聊透 GPU 通訊技術——GPU Direct、NVLink、RDMA
最近人工智慧大火,AI 應用所涉及的技術能力包括語音、影象、視訊、NLP 等多方面,而這些都需要強大的計算資源支援。AI 技術對算力的需求是非常龐大的,雖然 GPU 的計算能力在持續提升,但是對於 AI 來說,單卡的計算能力就算再強,也是有極限的,這就需要多 GPU 組合。而 GPU 多卡的組合,主要分為單個伺服器多張 GPU 卡和多個伺服器,每個伺服器多張卡這兩種情況,無論是單機多卡還是多機多卡,GPU 之間需要有超強的通訊支援。接下來,我們就來聊聊 GPU 通訊技術。
單機多卡GPU通訊
GPU Direct
GPU Direct 是 NVIDIA 開發的一項技術,可實現 GPU 與其他裝置(例如網路介面卡 (NIC) 和儲存裝置)之間的直接通訊和資料傳輸,而不涉及 CPU。
傳統上,當資料需要在 GPU 和另一個裝置之間傳輸時,資料必須通過 CPU,從而導致潛在的瓶頸並增加延遲。使用 GPUDirect,網路介面卡和儲存驅動器可以直接讀寫 GPU 記憶體,減少不必要的記憶體消耗,減少 CPU 開銷並降低延遲,從而顯著提高效能。GPU Direct 技術包括 GPUDirect Storage、GPUDirect RDMA、GPUDirect P2P 和 GPUDirect 視訊。
GPUDirect Storage
GPUDirect Storage 允許儲存裝置和 GPU 之間進行直接資料傳輸,繞過 CPU,減少資料傳輸的延遲和 CPU 開銷。
通過 GPUDirect Storage,GPU 可以直接從儲存裝置(如固態硬碟(SSD)或非易失性記憶體擴充套件(NVMe)驅動器)存取資料,而無需將資料先複製到 CPU 的記憶體中。這種直接存取能夠實現更快的資料傳輸速度,並更高效地利用 GPU 資源。
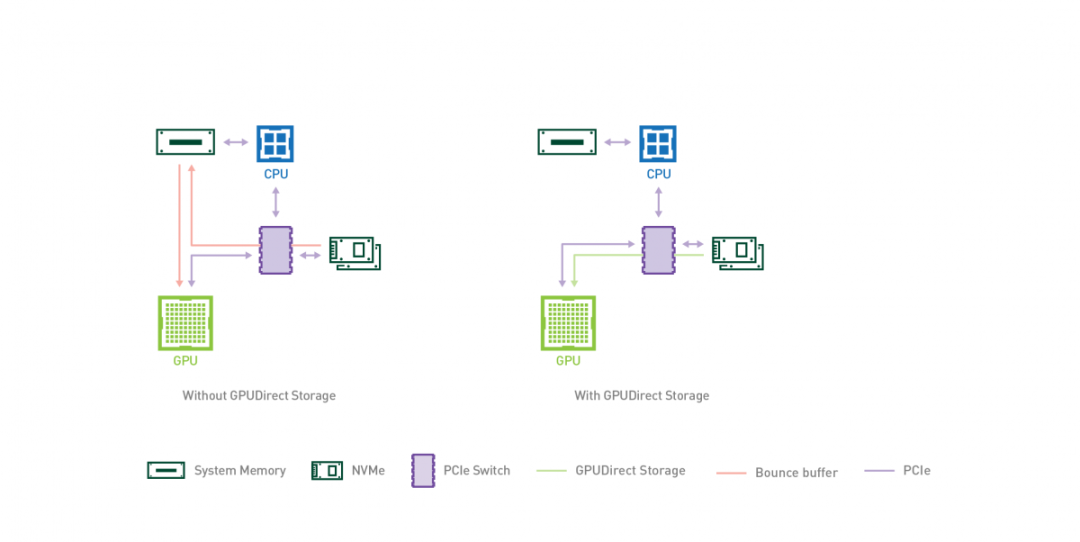
GPUDirect Storage 的主要特點和優勢包括:
- 減少 CPU 參與:通過繞過 CPU,實現 GPU 和儲存裝置之間的直接通訊,GPUDirect Storage 減少了 CPU 開銷,並釋放 CPU 資源用於其他任務,從而改善系統的整體效能。
- 低延遲資料存取:GPUDirect Storage 消除了資料通過 CPU 的傳輸路徑,從而最小化了資料傳輸的延遲。這對於實時分析、機器學習和高效能運算等對延遲敏感的應用非常有益。
- 提高儲存效能:通過允許 GPU 直接存取儲存裝置,GPUDirect Storage 實現了高速資料傳輸,可以顯著提高儲存效能,加速資料密集型工作負載的處理速度。
- 增強的可延伸性:GPUDirect Storage 支援多 GPU 設定,允許多個 GPU 同時存取儲存裝置。這種可延伸性對於需要大規模並行處理和資料分析的應用至關重要。
- 相容性和生態系統支援:GPUDirect Storage 設計用於與各種儲存協定相容,包括 NVMe、NVMe over Fabrics和網路附加儲存(NAS)。它得到了主要儲存供應商的支援,並整合到流行的軟體框架(如NVIDIA CUDA)中,以簡化與現有的 GPU 加速應用程式的整合。
GPUDirect P2P
某些工作負載需要位於同一伺服器中的兩個或多個 GPU 之間進行資料交換,在沒有 GPUDirect P2P 技術的情況下,來自 GPU 的資料將首先通過 CPU 和 PCIe 匯流排複製到主機固定的共用記憶體。然後,資料將通過 CPU 和 PCIe 匯流排從主機固定的共用記憶體複製到目標 GPU,資料在到達目的地之前需要被複制兩次。

有了 GPUDirect P2P 通訊技術後,將資料從源 GPU 複製到同一節點中的另一個 GPU 不再需要將資料臨時暫存到主機記憶體中。如果兩個 GPU 連線到同一 PCIe 匯流排,GPUDirect P2P 允許存取其相應的記憶體,而無需 CPU 參與。前者將執行相同任務所需的複製運算元量減半。
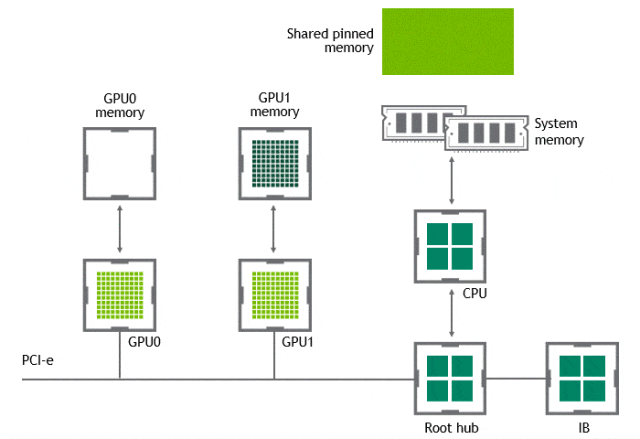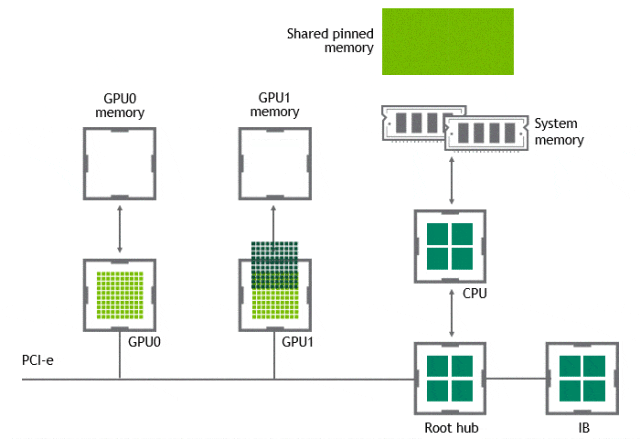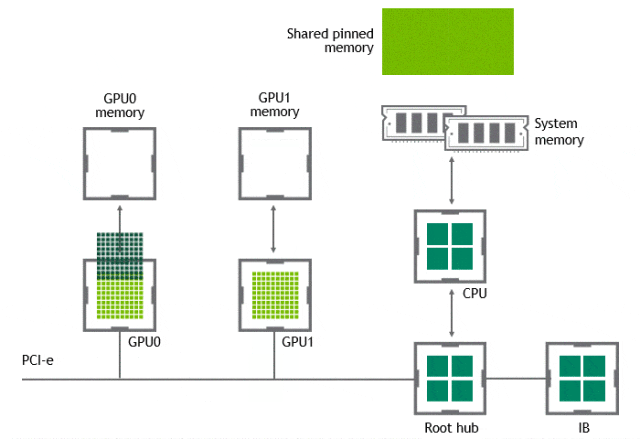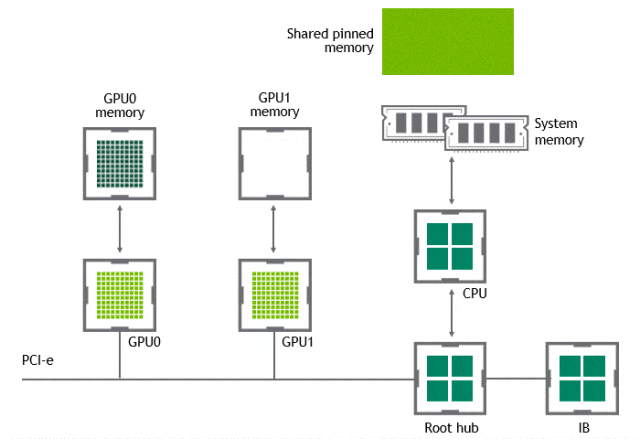
NVLink
在 GPUDirect P2P 技術中,多個 GPU 通過 PCIe 直接與 CPU 相連,而 PCIe3.0*16 的雙向頻寬不足 32GB/s,當訓練資料不斷增長時,PCIe 的頻寬滿足不了需求,會逐漸成為系統瓶頸。為提升多 GPU 之間的通訊效能,充分發揮 GPU 的計算效能,NVIDIA 於 2016 年釋出了全新架構的 NVLink。NVLink 是一種高速、高頻寬的互連技術,用於連線多個 GPU 之間或連線 GPU 與其他裝置(如CPU、記憶體等)之間的通訊。NVLink 提供了直接的對等連線,具有比傳統的 PCIe 匯流排更高的傳輸速度和更低的延遲。
- 高頻寬和低延遲:NVLink 提供了高達 300 GB/s 的雙向頻寬,將近 PCle 3.0 頻寬的 10 倍。對等連線超低延遲,可實現快速、高效的資料傳輸和通訊。
- GPU 間通訊:NVLink 允許多個 GPU 之間直接進行對等的通訊,無需通過主機記憶體或 CPU 進行資料傳輸。
- 記憶體共用:NVLink 還支援 GPU 之間的記憶體共用,使得多個 GPU 可以直接存取彼此的記憶體空間。
- 彈性連線:NVLink 支援多種連線設定,包括 2、4、6 或 8 個通道,可以根據需要進行靈活的設定和擴充套件。這使得 NVLink 適用於不同規模和需求的系統設定。
NVSwitch
NVLink 技術無法使單伺服器中 8 個 GPU 達到全連線,為解決該問題,NVIDIA 在 2018 年釋出了 NVSwitch,實現了 NVLink 的全連線。NVIDIA NVSwitch 是首款節點交換架構,可支援單個伺服器節點中 16 個全互聯的 GPU,並可使全部 8 個 GPU 對分別達到 300GB/s 的速度同時進行通訊。
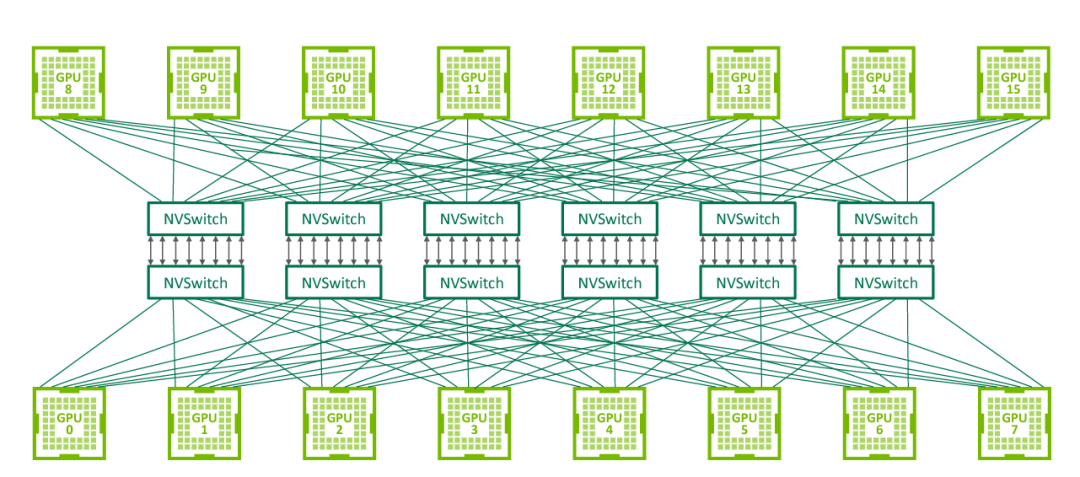
△ NVSwitch 全連線拓撲
多機多卡GPU通訊
RDMA
AI 計算對算力需求巨大,多機多卡的計算是一個常態,多機間的通訊是影響分散式訓練的一個重要指標。在傳統的 TCP/IP 網路通訊中,資料傳送方需要將資料進行多次記憶體拷貝,並經過一系列的網路協定的封包處理工作;資料接收方在應用程式中處理資料前,也需要經過多次記憶體拷貝和一系列的網路協定的封包處理工作。經過這一系列的記憶體拷貝、封包處理以及網路傳輸延時等,伺服器間的通訊時延往往在毫秒級別,不能夠滿足多機多卡場景對於網路通訊的需求。
RDMA(Remote Direct Memory Access)是一種繞過遠端主機而存取其記憶體中資料的技術,解決網路傳輸中資料處理延遲而產生的一種遠端記憶體直接存取技術。
目前 RDMA 有三種不同的技術實現方式:
- InfiniBand(IB):IB 是一種高效能互連技術,它提供了原生的 RDMA 支援。IB 網路使用專用的 IB 介面卡和交換機,通過 RDMA 操作實現節點之間的高速直接記憶體存取和資料傳輸。
- RoCE(RDMA over Converged Ethernet):RoCE是在乙太網上實現 RDMA 的技術。它使用標準的乙太網作為底層傳輸媒介,並通過使用 RoCE 介面卡和適當的協定棧來實現 RDMA 功能。
- iWARP:iWARP 是基於 TCP/IP 協定棧的 RDMA 實現。它使用普通的乙太網介面卡和標準的網路交換機,並通過在 TCP/IP 協定棧中實現 RDMA 功能來提供高效能的遠端記憶體存取和資料傳輸。
GPUDirect RDMA
GPUDirect RDMA 結合了 GPU 加速計算和 RDMA(Remote Direct Memory Access)技術,實現了在 GPU 和 RDMA 網路裝置之間直接進行資料傳輸和通訊的能力。它允許 GPU 直接存取 RDMA 網路裝置中的資料,無需通過主機記憶體或 CPU 的中介。
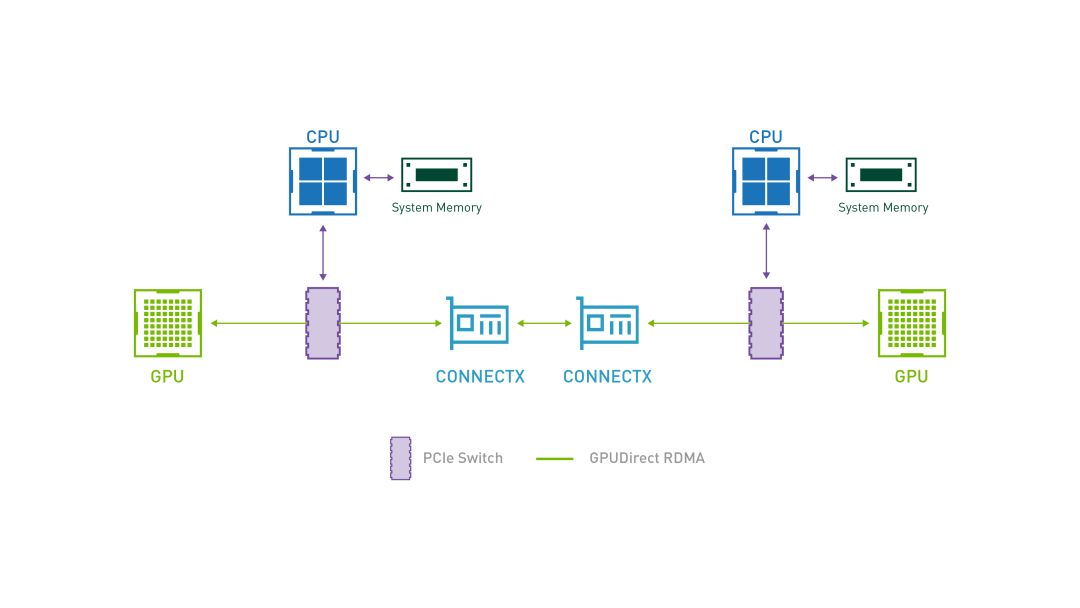
GPUDirect RDMA 通過繞過主機記憶體和 CPU,直接在 GPU 和 RDMA 網路裝置之間進行資料傳輸,顯著降低傳輸延遲,加快資料交換速度,並可以減輕 CPU 負載,釋放 CPU 的計算能力。另外,GPUDirect RDMA 技術允許 GPU 直接存取 RDMA 網路裝置中的資料,避免了資料在主機記憶體中的複製,提高了資料傳輸的頻寬利用率
IPOIB
IPOIB(IP over InfiniBand)是一種在 InfiniBand 網路上執行 IP 協定的技術。它將標準的 IP 協定棧與 IB 互連技術相結合,使得在 IB 網路上的節點能夠使用 IP 協定進行通訊和資料傳輸。
IPOIB 提供了基於 RDMA 之上的 IP 網路模擬層,允許應用無修改的執行在 IB 網路上。但是,IPoIB 仍然經過核心層(IP Stack),會產生大量系統呼叫,並且涉及 CPU 中斷,因此 IPoIB 效能比 RDMA 通訊方式效能要低,大多數應用都會採用 RDMA 方式獲取高頻寬低延時的收益,少數的關鍵應用會採用 IPoIB 方式通訊。
在大規模計算中,單機多卡場景下使用 GPUDiect、NVLink 技術,分散式場景下使用 GPUDirect RDMA 技術,可以大大縮短通訊時間,提升整體效能。
如果你對 GPU 相關技術感興趣,你可以用它嘗試搭建 AI 繪畫平臺或者做一些推理的工作。AI 繪畫搭建的教學我先放在這裡啦:《從 0 到 1,帶你玩轉 AI 繪畫》