中文命名實體識別
本文通過people_daily_ner資料集,介紹兩段式訓練過程,第一階段是訓練下游任務模型,第二階段是聯合訓練下游任務模型和預訓練模型,來實現中文命名實體識別任務。
一.任務和資料集介紹
1.命名實體識別任務
NER(Named Entity Recognition)和Pos(Part-of-Speech)是2類典型的標記分類問題。NER是資訊抽取基礎,識別文字中的實體(比如人名、地點、組織結構名等),本質就是預測每個字對應的標記。DL興起前,主要是HMM和CRF等模型,現在基本是DL模型。可根據需要設定標註方式,常見方式有BIO、BIESO等。NER資料樣例如下所示:
 2.資料集介紹
2.資料集介紹
本文使用中文命名實體識別資料集people_daily_ner,樣例資料如下所示:
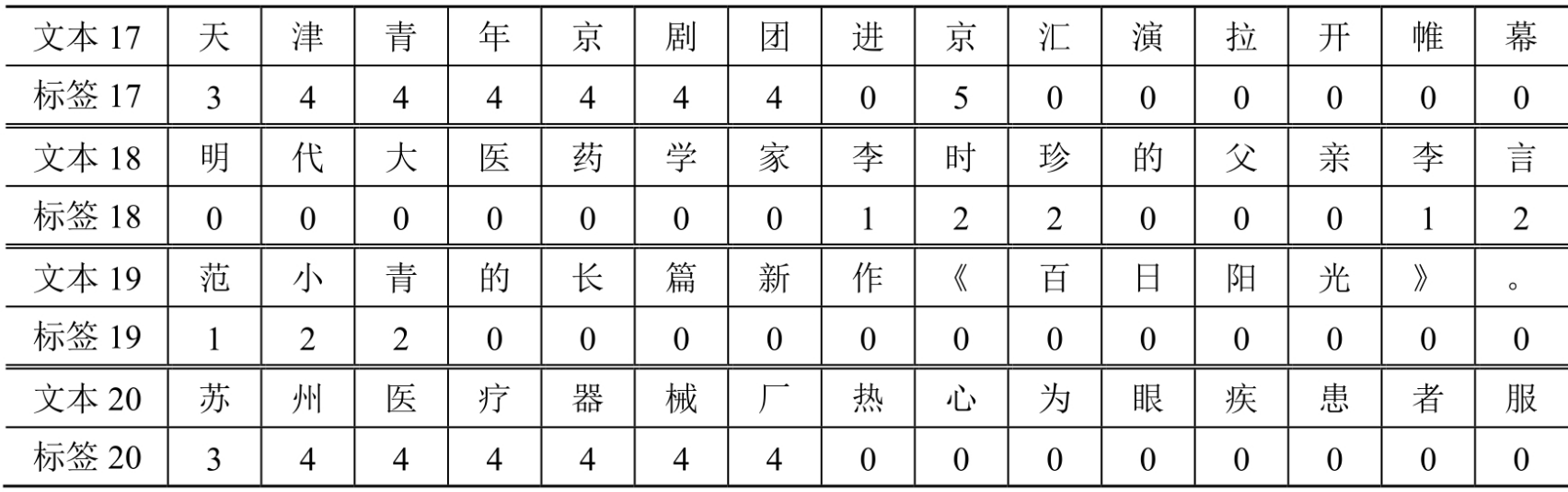 people_daily_ner資料集標籤對照表如下所示:
people_daily_ner資料集標籤對照表如下所示:

O:表示不屬於一個命名實體。 B-PER:表示人名的開始。 I-PER:表示人名的中間和結尾部分。 B-ORG:表示組織機構名的開始。 I-ORG:表示組織機構名的中間和結尾部分。 B-LOC:表示地名的開始。 I-LOC:表示地名的中間和結尾部分。
3.模型架構
本文使用hfl/rbt3模型[2],引數量約3800萬。基本思路為使用一個預訓練模型從文字中抽取資料特徵,再對每個字的資料特徵做分類任務,最終得到和原文一一對應的標籤序列(BIO)。
二.準備資料集
1.使用編碼工具
使用hfl/rbt3編碼器編碼工具如下所示:
def load_encode_tool(pretrained_model_name_or_path):
"""
載入編碼工具
"""
tokenizer = AutoTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}'))
return tokenizer
if __name__ == '__main__':
# 測試編碼工具
pretrained_model_name_or_path = r'L:/20230713_HuggingFaceModel/rbt3'
tokenizer = load_encode_tool(pretrained_model_name_or_path)
print(tokenizer)
# 測試編碼句子
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[
[ '海', '釣', '比', '賽', '地', '點', '在', '廈', '門', '與', '金', '門', '之', '間', '的', '海', '域', '。'],
[ '這', '座', '依', '山', '傍', '水', '的', '博', '物', '館', '由', '國', '內', '′', '一', '流', '的', '設', '計', '師', '主', '持', '設', '計', '。']],
truncation=True, # 截斷
padding='max_length', # [PAD]
max_length=20, # 最大長度
return_tensors='pt', # 返回pytorch張量
is_split_into_words=True # 按詞切分
)
# 檢視編碼輸出
for k, v in out.items():
print(k, v.shape)
# 將編碼還原為句子
print(tokenizer.decode(out['input_ids'][0]))
print(tokenizer.decode(out['input_ids'][1]))
輸出結果如下所示:
BertTokenizerFast(name_or_path='L:\20230713_HuggingFaceModel\rbt3', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
input_ids torch.Size([2, 20])
token_type_ids torch.Size([2, 20])
attention_mask torch.Size([2, 20])
[CLS] 海 釣 比 賽 地 點 在 廈 門 與 金 門 之 間 的 海 域 。 [SEP]
[CLS] 這 座 依 山 傍 水 的 博 物 館 由 國 內 一 流 的 設 計 [SEP]
需要說明引數is_split_into_words=True讓編碼器跳過分詞步驟,即告訴編碼器輸入句子是分好詞的,不用再進行分詞。
2.定義資料集
定義資料集程式碼如下所示:
class Dataset(torch.utils.data.Dataset):
def __init__(self, split):
# 線上載入資料集
# dataset = load_dataset(path='people_daily_ner', split=split)
# dataset.save_to_disk(dataset_dict_path='L:/20230713_HuggingFaceModel/peoples_daily_ner')
# 離線載入資料集
dataset = load_from_disk(dataset_path='L:/20230713_HuggingFaceModel/peoples_daily_ner')[split]
# print(dataset.features['ner_tags'].feature.num_classes) #7
# print(dataset.features['ner_tags'].feature.names) # ['O','B-PER','I-PER','B-ORG','I-ORG','B-LOC','I-LOC']
self.dataset = dataset
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
tokens = self.dataset[i]['tokens']
labels = self.dataset[i]['ner_tags']
return tokens, labels
if __name__ == '__main__':
# 測試編碼工具
pretrained_model_name_or_path = r'L:/20230713_HuggingFaceModel/rbt3'
tokenizer = load_encode_tool(pretrained_model_name_or_path)
# 載入資料集
dataset = Dataset('train')
tokens, labels = dataset[0]
print(tokens, labels, dataset)
print(len(dataset))
輸出結果如下所示:
['海', '釣', '比', '賽', '地', '點', '在', '廈', '門', '與', '金', '門', '之', '間', '的', '海', '域', '。'] [0, 0, 0, 0, 0, 0, 0, 5, 6, 0, 5, 6, 0, 0, 0, 0, 0, 0] <__main__.Dataset object at 0x0000027B01DC3940>
20865
其中,20865表示訓練資料集的大小。在people_daily_ner資料集中,每條資料包括兩個欄位,即tokens和ner_tags,分別代表句子和標籤,在__getitem__()函數中把這兩個欄位取出並返回即可。
3.定義計算裝置
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
print(device)
4.定義資料整理函數
def collate_fn(data):
tokens = [i[0] for i in data]
labels = [i[1] for i in data]
inputs = tokenizer.batch_encode_plus(tokens, # 文字列表
truncation=True, # 截斷
padding=True, # [PAD]
max_length=512, # 最大長度
return_tensors='pt', # 返回pytorch張量
is_split_into_words=True) # 分詞完成,無需再次分詞
# 求一批資料中最長的句子長度
lens = inputs['input_ids'].shape[1]
# 在labels的頭尾補充7,把所有的labels補充成統一的長度
for i in range(len(labels)):
labels[i] = [7] + labels[i]
labels[i] += [7] * lens
labels[i] = labels[i][:lens]
# 把編碼結果移動到計算裝置上
for k, v in inputs.items():
inputs[k] = v.to(device)
# 把統一長度的labels組裝成矩陣,移動到計算裝置上
labels = torch.tensor(labels).to(device)
return inputs, labels
形參data表示一批資料,主要是對句子和標籤進行編碼,這裡會涉及到一個填充的問題。標籤的開頭和尾部填充7,因為0-6都有物理意義),而句子開頭會被插入[CLS]標籤。無論是句子還是標籤,最終都被轉換為矩陣。測試資料整理函數如下所示:
data = [
(
['海', '釣', '比', '賽', '地', '點', '在', '廈', '門', '與', '金', '門', '之', '間', '的', '海', '域', '。'], [0, 0, 0, 0, 0, 0, 0, 5, 6, 0, 5, 6, 0, 0, 0, 0, 0, 0]
),
(
['這', '座', '依', '山', '傍', '水', '的', '博', '物', '館', '由', '國', '內', '一', '流', '的', '設', '計', '師', '主', '持', '設', '計', ',', '整', '個', '建', '築', '群', '精', '美', '而', '恢', '宏', '。'],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
)]
inputs, labels = collate_fn(data)
for k, v in inputs.items():
print(k, v.shape)
print('labels', labels.shape)
輸出結果如下所示:
input_ids torch.Size([2, 37])
token_type_ids torch.Size([2, 37])
attention_mask torch.Size([2, 37])
labels torch.Size([2, 37])
5.定義資料集載入器
loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=16, collate_fn=collate_fn, shuffle=True, drop_last=True)
通過資料集載入器檢視一批樣例資料,如下所示:
for i, (inputs, labels) in enumerate(loader):
break
print(tokenizer.decode(inputs['input_ids'][0]))
print(labels[0])
for k, v in inputs.items():
print(k, v.shape)
輸出結果如下所示:
[CLS] 這 種 輸 液 器 不 必 再 懸 吊 藥 瓶 , 改 用 氣 壓 推 動 液 體 流 動 , 自 閉 防 回 流 , 安 全 、 簡 便 、 抗 汙 染 , 堪 稱 輸 液 器 歷 史 上 的 一 次 革 命 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
