什麼是覆蓋索引?
2023-09-05 18:01:01
前言
要搞明白覆蓋索引首先就得明白主鍵索引和輔助索引的區別,以及查詢時引擎的工作方式。
當然,以上都是基於innoDB引擎來說。
主鍵索引與輔助索引的區別
相信大家也瞭解過這方面的知識,這裡就不展開了,直接上總結。
主鍵索引
葉子節點儲存資料
輔助索引
葉子節點儲存主鍵值
查詢一條資料是如何工作的呢
先說查詢過程:
由於輔助索引只儲存主鍵的值,如果使用輔助索引搜尋資料就必須先從輔助索引取到主鍵的值,再使用主鍵的值去主鍵索引上查詢,直到找到葉子節點上的資料返回。 ---- 這個也稱之為回表
那麼如何避免**回表**查詢的發生呢?
如果輔助索引上已經存在我們需要的資料,那麼引擎就不會去主鍵上去搜尋資料了。 ---- 這個就是所謂的"**覆蓋索引**"
接下來我們來證明一下它。
回表查詢
假如有這樣一張表:
CREATE TABLE `test` ( `id` int(11) NOT NULL, `age` int(11) NOT NULL, `name` varchar(255) NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `idx_age_name` (`age`,`name`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
我們給age新增一個索引, 接下來隨意插入幾條資料
insert into test(`id`,`age`,`name`) VALUES(1,10,"小明"),(2,11,"小紅"),(3,12,"小偉");
查詢一條資料
select * from test where age = 10
檢視一下耗時

分析一下語句:
desc select * from test where age = 10
檢視執行計劃:
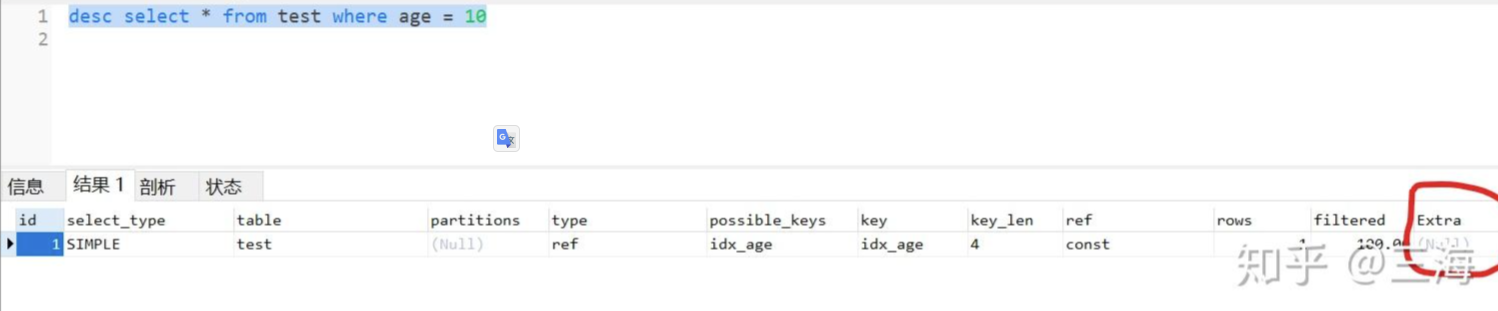
可以看到extra列為空,key則使用了idx_age索引, 大致的查詢耗時在0.024秒左右。
這樣的查詢速度快嗎?
我說我還能再優化一下,你敢信嗎? - 魯迅(我沒說過)
覆蓋索引
只需要稍微改變一下查詢的欄位, 我們就發現其中的區別了。
select age,name from test where age = 10
檢視一下耗時:

可以看到耗時減少了!
發生了什麼呢,我們再來分析一下語句
desc select age,name from test where age = 10

可以看到extra列有一個 *using idnex* , 這個的意思就是使用了覆蓋索引,無需回表查詢了。