一個爛分頁,踩了三個坑!
你好呀,我是歪歪。
前段時間踩到一個比較無語的生產 BUG,嚴格來說其實也不能算是 BUG,只能說開發同事對於業務同事的需求理解沒有到位。
這個 BUG 其實和分頁沒有任何關係,但是當我去排查問題的時候,我看了一眼 SQL ,大概是這樣的:
select * from table order by priority limit 1;
priority,就是優先順序的意思。
按照優先順序 order by 然後 limit 取優先順序最高(數位越小,優先順序越高)的第一條 ,結合業務背景和資料庫裡面的資料,我立馬就意識到了問題所在。
想起了我當年在寫分頁邏輯的時候,雖然場景和這個完全不一樣,但是踩過到底層原理一模一樣的坑,這玩意印象深刻,所以立馬就識別出來了。
藉著這個問題,也盤點一下我遇到過的三個關於分頁查詢有意思的坑。
職業生涯的第一個生產 BUG
歪師傅職業生涯的第一個生產 BUG 就是一個小小的分頁查詢。
當時還在做支付系統,接手的一個需求也很簡單就是做一個定時任務,定時把資料庫裡面狀態為初始化的訂單查詢出來,呼叫另一個服務提供的介面查詢訂單的狀態並更新。
由於流程上有資料強校驗,不用考慮資料不存在的情況。所以該介面可能返回的狀態只有三種:成功,失敗,處理中。
很簡單,很常規的一個需求對吧,我分分鐘就能寫出虛擬碼:
//獲取訂單狀態為初始化的資料(0:初始化 1:處理中 2:成功 3:失敗)
//select * from order where order_status=0;
ArrayList initOrderInfoList = queryInitOrderInfoList();
//迴圈處理這批資料
for(OrderInfo orderInfo : initOrderInfoList){
//捕獲異常以免一條資料錯誤導致迴圈結束
try{
//發起rpc呼叫
String orderStatus = queryOrderStatus(orderInfo.getOrderId);
//更新訂單狀態
updateOrderInfo(orderInfo.getOrderId,orderStatus);
} catch (Exception e){
//列印異常
}
}
來,你說上面這個程式有什麼問題?

其實在絕大部分情況下都沒啥大問題,資料量不多的情況下程式跑起來沒有任何毛病。
但是,如果資料量多起來了,一次性把所有初始化狀態的訂單都拿出來,是不是有點不合理了,萬一把記憶體給你撐爆了怎麼辦?
所以,在我已知資料量會很大的情況下,我採取了分批次獲取資料的模式,假設一次性取 100 條資料出來玩。
那麼 SQL 就是這樣的:
select * from order where order_status=0 order by create_time limit 100;
所以上面的虛擬碼會變成這樣:
while(true){
//獲取訂單狀態為初始化的資料(0:初始化 1:處理中 2:成功 3:失敗)
//select * from order where order_status=0 order by create_time limit 100;
ArrayList initOrderInfoList = queryInitOrderInfoList();
//迴圈處理這批資料
for(OrderInfo orderInfo : initOrderInfoList){
//捕獲異常以免一條資料錯誤導致迴圈結束
try{
//發起rpc呼叫
String orderStatus = queryOrderStatus(orderInfo.getOrderId);
//更新訂單狀態
updateOrderInfo(orderInfo.getOrderId,orderStatus);
} catch (Exception e){
//列印異常
}
}
}
來,你又來告訴我上面這一段邏輯有什麼問題?

作為程式設計師,我們看到 while(true) 這樣的寫法立馬就要警報拉滿,看看有沒有死迴圈的風險。
那你說上面這段程式碼在什麼時候退不出來?