tensor([7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7], device='cuda:0')
input_ids torch.Size([16, 87])
token_type_ids torch.Size([16, 87])
attention_mask torch.Size([16, 87])
三.定義模型
1.載入預訓練模型
# 載入預訓練模型
pretrained = AutoModel.from_pretrained(Path(f'{pretrained_model_name_or_path}'))
# 統計引數量
# print(sum(i.numel() for i in pretrained.parameters()) / 10000)
# 測試預訓練模型
pretrained.to(device)
2.定義下游任務模型
先介紹一個兩段式訓練的概念,通常是先單獨對下游任務模型進行訓練,然後再連同預訓練模型和下游任務模型一起進行訓練的模式。
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
# 標識當前模型是否處於tuning模式
self.tuning = False
# 當處於tuning模式時backbone應該屬於當前模型的一部分,否則該變數為空
self.pretrained = None
# 當前模型的神經網路層
self.rnn = torch.nn.GRU(input_size=768, hidden_size=768, batch_first=True)
self.fc = torch.nn.Linear(in_features=768, out_features=8)
def forward(self, inputs):
# 根據當前模型是否處於tuning模式而使用外部backbone或內部backbone計算
if self.tuning:
out = self.pretrained(**inputs).last_hidden_state
else:
with torch.no_grad():
out = pretrained(**inputs).last_hidden_state
# backbone抽取的特徵輸入RNN網路進一步抽取特徵
out, _ = self.rnn(out)
# RNN網路抽取的特徵最後輸入FC神經網路分類
out = self.fc(out).softmax(dim=2)
return out
# 切換下游任務模型的tuning模式
def fine_tuning(self, tuning):
self.tuning = tuning
# tuning模式時,訓練backbone的引數
if tuning:
for i in pretrained.parameters():
i.requires_grad = True
pretrained.train()
self.pretrained = pretrained
# 非tuning模式時,不訓練backbone的引數
else:
for i in pretrained.parameters():
i.requires_grad_(False)
pretrained.eval()
self.pretrained = None
(1)tuning表示當前模型是否處於微調模型,pretrained表示微調模式時預訓練模型屬於當前模型。
(2)在__init__()中定義了下游任務模型的2個層,分別為GRU網路和全連線神經網路層,GRU作用是進一步抽取特徵,提高模型預測正確率。
(3)fine_tuning()用來切換訓練模式pretrained.train()和評估模式pretrained.eval()。
四.訓練和測試
1.模型訓練
def train(epochs):
lr = 2e-5 if model.tuning else 5e-4 # 根據模型的tuning模式設定學習率
optimizer = AdamW(model.parameters(), lr=lr) # 優化器
criterion = torch.nn.CrossEntropyLoss() # 損失函數
scheduler = get_scheduler(name='linear', num_warmup_steps=0, num_training_steps=len(loader) * epochs, optimizer=optimizer) # 學習率衰減策略
model.train()
for epoch in range(epochs):
for step, (inputs, labels) in enumerate(loader):
# 模型計算
# [b,lens] -> [b,lens,8]
outs = model(inputs)
# 對outs和labels變形,並且移除PAD
# outs -> [b, lens, 8] -> [c, 8]
# labels -> [b, lens] -> [c]
outs, labels = reshape_and_remove_pad(outs, labels, inputs['attention_mask'])
# 梯度下降
loss = criterion(outs, labels) # 計算損失
loss.backward() # 反向傳播
optimizer.step() # 更新引數
scheduler.step() # 更新學習率
optimizer.zero_grad() # 清空梯度
if step % (len(loader) * epochs // 30) == 0:
counts = get_correct_and_total_count(labels, outs)
accuracy = counts[0] / counts[1]
accuracy_content = counts[2] / counts[3]
lr = optimizer.state_dict()['param_groups'][0]['lr']
