關於XXLJOB叢集模式下排程失敗的問題
xxljob在叢集模式下排程高頻任務時,有時會出現排程失敗的問題,具體報錯如下:
java.io.EOFException: HttpConnectionOverHTTP@6be8bf0c(l:/10.48.2.64:38538 <-> r:/10.48.1.125:18989,closed=false)[HttpChannelOverHTTP@296ee40c(exchange=HttpExchange@4d219770 req=TERMINATED/null@null res=PENDING/null@null)[send=HttpSenderOverHTTP@3c6b8ccf(req=QUEUED,snd=COMPLETED,failure=null)[HttpGenerator{s=START}],recv=HttpReceiverOverHTTP@12554491(rsp=IDLE,failure=null)[HttpParser{s=CLOSED,0 of -1}]]] at org.eclipse.jetty.client.http.HttpReceiverOverHTTP.earlyEOF(HttpReceiverOverHTTP.java:277) at org.eclipse.jetty.http.HttpParser.parseNext(HttpParser.java:1305) at org.eclipse.jetty.client.http.HttpReceiverOverHTTP.shutdown(HttpReceiverOverHTTP.java:182) at org.eclipse.jetty.client.http.HttpReceiverOverHTTP.process(HttpReceiverOverHTTP.java:129) at org.eclipse.jetty.client.http.HttpReceiverOverHTTP.receive(HttpReceiverOverHTTP.java:69) at org.eclipse.jetty.client.http.HttpChannelOverHTTP.receive(HttpChannelOverHTTP.java:90) at org.eclipse.jetty.client.http.HttpConnectionOverHTTP.onFillable(HttpConnectionOverHTTP.java:174) at