當有任何一條資料的狀態沒有從初始化變成成功、失敗或者處理中的時候,就會導致一直迴圈。
而雖然發起 RPC 呼叫的地方,服務提供方能確保返回的狀態一定是成功、失敗、處理中這三者之中的一個,但是這個有一個前提是介面呼叫正常的情況下。
如果介面呼叫一旦異常,那麼按照上面的寫法,在丟擲異常後,狀態並未發生變化,還會是停留在「初始化」,從而導致死迴圈。
當年,測試同學在測試階段直接就測出了這個問題,然後我對其進行了修改。
我改變了思路,把每次分批次查詢 100 條資料,修改為了分頁查詢,引入了 PageHelper 外掛:
//是否是最後一頁
while(pageInfo.isLastPage){
pageNum=pageNum+1;
//獲取訂單狀態為初始化的資料(0:初始化 1:處理中 2:成功 3:失敗)
//select * from order where order_status=0 order by create_time limit pageNum*100,100;
PageHelper.startPage(pageNum,100);
ArrayList initOrderInfoList = queryInitOrderInfoList();
pageInfo = new PageInfo(initOrderInfoList);
//迴圈處理這批資料
for(OrderInfo orderInfo : initOrderInfoList){
//捕獲異常以免一條資料錯誤導致迴圈結束
try{
//發起rpc呼叫
String orderStatus = queryOrderStatus(orderInfo.getOrderId);
//更新訂單狀態
updateOrderInfo(orderInfo.getOrderId,orderStatus);
} catch (Exception e){
//列印異常
}
}
}
跳出迴圈的條件為判斷當前頁是否是最後一頁。
由於每回圈一次,當前頁就加一,那麼理論上講一定會是翻到最後一頁的,沒有任何毛病,對不對?
我們可以分析一下上面的程式碼邏輯。
假設,我們有 120 條 order_status=0 的資料。
那麼第一頁,取出了 100 條資料:
SELECT * from order_info WHERE order_status=0 LIMIT 0,100;
這 100 條處理完成之後,第二頁還有資料嗎?
第二頁對應的 sql 為:
SELECT * from order_info WHERE order_status=0 LIMIT 100,100;
但是這個時候,狀態為 0 的資料,只有 20 條了,而分頁要從第 100 條開始,是不是獲取不到資料,導致遺漏資料了?
確實一定會翻到最後一頁,解決了死迴圈的問題,但又有大量的資料遺漏怎麼辦呢?

當時我苦思冥想,想到一個辦法:導致資料遺漏的原因是因為我在翻頁的時候,資料狀態在變化,導致總體資料在變化。
那麼如果我每次都從後往前取資料,每次都固定取最後一頁,能取到資料就代表還有資料要處理,迴圈結束條件修改為「當前頁即是第一頁,也是最後一頁時」就結束,這樣不就不會遺漏資料了?
我再給你分析一下。
假設,我們有 120 條 order_status=0 的資料,從後往前取了 100 天出來進行出來,有 90 條處理成功,10 條的狀態還是停留在「處理中」。
第二次再取的時候,會把剩下的 20 條和這次「處理中」的 10 條,共計 30 條再次取出來進行處理。
確保沒有資料遺漏。
後來測試環節驗收通過了,這個方案上線之後,也確實沒有遺漏過資料了。
直到後來又一天,提供 queryOrderStatus 介面的服務異常了,我發過去的請求超時了。
導致我取出來的資料,每一條都會丟擲異常,都不會更新狀態。從而導致我每次從後往前取資料,都取到的是同一批資料。
從程式上的表現上看,紀錄檔瘋狂的列印,但是其實一直在處理同一批,就是死迴圈了。
好在我當時還在新手保護期,領導幫我扛下來了。
最後隨著業務的發展,這塊邏輯也完全發生了變化,邏輯由我們主動去呼叫 RPC 介面查詢狀態變成了,下游狀態變化後進行 MQ 主動通知,所以我這一坨騷程式碼也就隨之光榮下崗。
我現在想了一下,其實這個場景,用分頁的思想去取資料真的不好做。
還不如用最開始的分批次的思想,只不過在會變化的「狀態」之外,再加上另外一個不會改變的限定條件,比如常見的建立時間:
select * from order where order_status=0 and create_time>xxx order by create_time limit 100;
最好不要基於狀態去做分頁,如果一定要基於狀態去做分頁,那麼要確保狀態在分頁邏輯裡面會扭轉下去。
這就是我職業生涯的第一個生產 BUG,一個低階的分頁邏輯錯誤。
還是分頁,又踩到坑
這也是在工作的前兩年遇到的一個關於分頁的坑。
最開始在學校的時候,大家肯定都手擼過分頁邏輯,自己去算總頁數,當前頁,頁面大小啥的。
當時功力尚淺,覺得這部分邏輯寫起來是真複雜,但是扣扣腦袋也還是可以寫出來。
後來參加工作了之後,在專案裡面看到了 PageHelper 這個玩意,瞭解之後發了「斯國一」的驚歎:有了這玩意,誰還手寫分頁啊。

但是我在使用 PageHelper 的時候,也踩到過一個經典的「坑」。
最開始的時候,程式碼是這樣的:
PageHelper.startPage(pageNum,100);
List<OrderInfo> list = orderInfoMapper.select(param1);
後來為了避免不帶 where 條件的全表查詢,我把程式碼修改成了這樣:
PageHelper.startPage(pageNum,100);
if(param != null){
List<OrderInfo> list = orderInfoMapper.select(param);
}
然後,隨著程式的迭代,就出 BUG 了。因為有的業務場景下,param 引數一路傳遞進來之後就變成了 null。
但是這個時候 PageHelper 已經在當前執行緒的 ThreadLocal 裡面設定了分頁引數了,但是沒有被消費,這個引數就會一直保留在這個執行緒上,也就是放線上程的 ThreadLocal 裡面。
當這個執行緒繼續往後跑,或者被複用的時候,遇到一條 SQL 語句時,就可能導致不該分頁的方法去消費這個分頁引數,產生了莫名其妙的分頁。
所以,上面這個程式碼,應該寫成下面這個樣子:
if(param != null){
PageHelper.startPage(pageNum,100);
List<OrderInfo> list = orderInfoMapper.select(param);
}
也是這次踩坑之後,我翻閱了 PageHelper 的原始碼,瞭解了底層原理,並總結了一句話:需要保證在 PageHelper 方法呼叫後緊跟 MyBatis 查詢方法,否則會汙染執行緒。
在正確使用 PageHelper 的情況下,其外掛內部,會在 finally 程式碼段中自動清除了在 ThreadLocal 中儲存的物件。
這樣就不會留坑。
這次翻頁原始碼的過程影響也是比較深刻的,雖然那個時候經驗不多,但是得益於 MyBatis 的原始碼和 PageHelper 的原始碼寫的都非常的符合正常人的思維,閱讀起來門檻不高,再加上我有具體的疑問,所以那是一次古早時期,尚在新手村時,為數不多的,閱讀原始碼之後,感覺收穫滿滿的經歷。
分頁丟資料
關於這個 BUG 可以說是印象深刻了。
當年遇到這個坑的時候排查了很長時間沒啥頭緒,最後還是組裡的大佬指了條路。
業務需求很簡單,就是在管理頁面上可以查詢訂單列表,查詢結果按照訂單的建立時間倒序排序。
對應的分頁 SQL 很簡單,很常規,沒有任何問題:
