升訊威線上客服系統的並行高效能資料處理技術:高效能TCP伺服器技術
我在業餘時間開發維護了一款免費開源的升訊威線上客服系統,也收穫了許多使用者。對我來說,只要能獲得使用者的認可,就是我最大的動力。
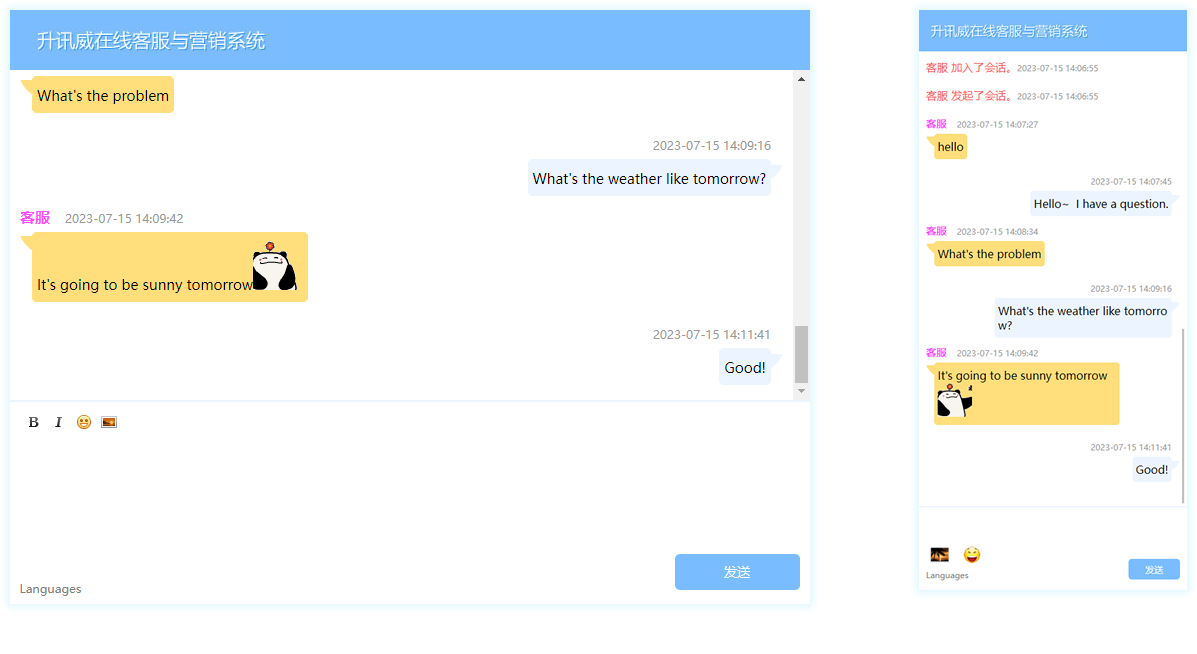
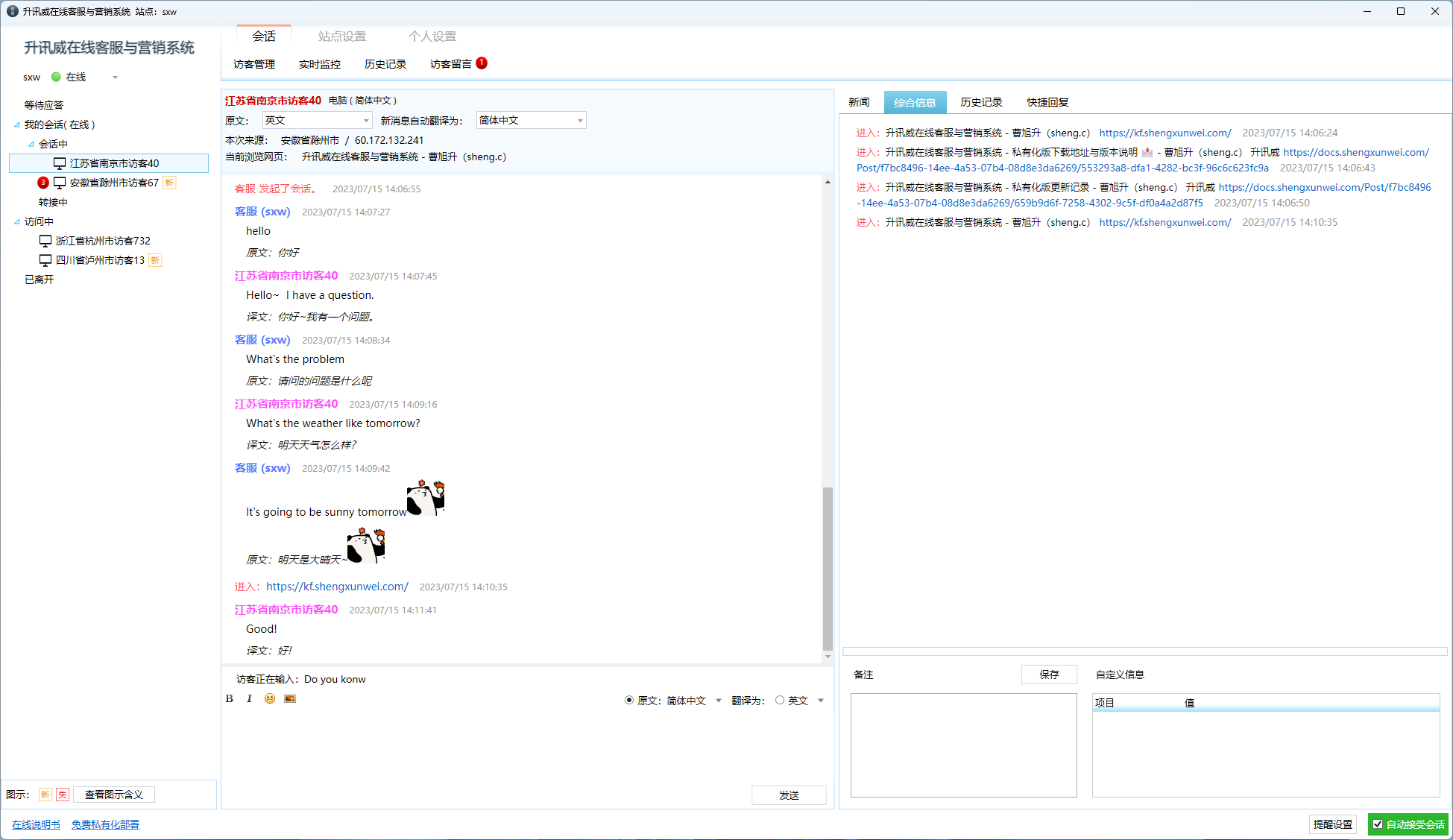
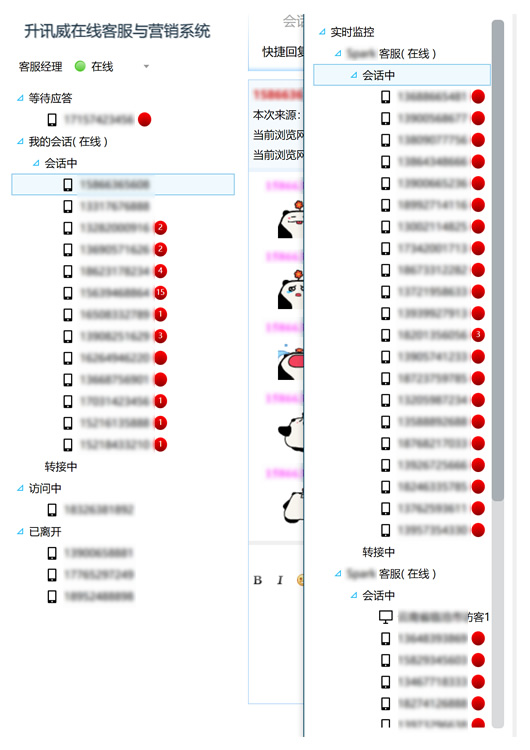
最近客服系統成功經受住了客戶現場組織的壓力測試,獲得了客戶的認可。
客戶組織多名客服上線後,所有員工同一時間開啟訪客頁面瘋狂不停的給線上客服發訊息,系統穩定無異常無掉線,客服回覆訊息正常。訊息實時到達無任何延遲。

我會通過一系列的文章詳細分析升訊威線上客服系統的並行高效能技術是如何實現的,使用了哪些方案以及具體的做法。
本篇介紹資料傳輸方面的管線技術。
Pipelines誕生於.NET Core團隊,為使Kestrel成為業界最快的Web伺服器之一。最初從作為Kestrel內部的實現細節發展成為可重用的API,它在.Net Core 2.1中作為可用於所有.NET開發人員的最高階BCL API(System.IO.Pipelines)提供。
使用NetworkStream的TCP伺服器
在Pipelines之前用.NET編寫的典型程式碼如下所示:
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// 在buffer中處理一行訊息
ProcessLine(buffer);
}
此程式碼可能在本地測試時正確工作,但它有幾個潛在錯誤:
一次ReadAsync呼叫可能沒有收到整個訊息(行尾)。
它忽略了stream.ReadAsync()返回值中實際填充到buffer中的資料量。(譯者注:即不一定將buffer填充滿)
一次ReadAsync呼叫不能處理多條訊息。
這些是讀取流資料時常見的一些缺陷。為了解決這個問題,我們需要做一些改變:
我們需要緩衝傳入的資料,直到找到新的行。
我們需要解析緩衝區中返回的所有行
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered);
if (bytesRead == 0)
{
// EOF 已經到末尾
break;
}
// 跟蹤已緩衝的位元組數
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// 在緩衝資料中查詢找一個行末尾
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed, bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// 根據偏移量計算一行的長度
var lineLength = linePosition - bytesConsumed;
// 處理這一行
ProcessLine(buffer, bytesConsumed, lineLength);
// 移動bytesConsumed為了跳過我們已經處理掉的行 (包括\n)
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
這一次,這可能適用於本地開發,但一行可能大於1KiB(1024位元組)。我們需要調整輸入緩衝區的大小,直到找到新行。
因此,我們可以在堆上分配緩衝區去處理更長的一行。我們從使用者端解析較長的一行時,可以通過使用ArrayPool
