xv6 中的程序切換:MIT6.s081/6.828 lectrue11:Scheduling 以及 Lab6 Thread 心得
絮絮叨
這兩節主要介紹 xv6 中的執行緒切換,首先預警說明,這節課程的容量和第 5/6 節:程序的使用者態到核心態的切換一樣,細節多到爆炸,連我自己複習時都有點懵,看來以後不能偷懶了,學完課程之後要馬上寫部落格總結。但是不要怕,這節的內容真的特別有趣!
同時,再次強調這個系列的部落格(其實包括我所有的部落格)都不是課程的中文翻譯或者簡單摘抄,是我學完課程之後的思考和總結,是綜合了視訊、xv6 book、xv6 原始碼以及大量資料後的思考和總結的成果,寫部落格真的好累啊,點收藏的小夥伴如果覺得俺寫的還行順便點個贊唄,這個點贊-收藏比如此懸殊讓我有點繃不住 233333,剛從知乎上學了個金句:「反正收藏了你也不看,點贊意思下得了。。。」~如果想要看課程中文翻譯的童鞋點[這裡](11.1 執行緒(Thread)概述 - MIT6.S081 (gitbook.io))
ps:xv6 中一個程序只包含一個執行緒,所以老師在講課時並沒有特意區分程序和執行緒(值得吐槽),本文中也是混用的,,但是要記住本節講的是程序的切換,如果出現執行緒字樣,也請理解為程序。
引言
說到程序切換,我相信即使是計算機的初學者,都能說上一句:
「 就是上下文切換嘛!儲存 A 執行緒的各種暫存器資訊等,然後恢復 B 程序的相應資訊,這樣就由 A 程序切換到了 B 程序。」
這樣的回答沒有任何問題,上下文切換確實是執行緒切換最核心的思想,但是執行緒切換的一個重要特點是:思想很簡單,工程實現十分晦澀,連 xv6 book 都承認這部分程式碼是整個 xv6 中 最晦澀難懂的一部分程式碼:
the implementation is some of the most opaque code in xv6.
但還是那句話,魔鬼隱藏在細節中,之所以實現如此晦澀,是因為執行緒切換面臨以下幾個難點:
- 切換執行緒時,儲存執行緒的哪些資訊?在哪儲存它們?
- 什麼時候切換執行緒?是當前執行緒自願讓出 cpu 還是 cpu 強制其讓出?如何自願?如何強制?
- 執行緒切換對於使用者程序如何實現透明?比如你有一個單核 cpu,需要執行 2 個程序,那麼這 2 個程序一定是都認為自己獨佔 cpu(就像認為自己獨佔記憶體一樣),如何做到這一點?
- 和上一個情況相反,如果有多個 cpu 核,但是隻有一個待排程的程序,如何加鎖來防止這個程序在多個 cpu 上執行?
以上幾點如果要在工程程式碼中全部解決,確實需要花一番心思的,下面來看細節。
程序切換的細節
以兩個計算密集型程序為例,我們討論在不主動 yield(出讓)cpu 的情況下,程序是如何切換的。
當一個程序執行的時間足夠久,以至於硬體產生週期性的定時器中斷,該中斷訊號傳入核心,程式執行的控制權從使用者空間程式碼切換到核心中的中斷處理程式(注,因為中斷處理程式優先順序更高)
usertrap() 函數在第5/6節已經講過,這是 xv6 核心空間中的一個函數,如果有中斷、異常、系統呼叫發生,就會跳轉到這裡,在這裡進行進一步判斷並且執行相應的處理程式
//
// handle an interrupt, exception, or system call from user space.
// called from trampoline.S
//
void usertrap(void)
{
int which_dev = devintr()
// save user program counter.
struct proc *p = myproc();
// 由於中斷髮生時處於使用者空間,而且中斷髮生時 PC-> SEPC,所以這裡 p->trapframe->epc 被賦予了使用者空間中某條指令的地址
p->trapframe->epc = r_sepc();
// some code ignore
// ...
// ...
// ...
