基於 LLM 的知識圖譜另類實踐
本文整理自社群使用者陳卓見在「夜談 LLM」主題分享上的演講,主要包括以下內容:
- 利用大模型構建知識圖譜
- 利用大模型操作結構化資料
- 利用大模型使用工具
利用大模型構建知識圖譜

上圖是之前,我基於大語言模型構建知識圖譜的成品圖,主要是將金融相關的股票、人物、漲跌幅之類的基金資訊抽取出來。之前,我們要實現這種資訊抽取的話,一般是用 Bert + NER 來實現,要用到幾千個樣本,才能開發出一個效果相對不錯的模型。而到了大語言模型時代,我們有了 few-shot 和 zero-shot 的能力。
這裡穿插下 few-shot 和 zero-shot 的簡單介紹,前者是小樣本學習,後者是零樣本學習,模型藉助推理能力,能對未見過的類別進行分類。
因為大語言模型的這種特性,即便你不給模型輸入任何樣本,它都能將 n+ 做好,呈現一個不錯的效果。如果你再給模型一定的例子,進行學習:
is_example = {
'基金':[
{
'content': '4月21日,易方達基金公司明星基金經理張坤在管的4只基金產品悉數釋出了2023年年報'
'answers':{
'基金名稱':['易方達優質企業','易方達藍籌精選'],
'基金經理':['張坤'],
'基金公司':['易方達基金公司'],
'基金規模':['889.42億元'],
'重倉股':['五糧液','茅臺']
}
}
],
'股票':[
{
'content': '國聯證券04月23日釋出研報稱,給予東方財富(300059.SZ,最新價:17.03元)買入評級...'
'answers':{
'股票名稱':['東方財富'],
'董事長':['其實'],
'漲跌幅':['原文中未提及']
}
}
]
}
就能達到上述的效果。有了大語言模型之後,使用者對資料的需求會減少很多,對大多數人而言,你不需要那麼多預算去搞資料了,大語言模型就能實現資料的簡單抽取,滿足你的業務基本需求,再輔助一些規則,就可以。
而這些大語言模型的能力,主要是大模型的 ICL(In-Context Learning)能力以及 prompt 構建能力。ICL 就是給定一定樣本,輸入的樣本越多,輸出的效果越好,但是這個能力受限於模型的最大 token 長度,像是 ChatGLM-2,第一版本只有 2k 的輸入長度,像是上面的這個範例,如果你的輸入特別多的話,可能很快就達到了這個模型可輸入的 token 上限。當然,現在有不少方法來提升這個輸入長度的限制。比如,前段時間 Meta 更新的差值 ORp 方法,能將 2k 的 token 上限提升到 32k。在這種情況下,你的 prompt 工程可以非常完善,加入超多的限制條件和巨多的範例,達到更好的效果。
此外,進階的大模型使用的話,你可以採用 LoRA 之類的微調方式,來強化效果。如果你有幾百個,甚至上千個樣本,這時候輔助用個 LoRA 做微調,加一個類似 A100 的顯示卡機器,就可以進行相關的微調工作來強化效果。
利用大模型操作結構化資料

結構化資料其實有非常多種類,像圖資料也是一種結構化資料,表資料也是一種結構化資料,還有像是 MongoDB 之類的檔案型資料庫儲存的資料。Office 全家桶之前就在搞這塊的工作,有一篇相關論文講述瞭如何用大模型來操作 Sheet。
此外,還有一個相關工作是針對 SQL 的。前兩年,有一個研究方向特別火,叫:Text2SQL,就是如何用自然語言去生成 SQL。

大家吭哧吭哧做了好幾年,對於單表的查詢這塊做得非常好。但是有一個 SQL 困境,就是多表查詢如何實現?多表查詢,一方面是沒有相關資料,本身多表查詢的例子就非常少,限制了模型提升;另一方面,多表查詢本身就難以學習,學習條件會更加複雜。
而大語言模型出來之後,基於 GPT-4,或者是 PaLM 2 之類的模型,去訓練一個 SQL 版本的模型,效果會非常好。SQL-PaLM 運算元據庫的方式有兩種。一是在上下文學習(In-context learning), 也就是給模型一些例子,包括資料庫的 schema、自然語言的問題和對應的 SQL 語句,然後再問幾個新問題,要求模型輸出 SQL 語句。另一種方式是微調(fine-tuning),像是用 LoRA 或者是 P-tuning。

