CDC一鍵入湖:當 Apache Hudi DeltaStreamer 遇見 Serverless Spark
Apache Hudi的DeltaStreamer是一種以近實時方式攝取資料並寫入Hudi表的工具類,它簡化了流式資料入湖並儲存為Hudi表的操作,自 0.10.0 版開始,Hudi又在DeltaStreamer的基礎上增加了基於Debezium的CDC資料處理能力,這使得其可以直接將Debezium採集的CDC資料落地成Hudi表,這一功能極大地簡化了從源頭業務資料庫到Hudi資料湖的資料整合工作。
另一方面,得益於開箱即用和零運維的極致體驗,越來越多的雲上使用者開始擁抱Serverless產品。Amazon雲平臺上的EMR是一個整合了多款主流巨量資料工具的計算平臺,自6.6.0版本開始,EMR推出了 Serverless版本,開始提供無伺服器的Spark執行環境,使用者無需維護Hadoop/Spark叢集,即可輕鬆提交Spark作業。
一個是「全設定」的Hudi工具類, 一個是「開箱即用」的Spark執行環境,兩者結合在一起,無需編寫CDC處理程式碼,無需構建Spark叢集,僅通過一條命令,就可以輕鬆實現CDC資料入湖,這是一個非常吸引人的技術方案,本文我們就詳細介紹一下這一方案的整體架構和實現細節。
1. 整體架構
Apache Huid在 0.10.0版引入的DeltaStreamer CDC是一整條CDC資料處理鏈路中的末端環節,為了能讓大家清楚地理解DeltaStreamer在其中所處的位置和發揮的作用,我們有必要看一下完整架構:
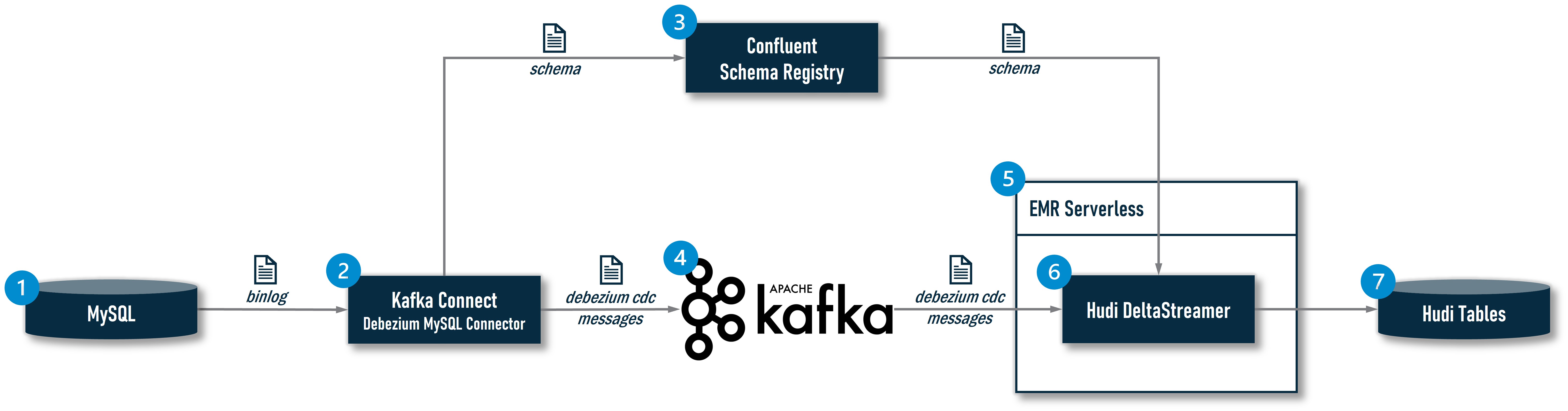
①:MySQL是一個業務資料庫,是CDC資料的源頭;
②:系統使用一個CDC攝取工具實時讀取MySQL的binlog,業界主流的CDC攝取工具有:Debezium,Maxwell,FlinkCDC等,在該架構中,選型的是安裝了Debezium MySQL Connector的Kafka Connect;
③:現在越來越多的CDC資料攝取方案開始引入Schema Registry用於更好的控制上游業務系統的Schema變更,實現更可控的Schema Evolution。在開源社群,較為主流的產品是Confluent Schema Registry,且目前Hudi的DeltaStreamer也僅支援Confluent這一種Schema Registry,所以該架構選型的也是它。引入Schema Registry之後,Kafka Connect在捕獲一條記錄時,會先在其原生的Schema Cache中查詢是否已經存在對應的Schema,如果有,則直接從本地Cache中獲得Schema ID,如果沒有,則會將其提交給Schema Registry,由Schema Registry完成該Schema的註冊並將生成的Schema ID返回給Kafka Connect,Kafka Connect會基於Schema ID對原始的CDC資料進行封裝(序列化):一是將Schema ID新增到訊息中,二是如果使用Avro格式傳遞訊息,Kafka Connect會去除Avro訊息中的Schema部分,只保留Raw Data,因為Schema資訊已快取在Producer和Consumer本地或可通過Schema Registry一次性獲得,沒有必要伴隨Raw Data傳輸,這樣可以大大減小Avro訊息的體積,提升傳輸效率。這些工作是通過Confluent提供的Avro Converter(io.confluent.connect.avro.AvroConverter)完成的;
④:Kafka Connect將封裝好的Avro訊息投遞給Kafka
⑤:EMR Serverless為DeltaStreamer提供Serverless的Spark執行環境;
⑥:Hudi的DeltaStreamer作為一個Spark作業執行在EMR Serverless環境中,它從Kafka讀取到Avro訊息後,會使用Confluent提供的Avro反序列化器(io.confluent.kafka.serializers.KafkaAvroDeserializer)解析Avro訊息,得到Schema ID和Raw Data,反序列化器同樣會先在原生的Schema Cache中根據ID查詢對應的Schema,如果找到就根據這個Schema將Raw Data反序列化,如果沒有找到,就向Schema Registry請求獲取該ID對應的Schema,然後再進行反序列化;
⑦:DeltaStreamer將解析出來的資料寫入存放在S3上的Hudi表,如果資料表不存在,會自動建立表並同步到Hive MetaStore中
2. 環境準備
限於篇幅,本文不會介紹①、②、③、④環節的構建工作,讀者可以參考以下檔案自行構建一套完整的測試環境:
①MySQL:如果僅以測試為目的,建議使用Debezium提供的官方Docker映象,構建操作可參考其官方檔案(下文將給出的操作範例所處理的CDC資料就是自於該MySQL映象中的inventory資料庫);
②Kafka Connect:如果僅以測試為目的,建議使用Confluent提供的官方Docker映象,構建操作可參考其官方檔案,或者使用AWS上託管的Kafka Connct:Amazon MSK Connect。需要提醒的是:Kafka Connect上必須安裝Debezium MySQL Connector和Confluent Avro Converter兩個外掛,因此需要在官方映象的基礎上手動新增這兩個外掛;
③Confluent Schema Registry:如果僅以測試為目的,建議使用Confluent提供的官方Docker映象,構建操作可參考其官方檔案;
④Kafka:如果僅以測試為目的,建議使用Confluent提供的官方Docker映象,構建操作可參考其官方檔案,或者使用AWS上託管的Kafka:Amazon MSK
完成上述工作後,我們會獲得「Confluent Schema Registry」和「Kafka Bootstrap Servers」兩項依賴服務的地址,它們是啟動DeltaStreamer CDC作業的必要條件,後續會以引數形式傳遞給DeltaStreamer作業。
3. 設定全域性變數
環境準備工作就緒後,就可以著手第⑤、⑥、⑦部分的工作了。本文所有操作全部通過命令完成,以shell指令碼形式提供給讀者使用,指令碼上會標註實操步驟的序號,如果是二選一操作,會使用字母a/b加以標識,部分操作還有範例供讀者參考。為了使指令碼具有良好的可移植性,我們將與環境相關的依賴項和需要使用者自定義的設定項抽離出來,以全域性變數的形式集中設定,如果您在自己的環境中執行本文操作,只需修改下面的全域性變數即可,不必修改具體命令:
| 變數 | 說明 | 設定時機 |
|---|---|---|
| APP_NAME | 由使用者為本應用設定的名稱 | 提前設定 |
| APP_S3_HOME | 由使用者為本應用設定的S3專屬桶 | 提前設定 |
| APP_LOCAL_HOME | 由使用者為本應用設定的本地工作目錄 | 提前設定 |
| SCHEMA_REGISTRY_URL | 使用者環境中的Confluent Schema Registry地址 | 提前設定 |
| KAFKA_BOOTSTRAP_SERVERS | 使用者環境中的Kafka Bootstrap Servers地址 | 提前設定 |
| EMR_SERVERLESS_APP_SUBNET_ID | 將要建立的EMR Serverless Application所屬子網ID | 提前設定 |
| EMR_SERVERLESS_APP_SECURITY_GROUP_ID | 將要建立的EMR Serverless Application所屬安全組ID | 提前設定 |
| EMR_SERVERLESS_APP_ID | 將要建立的EMR Serverless Application的ID | 過程中產生 |
| EMR_SERVERLESS_EXECUTION_ROLE_ARN | 將要建立的EMR Serverless Execution Role的ARN | 過程中產生 |
| EMR_SERVERLESS_JOB_RUN_ID | 提交EMR Serverless作業後返回的作業ID | 過程中產生 |
接下來,我們將進入實操階段,需要您擁有一個安裝了AWS CLI並設定了使用者憑證的Linux環境(建議使用Amazon Linux2),通過SSH登入後,先使用命令sudo yum -y install jq安裝操作json檔案的命令列工具:jq(後續指令碼會使用到它),然後將以上全域性變數悉數匯出(請根據您的AWS賬號和本地環境替換命令列中的相應值):
# 實操步驟(1)
export APP_NAME='change-to-your-app-name'
export APP_S3_HOME='change-to-your-app-s3-home'
export APP_LOCAL_HOME='change-to-your-app-local-home'
export SCHEMA_REGISTRY_URL='change-to-your-schema-registry-url'
export KAFKA_BOOTSTRAP_SERVERS='change-to-your-kafka-bootstrap-servers'
export EMR_SERVERLESS_APP_SUBNET_ID='change-to-your-subnet-id'
export EMR_SERVERLESS_APP_SECURITY_GROUP_ID='change-to-your-security-group-id'
以下是一份範例:
# 範例(非實操步驟)
export APP_NAME='apache-hudi-delta-streamer'