select * from table order by create_time desc limit 0,10;
但是當年在頁面上的表現大概是這樣的:
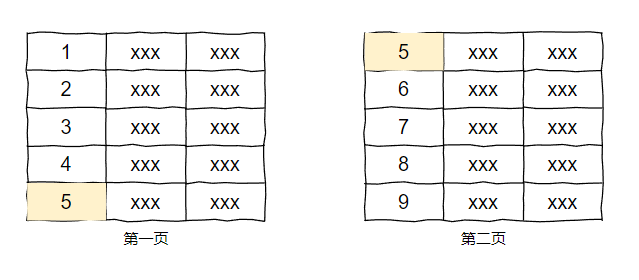
訂單編號為 5 的這條資料,會同時出現在了第一頁和第二頁。
甚至有的資料在第二頁出現了之後,在第五頁又出現一次。
後來定位到產生這個問題的原因是因為有一批數量不小的訂單資料是通過線下執行 SQL 的方式匯入的。
而匯入的這一批資料,寫 SQL 的同學為了方便,就把 create_time 都設定為了同一個值,比如都設定為了 2023-09-10 12:34:56 這個時間。
由於 create_time 又是我作為 order by 的欄位,當這個欄位的值大量都是同一個值的時候,就會導致上面的一條資料在不同的頁面上多次出現的情況。
針對這個現象,當時組裡的大佬分析明白之後,扔給我一個連結:
https://dev.mysql.com/doc/refman/5.7/en/limit-optimization.html
這是 MySQL 官方檔案,這一章節叫做「對 Limit 查詢的優化」。
開篇的時候人家就是這樣說的:
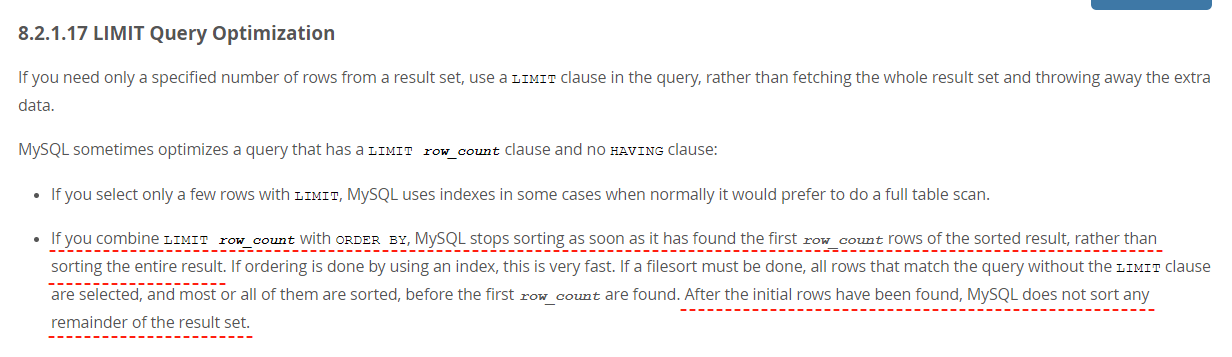
如果將 LIMIT row_count 和 ORDER BY 組合在一起,那麼 MySQL 在找到排序結果的第一行 count 行時就停止排序,而不是對整個結果進行排序。
然後給了這一段補充說明:

如果多條記錄的 ORDER BY 列中有相同的值,伺服器可以自由地按任何順序返回這些記錄,並可能根據整體執行計劃的不同而採取不同的方式。
換句話說,相對於未排序列,這些記錄的排序順序是 nondeterministic 的:
然後官方給了一個範例。
首先,不帶 limit 的時候查詢結果是這樣的:
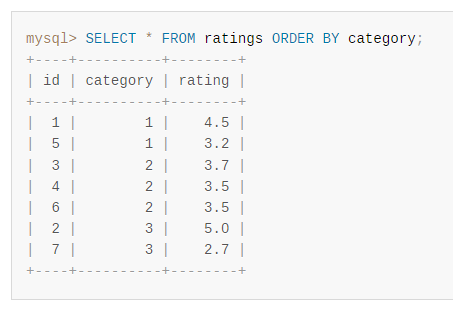
基於這個結果,如果我要取前五條資料,對應的 id 應該是 1,5,3,4,6。
但是當我們帶著 limit 的時候查詢結果可能是這樣的:
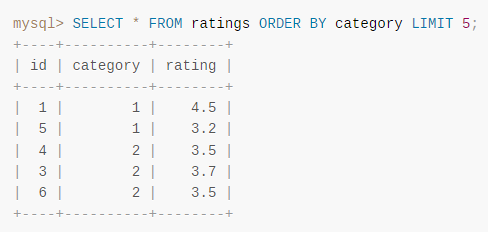
對應的 id 實際是 1,5,4,3,6。
這就是前面說的:如果多條記錄的 ORDER BY 列中有相同的值,伺服器可以自由地按任何順序返回這些記錄,並可能根據整體執行計劃的不同而採取不同的方式。
從程式上的表現上來看,結果就是 nondeterministic。
所以看到這裡,我們大概可以知道我前面遇到的分頁問題的原因是因為那一批手動插入的資料對應的 create_time 欄位都是一樣的,而 MySQL 這邊又對 Limit 引數做了優化,執行結果出現了不確定性,從而頁面上出現了重複的資料。
而回到文章最開始的這個 SQL,也就是我一眼看出問題的這個 SQL:
select * from table order by priority limit 1;
因為在我們的介面上,只是約定了數位越小優先順序越高,數位必須大於 0。
所以當大家在輸入優先順序的時候,大部分情況下都預設自己編輯的資料對應的優先順序最高,也就是設定為 1,從而導致資料庫裡面有大量的優先順序為 1 的資料。
而程式每次處理,又只會按照優先順序排序只會,取一條資料出來進行處理。
經過前面的分析我們可以知道,這樣取出來的資料,不一定每次都一樣。
所以由於有這段程式碼的存在,導致業務上的表現就很奇怪,明明是一模一樣的請求引數,但是最終返回的結果可能不相同。
好,現在,我問你,你說在前面,我給出的這樣的分頁查詢的 SQL 語句有沒有毛病?
select * from table order by create_time desc limit 0,10;
沒有任何毛病嘛,執行結果也沒有任何毛病?
