【RocketMQ】訊息的拉取總結
在上一講中,介紹了訊息的儲存,生產者向Broker傳送訊息之後,資料會寫入到CommitLog中,這一講,就來看一下消費者是如何從Broker拉取訊息的。
RocketMQ訊息的消費以組為單位,有兩種消費模式:
廣播模式:同一個訊息佇列可以分配給組內的每個消費者,每條訊息可以被組內的消費者進行消費。
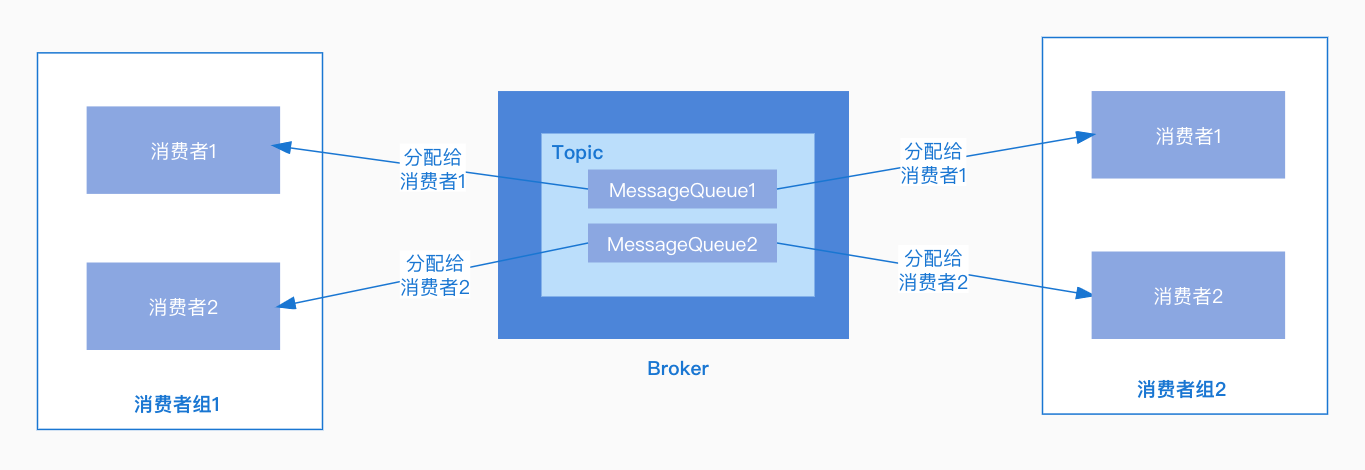
叢集模式:同一個消費組下,一個訊息佇列同一時間只能分配給組內的一個消費者,也就是一條訊息只能被組內的一個消費者進行消費。
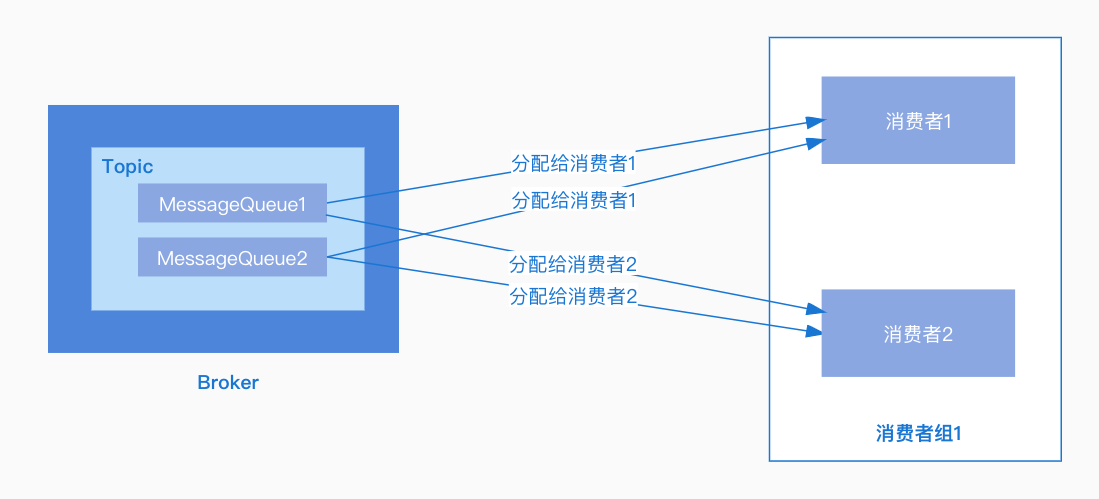
通常使用叢集模式的情況比較多,接下來以叢集模式(Push模式)為例看一下訊息的拉取過程。
消費者啟動時處理
消費者在啟動的時候主要做了以下幾件事情:
- Topic訂閱處理;
- MQClientInstance範例建立;
- 載入消費進度儲存物件,裡面儲存了每個訊息佇列的消費進度;
- 從NameServer更新Topic路由資訊;
- 向Broker進行註冊;
- 觸發負載均衡;
主題訂閱處理
RocketMQ消費者以組為單位,啟用消費者時,需要設定消費者組名稱以及要訂閱的Topic資訊(需要知道要消費哪個Topic上面的訊息):
@RunWith(MockitoJUnitRunner.class)
public class DefaultMQPushConsumerTest {
@Mock
private MQClientAPIImpl mQClientAPIImpl;
private static DefaultMQPushConsumer pushConsumer;
@Before
public void init() throws Exception {
// ...
// 消費者組名稱
String consumerGroup = "FooBarGroup";
// 範例化DefaultMQPushConsumer
pushConsumer = new DefaultMQPushConsumer(consumerGroup);
pushConsumer.setNamesrvAddr("127.0.0.1:9876");
// ...
// 設定訂閱的主題
pushConsumer.subscribe("FooBar", "*");
// 啟動消費者
pushConsumer.start();
}
}
所以消費者啟動的時候,首先會獲取訂閱的Topic資訊,由於一個消費者可以訂閱多個Topic,所以消費者使用一個Map儲存訂閱的Topic資訊,KEY為Topic名稱,VALUE為對應的表示式,之後會遍歷每一個訂閱的Topic,然後將其封裝為SubscriptionData物件,並加入到負載均衡物件RebalanceImpl中,等待進行負載均衡。
MQClientInstance範例建立
MQClientInstance中有以下幾個關鍵資訊:
- 訊息拉取服務:對應實現類為
PullMessageService,是用來從Broker拉取訊息的服務; - 負載均衡服務:對應的實現類為
RebalanceService,是用來進行負載均衡,為每個消費者分配對應的消費佇列; - 消費者列表(consumerTable):記錄該範例上的所有消費者資訊,key為消費者組名稱,value為消費者對應的
MQConsumerInner物件,每一個消費者啟動的時候會向這裡註冊,將自己加入到consumerTable中;

需要注意MQClientInstance範例是以clientId為單位建立的,相同的clientId共用一個MQClientInstance範例,clientId由以下資訊進行拼裝:
(1)伺服器的IP;
(2)範例名稱(instanceName);
(3)單元名稱(unitName)(不為空的時候才拼接);
最終拼接的clientId字串為:伺服器IP + @ + 範例名稱 + @ + 單元名稱。
所以在同一個伺服器上,如果範例名稱和單元名稱也相同的話,所有的消費者會共同使用一個MQClientInstance範例。
MQClientInstance啟動的時候會把訊息拉取服務和負載均衡服務也啟動(啟動對應的執行緒)。
獲取Topic路由資訊
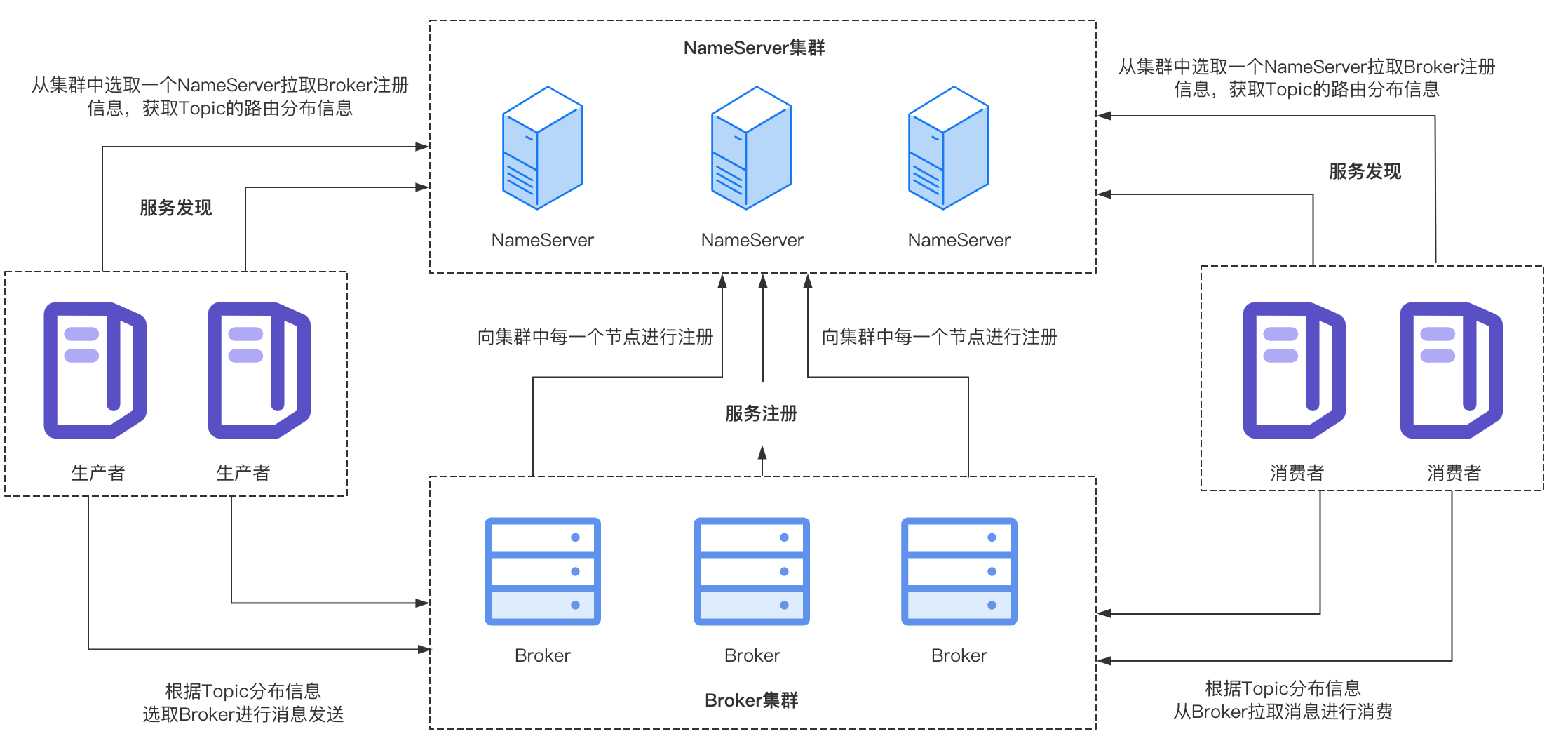
前面已經得知了當前消費者訂閱的Topic資訊,接下來需要知道這些Topic的分佈情況,也就是分佈在哪些Broker上,Topic的分佈資訊可以從NameServer中獲取到,因為Broker會向NameServer進行註冊,上報自己負責的Topic資訊,所以這一步消費者向NameServer傳送請求,從NameServer中拉取最新的Topic的路由資訊快取在本地。
載入消費進度
消費者在進行消費的時候,需要知道應該從哪個位置開始拉取訊息,OffsetStore類中記錄這些資料,不同的模式對應的實現類不同:
- 叢集模式:訊息的消費進度儲存在Broker中,由Broker記錄每個消費佇列的消費進度,對應實現類為
RemoteBrokerOffsetStore。 - 廣播模式:訊息的消費進度儲存在消費者端,對應實現類為
LocalFileOffsetStore。
這裡關注叢集模式,在叢集模式下,載入消費進度時,會進入RemoteBrokerOffsetStore的load方法,load方法是從本地載入檔案讀取消費進度,因為叢集模式下需要從Broker獲取,所以load方法什麼也沒幹,在負載均衡分配了訊息佇列,進行訊息拉取的時候再向Broker傳送請求獲取消費進度。
向Broker進行註冊
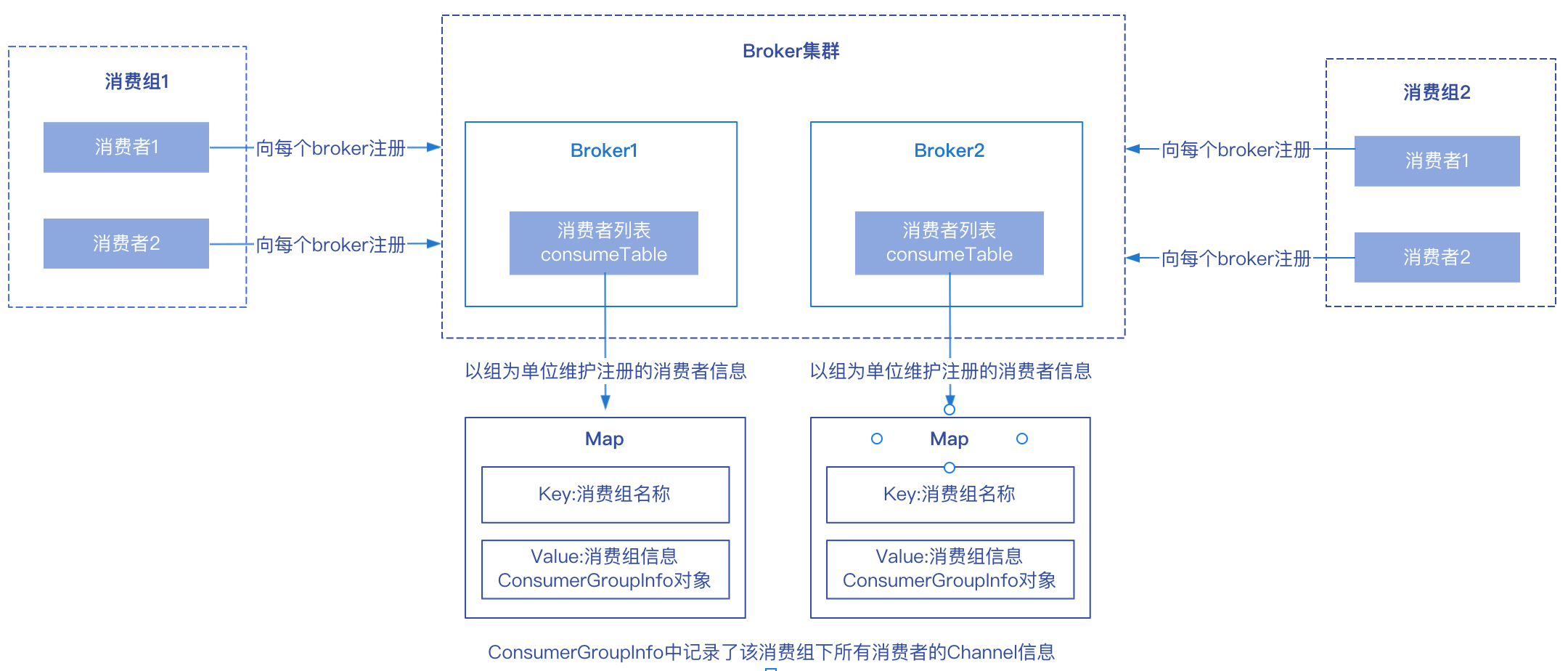
由於消費者增加或者減少會影響訊息佇列的分配,所以Broker需要感知消費者的上下線情況,消費者在啟動時會向所有的Broker傳送心跳包進行註冊,通知Broker消費者上線。
Broker收到消費者傳送的心跳包之後,會從請求中解析相關資訊,將該消費者註冊到Broker維護的消費者列表consumerTable中,其中KEY為消費者組名稱,Value為該消費組的詳細資訊(ConsumerGroupInfo物件),裡面記錄了該消費組下所有消費者的Channel資訊。
觸發負載均衡
啟動最後一步,會立即觸發一次負載均衡,為消費者分配訊息佇列。
負載均衡
負載均衡是通過消費者啟動時建立的MQClientInstance範例實現的(doRebalance方法),它的處理邏輯如下:
-
MQClientInstance中有一個消費者列表consumerTable,存放了該範例上註冊的所有消費者物件,Key為組名稱,Value為消費者,所以會遍歷所有的消費者,對該範例上註冊的每一個消費者進行負載均衡; -
對於每一個消費者,需要獲取其訂閱的所有Topic資訊,然後再對每一個Topic進行負載均衡,前面可知消費者訂閱的Topic資訊被封裝為了
SubscriptionData物件,所以這裡獲取到所有的SubscriptionData物件進行遍歷,開始為每一個消費者分配訊息佇列;
分配訊息佇列
這裡我們關注叢集模式下的分配,它的處理邏輯如下:
- 根據Topic獲取該Topic下的所有消費佇列(
MessageQueue物件);
消費者在啟動時向NameServer傳送請求獲取Topic的路由資訊,從中解析中每個主題對應的訊息佇列,放入負載均衡物件的
topicSubscribeInfoTable變數中,所以這一步直接從topicSubscribeInfoTable中獲取主題對應的訊息佇列即可。
-
根據主題資訊和消費者組名稱,查詢訂閱了該主題的所有消費者的ID:
(1)根據主題選取Broker:從NameServer中拉取的主題路資訊中可以找到每個主題分佈在哪些Broker上,從中隨機選取一個Broker;
(2)向Broker傳送請求:根據上一步獲取到的Broker,向其傳送請求,查詢訂閱了該主題的所有消費者的ID(消費者會向Broker註冊,所以可以通過Broker查詢訂閱了某個Topic的消費者); -
如果主題對應的訊息佇列集合和獲取到的消費者ID都不為空,對訊息佇列集合和消費ID集合進行排序;
-
獲取分配策略,根據具體的分配策略,為當前的消費者分配對應的消費佇列,RocketMQ預設提供了以下幾種分配策略:
-
AllocateMessageQueueAveragely:平均分配策略,根據訊息佇列的數量和消費者的個數計算每個消費者分配的佇列個數。
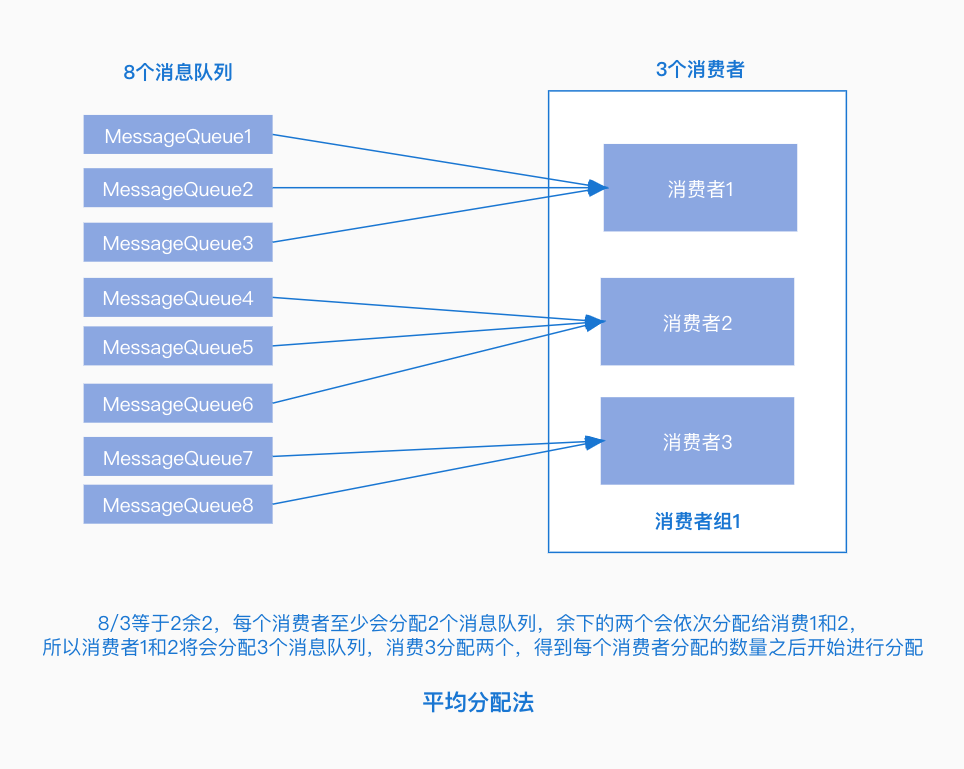
-
AllocateMessageQueueAveragelyByCircle:平均輪詢分配策略,將訊息佇列逐個分發給每個消費者。
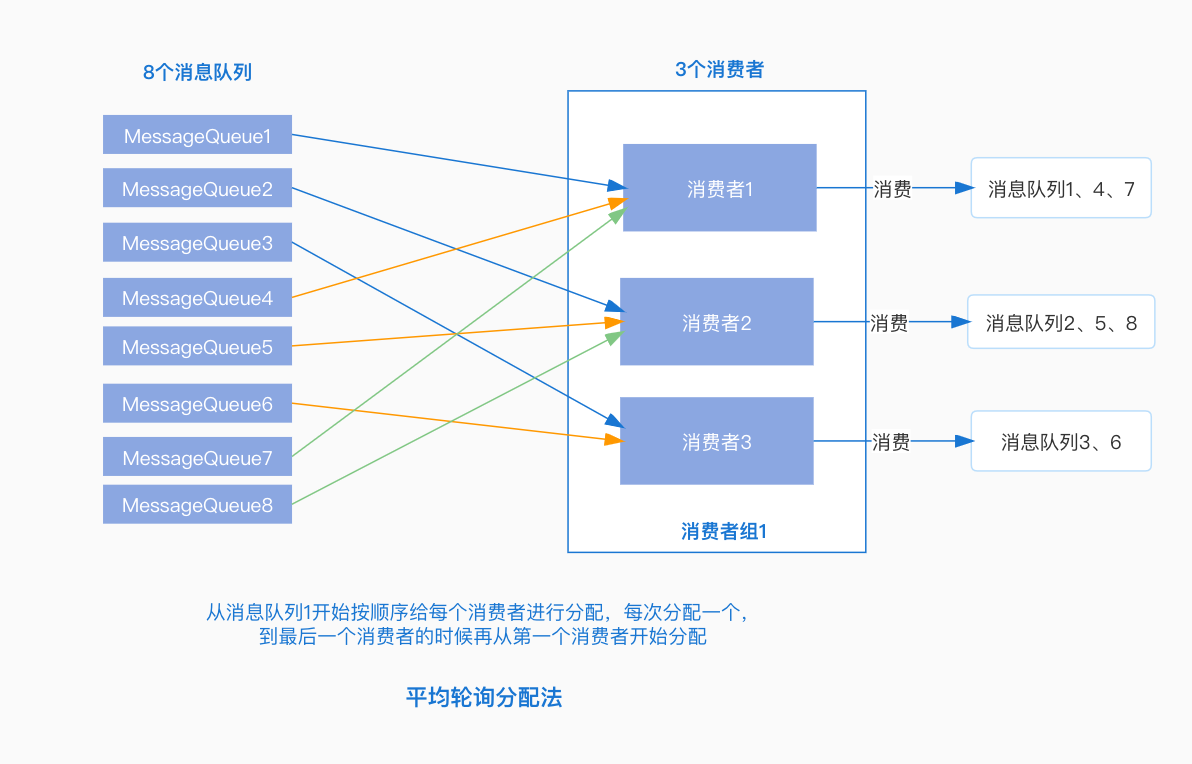
-
AllocateMessageQueueConsistentHash:根據一致性 hash進行分配。
-
AllocateMessageQueueByConfig:根據設定,為每一個消費者設定固定的訊息佇列 。
-
AllocateMessageQueueByMachineRoom:分配指定機房下的訊息佇列給消費者。
-
AllocateMachineRoomNearby:優先分配給同機房的消費者。
-
-
根據最新分配的訊息佇列,更新當前消費者負責的訊息處理佇列;
更新訊息處理佇列
每個訊息佇列(MessageQueue)對應一個處理佇列(ProcessQueue),後續使用這個ProcessQueue記錄的資訊進行訊息拉取:

分配給當前消費者的所有訊息佇列,由一個Map儲存(processQueueTable),KEY為訊息佇列,value為對應的處理佇列:

由於負載均衡之後,消費者負責的訊息佇列可能發生變化,所以這裡需要更新當前消費者負責的訊息佇列,它主要是拿負載均衡後重新分配給當前消費的訊息佇列集合與上一次記錄的分配資訊做對比,有以下兩種情況:
(1)某個訊息佇列之前分配給了當前消費者,但是這次沒有,說明此佇列不再由當前消費者消負責,需要進行刪除,此時將該訊息佇列對應的處理佇列中的dropped狀態置為true即可;
(2)某個消費者之前未分配給當前消費者,但是本次負載均衡之後分配給了當前消費者,需要進行新增,會新建一個處理佇列(ProcessQueue)加入到processQueueTable中;
對於情況2,由於是新增分配的訊息佇列,消費者還需要知道從哪個位置開始拉取訊息,所以需要通過OffsetStore來獲取儲存的消費進度,也就是上次消費到哪條訊息了,然後判斷本次從哪條訊息開始拉取。前面在消費者啟動的提到叢集模式下對應的實現類為RemoteBrokerOffsetStore,再進入到這一步的時候,才會向Broker傳送請求,獲取訊息佇列的消費進度,並更新到offsetTable中。
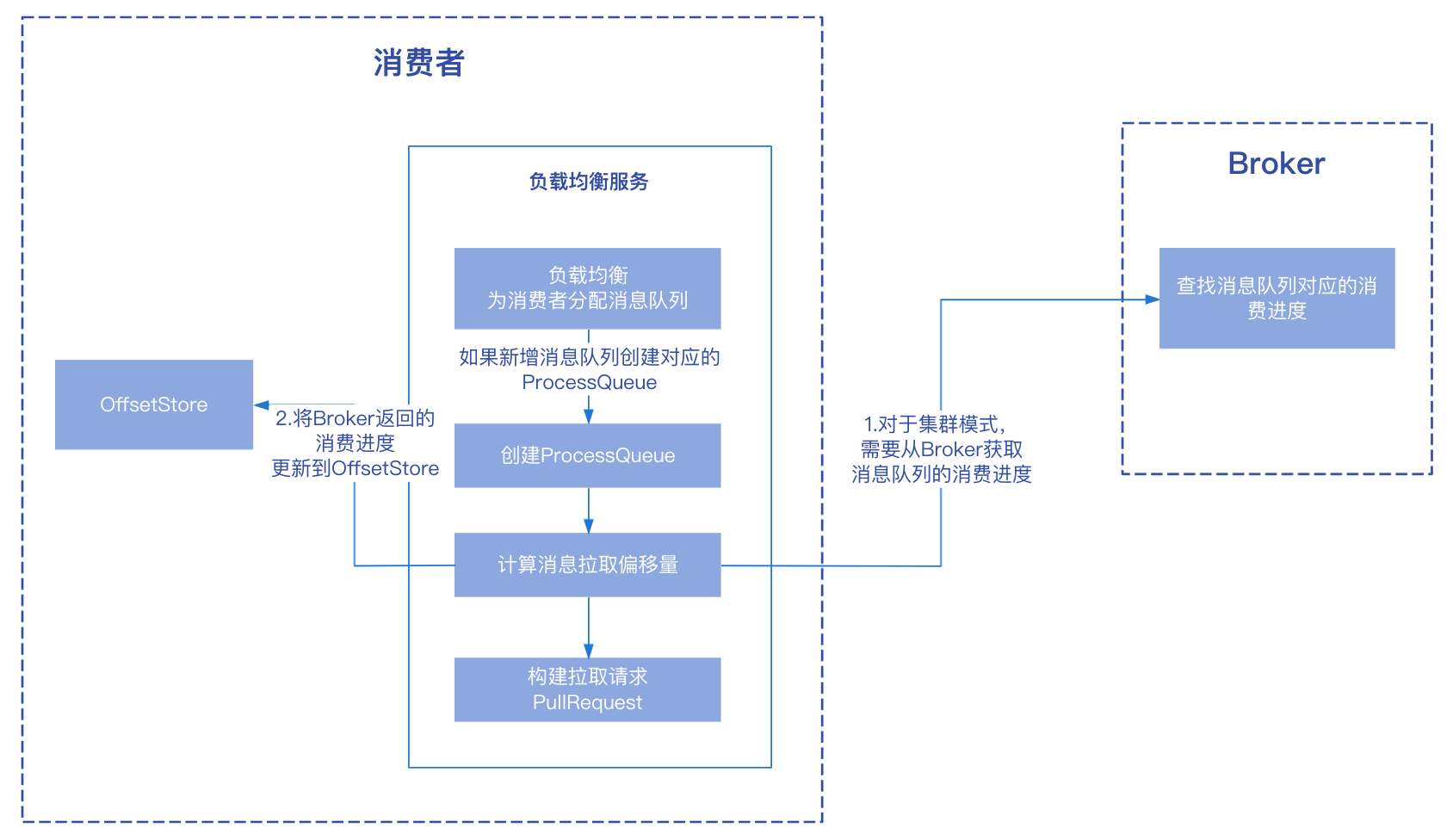
從Broker獲取消費進度之後,有以下幾種拉取策略:
(1)CONSUME_FROM_LAST_OFFSET(上次消費位置開始拉取):從OffsetStore獲取訊息佇列對應的消費進度值lastOffset,判斷是否大於等於0,如果大於0則返回lastOffset的值,從這個位置繼續拉取;
(2)CONSUME_FROM_FIRST_OFFSET(第一個位置開始拉取):從OffsetStore獲取訊息佇列對應的消費進度值lastOffset,如果大於等於0,依舊從這個位置繼續拉取,否則才從第一條訊息拉取,此時返回值為0;
(3)CONSUME_FROM_TIMESTAMP(根據時間戳拉取):從OffsetStore獲取訊息佇列對應的消費進度值lastOffset,如果大於等於0,依舊從這個位置繼續拉取,否則在不是重試TOPIC的情況下,根據消費者的啟動時間查詢應該從什麼位置開始消費;
nextOffset拉取偏移量的值確定之後,會將ProcessQueue加入到processQueueTable中,並構建對應的訊息拉取請求PullRequest,並設定以下資訊:
- consumerGroup:消費者組名稱;
- nextOffset:從哪條訊息開始拉取,設定的是上面計算的訊息拉取偏移量
nextOffset的值; - MessageQueue:訊息佇列,從哪個訊息佇列上面消費訊息;
- ProcessQueue:處理佇列,訊息佇列關聯的處理佇列;
PullRequest構建完畢之後會將其加入到訊息拉取服務中的一個阻塞佇列中,等待訊息拉取服務進行處理。
訊息拉取
消費者傳送拉取請求
訊息拉取服務中,使用了一個阻塞佇列,阻塞佇列中存放的是訊息拉取請求PullRequest物件,如果有訊息拉取請求到來,就會從阻塞佇列中取出對應的請求進行處理,從Broker拉取訊息,拉取訊息的處理邏輯如下:
- 從拉取請求
PullRequest中獲取對應的處理佇列ProcessQueue,先判斷是否置為Dropped刪除狀態,如果處於刪除狀態不進行處理; - 從處理佇列中獲取快取的訊息的數量及大小進行驗證判斷是否超過了設定的值,因為處理佇列中之前可能已經拉取了訊息還未處理完畢,為了不讓訊息堆積需要先處理之前的訊息,所以會延遲50毫秒後重新加入到拉取請求佇列中處理;
- 判斷是否是順序消費,這裡先不討論順序消費,如果是非順序消費,判斷processQueue中佇列最大偏移量和最小偏移量的間距是否超過
ConsumeConcurrentlyMaxSpan的值,如果超過需要進行流量控制,延遲50毫秒後重新加入佇列中進行處理; - 向Broker傳送拉取訊息請求,從Broker拉取訊息:
(1)ProcessQueue關聯了一個訊息佇列MessageQueue物件,訊息佇列物件中有其所在的Broker名稱,根據名稱再查詢該Broker的詳細資訊;
(2)根據第(1)步的查詢結果,構建訊息拉取請求,在請求中設定本次要拉取訊息的Topic名稱、訊息佇列ID等資訊,然後向Broker傳送請求; - 消費者處理拉取請求返回結果,上一步向Broker傳送請求的時候可以同步傳送也可以非同步傳送請求,對於非同步傳送請求當請求返回成功之後,會有一個回撥函數,在回撥函數中處理訊息拉取結果。
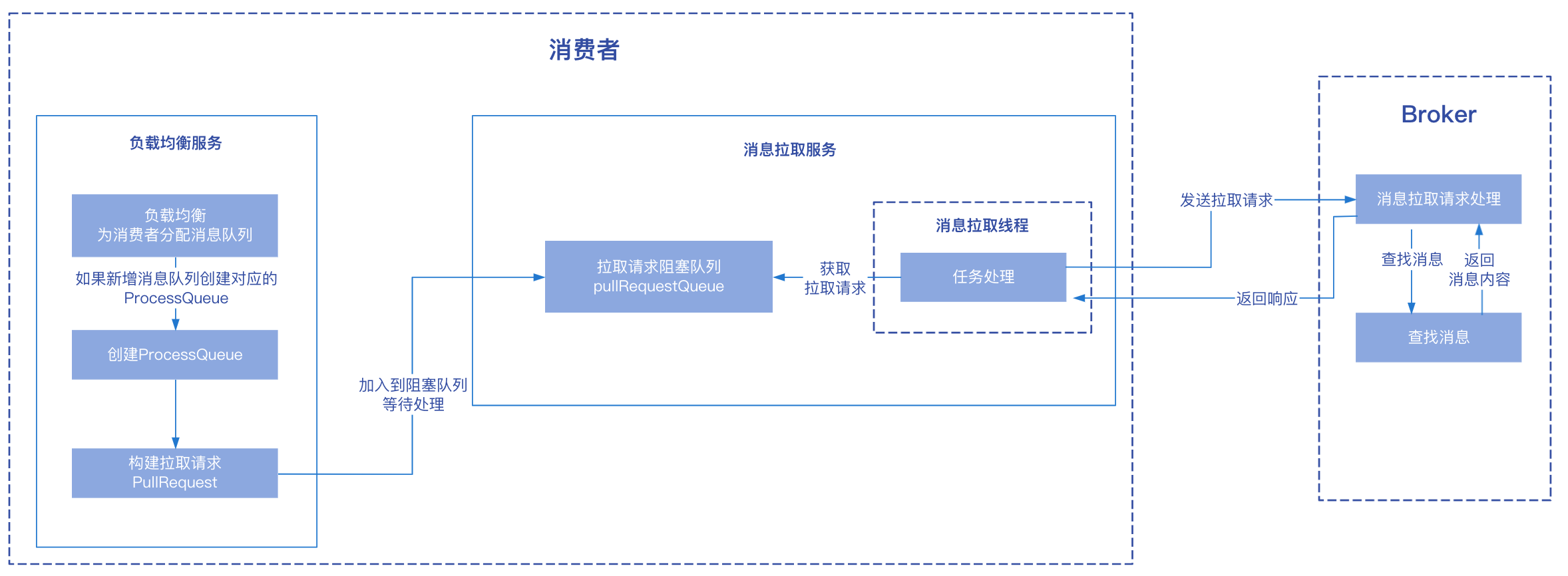
Broker處理訊息拉取請求
ConsumeQueue
RocketMQ在訊息儲存的時候將訊息順序寫入CommitLog檔案,如果想根據Topic對訊息進行查詢,需要掃描所有CommitLog檔案,這種方式效能低下,所以RocketMQ又設計了ConsumeQueue儲存訊息的邏輯索引,在RocketMQ的儲存檔案目錄下,有一個consumequeue資料夾,裡面又按Topic分組,每個Topic一個資料夾,Topic資料夾內是該Topic的所有訊息佇列,以訊息佇列ID命名資料夾,每個訊息佇列都有自己對應的ConsumeQueue檔案:
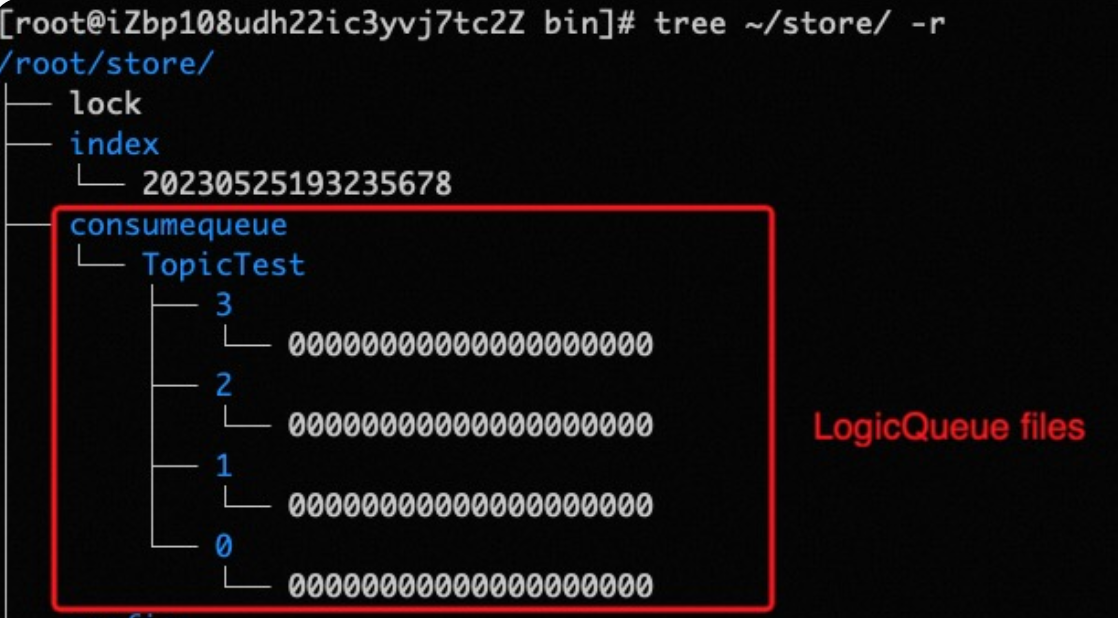
ConsumeQueue中儲存的每條資料大小是固定的,總共20個位元組:

- 訊息在CommitLog檔案的偏移量,佔用8個位元組;
- 訊息大小,佔用4個位元組;
- 訊息Tag的hashcode值,用於tag過濾,佔用8個位元組;
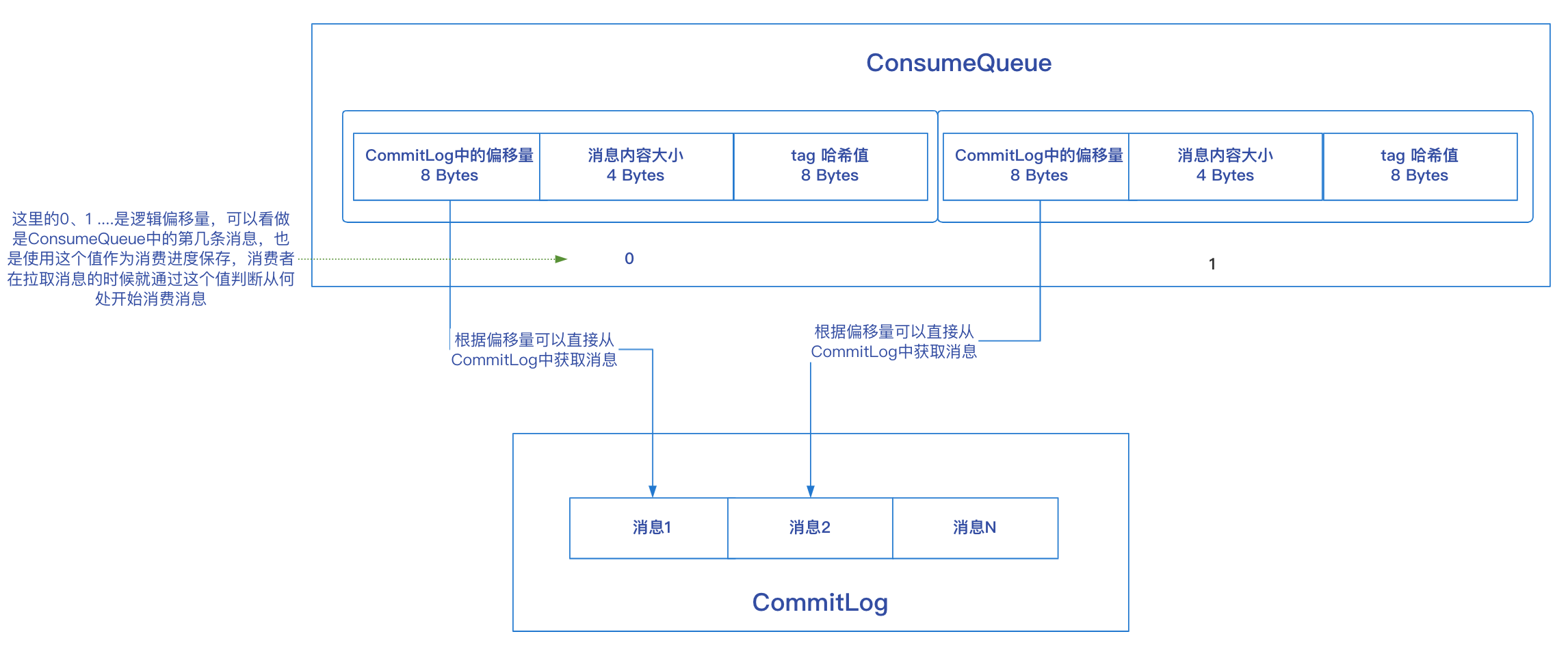
Broker在收到消費傳送的拉取訊息請求後,會根據拉取請求中的Topic名稱和訊息佇列ID(queueId)查詢對應的消費資訊ConsumeQueue物件:
Broker中的consumeQueueTable中儲存了每個Topic對應的消費佇列資訊,Key為Topic名稱,Value為Topic對應的消費佇列資訊,它又是一個MAP,其中Key為訊息佇列ID(queueId),value為該訊息佇列的消費消費資訊(ConsumeQueue物件)。
在獲取到息ConsumeQueue之後,從中可以獲取其中記錄的最小偏移量minOffset和最大偏移量maxOffset,然後與拉取請求中攜帶的訊息偏移量offset的值對比進行合法校驗,校驗通過才可以查詢訊息,對於訊息查詢結果大概有如下幾種狀態:
nextOffsetCorrection方法:用於校正消費者的拉取偏移量,不過需要注意,當前Broker是主節點或者開啟了
OffsetCheckInSlave校驗時,才會對拉取偏移量進行糾正,所以以下幾種狀態中如果呼叫了此方法進行校正,前提是滿足此條件。
- NO_MESSAGE_IN_QUEUE:如果
CommitLog中的最大偏移量maxOffset值為0,說明當前訊息佇列中還沒有訊息,返回NO_MESSAGE_IN_QUEUE狀態; - OFFSET_TOO_SMALL:如果待拉取偏移量
offset的值小於CommitLog檔案的最小偏移量minOffset,說明拉取進度值過小,呼叫nextOffsetCorrection校正下一次的拉取偏移量為CommitLog檔案的最小偏移量(需要滿足校正的條件),並將這個偏移量放入nextBeginOffset變數; - OFFSET_OVERFLOW_ONE:如果待拉取偏移量
offset等於CommitLog檔案的最大偏移量maxOffset,依舊呼叫nextOffsetCorrection方法進行校正(需要滿足校正的條件),只不過校正的時候使用的還是offset的值,可以理解為這種情況什麼也沒幹。 - OFFSET_OVERFLOW_BADLY:如果待拉取偏移量
offset大於CommitLog檔案最大偏移量maxOffset,說明拉取偏移量越界,此時有以下兩種情況:- 如果最小偏移
minOffset量為0,呼叫nextOffsetCorrection方法校正下一次拉取偏移量為minOffset的值(需要滿足校正的條件),也就是告訴消費者,下次從偏移量為0的位置開始拉取訊息; - 如果最小偏移量
minOffset不為0,呼叫nextOffsetCorrection方法校正下一次拉取偏移量為maxOffset的值(需要滿足校正的條件),將下一次拉取偏移量的值設定為最大偏移量;
- 如果最小偏移
- NO_MATCHED_LOGIC_QUEUE:如果根據主題未找到訊息佇列,返回此狀態;
- FOUND:待拉取訊息偏移量
offset的值介於最大最小偏移量之間,此時可以正常查詢訊息;
需要注意以上是訊息查詢的結果狀態,Broker並沒有使用這個狀態直接返回給消費者,而是又做了一次處理。
經過以上步驟後,除了查詢到的訊息內容,Broker還會在訊息返回結果中設定以下資訊:
- 查詢結果狀態;
- 下一次拉取的偏移量,也就是
nextBeginOffset變數的值; CommitLog檔案的最小偏移量minOffset和最大偏移量maxOffset;
消費者對拉取結果的處理
消費者收到Broker返回的響應後,對響應結果進行處理:
- FOUND:訊息拉取請求成功,此時從響應中獲取Broker返回的下一次拉取偏移量的值,更新到拉取請求中,然後進行以下判斷:
- 如果拉取到的訊息內容為空,將拉取請求放入到阻塞佇列中再進行一次拉取;
- 如果拉取到的訊息內容不為空,將訊息提交到
ConsumeMessageService中進行消費(非同步處理),然後判斷拉取間隔的值是否大於0,如果大於0,會延遲一段時間進行下一次拉取,如果拉取間隔小於0表示需要立刻進行下一次拉取,此時將拉取請求加入阻塞佇列中進行下一次拉取。
- NO_MATCHED_MSG:沒有匹配的訊息,使用Broker返回的下一次拉取偏移量的值作為新的拉取訊息偏移量,然後將拉取請求加入阻塞佇列中立刻進行下一次進行拉取。
- OFFSET_ILLEGAL:拉取偏移量不合法,此時使用Broker返回的下一次拉取偏移量的值,更新到消費者記錄的訊息拉取偏移量中(
offsetStore),並持久化儲存,然後將當前的拉取請求中的處理佇列狀態置為dorp並刪除處理佇列,等待下一次重新構建拉取請求進行處理。
RocketMQ訊息拉取相關原始碼可參考:【RocketMQ】【原始碼】訊息的拉取