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}
RISC-V 中規定了如果是定時器中斷 which_dev的值會被置為 2,所以如果是定時器中斷,就會執行函數yield(),yield()的作用是該核心執行緒自願地將 cpu 出讓(yield)給執行緒排程器,並告訴執行緒排程器:你可以讓一些其他的執行緒執行了,下面是yield()的實現,可以看到核心函數是 sched(),並且將舊執行緒的狀態由"RUNNING"改為"RUNABLE",將一個正在執行的執行緒轉換成了一個當前不在執行但隨時可以再執行的執行緒。:
// Give up the CPU for one scheduling round.
void
yield(void)
{
struct proc *p = myproc();
acquire(&p->lock);
p->state = RUNNABLE;
sched();
release(&p->lock);
}
來看核心函數是 sched(),其中核心函數是swtch(),注意這裡不是拼寫錯誤,因為 switch 是 C 語言的關鍵字,不能作為函數名,所以採用 swtch 作為函數名:
void
sched(void)
{
// ignore some check code
// ...
// ...
// ...
struct proc *p = myproc();
swtch(&p->context, &mycpu()->context);
}
swtch函數會儲存使用者程序P1對應核心執行緒的暫存器至P1的 context 物件。然後將 cpu 的 context 物件恢復到相應的暫存器中,因為需要直接和暫存器打交道,所以 swtch 函數的程式碼是用組合寫的:
可以看到所謂的核心執行緒暫存器就是指 ra、sp、s0~s11 這 14 個暫存器。a0 暫存器對應著 swtch 函數的第一個引數,也就是當前執行緒的 context 物件地址;a1 暫存器對應著 swtch 函數的第二個引數,也就是即將要切換到的排程器執行緒的 context 物件地址
為什麼RISC-V中有32個暫存器,但是swtch函數中只儲存並恢復了14個暫存器?
因為swtch函數是從C程式碼呼叫的,所以我們知道Caller Saved Register會被C編譯器儲存在當前的棧上。Caller Saved Register大概有15-18個,而我們在swtch函數中只需要處理C編譯器不會儲存,但是對於swtch函數又有用的一些暫存器。所以在切換執行緒的時候,我們只需要儲存Callee Saved Register。
# Save current registers in old. Load from new.
.globl swtch
swtch:
# 上半部分,將 14 個暫存器的值儲存到當前執行緒的 context 物件中
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
# 下半部分,從 cpu 的 context 物件中恢復排程器執行緒的 14 個暫存器的值
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
# 指令 ret 被呼叫的時候,指令暫存器 pc 會被重置到 ra 所儲存的地址。 經列印 ra 的值可以發現是返回到 scheduler 函數中
ret
這裡要特別注意 ra 和 sp 暫存器的值,這也是理解整個執行緒切換的關鍵的關鍵!!!
列印出儲存之前的 ra 的值:可以發現是 sched 函數中的地址,這也符合邏輯,因為我們在 sched 函數中呼叫了 swtch 函數,在 swtch 函數中做的第一件事就是儲存 ra 暫存器,這時 ra 暫存器的值是當前程序中 swtch 函數執行完畢後的地址,也就是 sched 函數中 swtch 函數的下一行的地址

再列印出恢復之後 ra 的值,現在 ra 暫存器的值是 0x80001f2e,

列印出這個地址的指令,發現這個地址在 scheduler 函數中,意味著在 swtch 函數的後半部分:切換到排程器執行緒執行完畢後,函數會返回到 scheduler 函數中

完成 swtch 函數的後半部分:恢復從 cpu 中 14 個暫存器的值後,雖然依舊在 swtch 函數中,但已經不是 usertrap() -> yield() -> sched() -> swtch 這個鏈條上的 swtch 函數了,而是 scheduler() -> swtch 這個鏈條上的 swtch 函數;
至於 scheduler 函數什麼時候執行並且呼叫了 swtch 函數,這裡先大概說一下,下面會詳解:scheduler 函數屬於排程器執行緒,而排程器執行緒 是 xv6 系統啟動的最後一環,所以排程器執行緒早就隨著 xv6 的啟動而啟動了。
// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run.
// - swtch to start running that process.
