K8s 多叢集實踐思考和探索
作者:vivo 網際網路容器團隊 - Zhang Rong
本文主要講述了一些對於K8s多叢集管理的思考,包括為什麼需要多叢集、多叢集的優勢以及現有的一些基於Kubernetes衍生出的多叢集管理架構實踐。
一、為什麼需要多叢集
隨著K8s和雲原生技術的快速發展,以及各大廠商在自己的資料中心使用K8s的API進行容器化應用編排和管理,讓應用交付本身變得越來越標準化和統一化,並且實現了與底層基礎設施的完全解耦,為多叢集和混合雲提供了一個堅實技術基礎。談到多叢集多雲的資料中心基礎架構,會想到為什麼企業需要多叢集?
1.單叢集容量限制:
叢集上限5000個節點和15萬個Pod。同時單叢集的最大節點數不是一個確定值,其受到叢集部署方式和業務使用叢集資源的方式的影響。
2.多雲混合使用:
避免被單家供應商鎖定,不同叢集的最新技術規劃,或是出於成本等考慮,企業選擇了多雲架構。
3.業務流量突發:
正常情況下使用者使用自己的 IDC 叢集提供服務,當應對突發大流量時,迅速將應用擴容到雲上叢集共同提供服務,需具備公有云 IaaS接入,可以自動擴縮容計算節點,將公有云作為備用資源池。該模式一般針對無狀態的服務,可以快速彈性擴充套件,主要針對使用 CPU、記憶體較為密集的服務,如搜尋、查詢、計算等型別的服務。
4.業務高可用:
單叢集無法應對網路故障或者資料中心故障導致的服務的不可用。通常主要服務的叢集為一個,另一個叢集週期性備份。或者一個叢集主要負責讀寫,其他備份叢集唯讀,在主叢集所在的雲出現問題時可以快速切換到備份叢集。該模式可用於資料量較大的儲存服務,如部署一個高可用的mysql叢集,一個叢集負責讀寫,其他2個叢集備份唯讀,可以自動切換主備。
5.異地多活:
資料是實時同步的,多叢集都可以同時讀寫,這種模式通常針對極其重要的資料,如全域性統一的使用者賬號資訊等。
6.地域親和性:
儘管國內網際網路一直在提速,但是處於頻寬成本的考量,同一呼叫鏈的服務網路距離越近越好。服務的主調和被調部署在同一個地域內能夠有效減少頻寬成本;並且分而治之的方式讓應用服務本區域的業務,也能有效緩解應用服務的壓力。
二、多叢集探索
2.1 社群在多叢集上的探索
當前基於 K8s 多叢集專案如下:
1.Federation v1:
已經被社群廢棄,主要原因在於 v1 的設計試圖在 K8s 之上又構建一層 Federation API,直接遮蔽掉了已經取得廣泛共識的 K8s API ,這與雲原生社群的發展理念是相悖。
2.Federation v2:
