Llama2-Chinese專案:1-專案介紹和模型推理
Atom-7B與Llama2間的關係:Atom-7B是基於Llama2進行中文預訓練的開源大模型。為什麼叫原子呢?因為原子生萬物,Llama中文社群希望原子大模型未來可以成為構建AI世界的基礎單位。目前社群釋出了6個模型,如下所示:
FlagAlpha/Atom-7B
FlagAlpha/Llama2-Chinese-7b-Chat
FlagAlpha/Llama2-Chinese-7b-Chat-LoRA
FlagAlpha/Llama2-Chinese-13b-Chat
FlagAlpha/Llama2-Chinese-13b-Chat-LoRA
FlagAlpha/Llama2-Chinese-13b-Chat-4bit
一.Llama2-Chinese專案介紹
 1.Llama相關論文
1.Llama相關論文
LLaMA: Open and Efficient Foundation Language Models
Llama 2: Open Foundation and Fine-Tuned Chat Models
Code Llama: Open Foundation Models for Code
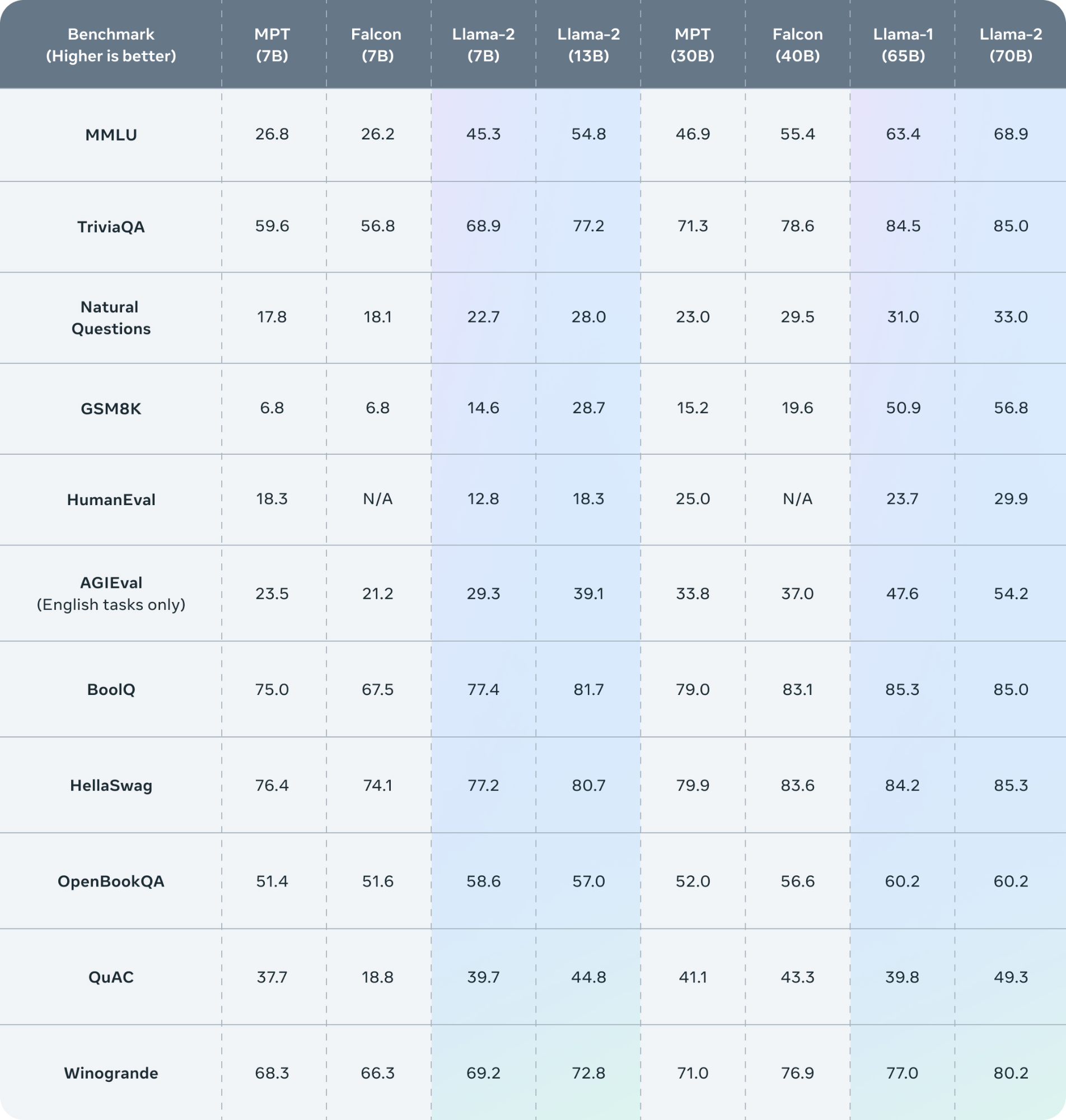
2.Llama2的評測結果
二.Atom-7B載入和推理
模型呼叫程式碼範例如下所示:
from transformers import AutoTokenizer, AutoModelForCausalLM
from pathlib import Path
import torch
pretrained_model_name_or_path = r'L:/20230903_Llama2/Atom-7B'
model = AutoModelForCausalLM.from_pretrained(Path(f'{pretrained_model_name_or_path}'), device_map='auto', torch_dtype=torch.float16, load_in_8bit=True) #載入模型
model = model.eval() #切換到eval模式
tokenizer = AutoTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}'), use_fast=False) #載入tokenizer
tokenizer.pad_token = tokenizer.eos_token #為了防止生成的文字出現[PAD],這裡將[PAD]重置為[EOS]
input_ids = tokenizer(['<s>Human: 介紹一下中國\n</s><s>Assistant: '], return_tensors="pt", add_special_tokens=False).input_ids.to('cuda') #將輸入的文字轉換為token
generate_input = {
"input_ids": input_ids, #輸入的token
"max_new_tokens": 512, #最大生成的token數量
"do_sample": True, #是否取樣
"top_k": 50, #取樣的top_k
"top_p": 0.95, #取樣的top_p