// - eventually that process transfers control
// via swtch back to the scheduler.
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// ---------------特別注意,這裡就是地址 0x80001f2e 處
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}
現在捋一下這個過程:
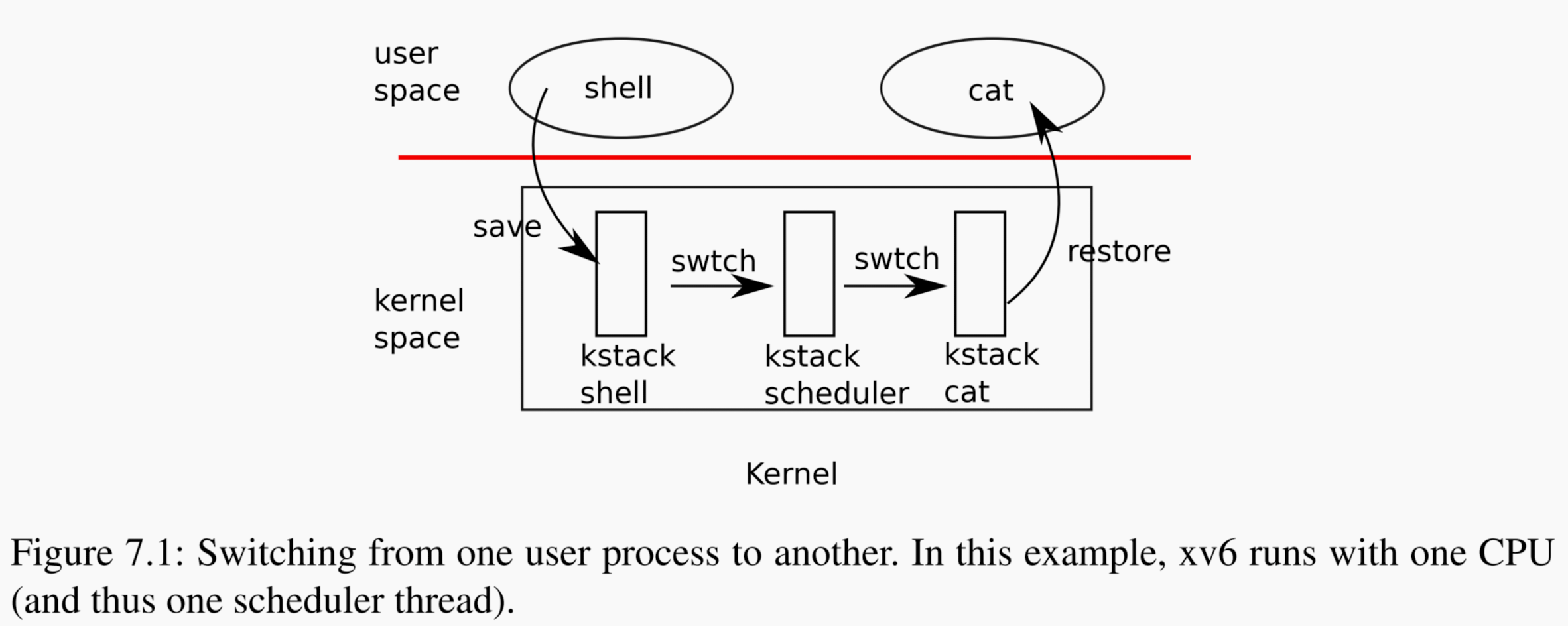
有兩個程序 P1 和 P2, 1 個 CPU core, 先執行 P2,然後執行 P1,然後再執行 P2,那麼 P1-> P2 是怎麼切換的?