已經被社群廢棄,提供了一個可以將任何 K8s API type 轉換成有多叢集概念的 federated type 的方法,以及一個對應的控制器以便推播這些 federated 物件 (Object)。而它並不像 V1 一樣關心複雜的推播策略(V1 的 Federation Scheduler),只負責把這些 Object 分發到使用者事先定義的叢集去。這也就意味著 Federation v2 的主要設計目標,其實是向多叢集推播 RBAC,policy 等叢集設定資訊。
3.Karmada:
參考Kubernetes Federation v2 核心實踐,並融入了眾多新技術,包括 Kubernetes 原生 API 支援、多層級高可用部署、多叢集自動故障遷移、多叢集應用自動伸縮、多叢集服務發現等,並且提供原生 Kubernetes 平滑演進路徑。
4.Clusternet:
是一個兼具多叢集管理和跨叢集應用編排的開源雲原生管控平臺,解決了跨雲、跨地域、跨可用區的叢集管理問題。在專案規劃階段,就是面向未來混合雲、分散式雲和邊緣計算等場景來設計的,支援海量叢集的接入和管理、應用分發、流量治理等。
5.OCM:
OCM 是一款 Kubernetes 多叢集平臺開源專案,它可以幫助你大大簡化跨雲/多雲場景下的叢集管理,無論這些叢集是在雲上託管,還是部署在自建資料中心,再或者是在邊緣資料中心中。OCM 提供的基礎模型可以幫助我們同時理解單叢集內部的容量情況,也可以橫跨多叢集進行資源/工作負載的編排排程。與此同時,OCM 還提供了一系列強大的擴充套件性或者叫做外掛框架(addon-framework)來幫助我們整合 CNCF 生態中的其他專案,這些擴充套件性也可以幫助我們無侵入地針對你的特定使用場景手工擴充套件特性。
以上多叢集專案主要功能為資源分發和排程,還有如多雲基礎設施管理cluster-api,多叢集檢索Clusterpedia,多叢集pod互通submariner,multicluster-ingress解決多叢集的ingress,服務治理和流量排程 Service Mesh,如istio、cilium等網路元件實現的multi cluster mesh解決跨叢集的mesh網路管理,以及結合儲存相關專案實現跨叢集儲存管理和遷移等。
2.2 vivo 在多叢集上的探索
2.2.1 非聯邦叢集管理

非聯邦多叢集管理系統主要是進行資源管理、運維管理和使用者管理,提供匯入K8s叢集許可權功能,並通過統一 Web 介面進行檢視和管理。這類工具不引入額外叢集聯邦的複雜,保持每個叢集的獨立性,同時通過統一的 Web 介面來檢視多個叢集的資源使用情況,支援通過 Web 介面建立 Deployment、Service 和負載均衡等,並且會整合持續整合、持續交付和監控告警等功能。由於叢集聯邦技術還在發展,大多數企業傾向於使用這種方式來運維和管理多叢集 Kubernetes 環境。當前vivo主要是通過這種方式管理多叢集。
