通過提示大語言模型進行個性化推薦LLM-Rec: Personalized Recommendation via Prompting Large Language Models
論文原文地址:https://arxiv.org/abs/2307.15780
本文提出了一種提示LLM並使用其生成的內容增強推薦系統的輸入的方法,提高了個性化推薦的效果。
LLM-Rec Prompting
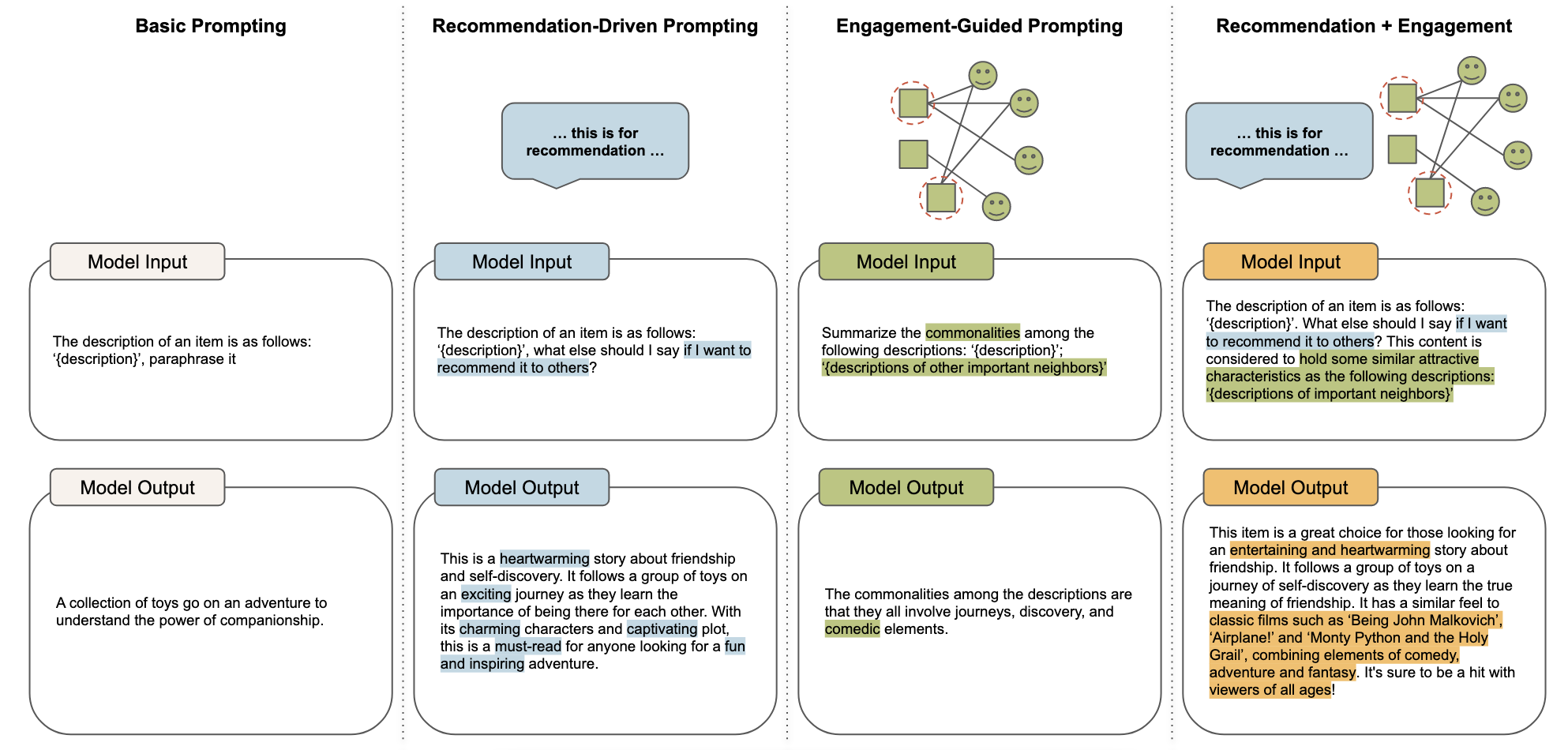
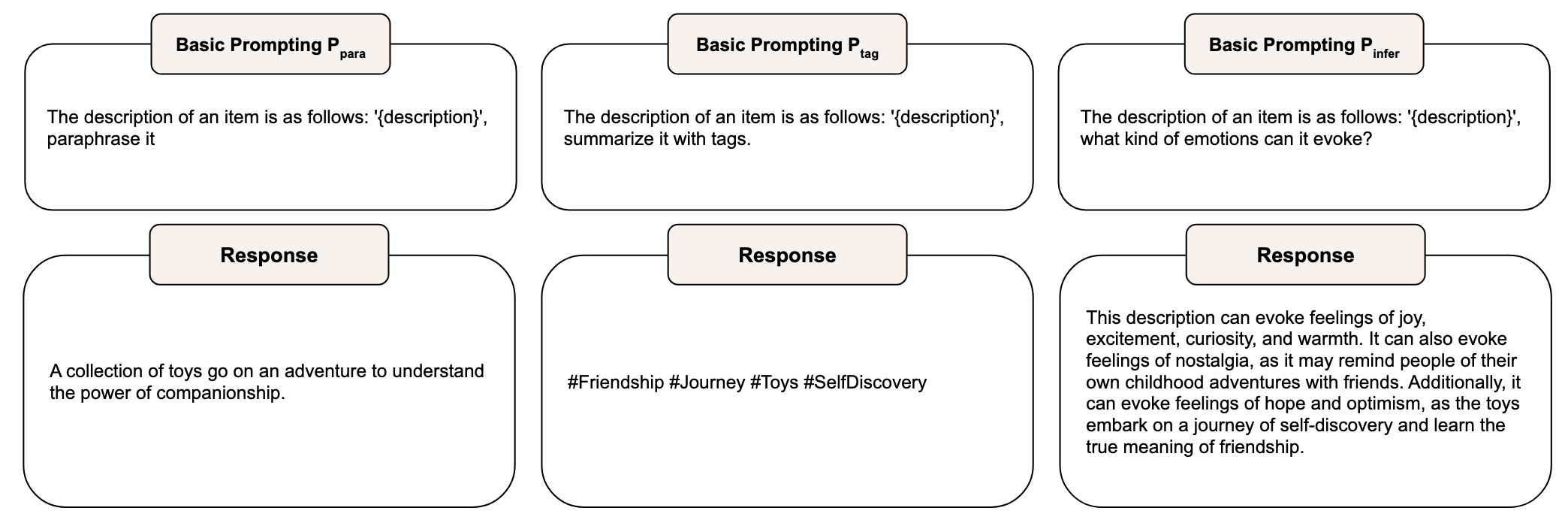
Basic prompting
基礎提示,主要有以下三種
- \(P_{para}\):提示LLM對原始內容進行改述,儘量保持原本的意思不變,並且不加入額外的內容。
- \(P_{tag}\):提示LLM用標籤總結原始內容,用更簡潔的表述捕獲關鍵資訊。
- \(P_{infer}\):提示LLM對原始內容的特徵進行一些推理,並提供一個比較寬泛的回答。
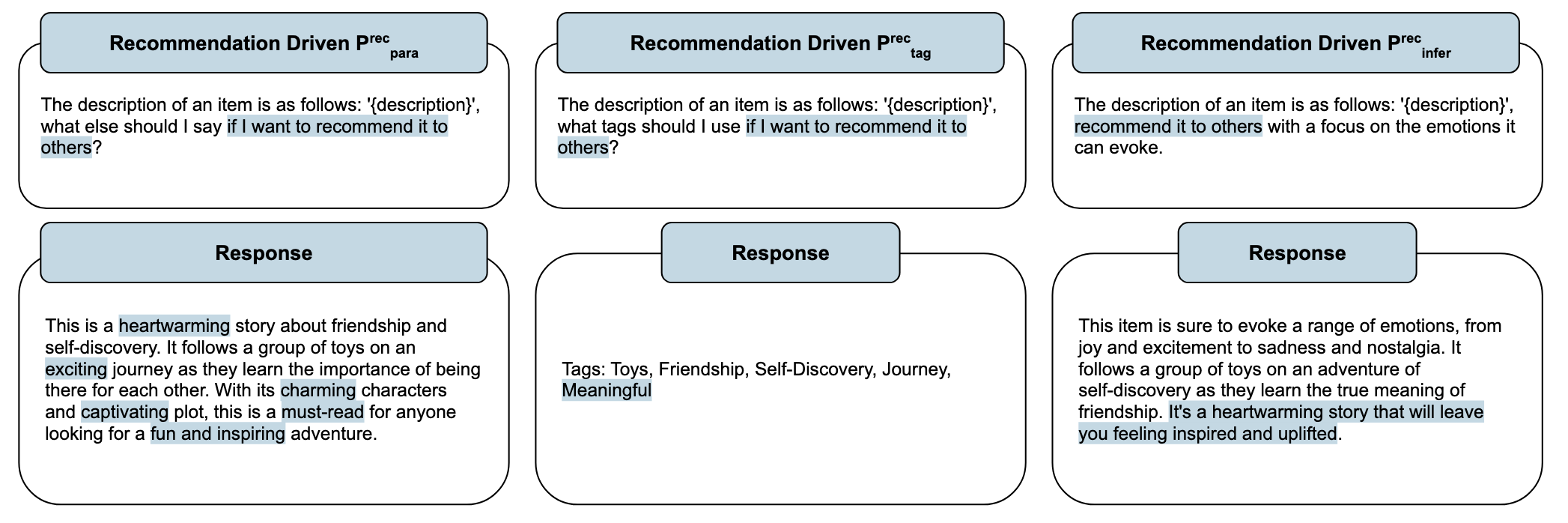
Recommendation-driven prompting
推薦驅動的提示,在基礎提示的基礎上增加推薦指令,例如「我想把它推薦給他人」這樣的語句。這種提示可以使得生成的內容更適合推薦的場景(雖然作者提到了有三種特點,但是我覺得可以用這一句話概括)。
Engagement-guided prompting
參與引導的提示。簡單來說,論文中作者根據user與item的互動(如果一個user常與兩個item互動,那麼這兩個item相似度較高),計算出與當前item最相似的T個item,並在輸入中,把這T個相似的item的描述也加入。這種方式可以使得LLM生成的內容與當前item更相關,更符合使用者的偏好。
Recommendation-driven + engagement-guided prompting
推薦驅動的提示與參與引導的提示的結合。
Experiment
- Benchmarks:用到兩個資料集MovieLens-1M和Recipe。
- Item module:
- Response generation:GPT-3(text-davinci-003)
- Text encoder:Sentence-BERT
- Engagement-guided prompting中的重要性度量:見上述。
- User module:大小為128的embedding
- User module:
- ItemPop:流行度推薦
- MLP
- AutoInt
- DCN-V2
- Model training:交叉熵損失
- Evaluation protocols:Precision、Recall、NDCG
Results
整體的評估框架。
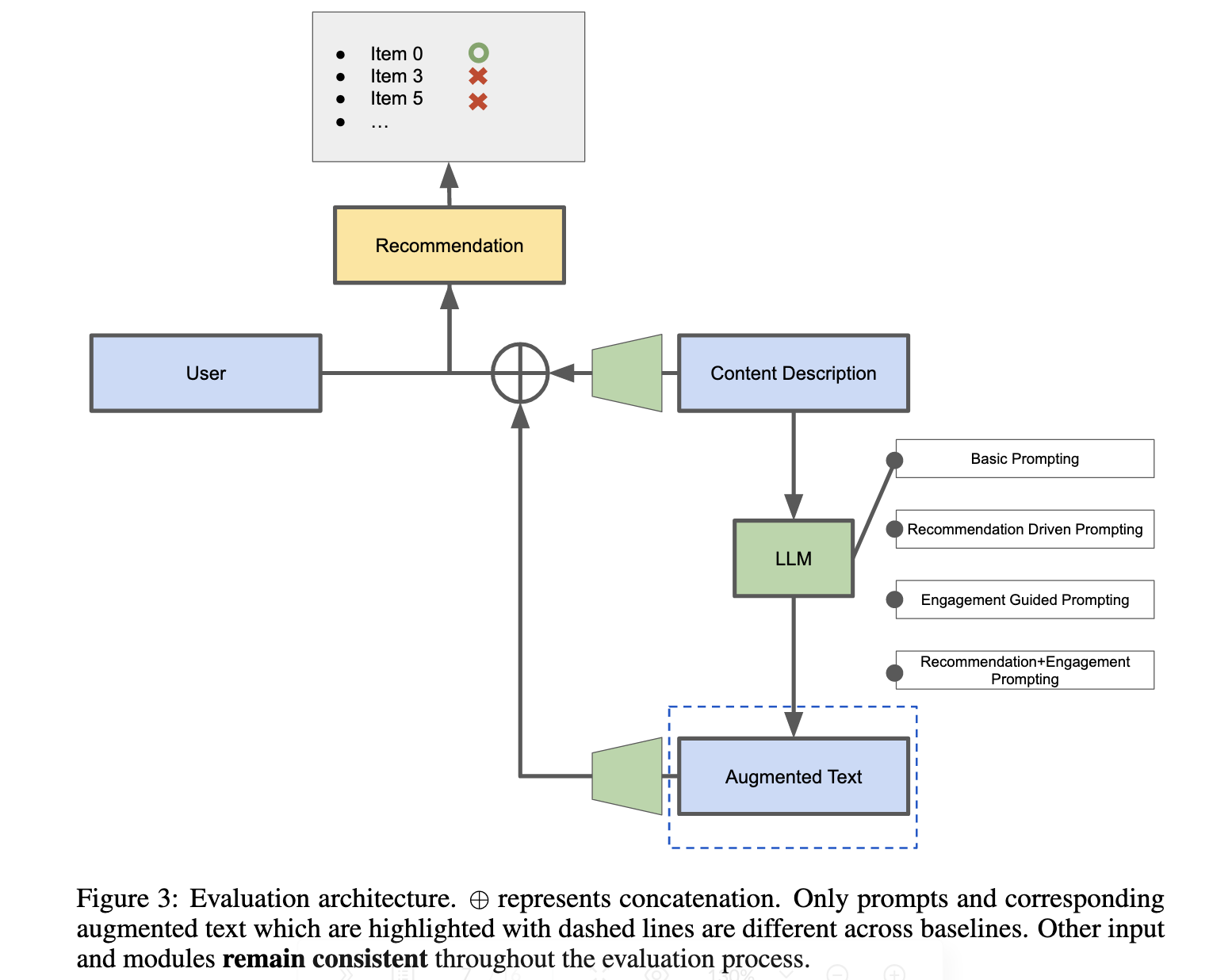
LLM-Rec(使用MLP作為推薦模型,只是輸入使用LLM進行了增強)取得了最佳推薦表現,超越了其他更復雜的基於特徵的方法。
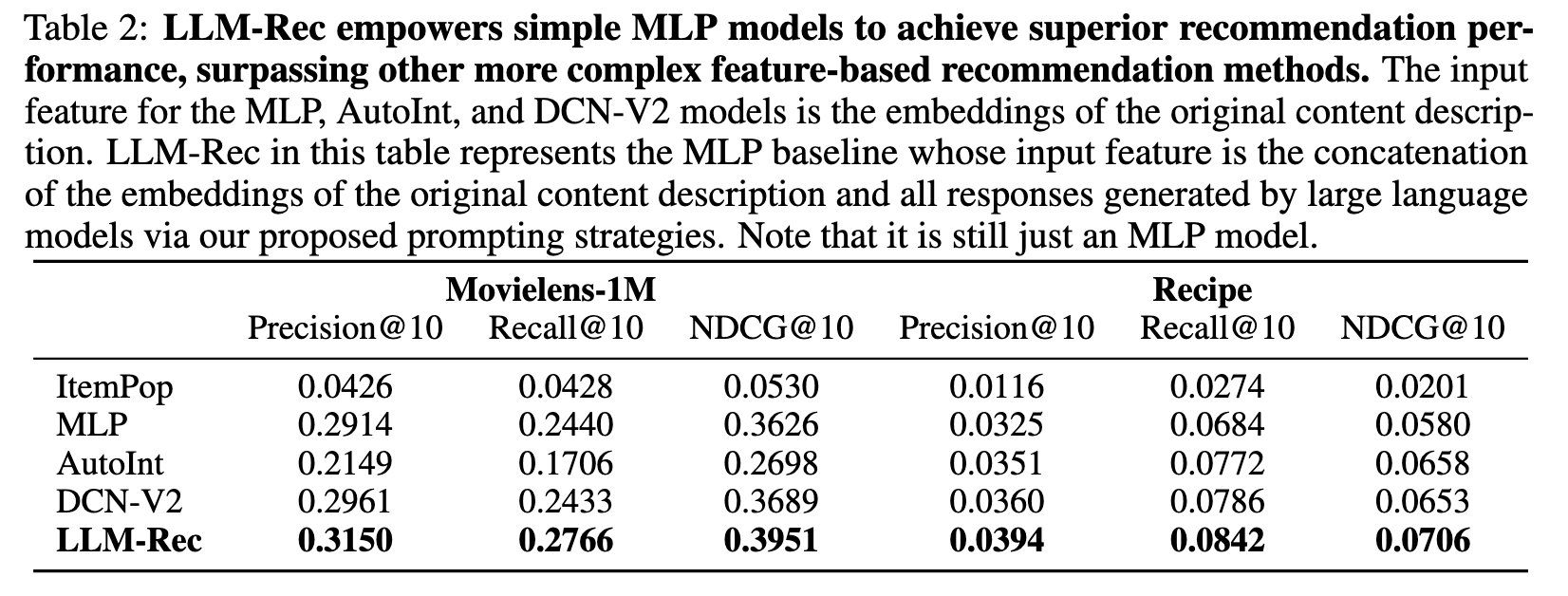
下表展示了每個提示策略的推薦效能,藍線是隻使用原始內容不進行資料增強的情況。
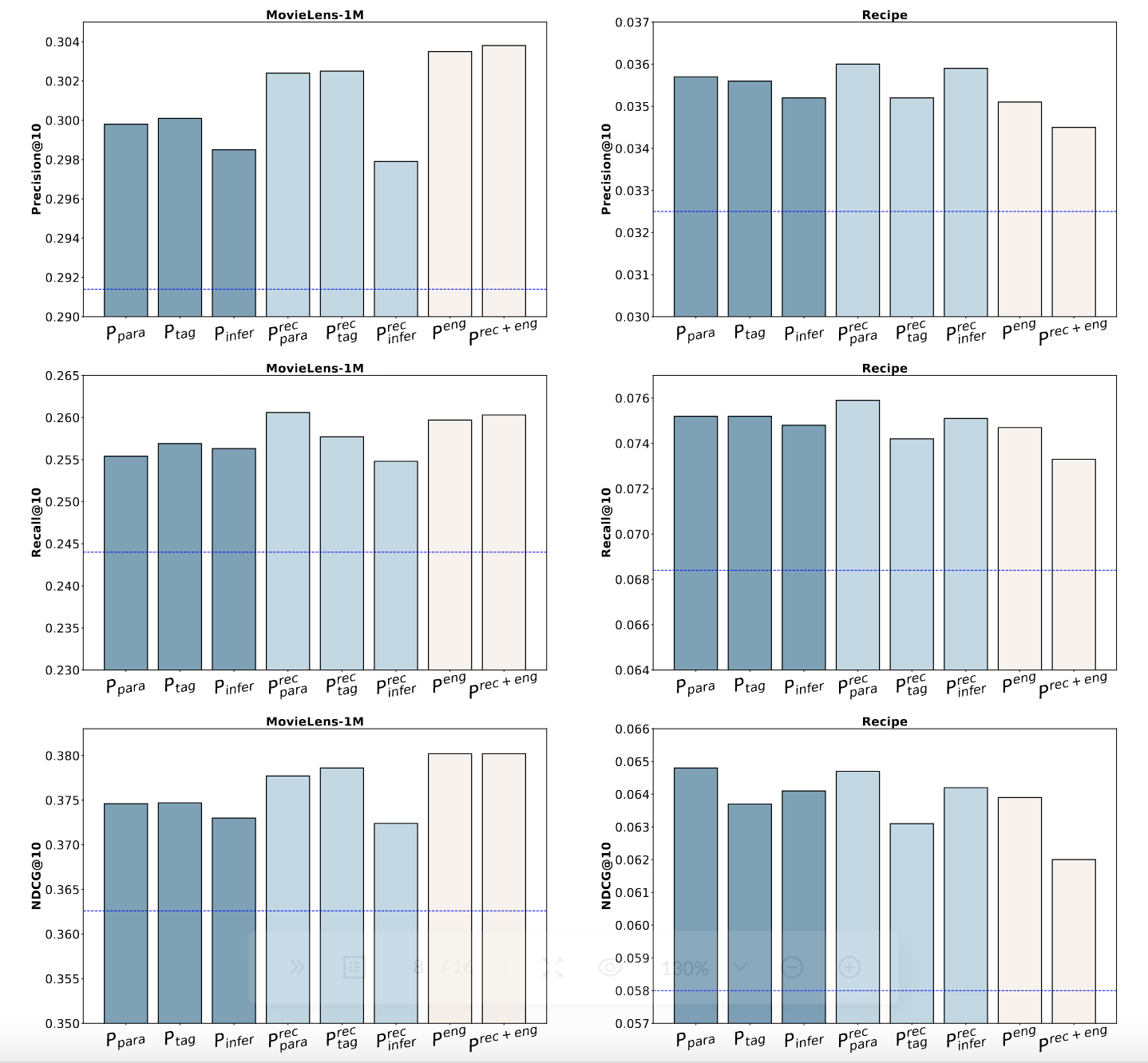
結合重要的關鍵字,而不是全部生成的內容,可以獲得更好的推薦效果。
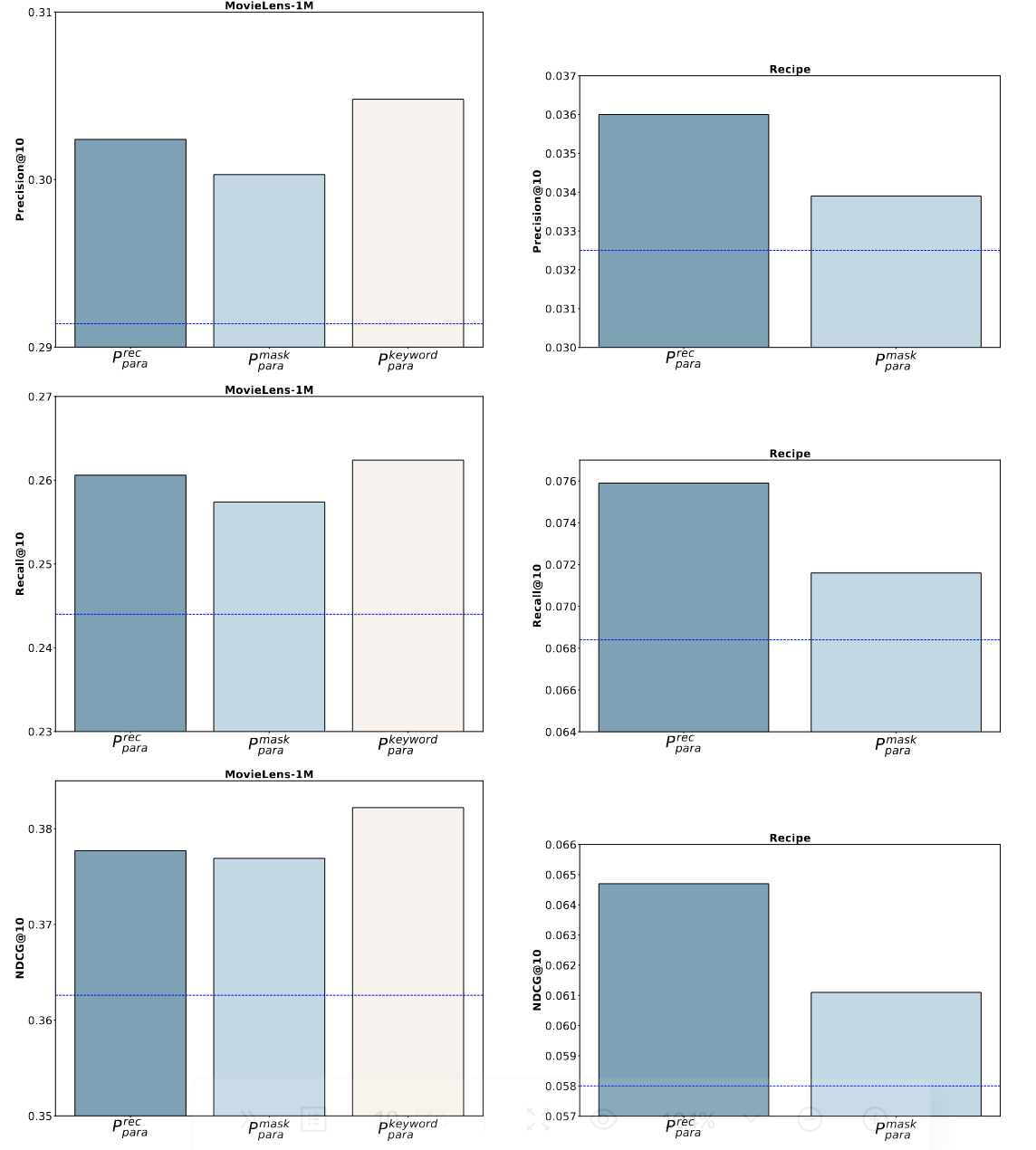
將生成的所有內容的embedding和原始內容的embedding拼在一起會有更好的推薦效果。
Summary
本文通過提示大模型對輸入進行資料增強,提高推薦系統的推薦效果。通過試驗結果可以看出,經過LLM增強後的輸入對推薦有很大幫助,即使是隻使用MLP作為推薦模型,也可以取得超越一些複雜的推薦模型的效果。將各種提示策略(轉述、標籤、推理)生成的內容進行整合後,會獲取更好的效果,這表明生成的內容是互補的。但是,作者在實驗中發現,通過推理進行資料增強並沒有達到預期的效果,因為通過推理生成的內容已經超出了原始資料的範圍,其對推薦可能會產生未知的影響,因此需要進一步研究如何設計出更合適的推理提示以及推理產生的內容對推薦的影響。