答:xv6 執行 P1 一段時間後,定時器中斷被週期性觸發,程序 P1 陷入核心態,在核心態中,儲存公用暫存器(14 個)的狀態到 P1->context 結構體中,然後恢復 cpu->context 結構體的資料到公用暫存器中,這樣就把切換到了排程器執行緒,排程器執行緒會尋找一個程序狀態為 RUNABLE 的程序(即 P2),將其狀態修改為 RUNNING,然後呼叫 swtch 切換公用暫存器的狀態為 P2->context,此時由排程器執行緒切換到 P2 的核心程序,接著返回到使用者態,便完成了 P1->P2 的切換,如下圖演示的這樣:
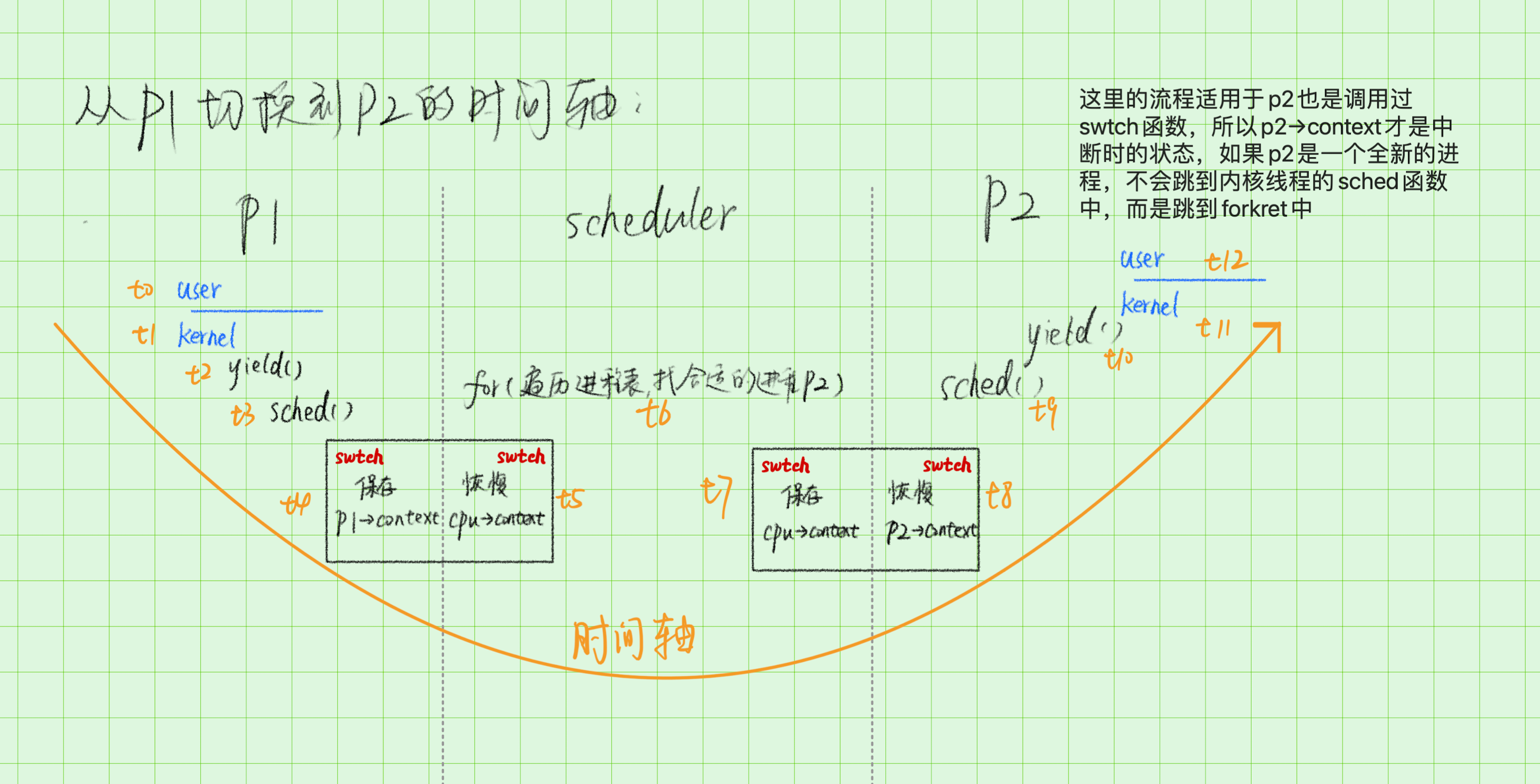
這個過程中最妙的地方在於對於 ra 暫存器的巧妙使用,使 swtch 函數巧妙地返回到了排程器程序中,然後又巧妙地返回到另一個使用者程序中,多到爆炸的細節見下圖:尤其注意圖中橙色的箭頭就是 swtch 函數返回的路徑。即 P1 的 shced 函數的 swtch 函數執行完畢後,就跳轉到 scheduler 函數的 c->proc = 0 這一行開始執行。當 shceduler() 函數的 swtch 執行完畢後,就跳轉到 P2 的 sched 函數的 swtch 函數的下一行開始執行。
具體細節見下圖:
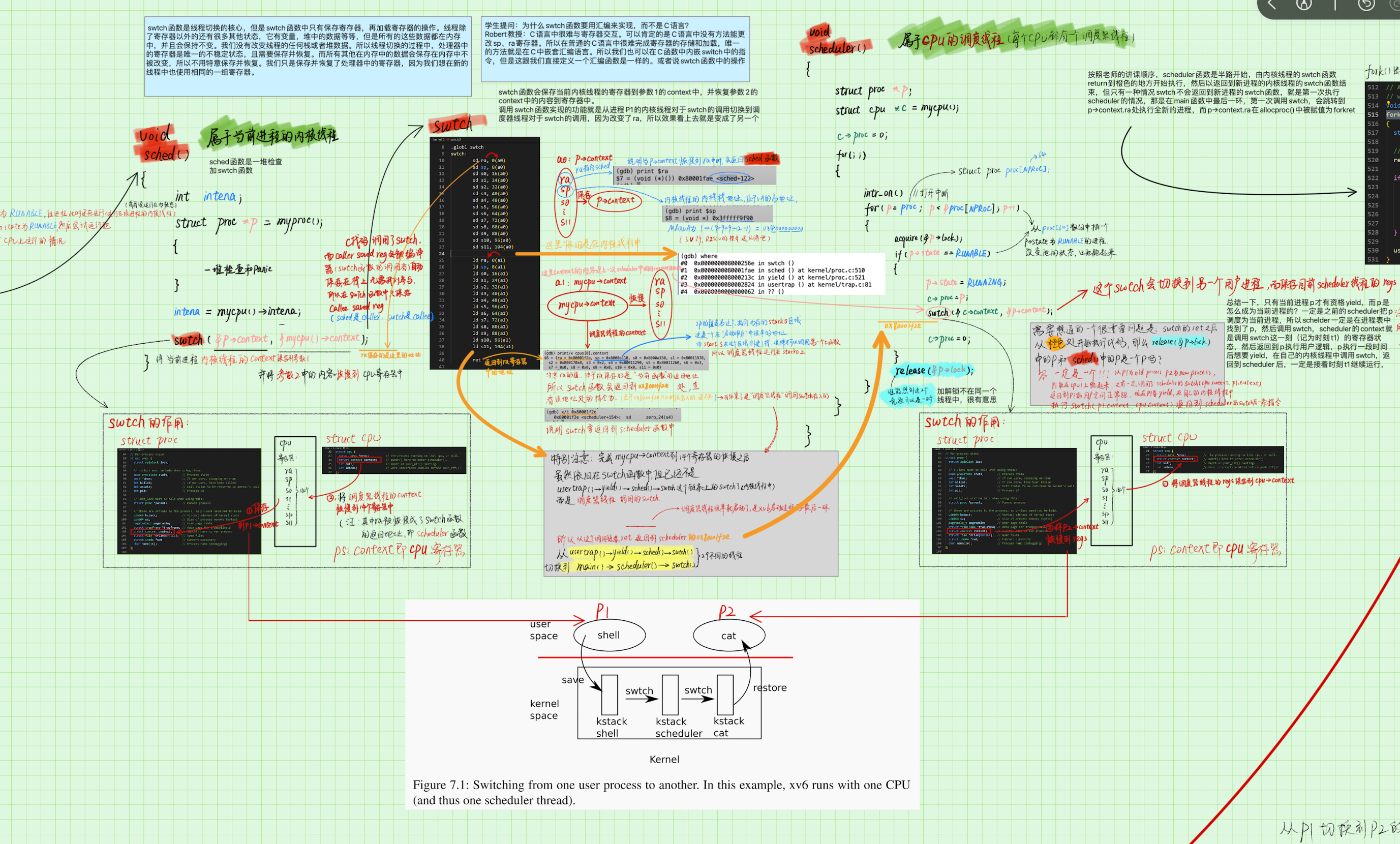
這裡最妙的地方在於排程器程序是怎麼保持連續性的,如下面的程式碼所示,scheduler 函數最核心的部分就是呼叫 swtch 函數,當程序 P1 由於終端切換到排程器程序時,會從地點 1 開始執行(因為 ra 指向地點 1),經過迴圈後到達地點 2,然後執行 swtch 後,離開 scheduler 函數,返回到 P2 的核心程序(因為 ra 指向該地址),下次又有中斷需要切換程序時,又會從地點 1 開始執行,所以 scheduler 函數就是連貫的,遍歷時 p 的值一直儲存在排程器程序的 stack 中,並不會丟失。
void
scheduler(void)
{
for(;;){