export APP_S3_HOME='s3://apache-hudi-delta-streamer'
export APP_LOCAL_HOME='/home/ec2-user/apache-hudi-delta-streamer'
export SCHEMA_REGISTRY_URL='http://localhost:8081'
export KAFKA_BOOTSTRAP_SERVERS='localhost:9092'
export EMR_SERVERLESS_APP_SUBNET_ID='subnet-0a11afe6dbb4df759'
export EMR_SERVERLESS_APP_SECURITY_GROUP_ID='sg-071f18562f41b5804'
至於 EMR_SERVERLESS_APP_ID、EMR_SERVERLESS_EXECUTION_ROLE_ARN、EMR_SERVERLESS_JOB_RUN_ID 三個變數將在後續的操作過程中產生並匯出。
4. 建立專屬工作目錄和儲存桶
作為一項最佳實踐,我們先為應用程式(Job)建立一個專屬的本地工作目錄(即APP_LOCAL_HOME設定的路徑)和一個S3儲存桶(即APP_S3_HOME設定的桶),應用程式的指令碼、組態檔、依賴包、紀錄檔以及產生的資料都統一存放在專屬目錄和儲存桶中,這樣會便於維護:
# 實操步驟(2)
mkdir -p $APP_LOCAL_HOME
aws s3 mb $APP_S3_HOME
5. 建立 EMR Serverless Execution Role
執行EMR Serverless作業需要設定一個IAM Role,這個Role將賦予EMR Serverless作業存取AWS相關資源的許可權,我們的DeltaStreamer CDC作業應至少需要分配:
- 對S3專屬桶的讀寫許可權
- 對Glue Data Catalog的讀寫許可權
- 對Glue Schema Registry的讀寫許可權
您可以根據EMR Serverless的官方檔案手動建立這個Role,然後將其ARN作為變數匯出(請根據您的AWS賬號環境替換命令列中的相應值):
# 實操步驟(3/a)
export EMR_SERVERLESS_EXECUTION_ROLE_ARN='change-to-your-emr-serverless-execution-role-arn'
以下是一份範例:
# 範例(非實操步驟)
export EMR_SERVERLESS_EXECUTION_ROLE_ARN='arn:aws:iam::123456789000:role/EMR_SERVERLESS_ADMIN'
考慮到手動建立這個Role較為煩瑣,本文提供如下一段指令碼,可以在您的AWS賬號中建立一個擁有管理員許可權的Role:EMR_SERVERLESS_ADMIN,從而幫助您快速完成本節工作(注意:由於該Role具有最高許可權,應謹慎使用,完成快速驗證後,還是應該在生產環境中設定嚴格限定許可權的專有Execution Role):
# 實操步驟(3/b)
EMR_SERVERLESS_EXECUTION_ROLE_NAME='EMR_SERVERLESS_ADMIN'
cat << EOF > $APP_LOCAL_HOME/assume-role-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EMRServerlessTrustPolicy",
"Effect": "Allow",
"Principal": {
"Service": "emr-serverless.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
jq . $APP_LOCAL_HOME/assume-role-policy.json
export EMR_SERVERLESS_EXECUTION_ROLE_ARN=$(aws iam create-role \
--no-paginate --no-cli-pager --output text \
--role-name "$EMR_SERVERLESS_EXECUTION_ROLE_NAME" \
--assume-role-policy-document file://$APP_LOCAL_HOME/assume-role-policy.json \
--query Role.Arn)
aws iam attach-role-policy \
--policy-arn "arn:aws:iam::aws:policy/AdministratorAccess" \
--role-name "$EMR_SERVERLESS_EXECUTION_ROLE_NAME"
6. 建立 EMR Serverless Application
向EMR Serverless提交作業前,需要先建立一個EMR Serverless Application,這是EMR Serverless中的一個概念,可以理解為一個虛擬的EMR叢集。在建立Application時,需要指定EMR的版本,網路設定,叢集規模,預熱節點等資訊。通常,我們僅需如下一條命令就可以完成建立工作:
# 範例(非實操步驟)
aws emr-serverless create-application \
--name "$APP_NAME" \
--type "SPARK" \
--release-label "emr-6.11.0"
但是,這樣建立出的Application是沒有網路設定的,由於我們的DeltaStreamer CDC作業需要存取位於特定VPC中的Confluent Schema Registry和Kafka Bootstrap Servers,所以必須顯式地為Application設定子網和安全組,以確保DeltaStreamer可以連通這兩項服務。因此,我們需要使用以下命令建立一個帶有特定網路設定的Application:
# 實操步驟(4)
cat << EOF > $APP_LOCAL_HOME/create-application.json
{
"name":"$APP_NAME",
"releaseLabel":"emr-6.11.0",
"type":"SPARK",
"networkConfiguration":{
"subnetIds":[
"$EMR_SERVERLESS_APP_SUBNET_ID"
],
"securityGroupIds":[
"$EMR_SERVERLESS_APP_SECURITY_GROUP_ID"
]
}
}
EOF
jq . $APP_LOCAL_HOME/create-application.json
export EMR_SERVERLESS_APP_ID=$(aws emr-serverless create-application \
--no-paginate --no-cli-pager --output text \
--release-label "emr-6.11.0" --type "SPARK" \
--cli-input-json file://$APP_LOCAL_HOME/create-application.json \
--query "applicationId")
7. 提交 Apache Hudi DeltaStreamer CDC 作業
建立好Application就可以提交作業了,Apache Hudi DeltaStreamer CDC是一個較為複雜的作業,設定項非常多,這一點從Hudi官方部落格給出的範例中可見一斑,我們要做的是:將使用spark-submit命令提交的作業「翻譯」成EMR Serverless的作業。
7.1 準備作業描述檔案
使用命令列提交EMR Serverless作業需要提供一個json格式的作業描述檔案,通常在spark-submit命令列中設定的引數都會由這個檔案來描述。由於DeltaStreamer作業的設定項非常多,限於篇幅,我們無法一一做出解釋,您可以將下面的作業描述檔案和Hudi官方部落格提供的原生Spark作業做一下對比,然後就能相對容易地理解作業描述檔案的作用了。
需要注意的是,在執行下面的指令碼時,請根據您的AWS賬號和本地環境替換指令碼中所有的<your-xxx>部分,這些被替換的部分取決於您本地環境中的源頭資料庫、資料表,Kakfa Topic以及Schema Registry等資訊,每換一張表都需要調整相應的值,所以沒有被抽離到全域性變數中。
此外,該作業其實並不依賴任何第三方Jar包,其使用的Confluent Avro Converter已經整合到了hudi-utilities-bundle.jar中,這裡我們特意在設定中宣告--conf spark.jars=$(...)(參考範例命令)是為了演示「如何載入三方類庫」,供有需要的讀者參考。
# 實操步驟(5)
cat << EOF > $APP_LOCAL_HOME/start-job-run.json
{
"name":"apache-hudi-delta-streamer",
"applicationId":"$EMR_SERVERLESS_APP_ID",
"executionRoleArn":"$EMR_SERVERLESS_EXECUTION_ROLE_ARN",
"jobDriver":{
"sparkSubmit":{
"entryPoint":"/usr/lib/hudi/hudi-utilities-bundle.jar",
"entryPointArguments":[
"--continuous",
"--enable-sync",
"--table-type", "COPY_ON_WRITE",
"--op", "UPSERT",
"--target-base-path", "<your-table-s3-path>",
"--target-table", "orders",
"--min-sync-interval-seconds", "60",
"--source-class", "org.apache.hudi.utilities.sources.debezium.MysqlDebeziumSource",
"--source-ordering-field", "_event_origin_ts_ms",
"--payload-class", "org.apache.hudi.common.model.debezium.MySqlDebeziumAvroPayload",
"--hoodie-conf", "bootstrap.servers=$KAFKA_BOOTSTRAP_SERVERS",
"--hoodie-conf", "schema.registry.url=$SCHEMA_REGISTRY_URL",
"--hoodie-conf", "hoodie.deltastreamer.schemaprovider.registry.url=${SCHEMA_REGISTRY_URL}/subjects/<your-registry-name>.<your-src-database>.<your-src-table>-value/versions/latest",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.topic=<your-kafka-topic-of-your-table-cdc-message>",
"--hoodie-conf", "auto.offset.reset=earliest",
"--hoodie-conf", "hoodie.datasource.write.recordkey.field=<your-table-recordkey-field>",
"--hoodie-conf", "hoodie.datasource.write.partitionpath.field=<your-table-partitionpath-field>",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor",
"--hoodie-conf", "hoodie.datasource.write.hive_style_partitioning=true",
"--hoodie-conf", "hoodie.datasource.hive_sync.database=<your-sync-database>",
"--hoodie-conf", "hoodie.datasource.hive_sync.table==<your-sync-table>",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_fields=<your-table-partition-fields>"
],
"sparkSubmitParameters":"--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.jars=<your-app-dependent-jars>"
}
},
"configurationOverrides":{
"monitoringConfiguration":{
"s3MonitoringConfiguration":{
"logUri":"<your-s3-location-for-emr-logs>"
}
}
}
}
EOF
jq . $APP_LOCAL_HOME/start-job-run.json
以下是一份範例:
# 範例(非實操步驟)
cat << EOF > $APP_LOCAL_HOME/start-job-run.json
{
"name":"apache-hudi-delta-streamer",
"applicationId":"$EMR_SERVERLESS_APP_ID",
"executionRoleArn":"$EMR_SERVERLESS_EXECUTION_ROLE_ARN",
"jobDriver":{
"sparkSubmit":{
"entryPoint":"/usr/lib/hudi/hudi-utilities-bundle.jar",
"entryPointArguments":[
"--continuous",
"--enable-sync",
"--table-type", "COPY_ON_WRITE",
"--op", "UPSERT",
"--target-base-path", "$APP_S3_HOME/data/mysql-server-3/inventory/orders",
"--target-table", "orders",
"--min-sync-interval-seconds", "60",
"--source-class", "org.apache.hudi.utilities.sources.debezium.MysqlDebeziumSource",
"--source-ordering-field", "_event_origin_ts_ms",
"--payload-class", "org.apache.hudi.common.model.debezium.MySqlDebeziumAvroPayload",
"--hoodie-conf", "bootstrap.servers=$KAFKA_BOOTSTRAP_SERVERS",
"--hoodie-conf", "schema.registry.url=$SCHEMA_REGISTRY_URL",
"--hoodie-conf", "hoodie.deltastreamer.schemaprovider.registry.url=${SCHEMA_REGISTRY_URL}/subjects/osci.mysql-server-3.inventory.orders-value/versions/latest",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.topic=osci.mysql-server-3.inventory.orders",
"--hoodie-conf", "auto.offset.reset=earliest",
"--hoodie-conf", "hoodie.datasource.write.recordkey.field=order_number",
"--hoodie-conf", "hoodie.datasource.write.partitionpath.field=order_date",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor",
"--hoodie-conf", "hoodie.datasource.write.hive_style_partitioning=true",
"--hoodie-conf", "hoodie.datasource.hive_sync.database=inventory",
"--hoodie-conf", "hoodie.datasource.hive_sync.table=orders",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_fields=order_date"
],
"sparkSubmitParameters":"--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.jars=$(aws s3 ls $APP_S3_HOME/jars/ | grep -o '\S*\.jar$'| awk '{print "'"$APP_S3_HOME/jars/"'"$1","}' | tr -d '\n' | sed 's/,$//')"
}
},
"configurationOverrides":{
"monitoringConfiguration":{
"s3MonitoringConfiguration":{
"logUri":"$APP_S3_HOME/logs"
}
}
}
}
EOF
jq . $APP_LOCAL_HOME/start-job-run.json
7.2 提交作業
準備好作業描述檔案後,就可以正式提交作業了,命令如下:
# 實操步驟(6)
export EMR_SERVERLESS_JOB_RUN_ID=$(aws emr-serverless start-job-run \
--no-paginate --no-cli-pager --output text \
--name apache-hudi-delta-streamer \
--application-id $EMR_SERVERLESS_APP_ID \
--execution-role-arn $EMR_SERVERLESS_EXECUTION_ROLE_ARN \
--execution-timeout-minutes 0 \
--cli-input-json file://$APP_LOCAL_HOME/start-job-run.json \
--query jobRunId)
7.3 監控作業
作業提交後,可以在控制檯檢視作業執行狀態。如果想在命令列視窗持續監控作業,可以使用如下指令碼:
# 實操步驟(7)
now=$(date +%s)sec
while true; do
jobStatus=$(aws emr-serverless get-job-run \
--no-paginate --no-cli-pager --output text \
--application-id $EMR_SERVERLESS_APP_ID \
--job-run-id $EMR_SERVERLESS_JOB_RUN_ID \
--query jobRun.state)
if [ "$jobStatus" = "PENDING" ] || [ "$jobStatus" = "SCHEDULED" ] || [ "$jobStatus" = "RUNNING" ]; then
for i in {0..5}; do
echo -ne "\E[33;5m>>> The job [ $EMR_SERVERLESS_JOB_RUN_ID ] state is [ $jobStatus ], duration [ $(date -u --date now-$now +%H:%M:%S) ] ....\r\E[0m"
sleep 1
done
else
echo -ne "The job [ $EMR_SERVERLESS_JOB_RUN_ID ] is [ $jobStatus ]\n\n"
break
fi
done
7.4 錯誤檢索
作業開始執行後,Spark Driver和Executor會持續生成紀錄檔,這些紀錄檔存放在設定的$APP_S3_HOME/logs路徑下,如果作業失敗,可以使用下面的指令碼快速檢索到錯誤資訊:
# 實操步驟(8)
JOB_LOG_HOME=$APP_LOCAL_HOME/log/$EMR_SERVERLESS_JOB_RUN_ID
rm -rf $JOB_LOG_HOME && mkdir -p $JOB_LOG_HOME
aws s3 cp --recursive $APP_S3_HOME/logs/applications/$EMR_SERVERLESS_APP_ID/jobs/$EMR_SERVERLESS_JOB_RUN_ID/ $JOB_LOG_HOME >& /dev/null
gzip -d -r -f $JOB_LOG_HOME >& /dev/null
grep --color=always -r -i -E 'error|failed|exception' $JOB_LOG_HOME
7.5 停止作業
DeltaStreamer是一個持續執行的作業,如果需要停止作業,可以使用如下命令:
# 實操步驟(9)
aws emr-serverless cancel-job-run \
--no-paginate --no-cli-pager\
--application-id $EMR_SERVERLESS_APP_ID \
--job-run-id $EMR_SERVERLESS_JOB_RUN_ID
8. 結果驗證
作業啟動後會自動建立一個資料表,並在指定的S3位置上寫入資料,使用如下命令可以檢視自動建立的資料表和落地的資料檔案:
# 實操步驟(10)
aws s3 ls --recursive <your-table-s3-path>
aws glue get-table --no-paginate --no-cli-pager \
--database-name <your-sync-database> --name <your-sync-table>
# 範例(非實操步驟)
aws s3 ls --recursive $APP_S3_HOME/data/mysql-server-3/inventory/orders/
aws glue get-table --no-paginate --no-cli-pager \
--database-name inventory --name orders
9. 評估與展望
本文,我們詳細介紹瞭如何在EMR Serverless上執行Apapche Hudi DeltaStreamer將CDC資料接入到Hudi表中,這是一個主打「零編碼」,「零運維」的超輕量解決方案。但是,它的侷限性也很明顯,那就是:一個DeltaStreamer作業只能接入一張表,這對於動輒就需要接入數百張甚至數千張表的資料湖來說是不實用的,儘管Hudi也提供了用於多表接入的MultiTableDeltaStreamer,但是這個工具類目前的成熟度和完備性還不足以應用於生產。此外,Hudi自0.10.0起針對Kafka Connect提供了Hudi Sink外掛(目前也是僅支援單表),為CDC資料接入Hudi資料湖開闢了新的途徑,這是值得持續關注的新亮點。
從長遠來看,CDC資料入湖並落地為Hudi表是一個非常普遍的需求,迭代並完善包括DeltaStreamer、HoodieMultiTableDeltaStreamer和Kafka Connect Hudi Sink外掛在內的多種原生元件在社群的呼聲將會越來越強烈,相信伴隨著Hudi的蓬勃發展,這些元件將不斷成熟起來,並逐步應用到生產環境中。
關於作者:耿立超,架構師,著有 《巨量資料平臺架構與原型實現:資料中臺建設實戰》一書,多年IT系統開發和架構經驗,對巨量資料、企業級應用架構、SaaS、分散式儲存和領域驅動設計有豐富的實踐經驗,個人技術部落格:https://laurence.blog.csdn.net
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