2.2.2 聯邦叢集管理
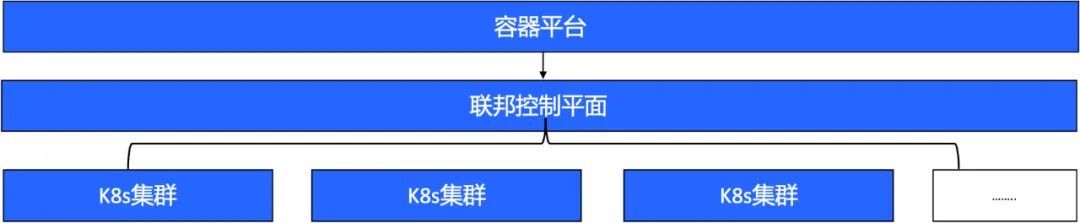
聯邦叢集主要將資源聯邦化,實現資源的統一管理和排程。隨著K8s在資料中心大量使用,K8s已成為基礎設施管理的標準,不同區域部署已非常普遍。如K8s執行在雲上來託管叢集、企業自建資料中心的私有云、邊緣計算等。越來越多的企業投入到多叢集管理專案,當然聯邦叢集肯定會增加整體架構的複雜度,叢集之間的狀態同步也會增加控制面的額外開銷。儘管增加了所有的複雜性,但普遍存在的多叢集拓撲引入了新的令人興奮的潛力。這種潛力超越了目前所探索的通過多個叢集進行的簡單靜態應用程式編排。事實上,多叢集拓撲對於跨不同位置編排應用程式和統一對基礎設施的存取非常有用。其中,這引入了一種令人興奮的可能性,可以透明而快速地將應用程式從一個叢集遷移到另一個叢集。在處理叢集災難或關鍵基礎設施干預、擴充套件或佈局優化時,移動工作負載是可行的。
vivo在聯邦叢集的探索方向主要有以下四個方面:
-
資源分發和編排
-
彈性突發
-
多叢集排程
-
服務治理和流量排程
本次主要分享資源分發和編排、彈性突發和多叢集排程以K8s為核心的聯邦多叢集探索。網路為核心的能力建設,主要為不同叢集的網路可以通過如 Service Mesh或者 Mesh Federation打通,就可以實現網路流量的靈活排程和故障轉移。實際上,也有很多應用通過隧道或者專線打通多個叢集,進一步保證了多叢集之間網路通訊的可靠性。vivo網路和服務發現主要是開源的基礎上自研,可以持續關注後面分享。
三、面向應用的多叢集實踐
雲原生技術的發展是持續輸出「事實標準的軟體」,而這些事實標準中,應用的彈性、易用性和可移植性是其所解決的三大本質問題。
-
應用的彈性:對於雲產品的客戶來說等價於業務可靠性和業務探索與創新的敏捷性,體現的是雲端計算所創造的客戶價值,應用彈性的另一個關注點在於快速部署、交付、以及在雲上的擴縮容能力。這就需要完善的應用交付鏈路以及應用的雲原生開發框架支撐;
-
易用性:能更好地發揮應用的彈性,在微服務軟體架構成為主流的情形下,易用性需要考慮通過技術手段實現對應用整體做全域性性的治理,實現全域性最優。這凸顯了 Service Mesh 的服務能力;
-
可移植性:實現多叢集和混合雲無障礙遷移等。