"temperature": 0.3, #取樣的temperature
"repetition_penalty": 1.3, #重複懲罰
"eos_token_id": tokenizer.eos_token_id, #結束token
"bos_token_id": tokenizer.bos_token_id, #開始token
"pad_token_id": tokenizer.pad_token_id #pad token
}
generate_ids = model.generate(**generate_input) #生成token
text = tokenizer.decode(generate_ids[0]) #將token轉換為文字
print(text) #輸出生成的文字
三.相關知識點
1.Fire庫
解析:Fire是一個Google開發的庫,用於自動生成Python命令列介面(CLI)。它可以幫助開發人員快速將Python物件和函數暴露為命令列工具。使用Fire可以自動建立命令列引數,引數型別和預設值等。
2.Llama1和Llama2區別
解析:
(1)Llama2採用Llama1的大部分預訓練設定和模型架構,它們使用標準的Transformer架構,應用RMSNorm進行預歸一化,使用SwiGLU啟用函數和旋轉位置編碼。與Llama1相比,主要的架構差異包括增加的上下文長度和分組查詢注意力(GQA)。
(2)Llama2總共公佈了7B、13B和70B三種引數大小的模型。相比於LLaMA,Llama2的訓練資料達到了2萬億token,上下文長度也由之前的2048升級到4096,可以理解和生成更長的文字。Llama2Chat模型基於100萬人類標記資料微調得到,在英文對話上達到了接近ChatGPT的效果。
四.相關問題
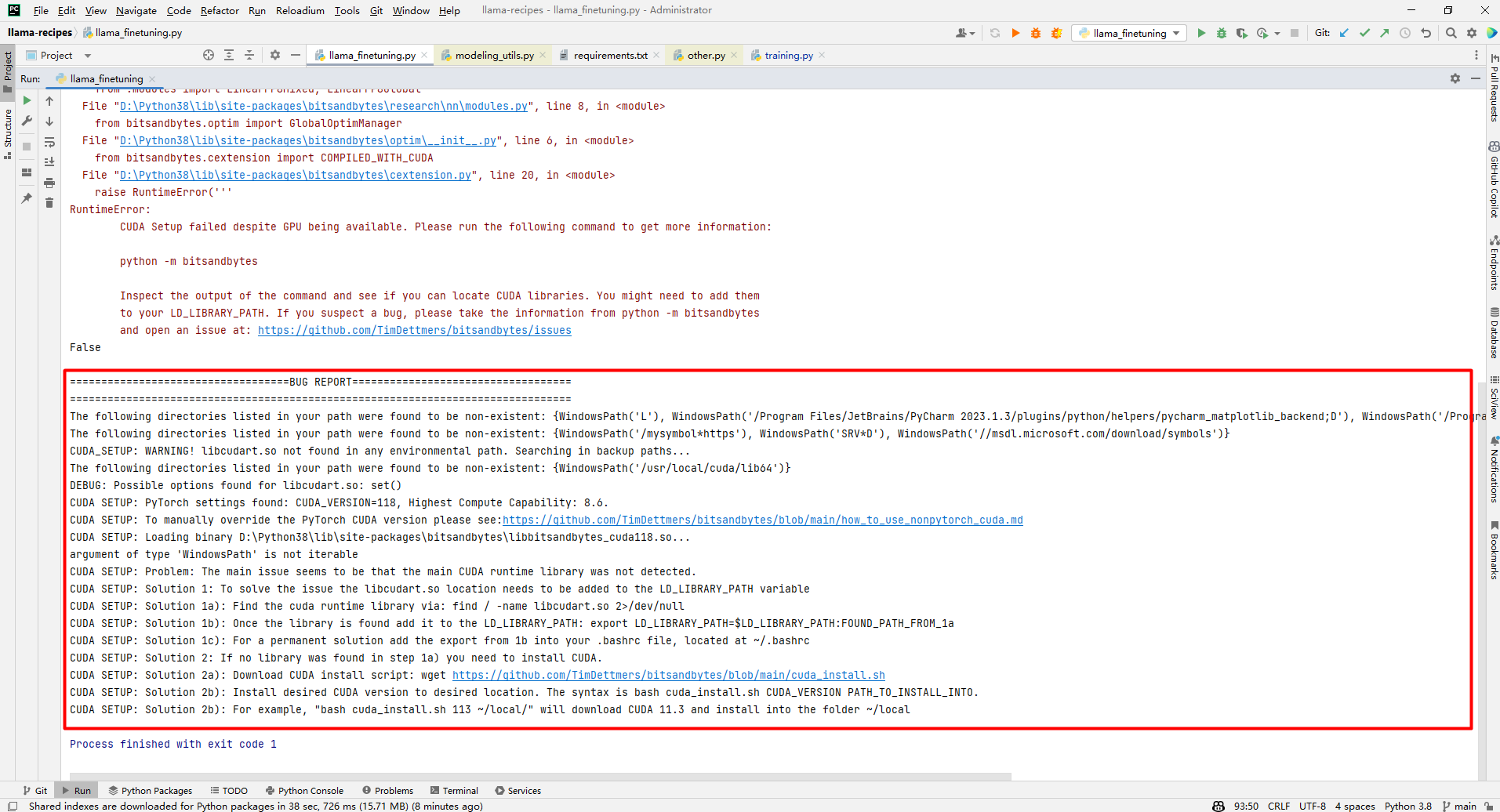
1.CUDA Setup failed despite GPU being available
解析:如下是網上介紹的解決方案,還有的建議原始碼編譯,但是這2種方案都沒有走通。
 (1)安裝路徑
(1)安裝路徑
bitsandbytes路徑(0.39.1):D:\Python38\Lib\site-packages\bitsandbytes CUDA路徑(v12.1):C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin
將"CUDA路徑(v12.1)"下的檔案拷貝到"bitsandbytes路徑(0.39.1)"目錄下:
cudart64_12.dll
cublas64_12.dll
cublasLt64_12.dll
cusparse64_12.dll
nvJitLink_120_0.dll
實踐經驗建議方式[8]為pip3 install https://github.com/jllllll/bitsandbytes-windows-webui/blob/main/bitsandbytes-0.39.0-py3-none-any.whl。有圖有證據如下所示:

(2)修改檔案 D:\Python38\Lib\site-packages\bitsandbytes\cuda_setup\main.py
將 if not torch.cuda.is_available(): return 'libsbitsandbytes_cpu.so', None, None, None, None替換為if torch.cuda.is_available(): return 'libbitsandbytes_cuda116.dll', None, None, None, None將2個地方的 self.lib = ct.cdll.LoadLibrary(binary_path)替換為self.lib = ct.cdll.LoadLibrary(str(binary_path))
(3)新增libbitsandbytes_cuda116.dll和libbitsandbytes_cpu.dll
存放路徑為D:\Python38\Lib\site-packages\bitsandbytes,下載地址參考[0]。
2.RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
解析:下載連結為[7],下載之前需要NVIDIA社群賬號登入。
 (1)解壓cudnn-windows-x86_64-8.9.4.25_cuda12-archive.zip
(1)解壓cudnn-windows-x86_64-8.9.4.25_cuda12-archive.zip
 (2)拷貝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1
(2)拷貝到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1
參考文獻:
[0]https://github.com/DeXtmL/bitsandbytes-win-prebuilt/tree/main
[1]https://github.com/facebookresearch/llama
[2]https://github.com/facebookresearch/llama-recipes/
[3]https://huggingface.co/meta-llama/Llama-2-7b-hf/tree/main
[4]https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI
[5]https://huggingface.co/meta-llama/Llama-2-70b-chat-hf
[6]https://huggingface.co/blog/llama2
[7]https://developer.nvidia.com/rdp/cudnn-download
[8]https://github.com/jllllll/bitsandbytes-windows-webui
[9]https://github.com/langchain-ai/langchain
[10]https://github.com/AtomEcho/AtomBulb
[11]https://github.com/huggingface/peft
[12]全引數微調時,報沒有target_modules變數:https://github.com/FlagAlpha/Llama2-Chinese/issues/169
[13]https://huggingface.co/FlagAlpha
[14]https://llama.family/