org.eclipse.jetty.io.AbstractConnection$2.run(AbstractConnection.java:544) at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:635) at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:555) at java.lang.Thread.run(Thread.java:748)
網上關於這個問題的原因和解決比較少,因此記錄下來問題的排查過程,供大家參考,如果有心急的同學可以直接跳到結尾檢視問題原因和解決方案
後續說明中的觸發側是指xxljob的伺服器端,執行側是指任務執行的應用端
排查過程中需要對xxljob的執行原理有大概的瞭解,以及tcp的握手和揮手操作有一定的瞭解,最後還需要知道一些tcpdump命令結果的一些知識,如果有不明白的可以先查一下相關資料
首先,我看到這個問題之後先去網上搜一下有沒有問題的原因說明和解決方案,但是查詢之後發現雖然很多人都遇到了,但是沒有說明具體的問題原因
所以,只好檢視一下xxl的原始碼,發現觸發操作是完全隔離的,叢集下不同機器沒有任何相互影響。而且非叢集模式下沒有這個問題,說明可以排除網路因素。
同時,我也將xxljob中發起觸發請求的程式碼複製出來,然後進行高頻率呼叫,但是沒有復現出問題,說明問題的出現可能跟高頻執行沒有太大關係
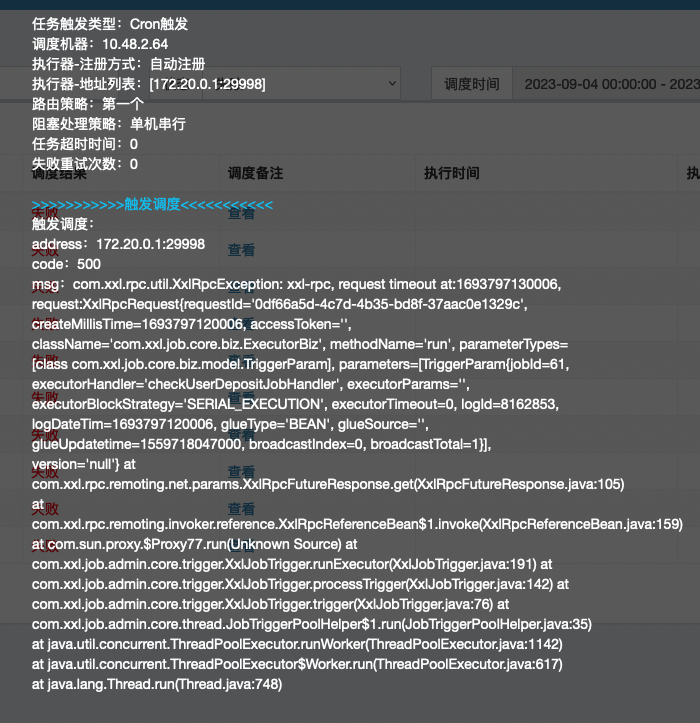
肯定是不同機器排程過程中導致的,仔細觀察下圖中的排程記錄,可以看到出問題的時間點總是在切換排程機器的第一次請求時發生。但是排程機器觸發操作是完全獨立的,所以到這裡就不明白為什麼會出現這種情況
於是,為了進一步排查問題,只能去嘗試抓一下網路請求,看網路請求有什麼不同

下面這個圖是通過tcpdump命令抓取的任務觸發機器和任務執行機器的網路通訊過程
看到這個我才發現,雖然xxljob是使用http進行通訊的,但是並不是走的短連線,而是長連線。
所以第一時間我認為是可能不同機器都已經建立了長連線但是由於排程觸發一直在其中一臺機器上,所以另一臺的連線可能已經斷開了,當觸發切換到另一臺機器時,由於連線已經斷開,但是應用層尚未感知到,所以造成的問題
另外,從這個網路互動紀錄檔中可以看到複用長連線的有效時間是30s(這個其實是後面發現問題的關鍵)
根據上面分析的結果,思考問題的其他表現時,發現上面的推斷並不能解釋所有的現象,比如下圖的表現
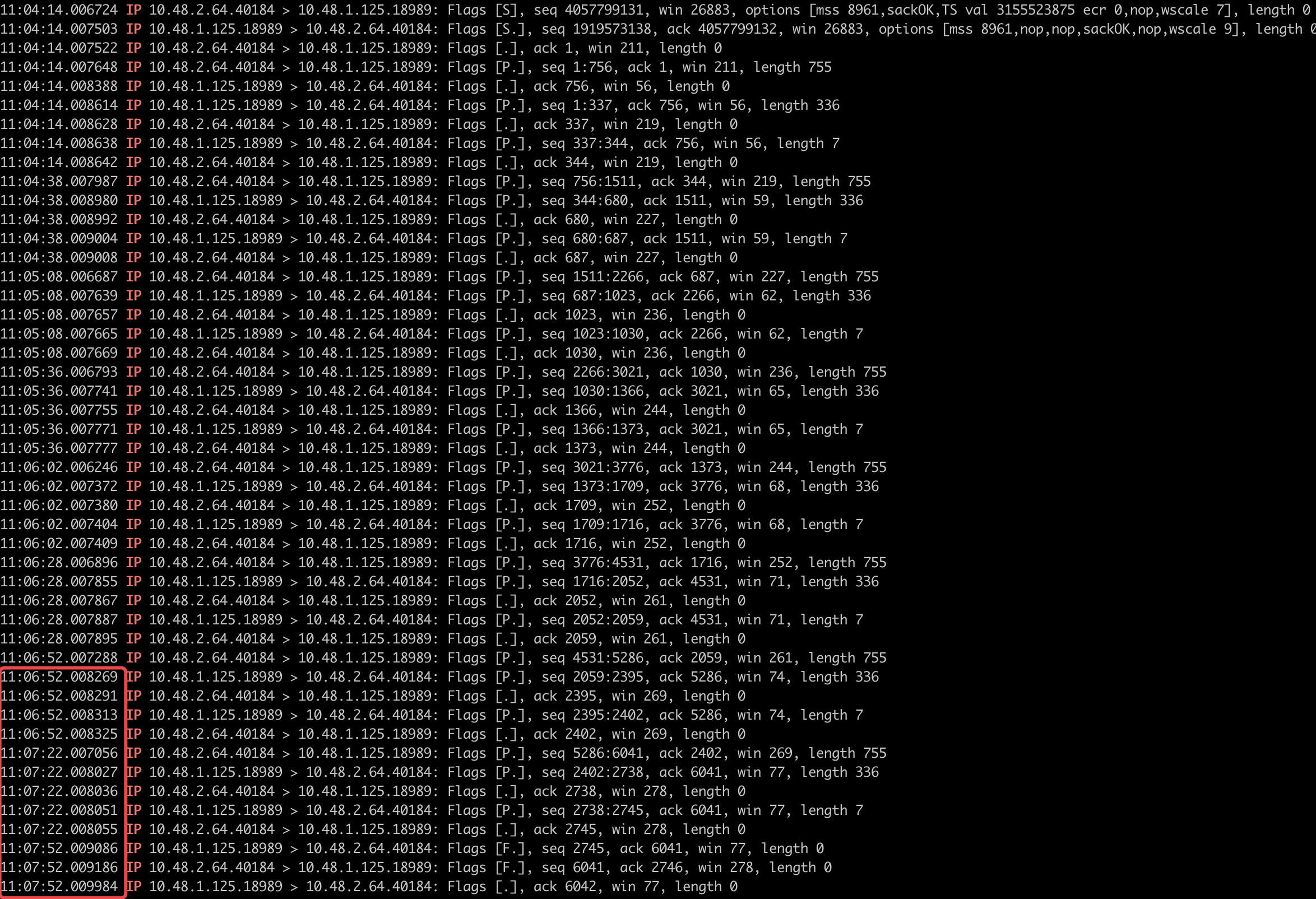
如果長連線已經中斷,那麼觸發側的請求無法傳送到執行側,執行側的資訊也無法反饋到觸發側才對。但是上面這個圖中可以明顯看到觸發側已經獲取到了執行側的報錯資訊,說明,執行側報錯之後已經通過原有連線將報錯資訊返回到了觸發側