上圖就是一個用 Prompt 工程來實現 Text2SQL,事先先把表的 schema 告訴大模型,再提問,再拼成 SQL…按照這種方式給出多個範例之後,大模型生成的 SQL 語句效果會非常好。還有一種就是上面提到的微調,將 schema 和 question 組合成樣本對,讓大模型去學習,這時候得到的效果會更好。具體可以看下 SQL-PaLM 這篇論文,參考文末延伸閱讀;
此外,還有更進階的用法,和思為之前舉的例子有點相似,就是大模型和知識圖譜結合。

比如說,我想問「奧巴馬出生在哪個國家「,它就是構建知識圖譜 KQs,再進行一個召回,而召回有很多種方法,比如之前思為分享的 Llama Index 的向量召回,而向量召回最大的難點在於模型,像 OpenAI 提供的模型,效果會比較好,但是資料量大的時候,頻繁呼叫 OpenAI API 介面一方面涉及到隱私問題,另一方面涉及到預算費用問題;而自己要訓練一個模型,不僅難度大,由於資料量的原因,效果也不是很好。因此,如果你是藉助 Llama Index 的向量模型進行召回,可能需要輔助一些額外的關鍵詞模型,基於關鍵詞匹配來進行召回,像是子圖召回之類的。
對應到這個例子,系統需要識別出關鍵詞是 Obama 和 Country,關聯到美國,再進行召回。這樣處理之後,將相關的事實 Retrieved Facts 餵給大模型,讓它輸出最終的結果。在 Retrieved Facts 部分(上圖藍色部分),輸入可能相對會比較長,在圖中可能是一個三元組,這樣就會相對比較簡單。這裡還會涉及到上面說的 2k 輸入 token 提升問題,還是一樣的通過一些微調手段來實現。
大模型使用工具
下面就是本文的重頭戲——大模型的使用工具。什麼是大模型工具?你可以理解為它是把一些複雜操作整合到一起,讓大模型做一個驅動。
舉個例子,ChatGPT 剛出來的時候,會有人說「給我點一個披薩」,這當中就涉及到許多複雜的操作。

Data-Copilot 是浙大某個團隊做的大模型工具,主要是做意圖識別和資訊抽取。上圖右側是「輸入一句話,把相關的圖繪製出來」的效果展示,這裡就要提取一句話中的關鍵詞資訊,關鍵詞資訊識別之後去對應的資料庫中找對應的資料,找到資料之後進行資料處理,最後再生成一個圖。這裡並沒有用到圖資料庫,而是直接基於 2Sheet 介面來實現的。
這裡我們向這個模型提出一個需求「今年上證50指數的所有成分股的淨利潤增長率同比是多少」,這個模型會將其解析成對應的一個個步驟進行操作。上圖右側顯示了一共有 4 步:
- Step1 解析關鍵指標;
- Step2 提取相關資料;
- Step3 資料處理,整理成對應格式;
- Step4 繪製成圖;
而大模型是如何實現的呢?主要分為兩層,一方面你要設計一個介面呼叫,供 prompt 呼叫;另一方面準備好底層資料,它可能是在圖資料庫中,也可能在關係型資料庫中,給介面做承接之用。