有沒有給你按照 create_time 排序?
摸著良心說,是有的。
有沒有給你取出排序後的 10 條資料?
也是有的。
所以,針對這種現象,官方的態度是:我沒錯!在我的概念裡面,沒有「分頁」這樣的玩意,你通過組合我提供的功能,搞出了「分頁」這種業務場景,現在業務場景出問題了,你反過來說我底層有問題?
這不是欺負老實人嗎?我沒錯!

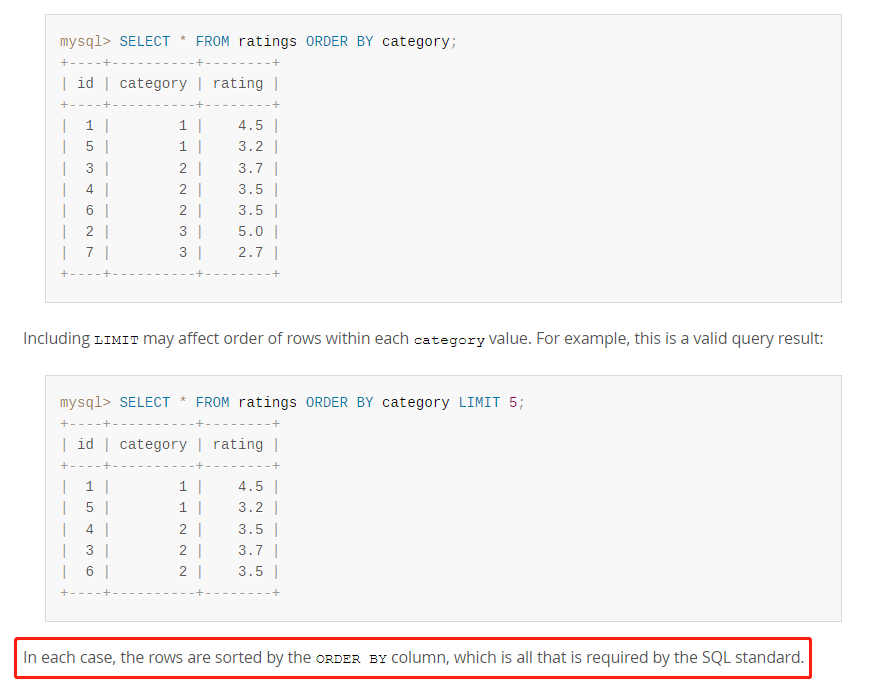
所以,官方把這兩種案例都拿出來,並且強調:
在每種情況下,查詢結果都是按 ORDER BY 的列進行排序的,這樣的結果是符合 SQL 標準的。
雖然我沒錯,但是我還是可以給你指個路。
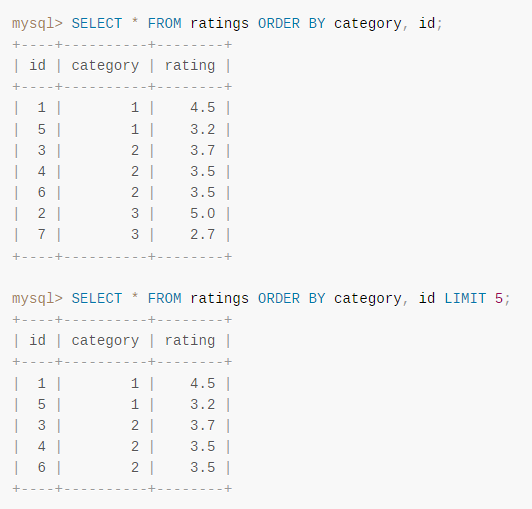
如果你非常在意執行結果的順序,那麼在 ORDER BY 子句中包含一個額外的列,以確保順序具有確定性。
例如,如果 id 值是唯一的,你可以通過這樣的排序使給定類別值的行按 id 順序出現。
你這樣去寫,排序的時候加個 id 欄位,就穩了:
好了,如果覺得本文對你有幫助的話,求個免費的點贊,不過分吧?