Paddle圖神經網路訓練-PGLBox程式碼閱讀筆記
| 圖儲存部分 | ||
|---|---|---|
| paddle/fluid/framework/fleet/heter_ps | graph_gpu_wrapper.h | GPU圖主入口 |
| graph_gpu_ps_table.h | GPU圖的主要儲存結構,neighbor取樣等都在這裡完成 | |
| gpu_graph_node.h | 節點,邊,鄰居等資料結構定義 | |
| paddle/fluid/distributed/ps/table/ | common_graph_table.h | CPU圖儲存 |
| 圖遊走部分 | ||
| paddle/fluid/framework/ | data_feed.h/data_feed.cu | SlotRecordInMemoryDataFeed 使用的datafeedGraphDataGenerator 圖遊走,準備輸入資料的封裝 |
| data_set.h | SlotRecordDataset 使用的dataset |
整體流程:
資料結構
- 讀入圖資料到記憶體
cpu_graph_table_, 即node和edge, 分別如下格式:
# edge
"0\t1",
"0\t9",
"1\t2",
# node
"user\t37\ta 0.34\tb 13 14\tc hello\td abc",
"item\t111\ta 0.21",
user和item讀到不同的GraphFeature結構裡面, 載入時會把user/item 通過node_to_id轉成int型別
圖儲存轉換適配視訊記憶體儲存
make_gpu_ps_graph 把cpu的node結構打平儲存, 通過多執行緒的方式把每個節點的鄰居儲存到 egde陣列裡, 每個節點通過neighbor_offset和neighbor_size, 就能在edge_array裡拿到自己的所有鄰居. 下面是一個neighbor具體的儲存例子
suppose we have a graph like this
0----3-----5----7
\ |\ |\
17 8 9 1 2
we save the nodes in arbitrary order,
in this example,the order is
[0,5,1,2,7,3,8,9,17]
let us name this array u_id;
we record each node's neighbors:
0:3,17
5:3,7
1:7
2:7
7:1,2,5
3:0,5,8,9
8:3
9:3
17:0
by concatenating each node's neighbor_list in the order we save the node id.
we get [3,17,3,7,7,7,1,2,5,0,5,8,9,3,3,0]
this is the neighbor_list of GpuPsCommGraph
given this neighbor_list and the order to save node id,
we know,
node 0's neighbors are in the range [0,1] of neighbor_list
node 5's neighbors are in the range [2,3] of neighbor_list
node 1's neighbors are in the range [4,4] of neighbor_list
node 2:[5,5]
node 7:[6,6]
node 3:[9,12]
node 8:[13,13]
node 9:[14,14]
node 17:[15,15]
...
by the above information,
we generate a node_list and node_info_list in GpuPsCommGraph,
node_list: [0,5,1,2,7,3,8,9,17]
node_info_list: [(2,0),(2,2),(1,4),(1,5),(3,6),(4,9),(1,13),(1,14),(1,15)]
記憶體->視訊記憶體的圖儲存
build_graph_from_cpu 構建GPUPSTable, 邊的型別也有多種, 通過edge_idx來區分.
- 先把所有node_id MemCPY 到VRAM
- 根據每個node的sparse feature數量, build_ps
- 把所有節點對應的鄰居節點copy到VRAM
注意: GpuPsGraphTable裡的table型別分為EDGE_TABLE和FEA_TABLE, 根據table型別和idx獲取對應的table, fea_table只有一個, 而EDGE_TABLE有type型別個
鄰居取樣
graph_neighbor_sample(int gpu_id, uint64_t *device_keys, int walk_degree, int len) walk_degree指的是鄰居節點取樣後的個數, 比如要給100個節點取樣鄰居,每個取樣10個鄰居, 這裡就是 (0, keys, 10, 100), TODO: 待確認這個函數是否使用
NeighborSampleResult用於儲存deepwalk結果, 在視訊記憶體裡.split_input_to_shard, 把要查的node分配到對應的顯示卡上. 並按照顯示卡序號重排, 把相同顯示卡的key排到一塊. left就是起始, right就是結束fill_shard_key: 把每張卡里存的node_id填到d_shard_keys裡面walk_to_dest: 把各自卡的shard_keys copy到對應卡的視訊記憶體裡- 每張卡各自非同步進行neighbor_sample, 把取樣的結果填到node.val_storage裡面. 最後move_result_to_source_gpu 再copy回原卡上.
fill_dvalues: 因為之前重排序過, 根據之前重排的idx, 還原原始順序, 把d_shard_vals賦值給val- 求actual_sample_size字首和: cumsum_actual_sample_size
- 把val中的空位置給去掉, 把不等長的actual_sample填充到actual_val裡面 (需要開啟壓縮, compress入參=true)
- 取樣圖示:
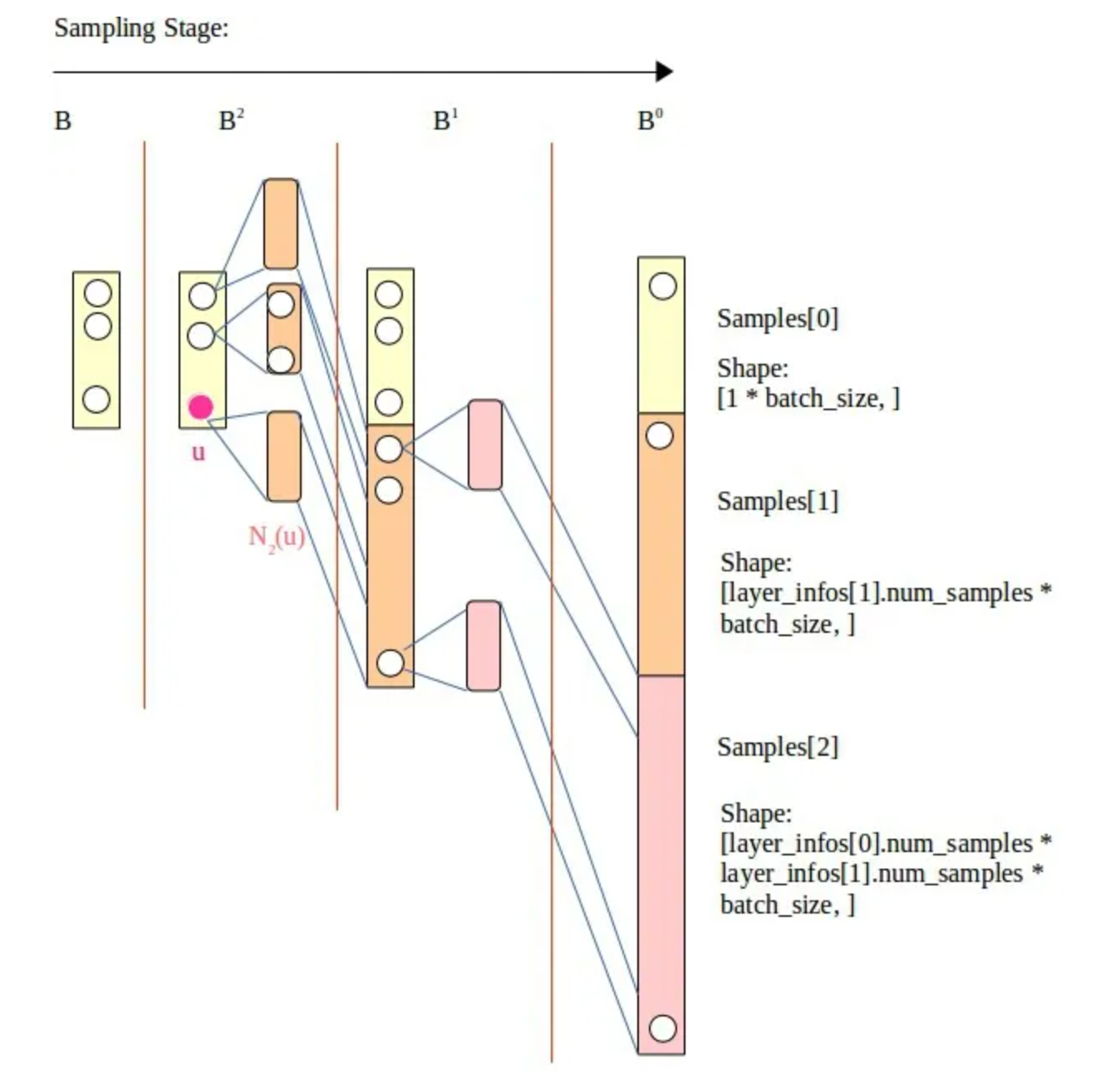
圖遊走
GraphDataGenerator核心函數: DoWalkandSage
各個成員解釋:
once_sample_startid_len_: 其實就是batch_size, 控制每次遊走的樣本數量, 使視訊記憶體能夠儘可能放下
walk_degree_(就是設定裡的walk_times): 每個起始節點重複n次遊走,這樣可以儘可能把一個節點的所有鄰居遊走一遍,使得訓練更加均勻
walk_len: metapath 遊走路徑深度
meta_path: 控制user和item交叉遊走
一. FillWalkBuf 進行鄰居節點遊走後填充到視訊記憶體buf中
- 根據起始節點型別, 把對應的節點找到
d_type_keys, 總長度batch_size * 遊走深度 * 遊走次數 * repeat_time; repeat_time的計算方式(python裡)如下: 用來控制遊走佔用視訊記憶體的大小
#第一步: 根據顯示卡當前的視訊記憶體大小和分配比例, 算出來最大單次遊走的去重後node個數
allocate_memory_bytes = total_gpu_memory_bytes * allocate_rate
train_pass_cap = max_unique_nodes = int(allocate_memory_bytes / (emb_size * 4 * 2))
#第二步: sample_size: 一層鄰居,二層鄰居取樣的個數
train_chunk_nodes = int(config.walk_len * config.walk_times * config.batch_size)
train_chunk_nodes *= np.prod(config.samples) * config.win_size
#第三步: 算大概去重前的大小, 這裡uniq_factor=0.4是咋定的?
train_sample_times_one_chunk = int(train_pass_cap / train_chunk_nodes / uniq_factor)
#滿意子圖上這個計算的結果
repeat_time_ = 40G * 0.1 / (100 * 4 * 2) / (8 * 10 * batch_size) * (3 * 2 * 2) / 0.4
-
進行鄰居取樣, 即呼叫
graph_neighbor_sample_v3, 如果取樣結果為空跳過這個batch, 每次FillOneStep前都要重新鄰居取樣 -
FillOneStep重要函數-
根據meta_path獲取遊走方式, 比如
meta_path: "u2t-t2u;t2u-u2t", 表示從u型別node->t型別node->u型別node, 解析設定時把u和t轉成了int型別的id, 通過src_node_id << 32 | dst_node_id 的方式儲存擴充套件關係 -
根據每個node對應的鄰居實際長度actual_sample_size, 求出字首和, 用於定位每個node在neighbor陣列裡對應的起始偏移量.
-
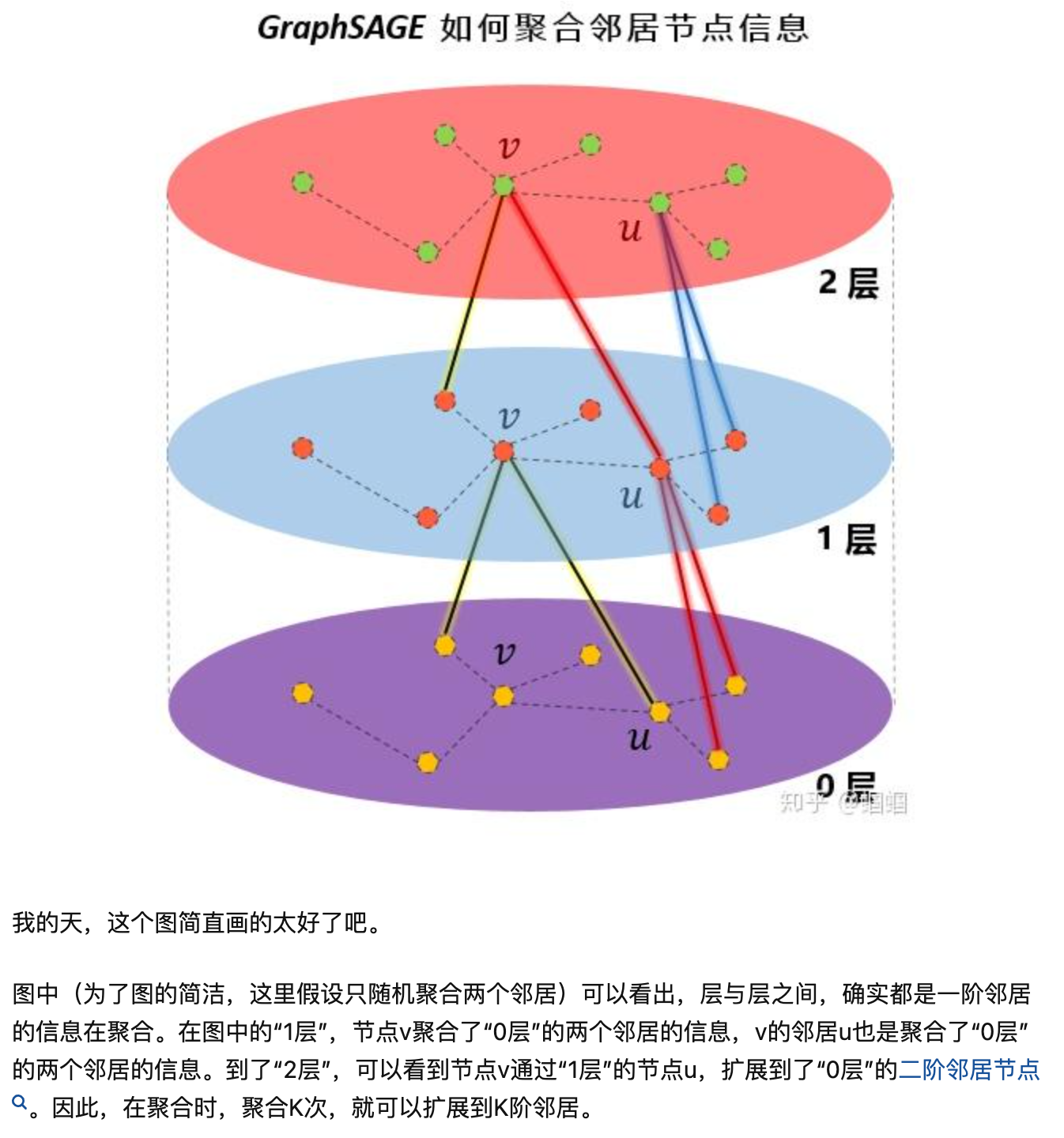
第一次遊走
GraphFillFirstStepKernel, 按照下圖的格式填到遊走結果: walk&walk_ntype裡面. 另外記錄下sample_key(長度 sum(actual_sample_size) * len), 後續輪次的遊走就不填walk了, 只記錄sample_key(這個用於後續遊走輪數的key記錄), 這個kernel只填walk[off+1], 即第一次的結果. -
node: 0, 1, 2, 3, 4 ... //id neighbor: 0, 0, 1, 1, 1 ...//每個id對應的鄰居列表 actual_size: 2, 3, ... //各個id對應的鄰居列表的長度 prefix_sum: 0, 2, 5, ... //鄰居長度字首和 --> walk: | | |0(key)---walk_len-1次遊走id---|...鄰居個數個| 1(key)---walk_len-1次遊走id---|...鄰居個| ...batch_size個| 總長度: (walk_len + 1) * 每個key對應的actual_sample_size * batch_size walk_ntype: 儲存walk中每個位置上對應的node型別 -
GraphDoWalkKernel根據d_sampleidx2row聚合walk. 把第二次遊走到最後一次遊走直接的所有d_walk填充好
-
-
第一次遊走單獨執行後, for迴圈進行圖的深度迭代(類似bfs), 如下圖. 也是先取樣, 然後繼續FillOneStep
-
更新全域性取樣狀態, 更新起始節點到下一個batch, cursor用於記錄當前遊走到了哪個型別的node(u還是t)
-
做一次全域性shuffle(total_sample_size * walk_len)
-
遊走步驟圖示:
二. FillInsBuf 構造訓練樣本
struct BufState {
int left;
int right;
int central_word; //正中間在哪, 初始值-1
int step; //初始值0
engine_wrapper_t random_engine_; //
int len; //初始值0
int cursor; //遊標, 用來記錄在所有樣本長度上處理到了第幾個batch
int row_num;
int batch_size;
int walk_len; //遊走深度
std::vector<int>* window; //視窗, 如果win_size=2 裡面儲存 -2, -1, 1, 2
}
樣本取樣之所以有central_word, 並且從中心開始左右擴充套件進行隨機的原理如下:
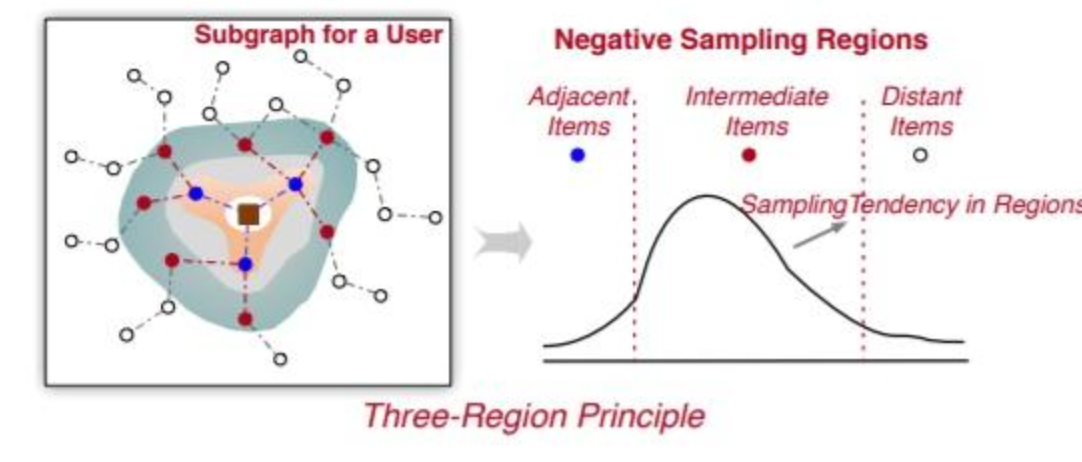
- 鄰接區域:在基於圖的推薦中,相鄰區域中的商品通常用於為中心使用者 u 傳播特徵資訊。因此,這些商品代表了使用者的積極偏好,不應作為消極偏好進行取樣。
- 中間區域:與相鄰商品不同的是,中間區域的這些商品被認為是可以為模型訓練帶來更多資訊的近似正樣本的難樣本。這些中間節點離中心使用者 u 有點遠,當它們作為相鄰商品在使用者-專案圖中傳播資訊時,會降低(或略微提高)推薦效能。與相鄰商品相比,這些中間商品在效能上的提升有限,有時甚至會降低效能。此外,將這些中間項傳播到中心節點可能會導致大量記憶體消耗。因此,中間專案應該被充分取樣為負樣本以增強負樣本。
- 更遠區域:距離中心使用者u很遠的商品節點,可以看做是易負樣本,這些樣本是很容易擬合的,在這上面過多的負取樣對效能提升幫助不大。
上面這個BufState就是用來記錄取樣位置的. (TODO: 這裡PGL用的平均分佈, 可能有效果優化空間)
MakeInsPair: 核心邏輯是(GraphFillIdKernel)
- 先過濾不在meta_path裡的pair對
- |src/src+step|...這種形式儲存到id_tensor, random_row應該是用來打亂節點順序的, 可能是想避免節點總是從0-n導致影響效果.
三 GenerateSampleGraph
第一步, 根據cursor算出當前batch的ins_buf偏移量
第二步, 對遊走序列進行去重dedup_keys_and_fillidx, 猜測例子是1->2->1->2, 這種把反覆遊走的序列給刪掉. 只保留一個1->2, 具體步驟:
-
填充好去重前的idx:
fill_idx -
根據key排序key和idx:
cub_sort_pairs -
統計相同key的數量:
cub_runlength_encode -
求key數量的字首和:
cub_exclusivesum -
根據重複率不同分別走不同的重填充kernel, 重複率高的時候用二分查詢:
kernel_fill_restore_idx
接下來根據鄰居取樣的層數進行迴圈
第三步, SampleNeighbors
graph_neighbor_sample_all_edge_type從GraphTable裡查詢每個meta_graph對應的edge_type表, 這個函數hipo實現時要重寫- 把key copy到對應的卡上
neighbor_sample_kernel_all_edge_type: 在每個edge_type對應的GpuPsCommGraph獲取edge權重. 如果鄰居個數超過sample_size, 從中隨機選取size個.- 把結果從記憶卡上copy回來:
move_result_to_source_gpu_all_edge_type, node.val_storage->d_shard_vals_ptr 並且填充value(根據actual_sample_size) neighbor_sample_kernel_all_edge_type, 把按卡進行重新排序的shard_vals根據之前儲存的索引, 給填回到NeighborSampleResultV2.val裡面
- 求各個edge結果actual_size的字首和, 總長度: uniq_node的個數 * edge_type個數, 把各個type的總長度儲存到edges_split_num裡面
FillActualNeighbors: 之前查詢edge_type的結果裡存在空值, 因為每個node對應的鄰居為sample_size個, 有些不滿長度的後面有空值, 根據actual_size把空值刪掉.
第四步: GetReindexResult 主要目的是對輸入的中心節點資訊和鄰居資訊進行從 0 開始的重新編號(同時去重鄰居節點),以方便後續的圖模型子圖訓練 API解釋
第五步: GetNodeDegree: 獲取各個node的neighbor_size
第六步: CopyUniqueNodes: 如果不是全視訊記憶體的儲存方式, 需要copy回記憶體.
四 GenerateBatch.Next() 填充slot/show/clk
FillGraphIdShowClkTensor: 直接全填1, 圖模型應該沒用這兩個欄位, 僅用於sparse更新
FillGraphSlotFeature:
get_feature_info_of_nodes: 依然是把node發到對應的卡上查- 從tables_裡查到node key對應的
GpuPsFeaInfo指標後, 從這個裡面讀取出feature_size - 計算每個node的feature_size的字首和
get_features_kernel: 根據feature_offset 在GpuPsCommGraphFea裡面, 從feature_list和slot_list裡讀出來- copy回原卡
move_result_to_source_gpu fill_feature_and_slot: 根據原來的idx把按卡號排序後的val填到排序前的位置裡面.
- 從tables_裡查到node key對應的
PGL設定
# ---------------------------資料設定-------------------------------------------------#
# 每種邊型別對應的檔案或者目錄, 這裡u2t_edges目錄對應graph_data_hdfs_path目錄下的u2u_edges目錄, 其它的以此類推。
# 如果u和t之間既有點選關係,有可能有關注關係,那麼可以用三元組表示,即用:u2click2t 和 u2focus2t 來表示點選和關注這兩種不同的關係
# 下面的範例表示u2t的邊儲存在 ${graph_data_hdfs_path}/u2t_edges/目錄
etype2files: "u2mainfeed2i:sl_1,u2faxian2i:sl_178"
# 每種節點型別對應的檔案或目錄, 不同型別的節點可以放在同個檔案,讀取的時候會自動過濾的。
# 下面的範例表示節點儲存在 ${graph_data_hdfs_path}/node_types/目錄
ntype2files: "u:nodes.txt,i:nodes.txt"
# the pair specified by 'excluded_train_pair' will not be trained, eg "w2q;q2t"
excluded_train_pair: ""
# only infer the node(s) specified by 'infer_node_type', eg "q;t"
infer_node_type: ""
# 目前使用graph_shard 的功能, 對資料進行分片,必須分片為1000 個part檔案
#hadoop_shard: True
auto_shard: True
num_part: 1000
# 是否雙向邊(目前只支援雙向邊)
symmetry: True
# ---------------------------圖遊走設定-------------------------------------------------#
# meta_path 元路徑定義。 注意跟etype2files變數的邊型別對應。用「-」隔開
# 按照下面的設定可以設定多條metapath, 每個";"號是一條使用者定義的metapath
meta_path: "u2mainfeed2i-i2mainfeed2u;i2mainfeed2u-u2mainfeed2i;u2faxian2i-i2faxian2u;i2faxian2u-u2faxian2i"
# 遊走路徑的正樣本視窗大小
win_size: 2
# neg_num: 每對正樣本對應的負樣本數量
neg_num: 5
# walk_len: metapath 遊走路徑深度
walk_len: 8
# walk_times: 每個起始節點重複n次遊走,這樣可以儘可能把一個節點的所有鄰居遊走一遍,使得訓練更加均勻。
walk_times: 10
# ---------------------------模型引數設定---------------------------------------------#
# 模型型別選擇
model_type: GNNModel
# embedding 維度,需要和hidden_size保持一樣。
emb_size: 100
# sparse_type: 稀疏引數伺服器的優化器,目前支援adagrad, shared_adam
sparse_type: adagrad_v2
# sparse_lr: 稀疏引數伺服器的學習率
sparse_lr: 0.1
# dense_lr: 稠密引數的學習率
dense_lr: 0.0005 #001
# slot_feature_lr: slot特徵的學習率
slot_feature_lr: 0.001
init_range: 0.1
# loss_type: 損失函數,目前支援hinge; sigmoid; nce
loss_type: sigmoid
margin: 2.0 # for hinge loss
# 如果slot 特徵很多(超過5個), 建議開啟softsign,防止數值太大。
softsign: False
# 對比學習損失函數選擇: 目前支援 simgcl_loss
gcl_loss: simgcl_loss
# sage 模型設定開關
sage_mode: True
# sage_layer_type: sage 模型型別選擇
sage_layer_type: "LightGCN"
sage_alpha: 0.8
samples: [3,2]
infer_samples: [10,10]
sage_act: "relu"
hcl: True
use_degree_norm: True
# 帶權取樣開關,同時作用於遊走和sage子圖取樣階段。
weighted_sample: True
# 是否返回邊權重,僅用於sage_mode=True模式,如邊不帶權則預設返回1。
return_weight: False
# 是否要進行訓練,如果只想單獨熱啟模型做預估(inference),則可以關閉need_train
need_train: True
# 是否需要進行inference. 如果只想單獨訓練模型,則可以關閉need_inference
need_inference: True
# 預估embedding的時候,需要的引數,保持預設即可.
dump_node_name: "src_node___id"
dump_node_emb_name: "src_node___emb"
# 是否需要dump遊走路徑
need_dump_walk: False
# ---------------------------train param config---------------------------------------------#
epochs: 3
# 訓練樣本的batch_size
batch_size: 50000
infer_batch_size: 30000
chunk_num: 1
# 1 for debug
debug_mode: 0
# 大致設定gpups的視訊記憶體佔用率 預設 0.25
gpups_memory_allocated_rate: 0.05
# 訓練模式,可填WHOLE_HBM/MEM_EMBEDDING/SSD_EMBEDDING,預設為MEM_EMBEDDING
train_storage_mode: MEM_EMBEDDING
jupyter: False
version: v_refactor_0104
# ---------------------------例行訓練和預測------------------------------#
# 若修改為"online_train",則表示需要進行例行訓練,否則預設為普通訓練模式。
train_mode: "online_train"
# 例行訓練的第一次圖資料起始時間。(注意,天級別更新的時候,日期的格式也一定要是20230217/00, 不能省略小時的單位)
start_time: 20230814/00
# 例行訓練的小時級間隔(當train_mode=online_train時生效),time_delta=1表示每次訓練一個小時資料,然後換到下一個小時。如果是天級別更新,則time_delta=24。
time_delta: 24
# ---------------------------save config---------------------------------------------#
# 為了加快訓練速度,可以設定每隔多少個epochs才儲存一次模型。預設最後一個epoch訓練完一定會儲存模型。
save_model_interval: 10
# 觸發ssd cache的頻率
save_cache_frequency: 4
# 記憶體中快取多少個pass
mem_cache_passid_num: 4
# 是否儲存為二進位制模式,僅在SSD模式下生效
save_binary_mode : False
# 儲存模型前,是否需要根據threshold刪除embedding
need_shrink: True
newest_time: 20230904/00
參考資料:
GraphSage原理: https://zhuanlan.zhihu.com/p/336195862
Graph4Rec論文: https://arxiv.org/pdf/2112.01035.pdf
取樣論文綜述: https://arxiv.org/pdf/2103.05872.pdf
負取樣原理介紹: https://zhuanlan.zhihu.com/p/484123877