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// 在buffer中計算中剩餘的位元組數
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// 將buffer size翻倍 並且將之前緩衝的資料複製到新的緩衝區
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// 將舊的buffer丟回池中
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF 末尾
break;
}
// 跟蹤已緩衝的位元組數
bytesBuffered += bytesRead;
do
{
// 在緩衝資料中查詢找一個行末尾
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed, bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// 根據偏移量計算一行的長度
var lineLength = linePosition - bytesConsumed;
// 處理這一行
ProcessLine(buffer, bytesConsumed, lineLength);
// 移動bytesConsumed為了跳過我們已經處理掉的行 (包括\n)
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
這段程式碼有效,但現在我們正在重新調整緩衝區大小,從而產生更多緩衝區副本。它將使用更多記憶體,因為根據程式碼在處理一行行後不會縮緩衝區的大小。為避免這種情況,我們可以儲存緩衝區序列,而不是每次超過1KiB大小時調整大小。
此外,我們不會增長1KiB的 緩衝區,直到它完全為空。這意味著我們最終傳遞給ReadAsync越來越小的緩衝區,這將導致對作業系統的更多呼叫。
為了緩解這種情況,我們將在現有緩衝區中剩餘少於512個位元組時分配一個新緩衝區:
public class BufferSegment
{
public byte[] Buffer { get; set; }
public int Count { get; set; }
public int Remaining => Buffer.Length - Count;
}
async Task ProcessLinesAsync(NetworkStream stream)
{
const int minimumBufferSize = 512;
var segments = new List<BufferSegment>();
var bytesConsumed = 0;
var bytesConsumedBufferIndex = 0;
var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) };
segments.Add(segment);
while (true)
{
// Calculate the amount of bytes remaining in the buffer
if (segment.Remaining < minimumBufferSize)
{
// Allocate a new segment
segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) };
segments.Add(segment);
}
var bytesRead = await stream.ReadAsync(segment.Buffer, segment.Count, segment.Remaining);
if (bytesRead == 0)
{
break;
}
// Keep track of the amount of buffered bytes
segment.Count += bytesRead;
while (true)
{
// Look for a EOL in the list of segments
var (segmentIndex, segmentOffset) = IndexOf(segments, (byte)'\n', bytesConsumedBufferIndex, bytesConsumed);
if (segmentIndex >= 0)
{
// Process the line
ProcessLine(segments, segmentIndex, segmentOffset);
bytesConsumedBufferIndex = segmentOffset;
bytesConsumed = segmentOffset + 1;
}
else
{
break;
}
}
// Drop fully consumed segments from the list so we don't look at them again
for (var i = bytesConsumedBufferIndex; i >= 0; --i)
{
var consumedSegment = segments[i];
// Return all segments unless this is the current segment
if (consumedSegment != segment)
{
ArrayPool<byte>.Shared.Return(consumedSegment.Buffer);
segments.RemoveAt(i);
}
}
}
}
(int segmentIndex, int segmentOffest) IndexOf(List<BufferSegment> segments, byte value, int startBufferIndex, int startSegmentOffset)
{
var first = true;
for (var i = startBufferIndex; i < segments.Count; ++i)
{
var segment = segments[i];
// Start from the correct offset
var offset = first ? startSegmentOffset : 0;
var index = Array.IndexOf(segment.Buffer, value, offset, segment.Count - offset);
if (index >= 0)
{
// Return the buffer index and the index within that segment where EOL was found
return (i, index);
}
first = false;
}
return (-1, -1);
}
此程式碼只是得到很多更加複雜。當我們正在尋找分隔符時,我們同時跟蹤已填充的緩衝區序列。為此,我們此處使用List
我們的伺服器現在處理部分訊息,它使用池化記憶體來減少總體記憶體消耗,但我們還需要進行更多更改:
- 我們使用的byte[]和ArrayPool
的只是普通的託管陣列。這意味著無論何時我們執行ReadAsync或WriteAsync,這些緩衝區都會在非同步操作的生命週期內被固定(以便與作業系統上的本機IO API互操作)。這對GC有效能影響,因為無法移動固定記憶體,這可能導致堆碎片。根據非同步操作掛起的時間長短,池的實現可能需要更改。 - 可以通過解耦讀取邏輯和處理邏輯來優化吞吐量。這會建立一個批次處理效果,使解析邏輯可以使用更大的緩衝區塊,而不是僅在解析單個行後才讀取更多資料。這引入了一些額外的複雜性
- 我們需要兩個彼此獨立執行的迴圈。一個讀取Socket和一個解析緩衝區。
- 當資料可用時,我們需要一種方法來向解析邏輯發出訊號。
- 我們需要決定如果迴圈讀取Socket「太快」會發生什麼。如果解析邏輯無法跟上,我們需要一種方法來限制讀取回圈(邏輯)。這通常被稱為「流量控制」或「背壓」。
- 我們需要確保事情是執行緒安全的。我們現在在讀取回圈和解析迴圈之間共用多個緩衝區,並且這些緩衝區在不同的執行緒上獨立執行。
- 記憶體管理邏輯現在分佈在兩個不同的程式碼段中,從填充緩衝區池的程式碼是從通訊端讀取的,而從緩衝區池取資料的程式碼是解析邏輯。
- 我們需要非常小心在解析邏輯完成之後我們如何處理緩衝區序列。如果我們不小心,我們可能會返回一個仍由Socket讀取邏輯寫入的緩衝區序列。
複雜性已經到了極端(我們甚至沒有涵蓋所有案例)。高效能網路應用通常意味著編寫非常複雜的程式碼,以便從系統中獲得更高的效能。
System.IO.Pipelines的目標是使這種型別的程式碼更容易編寫。
使用System.IO.Pipelines的TCP伺服器
讓我們來看看這個例子的樣子System.IO.Pipelines:
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
return Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// 從PipeWriter至少分配512位元組
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// 告訴PipeWriter從通訊端讀取了多少
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// 標記資料可用,讓PipeReader讀取
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// 告訴PipeReader沒有更多的資料
writer.Complete();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
SequencePosition? position = null;
do
{
// 在緩衝資料中查詢找一個行末尾
position = buffer.PositionOf((byte)'\n');
if (position != null)
{
// 處理這一行
ProcessLine(buffer.Slice(0, position.Value));
// 跳過 這一行+\n (basically position 主要位置?)
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
}
}
while (position != null);
// 告訴PipeReader我們以及處理多少緩衝
reader.AdvanceTo(buffer.Start, buffer.End);
// 如果沒有更多的資料,停止都去
if (result.IsCompleted)
{
break;
}
}
// 將PipeReader標記為完成
reader.Complete();
}
我們的行讀取器的pipelines版本有2個迴圈:
FillPipeAsync從Socket讀取並寫入PipeWriter。
ReadPipeAsync從PipeReader中讀取並解析傳入的行。
與原始範例不同,在任何地方都沒有分配顯式緩衝區。這是管道的核心功能之一。所有緩衝區管理都委託給PipeReader/PipeWriter實現。
這使得使用程式碼更容易專注於業務邏輯而不是複雜的緩衝區管理。
在第一個迴圈中,我們首先呼叫PipeWriter.GetMemory(int)從底層編寫器獲取一些記憶體; 然後我們呼叫PipeWriter.Advance(int)告訴PipeWriter我們實際寫入緩衝區的資料量。然後我們呼叫PipeWriter.FlushAsync()來提供資料給PipeReader。
在第二個迴圈中,我們正在使用PipeWriter最終來自的緩衝區Socket。當呼叫PipeReader.ReadAsync()返回時,我們得到一個ReadResult包含2條重要資訊,包括以ReadOnlySequence
在每個迴圈結束時,我們完成了reader和writer。這允許底層Pipe釋放它分配的所有記憶體。
System.IO.Pipelines
除了處理記憶體管理之外,其他核心管道功能還包括能夠在Pipe不實際消耗資料的情況下檢視資料。
PipeReader有兩個核心API ReadAsync和AdvanceTo。ReadAsync獲取Pipe資料,AdvanceTo告訴PipeReader不再需要這些緩衝區,以便可以丟棄它們(例如返回到底層緩衝池)。
流量控制
在一個完美的世界中,讀取和解析工作是一個團隊:讀取執行緒消耗來自網路的資料並將其放入緩衝區,而解析執行緒負責構建適當的資料結構。通常,解析將比僅從網路複製資料塊花費更多時間。結果,讀取執行緒可以輕易地壓倒解析執行緒。結果是讀取執行緒必須減慢或分配更多記憶體來儲存解析執行緒的資料。為獲得最佳效能,在頻繁暫停和分配更多記憶體之間存在平衡。
為了解決這個問題,管道有兩個設定來控制資料的流量,PauseWriterThreshold和ResumeWriterThreshold。PauseWriterThreshold決定有多少資料應該在呼叫PipeWriter.FlushAsync之前進行緩衝停頓。ResumeWriterThreshold控制reader消耗多少後寫入可以恢復。
IO排程
通常在使用async / await時,會線上程池執行緒或當前執行緒上呼叫continuation SynchronizationContext。
在執行IO時,對執行IO的位置進行細粒度控制非常重要,這樣可以更有效地利用CPU快取,這對於Web伺服器等高效能應用程式至關重要。Pipelines公開了一個PipeScheduler確定非同步回撥執行位置的方法。這使得呼叫者可以精確控制用於IO的執行緒。
實踐中的一個範例是在Kestrel Libuv傳輸中,其中IO回撥在專用事件迴圈執行緒上執行。
簡介
升訊威線上客服與行銷系統是一款客服軟體,但更重要的是一款行銷利器。
- 可以追蹤正在存取網站或使用 APP 的所有訪客,收集他們的瀏覽情況,使客服能夠主動出擊,施展話術,促進成單。
訪* 客端在 PC 支援所有新老瀏覽器。包括不支援 WebSocket 的 IE8 也能正常使用。 - 行動端支援所有手機瀏覽器、APP、各大平臺的公眾號對接。
- 支援訪客資訊互通,可傳輸訪客標識、名稱和其它任意資訊到客服系統。
- 具備一線專業技術水平,網路中斷,拔掉網線,手機飛航模式,不丟訊息。同類軟體可以按視訊方式對比測試。
-
- bilibili 視訊:https://www.bilibili.com/video/BV1pK4y1N7UP?t=22