這個例子更加複雜,是想讓大模型來預測中國未來(下四個季度)的 GDP 增長。這裡看到它分成了三部分(上圖橙色部分):
- Step1 拿到歷史資料;
- Step2 呼叫預測函數,它可能是線性函數,也可能是非線性函數,也有可能是深度學習模型;
- Step3 繪製成圖(上圖藍色部分);
一般來說,金融分析師做相關的金融資料分析的模型會相對統一,這種相對統一的模型我們用函數實現之後,就可以讓他的工作更加便捷:分析師只要說一句話,圖就畫好。這裡是 Data Copilot 的 GitHub 地址:https://github.com/zwq2018/Data-Copilot
大模型的最終形態
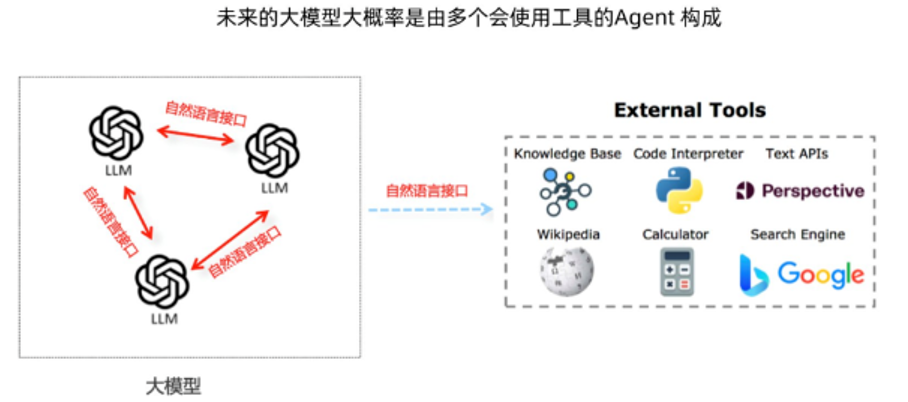
上面展示的形態,基本上人工痕跡還是很明顯的:prompt 要人為寫,資料介面也得人為寫。而我覺得它最終的形態,可能同 GPT4 的形態有點相似,像是前段時間出的 Code Interpreter,程式碼編譯器功能,你只用一句話,後面所有的功能都實現完了。大概實現過程就是上圖所示的,用 LLM 作為介面,把整個百科、計算器、搜尋、編譯器、知識圖譜等等接入進來,從而最終實現畫圖的功能。
而它的最終效果是怎麼樣的呢?下面是國際友人在推特上 po 出的一張圖:

就那麼簡單,你不需要額外地搞 API,就能實現一個功能。
LLM 你問我答
下面問題整理收集於本場直播,由 Wey 同社群使用者陳卓見一起回覆。
大語言模型和知識圖譜的結合案例
Q:目前大模型和知識圖譜的結合案例有嗎?有什麼好的分享嗎?
Wey:之前卓見老師在我們社群分享過一篇文章《利用 ChatGLM 構建知識圖譜》,包括我上面的分享,也算是一種實踐分享。當然我們後續會有更多的介紹。看看卓見有沒有其他補充。
陳卓見:我是相關的 LLM 從業人員,不過內部保密的緣故,這塊可能不能和大家分享很多。基本上就是我之前文章所講的那些,你如果有其他的問題交流,可以給文章留言,大家一起進一步交流下。
大模型入門教學
Q:現在如果要入門大語言模型的話,有什麼好的入門教材?
Wey:如果是利用大語言模型的話,可以看下 LangChain 作者和吳恩達老師出的教學,據說這個教學還挺不錯的。而我個人的話,會看一些論文,或者是追 LangChain 和 Llama Index 這兩個專案的最新實現,或者已經實現的東西,從中來學習下 LLM 能做什麼,以及它是如何實現這些功能的。而一些新的論文實現,這兩個專案也對其做了最小實現,可以很方便地快速使用起來,像是怎麼用 Embedding,它們支援哪些 Embedding 模型之類的事情。
陳卓見:思為分享的可能是偏應用層的,而對我們這些 LLM 從業者而言更多的可能是如何訓練大模型。比如說,我們想實現某個功能,我們應該如何去構造資料,選擇大模型。像是我們團隊,如果是來了一個實習生,會看他數學能力如何。假如數學不好的話,會先考慮讓他先多學點數學;如果數學水平不錯,現在同大模型相關的綜述文章也挺多的,會讓他去看看綜述文章,無論中文還是英文,都有不少相關的資料可以學習。像 transformer 層,大模型訓練的細節,分散式怎麼做,工程化如何實現,都是要去了解的。當然,這裡面肯定是有側重點的,你如果是想了解工程的知識,你可以去多看看工程知識;想了解底層原理,就多看看理論,因人而異。
這裡給一些相關的資料,大家有興趣可以學習下:
- A Survey of Large Language Models:https://arxiv.org/abs/2303.18223,主要了解下基本概念;
- 中文版的綜述《大語言模型綜述》:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey__Chinese_V1.pdf
如何基於 LLM 做問答
Q:NebulaGraph 論壇現在累計的問答資料和點贊標記,是不是很好的樣本資料,可以用來搞個不錯的專家客服?
Wey:在之前卓見老師的分享中,也提到了如果有高質量的問答 Pair,且有一定的資料量,是可以考慮用微調的方式,訓練一個問答專家。當然,最直接、最簡單的方式可能是上面分享說的 RAG 方式,用向量資料庫 embedding 下。
部署大模型的路徑和實現設定
Q:想問部署 65b 大模型最低成本的硬體設定和實現路徑?
陳卓見:先看你有沒有 GPU 的機器,當然 CPU 記憶體夠大也是可以的,有一臺 256B 記憶體的機器,應該 65b 也是能推理的。因為大模型分不同精度,一般我們訓練用到的精度是 fp16。而 fp16 的話,對於 65b 的模型,它大概視訊記憶體佔用大概是 120GB 到 130GB 之間。如果你用的記憶體訓練的話,記憶體得超過這個量級,一般是 256GB,就能推理的。但是不大推薦用 CPU,因為它的速度可能只有同等規模 GPU 的 1/10,甚至 1/20、1/50 都有可能的,這具體得看你的環境。
如果你用 GPU,它是有幾種選擇,如果你用 fp16 的精度想去做推理的話,那麼你可能需要 2 張 80GB 視訊記憶體的機器,比如說 A100、A800 這樣機器才能行。但最低實現的話,你可以選擇 INT4 精度,這時候需要一個 40GB 左右的視訊記憶體,比如買個 A6000,48GB 視訊記憶體,它應該也是能推理的。但這個推理其實是有限制的,因為推理是不斷的 next token prediction,是要一直生成 token 的,這就會佔用你的視訊記憶體。如果你讓它寫一篇長文的話,這時候 48GB 視訊記憶體應該是不夠用的,視訊記憶體會爆。所以,你準備 2 個 48GB 的視訊記憶體,在 INT4 下可以方便地進行推理之餘,還能搞搞模型並行,QPS 也會有所體現。但是單 48GB 視訊記憶體的話,記憶體可能會爆。
最近比較流行的有個 LLaMA CPP 專案,就支援 INT4 量化,而且未來還計劃支援 INT2 量化。但 INT2 量化這個效果就不敢保證了,因為 INT4 至少有不少專案,像是 LLaMA、ChatGLM 都做過實驗,測試下來精度損失不會那麼大,但是 INT2 還沒有實踐資料出來,不知道到底精度損失會有多少?
小結下,我建議你最好是準備一個 A800 的機器,或者是兩個 A6000 這樣的機器,或者四個 A30,都能做 65b 的推理。這個設定會比較穩妥一點。
下個問題。
Wey:這裡我想追問下卓見一個問題。我有一個窮人版的 24GB 視訊記憶體,暫時還沒試過 Fine-Tuning,但是我現在做正常精度的 6b 推理是 OK 的。如果是 INT4 的話,據說 6GB 視訊記憶體就可以推理?
陳卓見:這裡解釋下視訊記憶體和模型引數量的關係,如果你是 6b 模型的話,一般視訊記憶體是 12GB,就能做正常的 fp16 推理,而 INT4 的話,直接視訊記憶體除以 3,大概 4 GB 就可以做 INT4 的推理。如果你現在是 24GB 的視訊記憶體,其實可以試試 13b 的模型。
非結構化資料如何儲存到圖
Q:非結構化的資料,比如就一本書,如何先儲存到 graph 裡?
Wey: