。
今年,華為在原有的基礎上,拓展了更多端側AI場景解決方案。

華為HiAI Foundation是基於硬體創新架構的能力開放,構建了一個高效能的NPU、CPU、GPU運算元,同時提供整網融合、AIPP硬化預處理、運算元搜尋工具、異構計算等多元的基礎能力,在硬體創新架構和多元競爭基礎的能力上,提供生態開放機制,在生態開放機制上提供對使用者開放的介面DDK工具鏈、模型輕量化、運算元庫動態升級、開源等等機制。

華為HiAI Foundation主要由以下幾個部分構成,首先是HiAI Foundation DDK推理加速平臺,它主要完成與上層推理框架的接入,使開發者可以遮蔽底層硬體,能夠更加聚焦於模型效果的優化。第二部分是異構計算HCL平臺,它主要是使能各個硬體,比如NPU、CPU、GPU。第三部分是提供對應的工具鏈,包括模型轉換工具鏈、異構調優工具鏈。同時我們也提供了統一的API,通過一次開發可以做到賦能多形態的裝置硬體上執行,並且華為HiAI Foundation可以與HarmonyOS實時融合。

下面以典型AI場景為例,從部署的角度來探索一下華為HiAI Foundation是如何完成這些挑戰,並最終實現這些場景的落地。
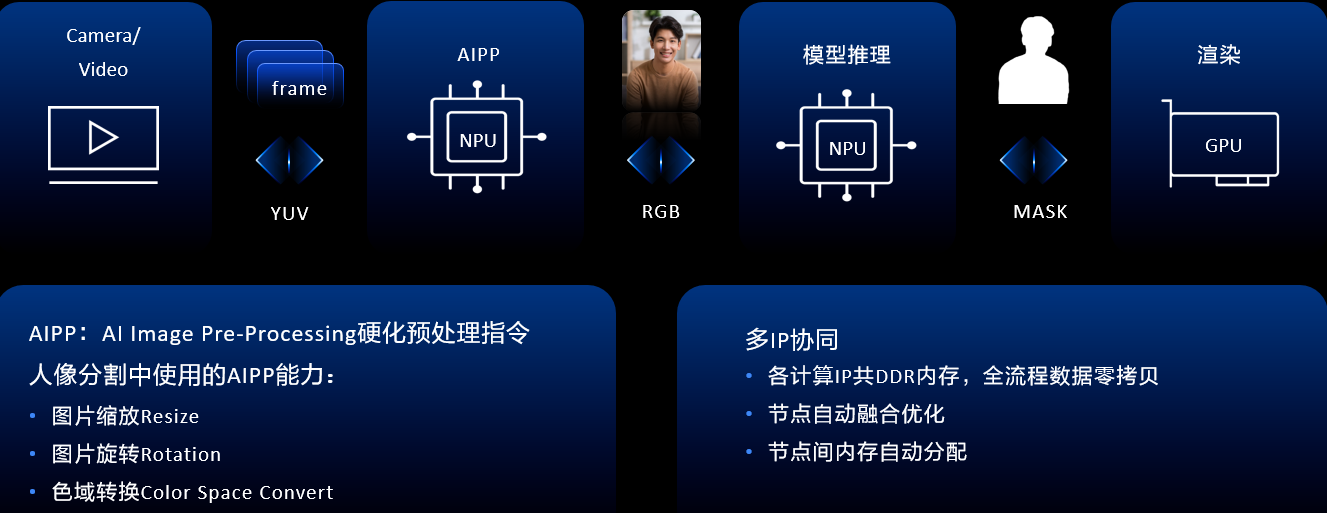
視覺類加速方案人像分割
我們知道人像分割通常用於視訊中的背景替換、長短視訊的彈幕穿人玩法等。華為HiAI Foundation通過人像分割,通過AIPP硬化預處理指令、模型量化,使得人像分割達到效能和功耗的業務要求。從視訊解碼和開通預覽流到AIPP推理和GPU渲染,有多個過程參與,華為HiAI Foundation不僅要進行推理,還要完成上下游的深度協同。


視訊流和開放預覽幀到模型,以人像分割為例,人像分割要求的輸入是RGB格式,並且輸入要求是固定的尺寸,視訊解碼幀和預覽流出來的資料,要求支援影象預處理的指令,並且把它硬化到NPU裡面,所以人像分割提供了包括圖片縮放resize、圖片旋轉rotation、色域轉換color space convert的能力。基於華為實驗室測試結果,實現效能提升20%,模型大小縮小75%,精度損失1%以內,效能提升19%。
第二部分是模型在NPU上的高效運算元推理,推理結束之後將結果送到GPU上做渲染。在傳統方案中,NPU和GPU通常是操作兩塊不同的記憶體,華為HiAI Foundation提供了零拷貝的介面,將NPU和GPU在同一塊記憶體上操作,並且在格式上保持嚴格一致,通過多IP協同+AIPP實現高效人像分割計算。
在端側部署過程中提供了模型視覺化+Profiling工具,通過模型視覺化了解HiAI Foundation結構,通過Profiling知道IP的分佈,包括運算元在NPU和GPU的推理時間,綜合起來通過視覺化工具和Profiling工具設計出系統友好的結構,設計效能最佳的模型。
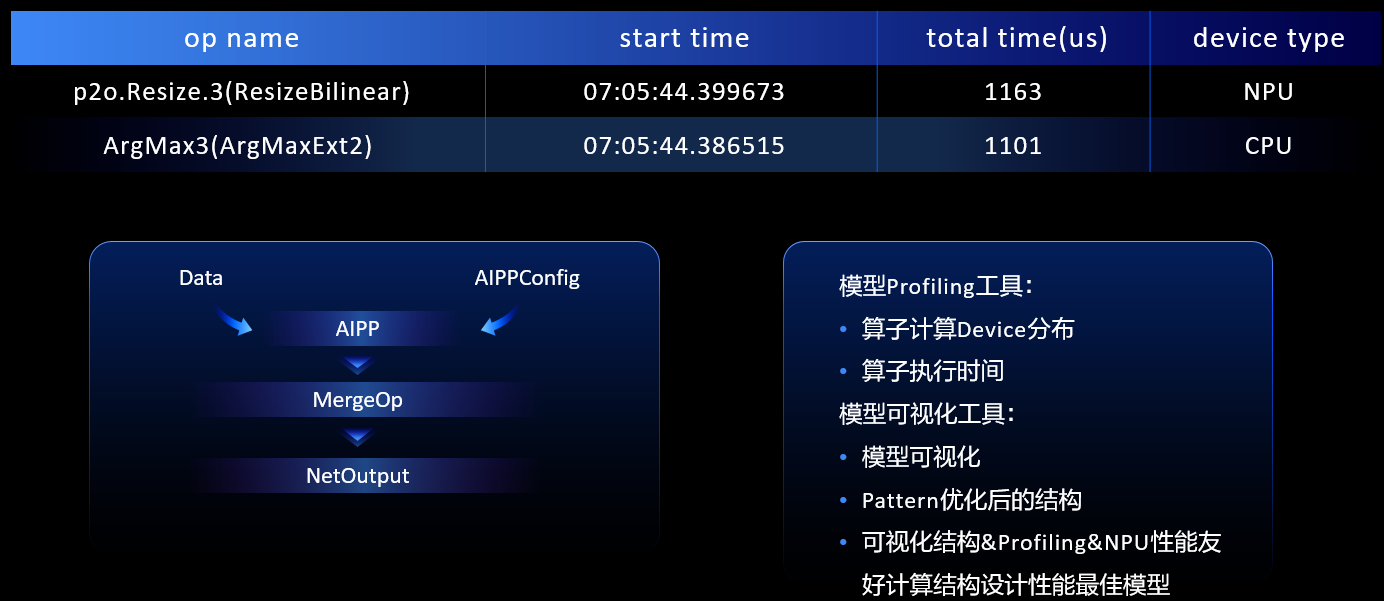
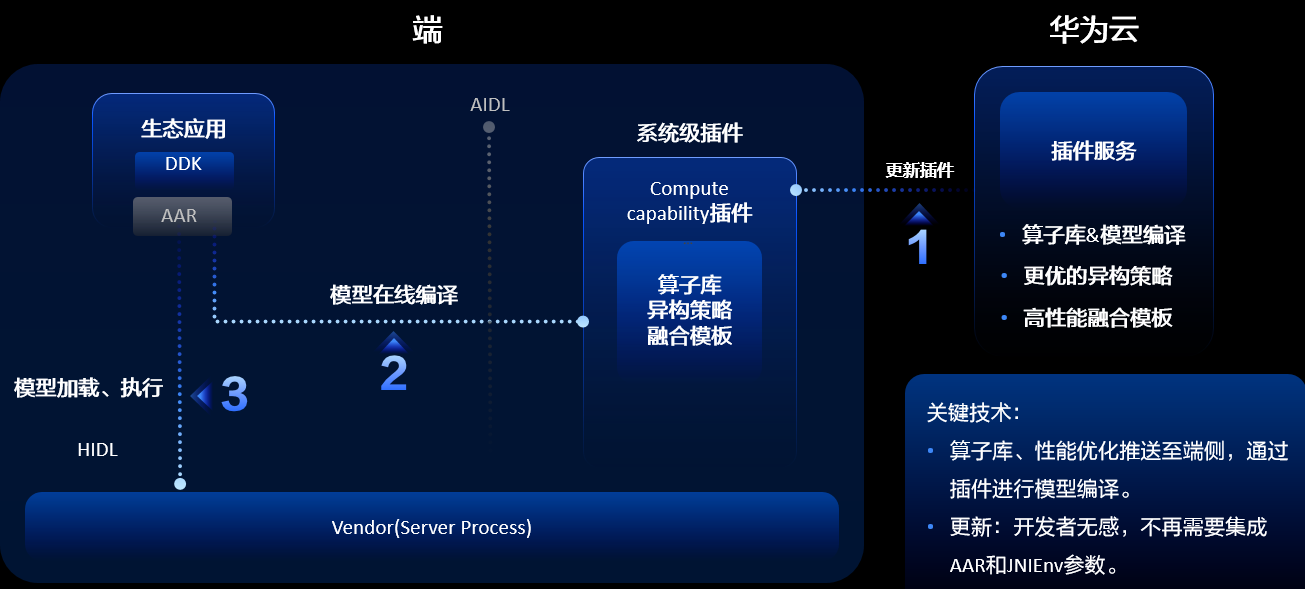
通過Profiling工具瞭解到模型運算元的效能不夠友好,然後把它反饋到HiAI Foundation,我們在支援好這些運算元之後,通過端雲協同的方式快速推播到使用者手中,使使用者能夠儘快上線業務。本次華為在端雲協同助力效能優化快速升級方面做了全面的升級,開發者無SDK就可以整合,相比原來繁瑣的整合要求,可以做到無感整合。
語音類的加速方案語音識別
端側部署語音識別實時出字、響應快,在端側執行可以保證使用者的隱私,此外華為能做到在NPU上執行,穩定性高,並且可以降低雲側的資源部署成本。在語音識別這一塊,HiAI Foundation支援的是端到端的Transformer模型,全部在雲端推理。基於華為實驗室測試結果,模型量化模型大小縮小74%,精度損失1%以內。
模型如圖所示,支援Transformer模型,開發者可以根據自身的業務,根據效能和泛化性來進行客製化,也可以實現高效的運算元融合。
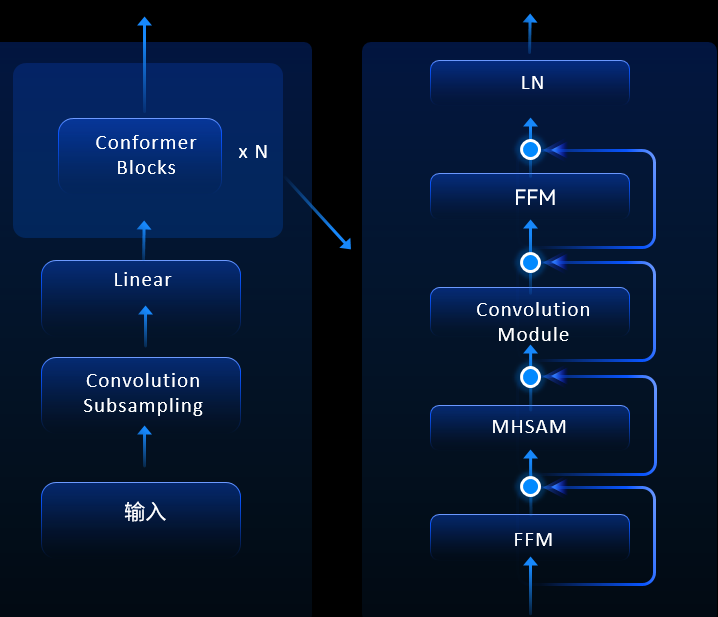
將原來需要頻繁和記憶體互動的指令融合成一個大的運算元,通過對這些關鍵結構進行運算元融合,總共帶來了60%的功耗收益,將左邊很多小運算元組成的結構融合成一個大運算元,避免這些小運算元頻繁和記憶體進行互動,從而提升了運算效率。

在端側部署的過程中,儲存空間也是開發者們關注的問題,希望用更小的儲存空間來實現更多更強的能力,所以華為提供量化工具鏈,通過量化工具鏈可以量化出更小巧、更靈活的模型。以人像分割和語音識別為例,基於華為實驗室測試結果,它們的儲存大小能夠相比32位元浮點減少70%以上,精度WER指標相比32浮點小於1%,相應的功率也有一定的提升。

在端側AI部署中會涉及到硬體、軟體和AI演演算法,所以華為通過開源的方式來加速業務,通過更多方式靈活部署。目前開放了推理原始碼的開源,通過開源可以做到和App、第三方深度學習框架對接,同時可以基於自身的需求做靈活的客製化裁剪,做到開發靈活,通過這些開源平臺能和開發者溝通更便捷。通過這些開源,開發者可以快速下載、編譯,即可在華為手機上用NPU做推理,更高效整合業務。
未來,華為會探索Transformer模型更加泛化、更高能效的場景化解決方案,同時在端雲協同上也會探索更多更高效能場景的能力支援,也會通過ModelZoo提供更多場景NPU友好的模型結構,使用者可以設計更加NPU友好的模型結構。
瞭解更多詳情>>
關注我們,第一時間瞭解 HMS Core 最新技術資訊~