那麼一個以應用為中心,圍繞應用交付的多叢集多叢集管理具備統一的雲原生應用標準定義和規範,通用的應用託管和分發中心,基於 Service Mesh 的跨雲的應用治理能力,以及 K8s 原生的、面向多叢集的應用交付和管理體系,將會持續不斷的產生巨大的價值。vivo當前主要結合Karmada和CNCF周邊專案來探索以上挑戰。
3.1 面向應用的多叢集持續釋出
3.1.1 應用釋出
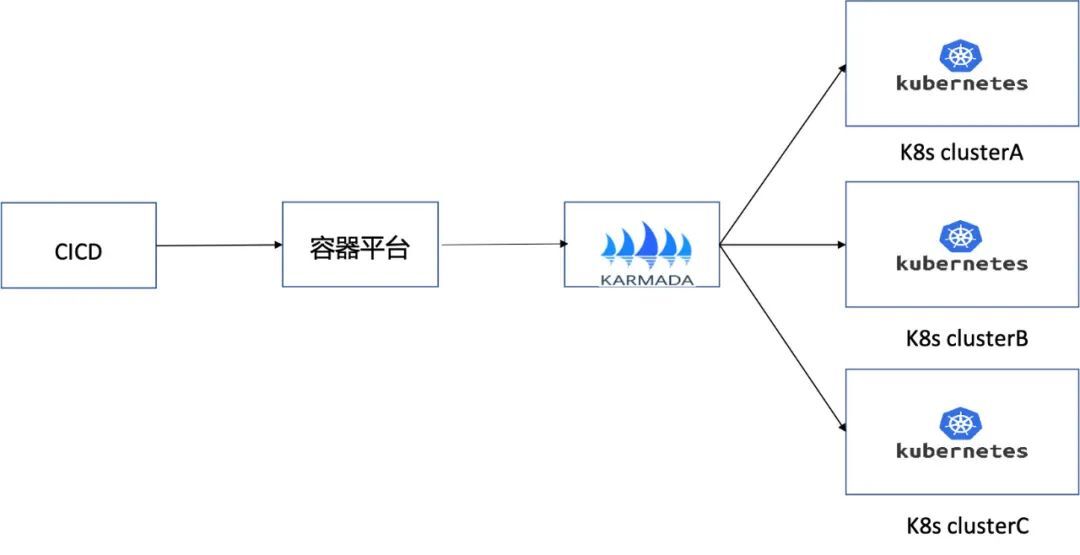
上圖是面向應用的多叢集持續釋出架構,我們主要的工作如下:
-
管理註冊多個Kubernetes叢集並接入Karmada,Karmada負責多個叢集的資源排程編排和故障轉移。
-
容器平臺統一管理K8s資源、Karmada策略和設定。
-
CICD平臺對應用進行單元測試、安全測試、編譯映象等操作,設定應用的儲存、金鑰、環境變數、網路和資源等,最終對接容器平臺的API生成K8s物件,統一交付。
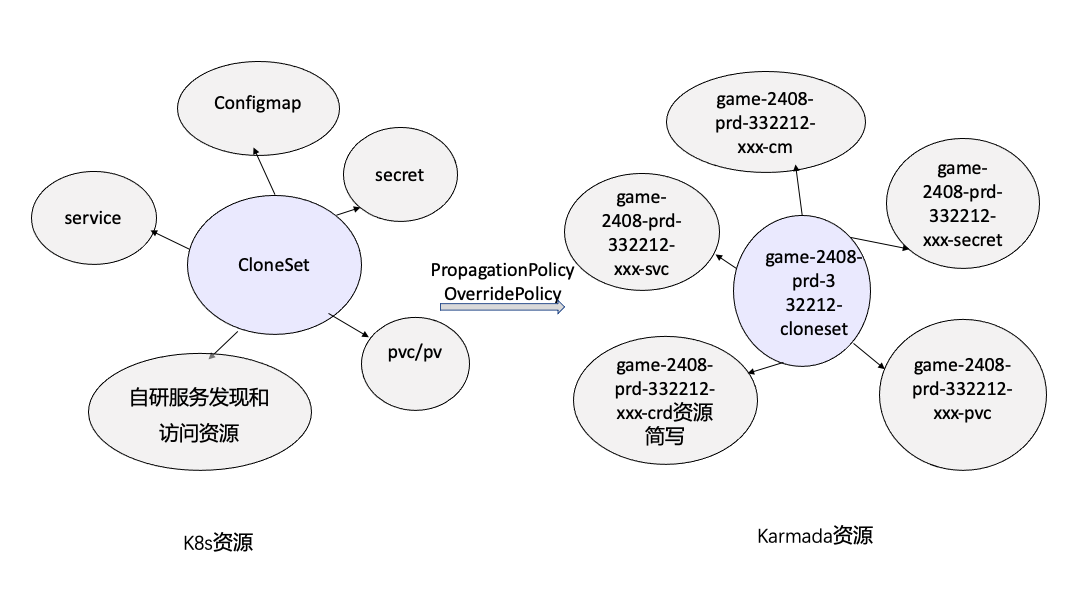
一個應用真正的能管理起來其實很複雜,如特定的場景需要原地升級和灰度釋出等。為了可以提供更加靈活、高階和易用的應用釋出能力,更好地滿足應用釋出的需求,最終選擇使用Openkruise。比如上圖有個遊戲的應用game-2408。它涉及到K8s資源有configmap、secret、pv、pvc、service,openkruise的cloneset、自研的服務發現和存取資源、以及Karmada的PropagationPolicy和OverridePolicy等資源,都能達到12個資源設定。比如儲存等資源都是按需申請和分配的,為了有效管理這些資源和關係,當前主要通過關聯資料庫進行管理,並打通cicd和容器平臺的互動,記錄應用釋出的狀態轉換,實現應用的捲動、灰度等釋出能力,達到可持續釋出的能力。
為了方便問題定位、K8s資源和Karmada資源的策略關係,當前Karmada 策略命名規範如下:
-
可以識別策略屬於那個workload
-
避免策略重複,需要加入workload型別
-
策略名超過63個字元,需要hash處理
-
xxx為非workload的資源名
遇到的問題總結:
-
一個資源無法被多個策略匹配,導致如configmap、secret等公用資源無法再次下發到其它叢集。
-
多個叢集之間序列釋出,如釋出完A叢集才能釋出B叢集的控制。
3.1.2 Openkruise資源解析
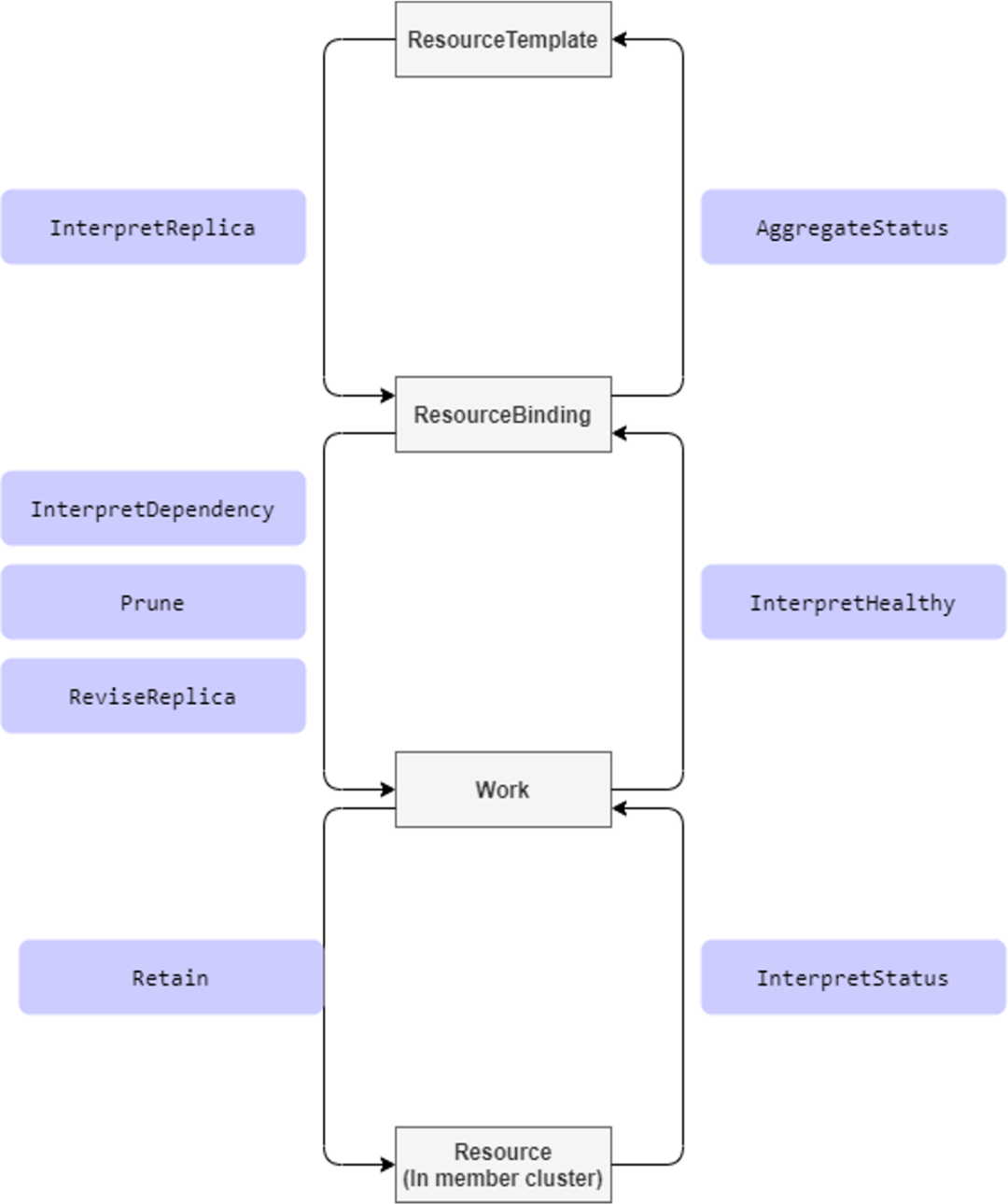
當前vivo的應用主要通過OpenKruise的Cloneset(無狀態)和AdvancedStatefulset(有狀態)控制器進行釋出。Kamrada目前只能識別K8s預設的資源,其它的資源都需要開發資源解析。為了解決上面提到的問題,Karmada 引入了 Resource Interpreter Webhook,通過干預從 ResourceTemplate-> ResourceBinding ->Work ->Resource 的這幾個階段來實現完整的自定義資源分發能力。
(1)InterpretReplica:
該 hook 點發生在從 ResourceTemplate 到 ResourceBinding 這個過程中,針對有 replica 功能的資源物件,比如類似 Deployment 的自定義資源,實現該介面來告訴 Karmada 對應資源的副本數。
(2)ReviseReplica:
該 hook 點發生在從 ResourceBinding 到 Work 這個過程中,針對有 replica 功能的資源物件,需要按照 Karmada 傳送的 request 來修改物件的副本數。Karmada 會通過排程策略把每個叢集需要的副本數計算好,你需要做的只是把最後計算好的值賦給你的 CR 物件。
(3)Retain:
該 hook 點發生在從 Work 到 Resource 這個過程中,針對 spec 內容會在 member 叢集單獨更新的情況,可以通過該 hook 告知 Karmada 保留某些欄位的內容。
(4)AggregateStatus:
該 hook 點發生在從 ResourceBinding 到 ResourceTemplate 這個過程中,針對需要將 status 資訊聚合到 Resource Template 的資源型別,可通過實現該介面來更新 Resource Template 的 status 資訊。
3.2 面向應用的多叢集彈性伸縮
3.2.1 彈性伸縮
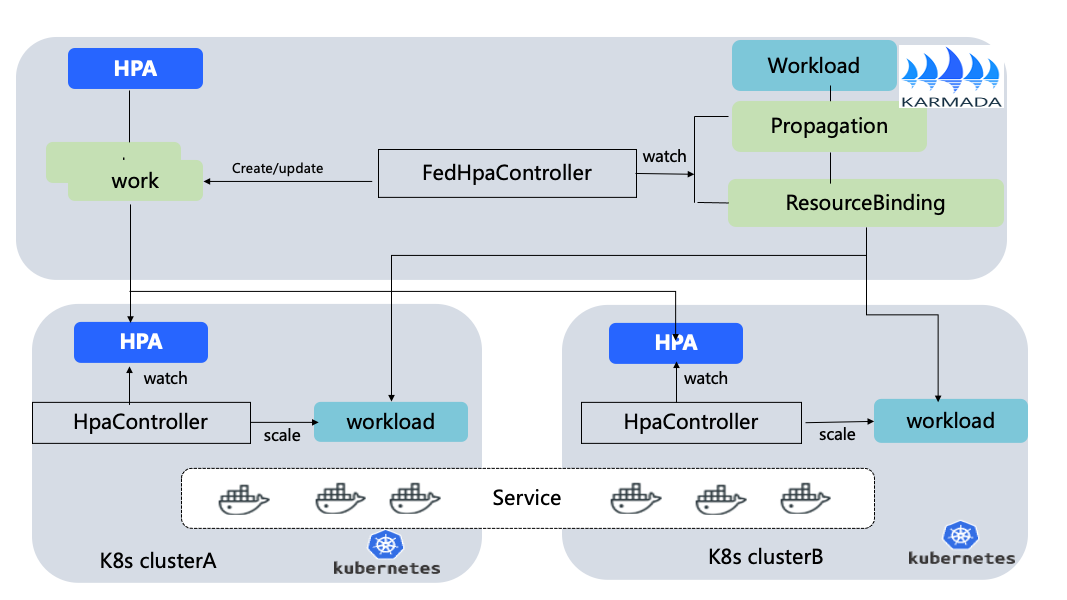
跨叢集HPA這裡定義為FedHPA,使用了K8s原生的HPA,在Karmada控制平面通過FedHpaController實現跨叢集的彈性排程擴縮容。
FedHPA流程:
-
使用者建立HPA資源,如指定workload、cpu上限、min和max值。
-
FedController開始計算clusterA和clusterB資源,在clusterA和clusterB建立HPA,並按比例分配叢集的min和max。
-
當叢集clusterA和clusterB觸發定義的cpu資源上限,clusterA和clusterB開始擴容。
-
Karmada控制平面的clusterA和clusterB的HPA work物件的status裡有記錄叢集擴容副本情況。
-
FedHPAController感知到work的變化,並獲取到每個叢集真實的副本數,開始更新排程資源RB和控制平面的workload副本數。保證了控制平面和member叢集的排程和副本數一致,不會出現重複排程和副本不一致。反之cpu流量下去開始縮容,計算過程一樣。
-
同時新增了資源再度均衡的能力,當叢集資源變化時,FedHPAController會計算叢集總資源、節點碎片、是否可排程等情況,重新分配每個叢集HPA的min和max值,確保在擴容時候有充足的資源。
3.2.2 定時伸縮
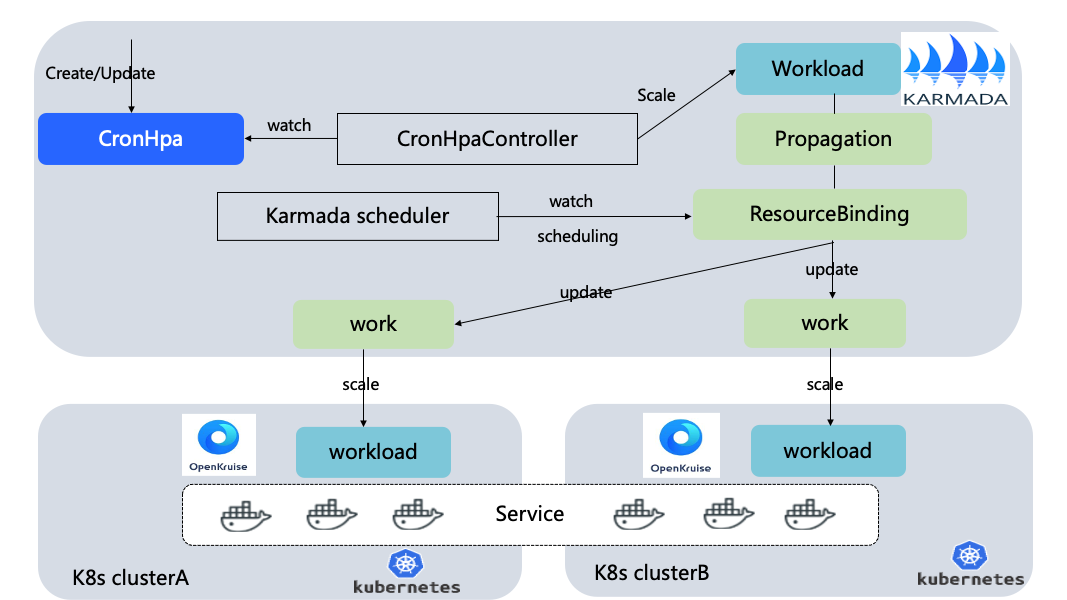
定時擴縮容是指應在固定時間點執行應用擴容來應對流量的高峰期。K8s本身沒有這個概念,這裡在Karmada控制平面定義了CronHpa資源,並通過Karmada-scheduler對多叢集統一排程。避免非聯邦化叢集在多個member叢集建立多個cronhpa。定時功能通過go-cron庫實現。
CronHpa流程:
-
使用者根據業務需求,建立CronHPA。定義擴容時間和縮容時間。
-
到擴容時間點,CronHPAController開始擴容workload。
-
Karmada-scheduler開始排程,根據每個叢集的資源開始合理分配每個叢集的副本數。
-
到縮容時間點,CronHPAController開始縮容workload。
3.2.3 手動和指定擴縮容
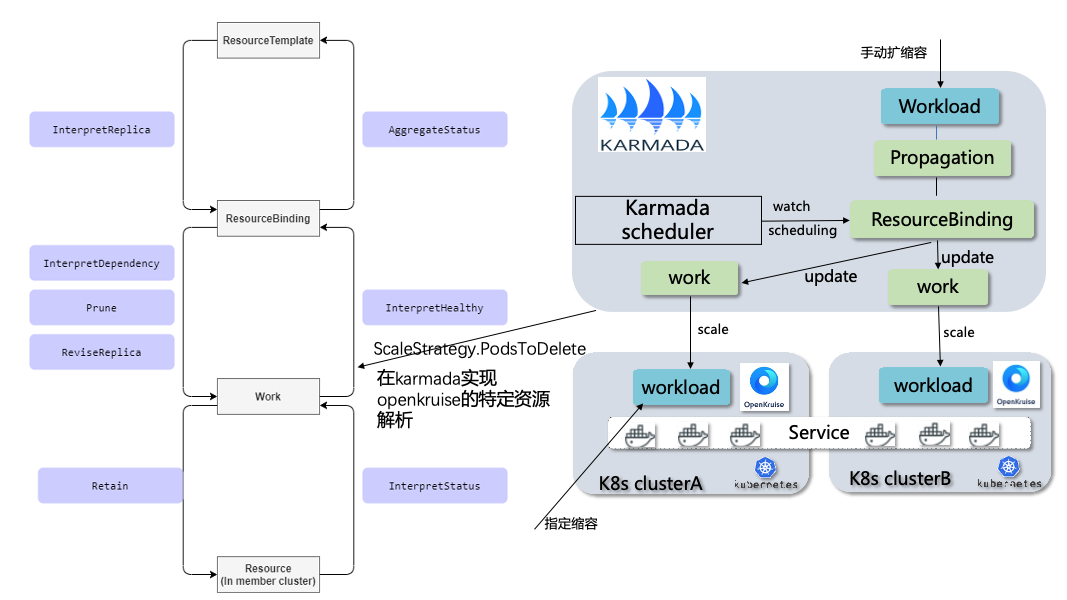
手動擴縮容流程:
-
使用者指定workload,進行擴容或者縮容。
-
Kamrada-scheduler開始排程,合理分配擴容或者縮容值到每個叢集。
指定縮容,這裡用到了openkruise能力。如訓練模型需要將一批效能差的pod進行縮容。
指定縮容流程:
-
使用者在clusterA 指定workload下面一個pod進行縮容,需要在
ScaleStrategy.PodsToDelete指定pod。
-
需要在Karmada實現openkurise實現該欄位的資源解析,不讓它被控制平面覆蓋。
-
並在控制平面更新workload的副本和pp資源,保證副本數和排程結果一致。
-
member叢集的openkruise開始刪除指定的pod。
也可以嘗試從Karmada控制平面指定刪除pod和更改排程的結果,這樣更加合理些,也不用新增Karmada資源解析。
3.3 統一排程
3.3.1 多叢集排程
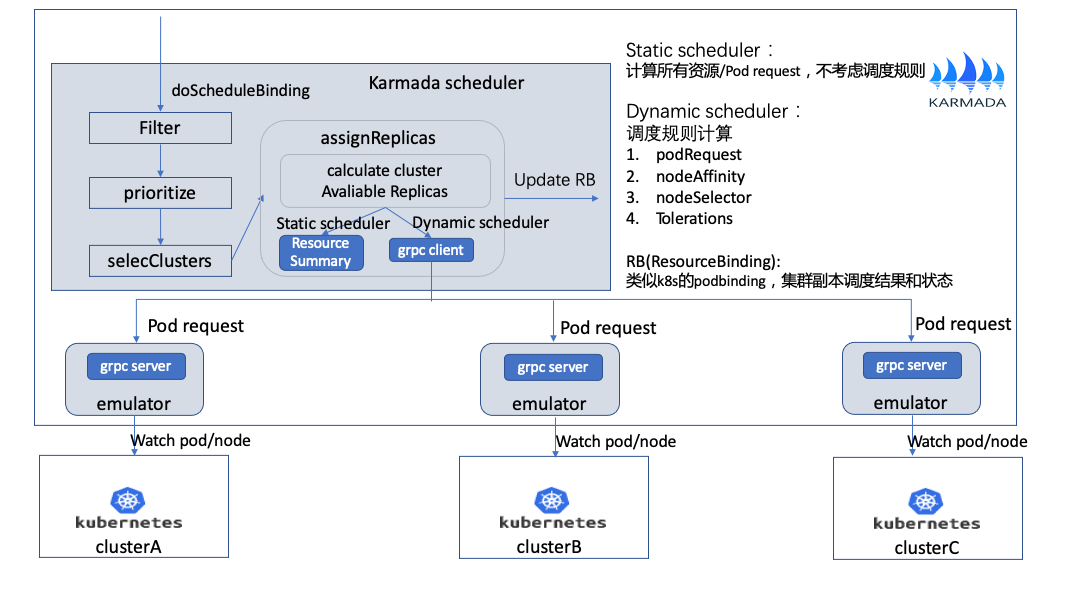
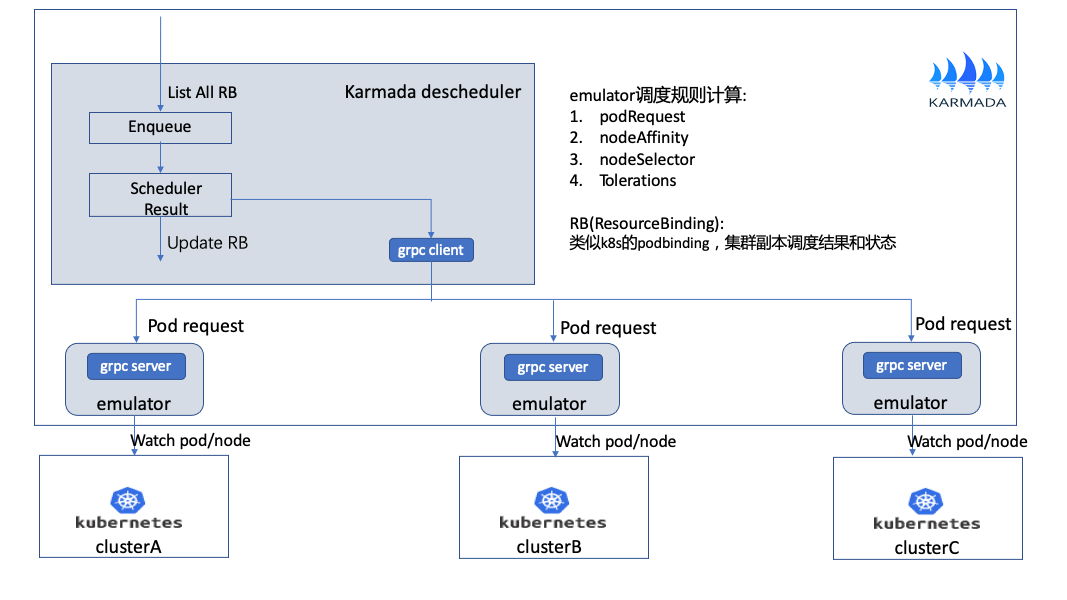
Karmada多叢集排程主要實現跨叢集資源的合理分配和叢集故障快速遷移業務。如上圖所示主要通過Karmada scheudler和emulator配合實現,其中emulator主要負責每個叢集的資源的估算。
workload排程流程:
-
使用者定義workload和策略匹配,生成RB資源。
-
doSchedulerBinding開始對RB進行排程,通過預選和優選排程演演算法選擇合適的叢集,當前不會進行資源計算,和K8s排程預選和優選不一樣。
-
selecClusters根據篩選的叢集,進行副本分配。這裡有2種模式,主要根據使用者設定的策略去選擇。
a.Static scheduler 只計算所有資源的request,不考慮排程規則。
b.Dynamic scheudler 會在計算所有request的同時,也會考慮一部分排程規則。
-
最終計算出每個叢集分配的副本數並更新RB資源,排程結束後其它控制器會根據RB進一步處理。
故障排程:
-
比如當叢集clusterA發生故障,在一定判定條件內,會觸發Karmada-scheduler重新排程。
-
Karmada-scheduler會將故障叢集的資源,排程到clusrerB和clusterC。
3.3.2 重排程
重排程的存在主要解決應用下發到member叢集沒有真正的執行起來,導致出現這樣的情況可能是叢集資源在不斷的變化,應用正在Karmada-scheduler多叢集排程的時候可能滿足,但經過member叢集二次排程時候無法排程。
重排程流程:
-
過濾RB資源,發現RB排程沒有達到預期。
-
對workload發起重新排程。
-
進過預選、優選等流程,再次分配排程結果。
-
最終將workload的所有pod排程起來。
3.3.3 單叢集排程模擬器
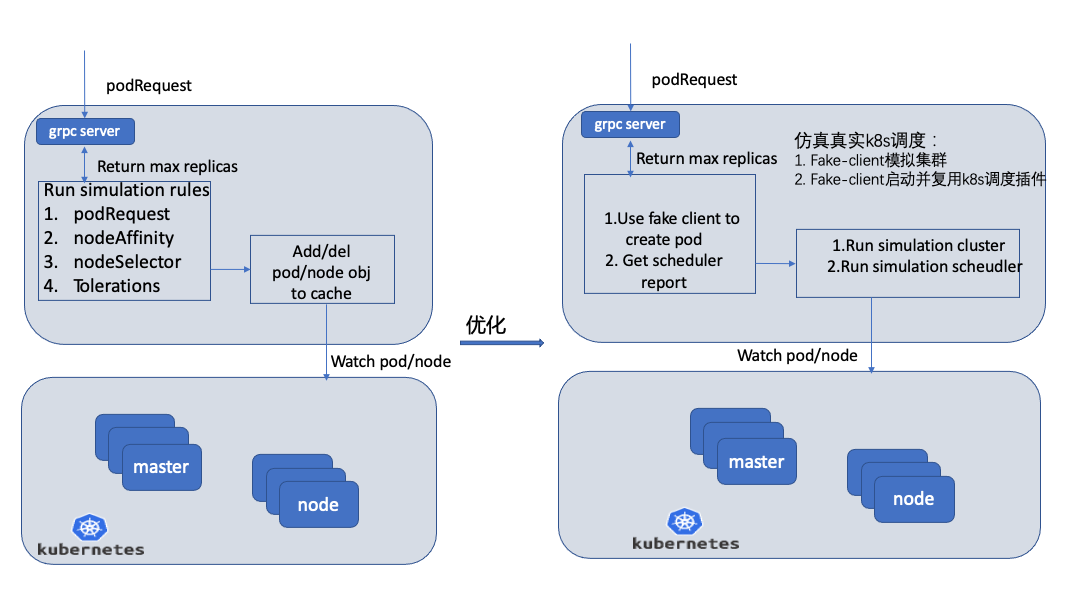
目前社群單叢集的排程估算器,只是簡單模擬了4種排程演演算法。和實際的排程演演算法有很大差距,目前線上有很多自研的排程演演算法和不同叢集需要設定不同演演算法,這樣估算器的精確度就會下降,導致排程出現pod pending的情況。可以對單叢集的排程模擬器進行優化。
-
使用fake client 去模擬線上叢集。
-
fake client啟動k8s預設的排程器以及自研的排程演演算法,修改binding介面。並設定到每個member叢集。
-
podRequest請求每個叢集排程模擬器,執行真實的排程演演算法,並計算排程結果。
3.4 灰度上線
3.4.1 應用遷移
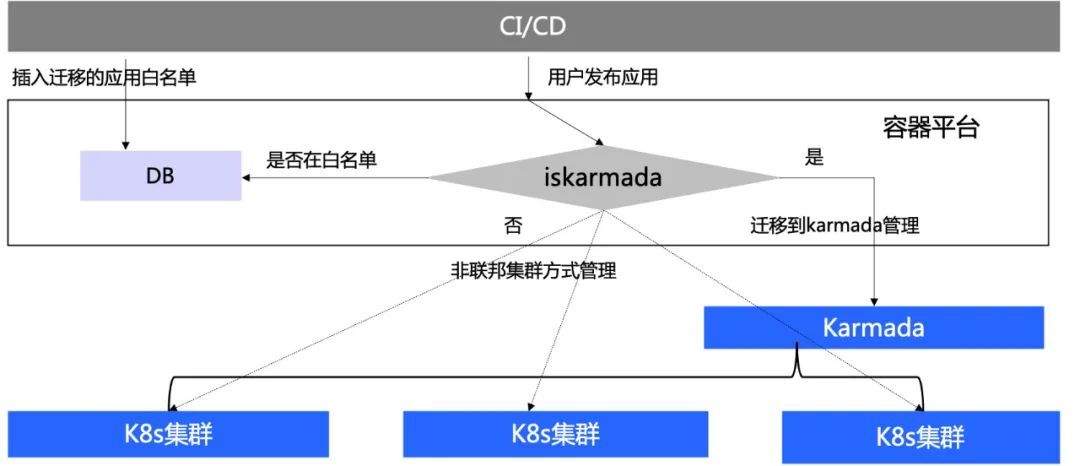
對於通過非聯邦化資源管理的應用,不能直接刪除在建立,需要平滑遷移到Karmada管理,對於使用者無感知。
主要流程如下:
-
管理員通過容器平臺,將需要遷移的應用插入遷移白名單。
-
使用者通過cicd釋出,容器平臺會進行釋出介面呼叫。
-
isKarmada模組會檢視遷移名單,在白名單內將資源聯邦化,接入Karmada管理。不在白名單內保持原有的靜態叢集管理。
-
最終完成應用的釋出,使用者完全無感知。保持2種管理方式並行存在。
3.4.2 應用回滾
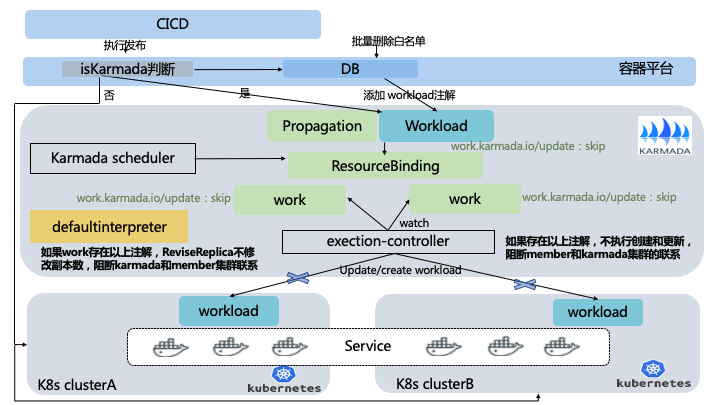
有了應用遷移的能力,是否就可以保證整個流程百分百沒有問題,其實是無法保證的。這就必須有應用回滾能力,提升使用者的遷移滿意度。
回滾的必要性總結:
-
應用釋出遷移的過程中發生了未知的錯誤,並且短時間無法恢復。避免阻塞應用正常釋出,需要回滾。
-
應用被Karmada接管後發生未知的錯誤,需要避免資源聯邦化後無法控制,需要回滾。
回滾流程:
-
管理員通過容器管理平臺,將需要回滾的應用從遷移白名單刪除。
-
並對應用對應的workload以及關聯的資源打上註解。
-
修改exection-controller原始碼,exection-controller發現以上註解,最終呼叫update/create時不做處理。
-
修改defaultInterpreter原始碼,發現以上註解ReviseReplica不修改副本數。
-
這樣就可以阻斷Karmada控制平面和member叢集的聯絡。這裡為什麼沒有直接從Karmada刪除資源,主要避免刪除這種高危操作以及方便後期恢復後重新接入Karmada。
3.4.3 遷移策略
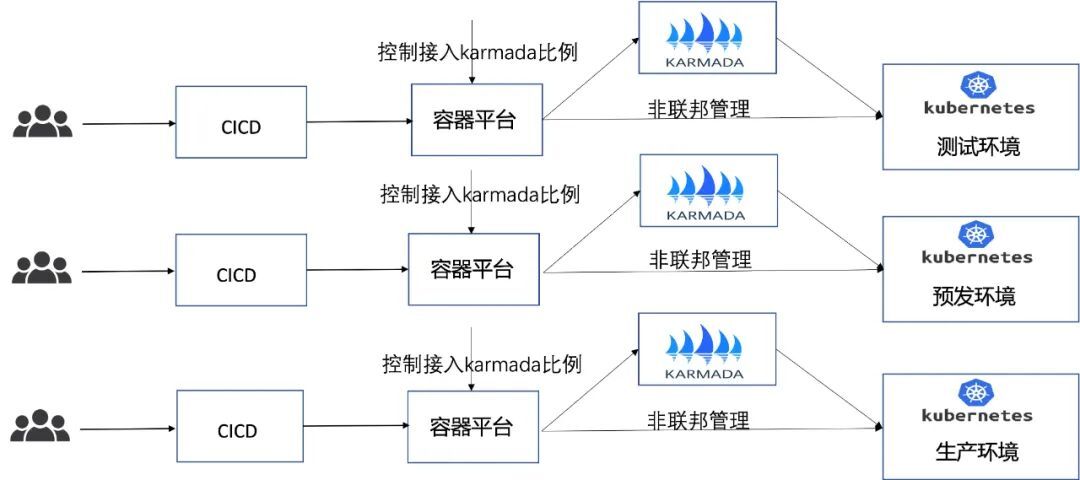
應用遷移Karmada原則:
-
先測試、再預發、最後生產
-
重大變更,分批次灰度,按照1:2:7比例灰度遷移
-
責任人雙方點檢驗證,並觀察監控5~10分鐘
-
灰度後確認沒有異常後繼續遷移,否則走回滾流程
四、總結
vivo當前主要通過非聯邦多叢集管理,結合CICD實現了應用靜態釋出和管理,具備了應用的捲動、灰度、手動擴縮容、指定縮容和彈性擴縮容等能力。相對於非聯邦多叢集部分能力不足,如跨叢集統一資源管理、排程和故障轉移等,在聯邦叢集進行部分能力的探索和實踐。同時聯邦叢集增加了整體架構的複雜度,叢集之間的狀態同步也會增加控制面的額外開銷和風險。當前社群在聯邦叢集還處在一個探索和不斷完善的階段,企業在使用聯邦叢集應結合自身需求、建立完善的運維保障和監控體系。對於已經存在的非聯邦化的資源需要建設遷移和回滾能力,控制發生故障的範圍和快速恢復能力。
參考專案: