資料庫深分頁介紹及優化方案 | 京東雲技術團隊
在前端頁面顯示,為了避免一次性展示全量資料,通過上下翻頁或指定頁碼的方式檢視部分資料,就像翻書一樣,這就利用了MySQL的分頁查詢。
一、MySQL的深分頁
查詢偏移量過大的分頁會導致資料庫獲取資料效能低下,以如下SQL為例:
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
這句SQL會使得MySQL在無法利用索引的情況下跳過1000000條記錄後,再獲取10條記錄,其效能可想而知。這種查詢偏移量過大的場景我們稱為深分頁。
MySQL的深分頁會帶來效能下降等問題,而這個問題在分散式資料庫場景下,會變得更加複雜。
二、分散式資料庫的深分頁
彈性資料庫JED可以簡單理解成分散式的MySQL資料庫,這裡以JED為例,介紹下大多數分散式資料庫是如何做分頁查詢的。
2.1 彈性資料庫的分頁實現
以下圖的例子,我們來介紹多分片資料庫如何執行分頁查詢。t_order表以id作為主鍵以t_col1作為分片鍵,資料分佈如下:
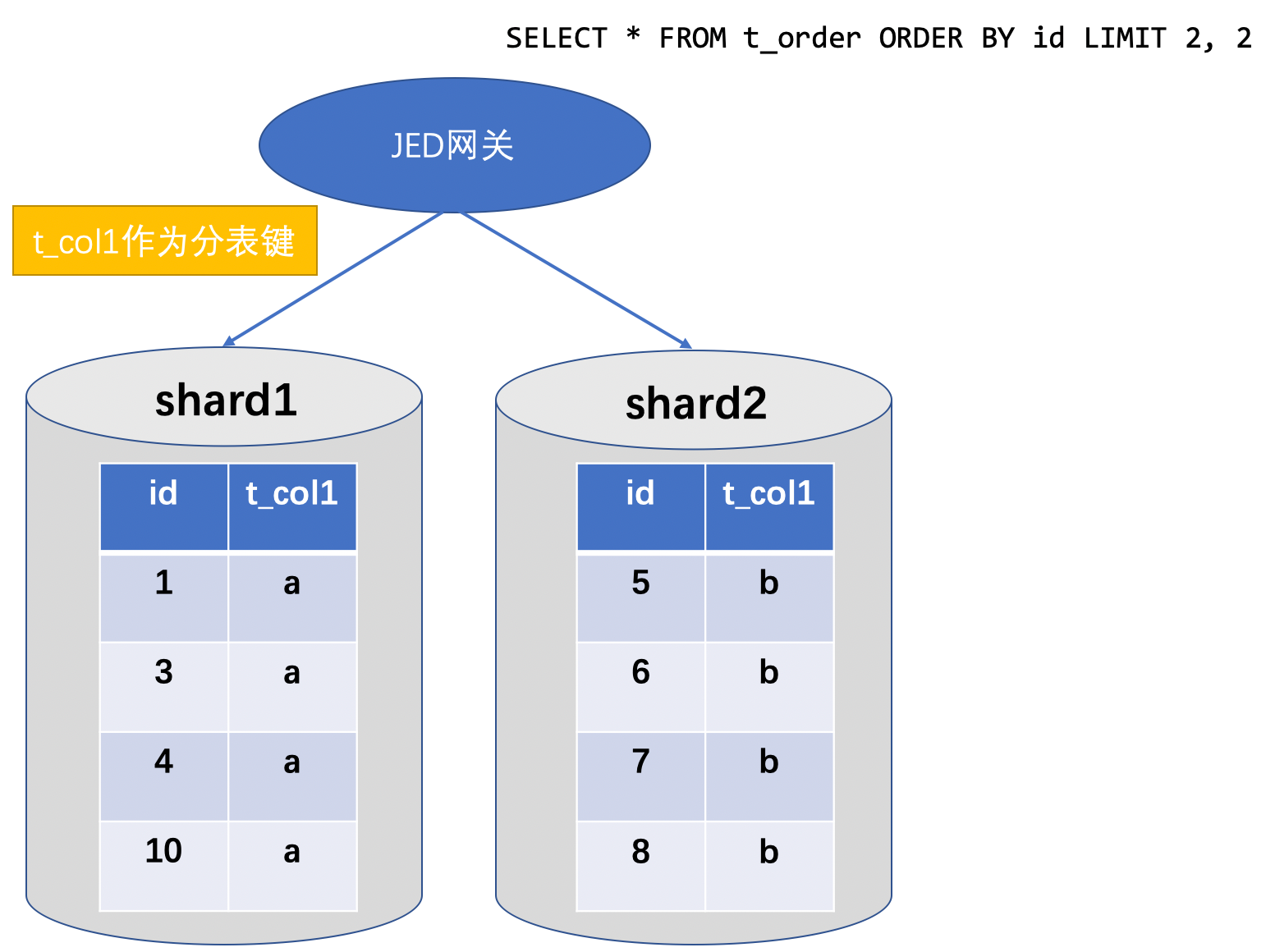
為了獲取t_order表第2條之後的兩條資料,執行SQL:
SELECT * FROM t_order ORDER BY id LIMIT 2, 2
假如只是簡單的把SQL下推到每個分片的MySQL範例執行,再在記憶體中對返回結果進行聚合排序處理,會是什麼效果呢?
分片1返回結果 {(id : 4, t_col1 : "a"), (id : 10, t_col1 : "a")};
分片2返回結果 {(id : 7, t_col1 : "b"), (id : 8, t_col1 : "b")};
記憶體排序計算後,將結果{(id : 4, t_col1 : "a"),(id : 7, t_col1 : "b")}返回,顯然這是一個錯誤的結果。為了得到正確的結果,需要每個分片都獲取前4條(2+2)資料,之後在記憶體中進行排序後分頁。因此,每個分片執行的SQL改寫為:
SELECT * FROM t_order ORDER BY id LIMIT 0, 4
再將返回的結果集在記憶體排序後,取第2條之後的兩條資料{(id : 4, t_col1 : "a"),(id : 5, t_col1 : "b")} 返回使用者。
2.2 深分頁存在的問題
由於分散式場景下,分頁語句會被放大。而這個問題,在執行深分頁SQL時(查詢偏移量過大),更加嚴重。深分頁會導致資料庫效能急劇下降,並且佔用大量的CPU、記憶體資源用於聚合排序運算。
當執行以下SQL,獲取1000000之後的10條資料:
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
在多分片場景下,為了保證資料的正確性,SQL會改寫為:
SELECT * FROM t_order ORDER BY id LIMIT 0, 1000010
將改寫後的SQL傳送至每一個分片執行,並將結果集返回,對結果集彙總處理後,把排序後的10條記錄返回給使用者。可以發現原SQL僅需要傳輸10條記錄至使用者端,而改寫之後的SQL則會傳輸1000010 * 2的記錄至使用者端,這將極大增大了OOM風險。
三、VtDriver的深分頁優化
3.1 SQL下推
VtDriver對查詢條件中帶有分片鍵,僅落至單一分片的查詢進行進一步優化。 落至單分片查詢的請求並不需要改寫SQL也可以保證記錄的正確性,因此在此種情況下,VtDriver並未進行SQL改寫,從而達到節省資源的效果。
3.2 流式處理
應用側主動開啟流式查詢功能。開啟流式查詢後,採用流式處理 + 歸併排序的方式來避免記憶體的過量佔用。由於SQL改寫不可避免的佔用了額外的頻寬,但並不會導致記憶體暴漲。 與直覺不同,大多數人認為VtDriver會將1000010 * 2記錄全部載入至記憶體,進而佔用大量記憶體而導致記憶體溢位。 但由於每個結果集的記錄是有序的,因此VtDriver每次比較僅獲取各個分片的當前結果集記錄,駐留在記憶體中的記錄僅為當前路由到的分片的結果集的當前遊標指向而已。 對於本身即有序的待排序物件,採用歸併排序,將會進一步降低效能損耗。
3.3 深分頁自動轉為流式查詢
針對深度分頁,VtDriver提供了根據深度分頁臨界值,自動開啟流式查詢的方式。
應用可通過deepPaginationThreshold引數,設定深度分頁臨界值。比如limit N,M,當N>deepPaginationThreshold設定的值時,會轉為流式查詢。
四、深分頁的優化建議
可以看到,即便VtDriver對於深分頁進行了優化,但是深分頁的使用場景還是會給應用帶來了很大的壓力。使用者通過優化SQL才可以從根本上解決問題。
4.1 範圍查詢
當可以保證ID的連續性時,使用者根據ID範圍進行分頁是比較好的解決方案:
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id
或通過記錄上次查詢結果的最後一條記錄的ID進行下一頁的查詢:
SELECT * FROM t_order WHERE id > 100000 LIMIT 10
4.2 子查詢
把查詢條件,轉移回到主鍵索引。由於子查詢中只獲取主鍵列對應的值,可以一定程度上降低應用OOM風險。
改寫後的SQL為(id為表t_order的主鍵):
SELECT * FROM t_order WHERE id >= (SELECT id FROM t_order limit 1000000, 1) LIMIT 10;
資料量過大時,使用者端仍有OOM風險,建議把子查詢僅作為應急過渡方案。
作者:京東零售 金越
來源:京東雲開發者社群 轉載請註明來源