// ......ignore some code
for(p = proc; p < &proc[NPROC]; p++) {
//地點 2,執行完 swtch 後離開 scheduler
swtch(&c->context, &p->context);
// 地點 1,進入 scheduler
// ......ignore some code
}
}
}
執行緒除了暫存器以外的還有很多其他狀態,它有變數,堆中的資料等等,但是所有的這些資料都在記憶體中,並且會保持不變。我們沒有改變執行緒的任何棧或者堆資料。所以執行緒切換的過程中,cpu 中的暫存器是唯一的不穩定狀態,且需要儲存並恢復。而所有其他在記憶體中的資料會儲存在記憶體中不被改變,所以不用特意儲存並恢復。我們只是儲存並恢復了cpu 中的暫存器,因為我們想在新的執行緒中也使用這組暫存器。
第一次呼叫 swtch 的特例
剛剛的過程我們已經看到了,當呼叫swtch函數的時候,實際上是從 P1 對於 swtch 的呼叫切換到了 P2 對於 switch 的呼叫(實際上是從 P1 對於 swtch 的呼叫切換到 排程器程序對於 swtch 的呼叫;從 排程器程序對於 swtch 的呼叫切換到 P2 對於 swtch 的呼叫,這裡這麼說只是為了宏觀上的理解),為什麼能從 cpu 的排程器執行緒切換到 P2 的核心程序呢?關鍵就是P2 的 context -> ra 的值是 P2 的 sched 函數的 swtch 函數的下一行,當這個地址被從 context 中恢復到 ra 暫存器中後,就會根據該地址返回到 P2 程序的 swtch 函數的下一行。
這裡有一個關鍵問題就是如果 P2 程序是第一次被排程,那麼 context->ra 的值就不會是 P2 的 sched 函數的 swtch 函數的下一行,原因也很簡單啊,因為之前 P2 一定是在執行,然後主動或者被動呼叫了 yield() 函數,出讓了 cpu,所以 ra 的值就儲存了出讓的那一刻的地址,也就是 P2 的 sched 函數的 swtch 函數的下一行,但是如果之前 P2 沒有執行,而是第一次被排程,就需要我們手動設定 P2->context->ra 的值了,在 xv6 中,這個值在 allocproc() 函數中被設定為 p->context.ra = (uint64)forkret;這個函數如下:
// A fork child's very first scheduling by scheduler()
// will swtch to forkret.
void
forkret(void)
{
static int first = 1;
// Still holding p->lock from scheduler.
release(&myproc()->lock);
if (first) {
// File system initialization must be run in the context of a
// regular process (e.g., because it calls sleep), and thus cannot
// be run from main().
first = 0;
fsinit(ROOTDEV);
}
usertrapret();
}
這個函數其實做的工作很簡單,當呼叫 fork 函數分配的子程序準備好後,會先在池子中等待 scheduler() 函數排程,當唄排程後,就會返回到 forkret 函數中,在這個函數中返回到使用者空間,這裡其實也解釋了為什麼 fork() 函數可以一次呼叫,兩次返回。
fork() 函數的實現
在第一節中我們就瞭解到,fork()函數是一次呼叫兩次返回,在父程序中返回子程序 pid,在子程序中返回 0,所以fork 的典型用法就是:
//pid_t fork(void);
pid_t pid = fork();
if(pid) // parent process
{
//do something in parent process
} else
{
//do something in child process
}
這好像和我們 c 語言的是相反的,怎麼可能一個函數呼叫一次,有兩個返回值呢???