這說明問題發生時,連線並沒有中斷,上面的分析是錯誤的。
之後又抓取到了問題發生時的網路互動紀錄檔,其中10.48.2.64.38538是xxljob伺服器端,也就是觸發側,10.48.1.125.18989是任務執行應用,也就是執行側
16:26:46.008470 IP 10.48.2.64.38538 > 10.48.1.125.18989: Flags [P.], seq 756:1511, ack 344, win 219, length 755 16:26:46.009007 IP 10.48.1.125.18989 > 10.48.2.64.38538: Flags [F.], seq 344, ack 756, win 56, length 0 16:26:46.009192 IP 10.48.2.64.38538 > 10.48.1.125.18989: Flags [F.], seq 1511, ack 345, win 219, length 0 16:26:46.009916 IP 10.48.1.125.18989 > 10.48.2.64.38538: Flags [.], ack 1512, win 59, length 0
從上面這個紀錄檔中可以看到
第一條是觸發側去傳送了一次請求到執行側,傳送的包的seq是756到1511
第二條是執行側反饋的返回結果,執行側直接傳送了關閉連線的請求,並且ack只確認到756
第三條是觸發側確認了關閉請求,第四條執行側確認了第三條的請求
所以2,3,4條是完整的走完了tcp的三次揮手操作,說明連線是執行側主動關閉的
然後我們重新觀察了一下正常的關閉連線的請求,發現每次都是由執行側去關閉的連線,並且關閉的時間就是最後一次的請求的30s之後(空閒超時)
同時我們也從原始碼中可以看到超時時間預設就是30s
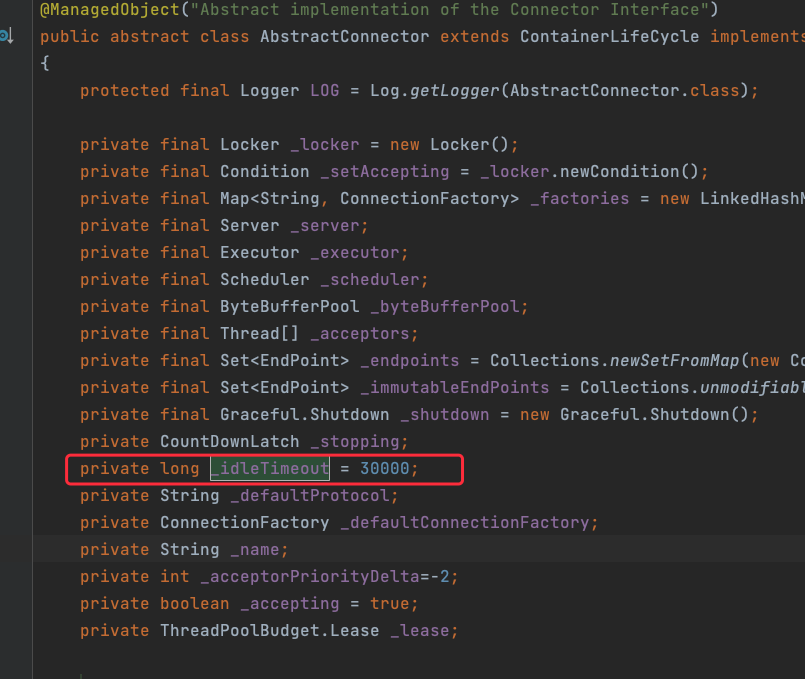
明白了問題所在,那麼修復就比較簡單了,我是採用修改空閒超時時間為10分鐘,這樣儘量避免排程切換和超時斷開正好碰到一起
這種解決方式理論上仍然有報錯的可能,但是概率大大降低了,同時也不需要修改xxljob原始碼,改動也比較小
如果有更好的解決方式歡迎評論區說明
測試類和修復類我都已經上傳到csdn了,由於我比較貧窮,需要一些csdn的積分下載別的資源,所以希望各位支援一些積分給我
下載連結:https://download.csdn.net/download/wsss_fan/88299099
如果確實沒有積分,可以聯絡我,我單獨發給你