Code Llama:Llama 2 學會寫程式碼了!
引言
Code Llama 是為程式碼類任務而生的一組最先進的、開放的 Llama 2 模型,我們很高興能將其整合入 Hugging Face 生態系統!Code Llama 使用與 Llama 2 相同的社群許可證,且可商用。
今天,我們很高興能釋出 Hugging Face 對 Code Llama 的全面支援 , 包括:
- Hub 上的模型支援,包括模型卡及許可證
- Transformers 已整合 Code Llama
- TGI 已整合 Code Llama,以支援對其進行快速高效的產品級推理
- 推理終端 (Inference Endpoints) 已整合 Code Llama
- 對 Code Llama 的程式碼基準測試結果已釋出
程式碼大語言模型的發展對於軟體工程師來說無疑是振奮人心的,因為這意味著他們可以通過 IDE 中的程式碼補全功能來提高生產力,並利用其來處理重複或煩人的任務,例如為程式碼編寫檔案字串或建立單元測試。
目錄
Code Llama 簡介
Code Llama 包含 3 個不同引數量的版本,分別為: 7 億引數版、13 億引數版 以及 340 億引數版。在訓練基礎模型時,先用同等引數量的 Llama 2 模型初始化權重,然後在 5000 億詞元的程式碼資料集上訓練。 Meta 還對訓得的基礎模型進行了兩種不同風格的微調,分別為: Python 專家版 (再加 1000 億個額外詞元) ; 以及指令微調版,其可以理解自然語言指令。
這些模型在 Python、C++、Java、PHP、C#、TypeScript 和 Bash 中都展現出最先進的效能。7B 和 13B 基礎版和指令版支援完形填空,因此非常適合用作程式碼助手。
Code Llama 基於 16k 上下文視窗訓練。此外,這三個尺寸的模型還進行了額外的長上下文微調,使其上下文視窗最多可延伸至 10 萬詞元。
受益於 RoPE 擴充套件方面的最新進展,將 Llama 2 的 4k 上下文視窗增加到 Code Llama 的 16k (甚至可以外插至 100k) 成為可能。社群發現可以對 Llama 的位置嵌入進行線性插值或頻域插值,這使得通過微調讓基礎模型輕鬆擴充套件到更大的上下文視窗成為可能。在 Code Llama 中,他們把頻域縮放和鬆弛技術二者結合起來: 微調長度是縮放後的預訓練長度的一小部分。這個做法賦予了模型強大的外推能力。
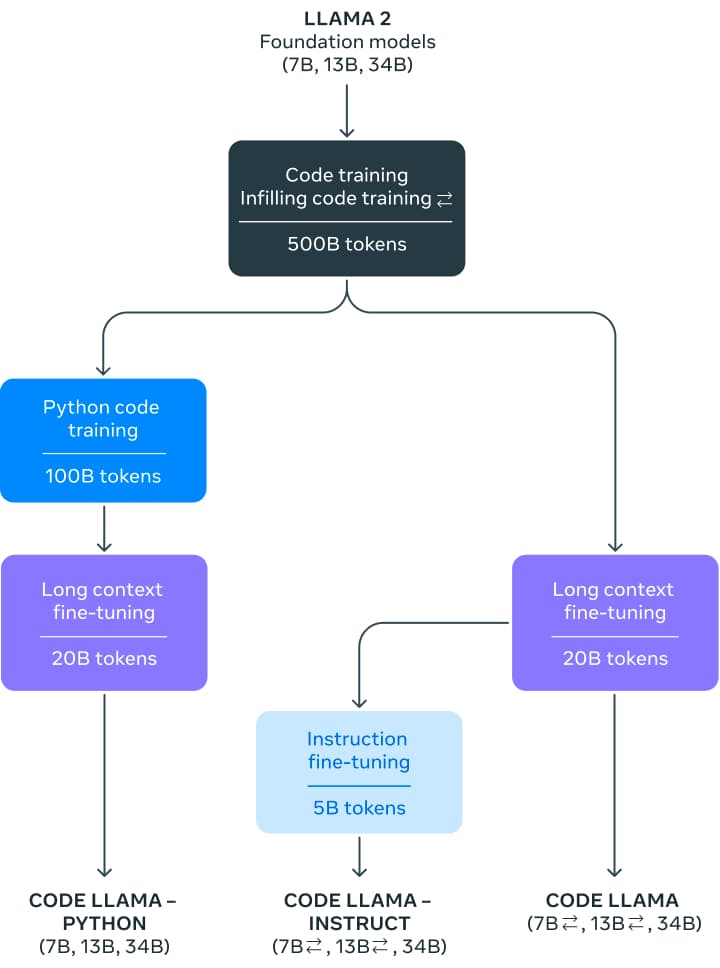
第一步是在 5000 億詞元的公開程式碼資料集上訓練出一個模型。該資料集中除了有程式碼資料集外,還包含一些自然語言資料集,例如有關程式碼和程式碼片段的討論,且最終資料集是使用近似去重法去過重的。不幸的是,Meta 沒有披露有關該資料集的更多資訊。
在對模型進行指令微調時,使用了兩個資料集: 為 Llama 2 Chat 收集的指令微調資料集和自指令資料集。自指令資料集收集了 Llama 2 編制出的程式設計面試問題,然後使用 Code Llama 生成單元測試和解答,最後通過執行測試來評估解答。
如何使用 Code Llama?
Transformers 從 4.33 版開始支援 Code Llama。在此之前,需要從主分支進行原始碼安裝才行。
演示
我們準備了 這個 Space 或下面的 Playground 以供大家嘗試 Code Llama 模型 (130 億引數!):
這個演示背後使用了 Hugging Face TGI,HuggingChat 也用了相同的技術,具體內容見下文。
你還可以玩玩 這個聊天機器人,或者複製一份到自己的賬號下以供你使用 – 它是自含的,因此你可以隨心所欲地修改程式碼!
Transformers
從最新發布的 transformers 4.33 開始,你可以在 Code Llama 上應用 HF 生態系統中的所有工具,例如:
- 訓練和推理指令碼和範例
- 安全的檔案格式 (
safetensors) - 與
bitsandbytes(4 位元量化) 和 PEFT 等工具結合使用 - 執行模型生成所需的工具及輔助程式碼
- 匯出模型以進行部署的機制
在 transformers 4.33 釋出之前,使用者需要從主分支原始碼安裝 transformers 。
!pip install git+https://github.com/huggingface/transformers.git@main accelerate
程式碼補全
我們可以使用 7B 和 13B 模型進行文字/程式碼補全或填充。下述程式碼演示瞭如何使用 pipeline 介面來進行文字補全。執行時,只需選擇 GPU 即可在 Colab 的免費 GPU 上執行。
from transformers import AutoTokenizer
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline(
"text-generation",
model="codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'def fibonacci(',
do_sample=True,
temperature=0.2,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
其輸出如下:
Result: def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
return
Code Llama 雖然專精於程式碼理解,但其仍是一個語言模型。你仍然可以使用相同的生成策略來自動完成註釋或自然語言文字。
程式碼填充
這是程式碼模型才能完成的專門任務。該模型經過訓練後,可以生成與給定上下文最匹配的程式碼 (包括註釋)。這是程式碼助理的典型使用場景: 要求它們根據上下文填充當前遊標處的程式碼。
此任務需要使用 7B 和 13B 的 基礎 或 指令 模型。任何 34B 或 Python 版模型不能用於此任務。
填充類任務需要在生成時使用與訓練時相同格式的輸入文字,因為訓練時會使用特殊的分隔符來區分提示的不同部分。幸運的是, transformers 的 CodeLlamaTokenizer 已經幫你把這事做了,如下所示:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
prompt = '''def remove_non_ascii(s: str) -> str:
""" <FILL_ME>
return result
'''
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
output = model.generate(
input_ids,
max_new_tokens=200,
)
output = output[0].to("cpu")
filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True)
print(prompt.replace("<FILL_ME>", filling))
輸出如下:
def remove_non_ascii(s: str) -> str:
""" Remove non-ASCII characters from a string.
Args:
s: The string to remove non-ASCII characters from.
Returns:
The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c
return result
在底層,分詞器會 自動按 <fill_me> 分割 並生成一個格式化的輸入字串,其格式與 訓練時的格式 相同。這樣做既避免了使用者自己格式化的很多麻煩,也避免了一些很難偵錯的陷阱,例如詞元粘合 (token glueing)。
對話式指令
如上所述,基礎模型可用於補全和填充。Code Llama 還包含一個適用於對話場景的指令微調模型。
為此類任務準備輸入時,我們需要一個提示模板。一個例子是我們在 Llama 2 博文 中描述的模板,如下:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST]{{ model_answer_1 }} </s><s>[INST]{{ user_msg_2 }} [/INST]
請注意,系統提示 ( system prompt ) 是可選的 - 沒有它模型也能工作,但你可以用它來進一步指定模型的行為或風格。例如,如果你希望獲得 JavaScript 的答案,即可在此宣告。在系統提示之後,你需要提供對話互動歷史: 使用者問了什麼以及模型回答了什麼。與填充場景一樣,你需要注意分隔符的使用。輸入的最後必須是新的使用者指令,這對模型而言是讓其提供答案的訊號。
以下程式碼片段演示瞭如何在實際工作中使用該模板。
- 首次使用者輸入,無系統提示
user = 'In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?'
prompt = f"<s>[INST]{user.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
- 首次使用者查詢,有系統提示
system = "Provide answers in JavaScript"
user = "Write a function that computes the set of sums of all contiguous sublists of a given list."
prompt = f"<s><<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
- 含對話歷史的多輪對話
該過程與 Llama 2 中的過程相同。為了最清楚起見,我們沒有使用迴圈或泛化此範例程式碼:
system = "System prompt"
user_1 = "user_prompt_1"
answer_1 = "answer_1"
user_2 = "user_prompt_2"
answer_2 = "answer_2"
user_3 = "user_prompt_3"
prompt = f"<<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user_1}"
prompt = f"<s>[INST]{prompt.strip()} [/INST]{answer_1.strip()} </s>"
prompt += f"<s>[INST]{user_2.strip()} [/INST]{answer_2.strip()} </s>"
prompt += f"<s>[INST]{user_3.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
4 位元載入
將 Code Llama 整合到 Transformers 中意味著我們可以立即獲得 4 位元載入等高階功能的支援。這使得使用者可以在英偉達 3090 卡等消費類 GPU 上執行大型的 32B 引數量模型!
以下是在 4 位元模式下執行推理的方法:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
使用 TGI 和推理終端
TGI 是 Hugging Face 開發的生產級推理容器,可用於輕鬆部署大語言模型。它包含連續批次處理、流式輸出、基於張量並行的多 GPU 快速推理以及生產級的紀錄檔記錄和跟蹤等功能。
你可以在自己的基礎設施上使用 TGI,也可以使用 Hugging Face 的 推理終端。要部署 Codellama 2 模型,請登陸其 模型頁面,然後單擊 Deploy -> Inference Endpoints 按鈕。
- 推理 7B 模型,我們建議選擇「GPU [medium] - 1x Nvidia A10G」。
- 推理 13B 模型,我們建議選擇「GPU [xlarge] - 1x Nvidia A100」。
- 推理 34B 模型,我們建議啟用
bitsandbytes量化並選擇「GPU [1xlarge] - 1x Nvidia A100」或「GPU [2xlarge] - 2x Nvidia A100」
注意: 你可能需要發郵件給 [email protected] 申請配額升級才能存取 A100
你可以在我們的博文中詳細瞭解如何 使用 Hugging Face 推理終端部署 LLM,該 博文 還包含了有關其支援的超參以及如何使用 Python 和 Javascript API 流式生成文字的相關知識。
評估
程式碼語言模型通常在 HumanEval 等資料集上進行基準測試,其包含了一系列程式設計題,我們將函數簽名和檔案字串輸入給模型,模型需要完成函數體程式碼的編寫。接著是執行一組預定義的單元測試來驗證所提出的解答。最後是報告通過率,即有多少解答通過了所有測試。pass@1 度量了模型一次生成即通過的頻率,而 pass@10 描述了模型生成 10 個候選解答其中至少有一個解答通過的頻率。
雖然 HumanEval 是一個 Python 基準測試,但社群付出了巨大努力將其轉成更多程式語言,從而實現更全面的評估。其中一種方法是 MultiPL-E,它將 HumanEval 翻譯成十多種程式語言。我們正在基於其製作一個 多語言程式碼排行榜,這樣社群就可以用它來比較不同模型在各種程式語言上的表現,以評估哪個模型最適合他們的需求。
| 模型 | 許可證 | 訓練資料集是否已知 | 是否可商用 | 預訓練詞元數 | Python | JavaScript | Leaderboard Avg Score |
|---|---|---|---|---|---|---|---|
| CodeLlaMa-34B | Llama 2 license | ❌ | ✅ | 2,500B | 45.11 | 41.66 | 33.89 |
| CodeLlaMa-13B | Llama 2 license | ❌ | ✅ | 2,500B | 35.07 | 38.26 | 28.35 |
| CodeLlaMa-7B | Llama 2 license | ❌ | ✅ | 2,500B | 29.98 | 31.8 | 24.36 |
| CodeLlaMa-34B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 53.29 | 44.72 | 33.87 |
| CodeLlaMa-13B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 42.89 | 40.66 | 28.67 |
| CodeLlaMa-7B-Python | Llama 2 license | ❌ | ✅ | 2,620B | 40.48 | 36.34 | 23.5 |
| CodeLlaMa-34B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.79 | 45.85 | 35.09 |
| CodeLlaMa-13B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 50.6 | 40.91 | 31.29 |
| CodeLlaMa-7B-Instruct | Llama 2 license | ❌ | ✅ | 2,620B | 45.65 | 33.11 | 26.45 |
| StarCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,035B | 33.57 | 30.79 | 22.74 |
| StarCoderBase-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 30.35 | 31.7 | 22.4 |
| WizardCoder-15B | BigCode-OpenRail-M | ❌ | ✅ | 1,035B | 58.12 | 41.91 | 32.07 |
| OctoCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 45.3 | 32.8 | 24.01 |
| CodeGeeX-2-6B | CodeGeeX License | ❌ | ❌ | 2,000B | 33.49 | 29.9 | 21.23 |
| CodeGen-2.5-7B-Mono | Apache-2.0 | ✅ | ✅ | 1400B | 45.65 | 23.22 | 12.1 |
| CodeGen-2.5-7B-Multi | Apache-2.0 | ✅ | ✅ | 1400B | 28.7 | 26.27 | 20.04 |
注意: 上表中的分數來自我們的程式碼排行榜,所有模型均使用相同的設定。欲瞭解更多詳情,請參閱 排行榜。