別急,學完前面的知識,我們就能理解這件事了,來看 fork 函數的實現:
int fork(void)
{
struct proc *child_process = allocproc();
// copy memory page table...
// copy fp and other properties
child_process->state = RUNNABLE;
child_process->trapframe->a0 = 0;// return value is 0 for child_process fork()
return child_process->pid;
}
剛剛說過,在 allocproc() 函數設定為 p->context.ra = (uint64)forkret;根據 ra 的值,所以子程序將來被排程後,會返回到 forkret 函數中,進而返回到使用者空間,並且子程序儲存返回值的 trapframe->a0 被設定為 0,而父程序的 trapframe->a0 被設定為子程序的 pid
void syscall(void)
{
//...
p->trapframe->a0 = fork(); //return value for parent is child_pid
//...
}
父程序遵循 c 語言的直覺,呼叫了 fork 函數,然後把自己的記憶體複製給子程序,並且返回了子程序的 pid,而子程序沒有立即返回,而是等待 scheduler 排程,排程後返回到 forkret 函數進而返回到使用者空間,並且由於父子程序的 trapframe page 是一樣的,下一行的程式碼地址是由 trapframe page 的 epc 變數儲存的,所以 pid_t pid = fork();這行程式碼在父程序中被執行後,子程序也會執行這行程式碼,給 pid 重新賦值為 0。
所以總結一下就是兩個要點:
- 由於複製了trapframe page ,所以
pid_t pid = fork();會被父子程序都執行 - fork() 是系統呼叫,進入核心態後父程序會新建一個子程序,父子程序會分別從核心態返回到使用者空間,父程序是系統呼叫的正常返回到使用者空間,子程序由於生在核心空間,是由 scheduler 呼叫返回到 forkret 函數然後返回到使用者空間
lab6 Thread 心得
這一節的三個小 lab 都是 morerate 級別的,思路和實現都比較簡單
Uthread: switching between threads
設計並實現一個使用者級別的執行緒切換機制,我理解就是為 xv6 實現多執行緒機制,其實相當於在使用者態重新實現一遍 xv6 中的 scheduler() 和 swtch() 的功能,所以大多數程式碼都是可以借鑑的。
而且由於是「使用者級」的執行緒,所以無需 trap 到核心態,只需要在程序中設定 n 個 thread 結構體,每個結構體都有空間儲存自己的 context 即可。
也無需使用時鐘中斷來強制執行排程,由執行緒主動呼叫 yield() 來出讓 cpu 、重新排程,這裡的程式碼比較簡單,就直接都貼出來了
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
/* Possible states of a thread: */
#define FREE 0x0
#define RUNNING 0x1
#define RUNNABLE 0x2
#define STACK_SIZE 8192
#define MAX_THREAD 4
// Saved registers for thread context switches.
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
struct thread {
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct context ctx; // 在 thread 中新增 context 結構體
};
struct thread all_thread[MAX_THREAD];
struct thread *current_thread;
extern void thread_switch(uint64, uint64);
void
thread_init(void)
{
// main() is thread 0, which will make the first invocation to
// thread_schedule(). it needs a stack so that the first thread_switch() can
// save thread 0's state. thread_schedule() won't run the main thread ever
// again, because its state is set to RUNNING, and thread_schedule() selects
// a RUNNABLE thread.