print(epoch, step, loss.item(), lr, accuracy, accuracy_content)
torch.save(model, 'model/中文命名實體識別.model')
訓練過程基本步驟如下所示:
(1)從資料集載入器中獲取一個批次的資料。
(2)讓模型計算預測結果。
(2)使用工具函數對預測結果和labels進行變形,移除預測結果和labels中的PAD。
(4)計算loss並執行梯度下降優化模型引數。
(5)每隔一定的steps,輸出一次模型當前的各項資料,便於觀察。
(6)每訓練完一個epoch,將模型的引數儲存到磁碟。
接下來介紹兩段式訓練過程,第一階段是訓練下游任務模型,第二階段是聯合訓練下游任務模型和預訓練模型如下所示:
# 兩段式訓練第一階段,訓練下游任務模型
model.fine_tuning(False)
# print(sum(p.numel() for p in model.parameters() / 10000))
train(1)
# 兩段式訓練第二階段,聯合訓練下游任務模型和預訓練模型
model.fine_tuning(True)
# print(sum(p.numel() for p in model.parameters() / 10000))
train(5)
2.模型測試
模型測試基本思路:從磁碟載入模型,然後切換到評估模式,將模型移動到計算裝置,從測試集中取批次資料,輸入模型中,統計正確率。
def test():
# 載入訓練完的模型
model_load = torch.load('model/中文命名實體識別.model')
model_load.eval() # 切換到評估模式
model_load.to(device)
# 測試資料集載入器
loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'), batch_size=128, collate_fn=collate_fn, shuffle=True, drop_last=True)
correct = 0
total = 0
correct_content = 0
total_content = 0
# 遍歷測試資料集
for step, (inputs, labels) in enumerate(loader_test):
# 測試5個批次即可,不用全部遍歷
if step == 5:
break
print(step)
# 計算
with torch.no_grad():
# [b, lens] -> [b, lens, 8] -> [b, lens]
outs = model_load(inputs)
# 對outs和labels變形,並且移除PAD
# fouts -> [b, lens, 8] -> [c, 8]
# labels -> [b, lens] -> [c]
outs, labels = reshape_and_remove_pad(outs, labels, inputs['attention_mask'])
# 統計正確數量
counts = get_correct_and_total_count(labels, outs)
correct += counts[0]
total += counts[1]
correct_content += counts[2]
total_content += counts[3]
print(correct / total, correct_content / total_content)
3.預測任務
def predict():
# 載入模型
model_load = torch.load('model/中文命名實體識別.model')
model_load.eval()
model_load.to(device)
# 測試資料集載入器
loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'), batch_size=32, collate_fn=collate_fn, shuffle=True, drop_last=True)
# 取一個批次的資料
for i, (inputs, labels) in enumerate(loader_test):
break
# 計算
with torch.no_grad():
# [b, lens] -> [b, lens, 8] -> [b, lens]
outs = model_load(inputs).argmax(dim=2)
for i in range(32):
# 移除PAD
select = inputs['attention_mask'][i] == 1
input_id = inputs['input_ids'][i, select]
out = outs[i, select]
label = labels[i, select]
# 輸出原句子
print(tokenizer.decode(input_id).replace(' ', ''))
# 輸出tag
for tag in [label, out]:
s = ''
for j in range(len(tag)):
if tag[j] == 0:
s += '.'
continue
s += tokenizer.decode(input_id[j])
s += str(tag[j].item())
print(s)
print('=====================')
參考文獻:
[1]HuggingFace自然語言處理詳解:基於BERT中文模型的任務實戰
[2]https://huggingface.co/hfl/rbt3
[3]https://huggingface.co/datasets/peoples_daily_ner/tree/main
[4]https://github.com/OYE93/Chinese-NLP-Corpus/
[5]https://github.com/ai408/nlp-engineering/blob/main/20230625_HuggingFace自然語言處理詳解/第10章:中文命名實體識別.py