current_thread = &all_thread[0];
current_thread->state = RUNNING;
}
void
thread_schedule(void)
{
struct thread *t, *next_thread;
/* Find another runnable thread. */
next_thread = 0;
t = current_thread + 1;
for(int i = 0; i < MAX_THREAD; i++){
if(t >= all_thread + MAX_THREAD)
t = all_thread;
if(t->state == RUNNABLE) {
next_thread = t;
break;
}
t = t + 1;
}
if (next_thread == 0) {
printf("thread_schedule: no runnable threads\n");
exit(-1);
}
if (current_thread != next_thread) { /* switch threads? */
next_thread->state = RUNNING;
t = current_thread;
current_thread = next_thread;
/* YOUR CODE HERE
* Invoke thread_switch to switch from t to next_thread:
* thread_switch(??, ??);
*/
thread_switch((uint64)&t->ctx, (uint64)&next_thread->ctx);
} else
next_thread = 0;
}
void
thread_create(void (*func)())
{
struct thread *t;
for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
if (t->state == FREE) break;
}
t->state = RUNNABLE;
// YOUR CODE HERE
t->ctx.ra = (uint64)func; // 返回地址
// thread_switch 的結尾會返回到 ra,從而執行執行緒程式碼
t->ctx.sp = (uint64)&t->stack + STACK_SIZE ; // 棧指標
}
void
thread_yield(void)
{
current_thread->state = RUNNABLE;
thread_schedule();
}
volatile int a_started, b_started, c_started;
volatile int a_n, b_n, c_n;
void
thread_a(void)
{
int i;
printf("thread_a started\n");
a_started = 1;
while(b_started == 0 || c_started == 0)
thread_yield();
for (i = 0; i < 100; i++) {
printf("thread_a %d\n", i);
a_n += 1;
thread_yield();
}
printf("thread_a: exit after %d\n", a_n);
current_thread->state = FREE;
thread_schedule();
}
void
thread_b(void)
{
int i;
printf("thread_b started\n");
b_started = 1;
while(a_started == 0 || c_started == 0)
thread_yield();
for (i = 0; i < 100; i++) {
printf("thread_b %d\n", i);
b_n += 1;
thread_yield();
}
printf("thread_b: exit after %d\n", b_n);
current_thread->state = FREE;
thread_schedule();
}
void
thread_c(void)
{
int i;
printf("thread_c started\n");
c_started = 1;
while(a_started == 0 || b_started == 0)
thread_yield();
for (i = 0; i < 100; i++) {
printf("thread_c %d\n", i);
c_n += 1;
thread_yield();
}
printf("thread_c: exit after %d\n", c_n);
current_thread->state = FREE;
thread_schedule();
}
int
main(int argc, char *argv[])
{
a_started = b_started = c_started = 0;
a_n = b_n = c_n = 0;
thread_init();
thread_create(thread_a);
thread_create(thread_b);
thread_create(thread_c);
thread_schedule();
exit(0);
}
Using threads
這個可以說是整個課程中最簡單的 lab 了,要做的就是兩點:
- 為 hashtable 加大表保證多執行緒操作的正確性;
- 降低鎖的粒度,為每個 hashtable 的 bucket 加鎖以提高並行性。
Barrier
這個 lab 但是挺有趣的,可以瞭解到了計算機中同步屏障機制是如何實現的。
簡單來說,一段程式碼被多個執行緒執行,如何保證多個執行緒都到了其中某一點之後,才能繼續往下執行?但是由於這個 lab 涉及到 lost wake-up 問題,所以我打算放到下一節一起復習~
ok,本節就到這裡,本門課程最難的一節就複習完啦,按照 lab 的線索,接下來再寫 3 篇,這個系列就收工~
對了我目前在尋找工作機會,本人計算機基礎比較紮實,獨立完成了 CSAPP(計算機組成)、MIT6.s081(作業系統)、MIT6.824(分散式)、Stanford CS144 NetWorking(計算機網路)、CMU15-445(資料庫基礎) 等硬核課程的所有 lab,如果有內推名額的大佬可私信我,我來發簡歷。
獲得更好的閱讀體驗,這裡是我的部落格,歡迎存取:byFMH - 部落格園
所有程式碼見:我的GitHub實現(記得切換到相應分支)