純分享:將MySql的建表DDL轉為PostgreSql的DDL
背景
現在信創是搞得如火如荼,在這個浪潮下,資料庫也是從之前熟悉的Mysql換到了某國產資料庫。
該資料庫我倒是想吐槽吐槽,它是基於Postgre 9.x的基礎上改的,至於改了啥,我也沒去詳細瞭解,當初的資料庫POC測試和後續的選型沒太參與,但對於我一個開發人員的角度來說,它給我帶來的不便主要是使用者端GUI工具這塊。
我們讀寫資料庫,程式這塊還好,CURD程式碼用到的語法,基本是sql標準相容的那些,沒用多少mysql的特殊語法,所以這塊沒啥感覺。
使用者端GUI這塊,pg的使用者端軟體目前知道幾個:
- navicat,公司沒采購正版,用不了,替代軟體是開源的dbeaver
- pgAdmin,pg官方使用者端,結果不知道這個國產化過程中改了啥,用pgAdmin連上就各種報錯,放棄
- dbeaver,這個倒是可以用,就是我感覺操作太麻煩了,太繁瑣
基於以上原因,一直用dbeaver來著,之前兩次把mysql專案的表結構換成pg,一次是寫了個亂七八糟的程式碼來做建表語句轉換,一次是用dbeaver建的,太繁瑣了。
這次又來了個專案,我就換回了我熟悉的sqlyog(一款mysql使用者端),幾下就把表建好了(mysql版本),然後寫了個工具程式碼,來把mysql的DDL轉換成pg的。
下面簡單介紹下這個轉換程式碼。
技術選型
以前寫這種程式碼,都是各種字串操作(正則、匹配、替換等等),反正程式碼最終是非常難以維護。這次就先去網上查了下,發現有人有類似需求,還發了文章:https://zhuanlan.zhihu.com/p/314069540
我發現其中利用了一個java庫,JSqlParser(https://github.com/JSQLParser/JSqlParser),我在網上也找了下其他的庫,java這塊沒有更好的了,遙遙領先。
其官方說明:
JSqlParser parses an SQL statement and translate it into a hierarchy of Java classes.
它支援解析sql語句這種非結構化文字為結構化資料,比如,針對如下的一個建庫sql:
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '排程-時間',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '執行中-紀錄檔數量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '執行成功-紀錄檔數量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '執行失敗-紀錄檔數量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
可以解析為如下的類及屬性:
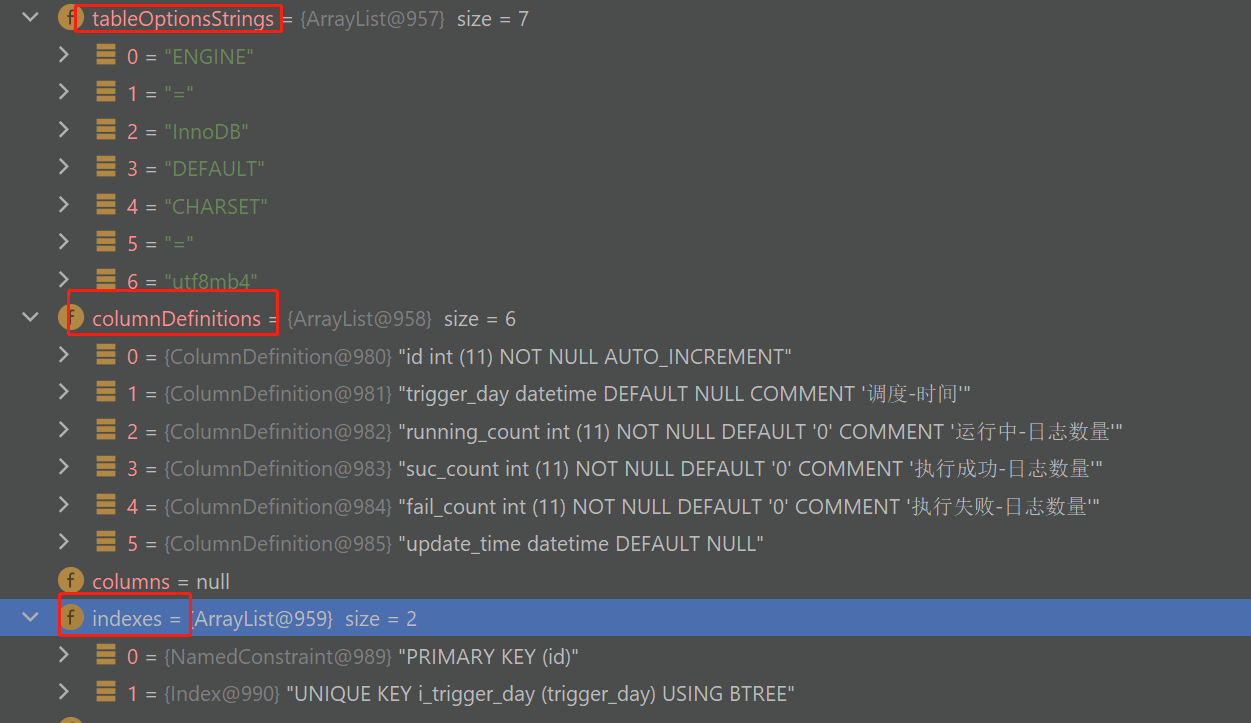
如上就包含了索引、列定義、建表選項等等。
我們接下來就只需要根據這些欄位,獲取資料並轉換為對應的Postgre的語法即可。
轉換效果
原始碼:https://github.com/cctvckl/convertMysqlDdlToPostgre.git
對於以上的類,給大家看看轉換效果:
CREATE TABLE xxl_job_log_report (
id serial PRIMARY KEY,
trigger_day timestamp NULL,
running_count int NOT NULL DEFAULT '0',
suc_count int NOT NULL DEFAULT '0',
fail_count int NOT NULL DEFAULT '0',
update_time timestamp NULL
);
COMMENT ON COLUMN xxl_job_log_report.trigger_day IS '排程-時間';
COMMENT ON COLUMN xxl_job_log_report.running_count IS '執行中-紀錄檔數量';
COMMENT ON COLUMN xxl_job_log_report.suc_count IS '執行成功-紀錄檔數量';
COMMENT ON COLUMN xxl_job_log_report.fail_count IS '執行失敗-紀錄檔數量';
這個sql,基本都滿足我們的要求了。
當然,我這個工具類,還沒特別完善,對於索引這塊,只支援了主鍵索引,其他索引型別,後面空了我補一下。
支援的DDL型別,目前僅限於create table和drop table,目前能滿足我個人需求了,反正mysqldump那些匯出來的sql結構基本就這樣。
暫不支援DML,如insert那些。
程式碼要點
整體邏輯
Statements statements = CCJSqlParserUtil.parseStatements(sqlContent);
for (Statement statement : statements.getStatements()) {
if (statement instanceof CreateTable) {
String sql = ProcessSingleCreateTable.process((CreateTable) statement);
totalSql.append(sql).append("\n");
} else if (statement instanceof Drop) {
String sql = ProcessSingleDropTable.process((Drop) statement);
totalSql.append(sql).append("\n");
} else {
throw new UnsupportedOperationException();
}
}
如上,CCJSqlParserUtil 是 JSqlParser 的工具類,將我們的sql轉換為一個一個的statement(即sql語句),我這邊利用instanceof檢查屬於哪種DDL,再呼叫對應的程式碼進行處理,設計模式也懶得弄,if else寫起來多快。
資料準備:表註釋
List<String> tableOptionsStrings = createTable.getTableOptionsStrings();
String tableCommentSql = null;
int commentIndex = tableOptionsStrings.indexOf("COMMENT");
if (commentIndex != -1) {
tableCommentSql = String.format("COMMENT ON TABLE %s IS %s;", tableFullyQualifiedName,tableOptionsStrings.get(commentIndex + 2));
}
解析出的表的相關屬性,全都被放在一個list中,我們根據COMMENT關鍵字定位索引,然後找後兩個,即是表註釋具體值。
資料準備:列註釋
由於我是直接在作者基礎上改的,https://zhuanlan.zhihu.com/p/314069540,所以也是像他那樣,複用了其程式碼,提取每一列的註釋,邏輯也是根據COMMENT關鍵字找到index,然後index+1就是註釋值。
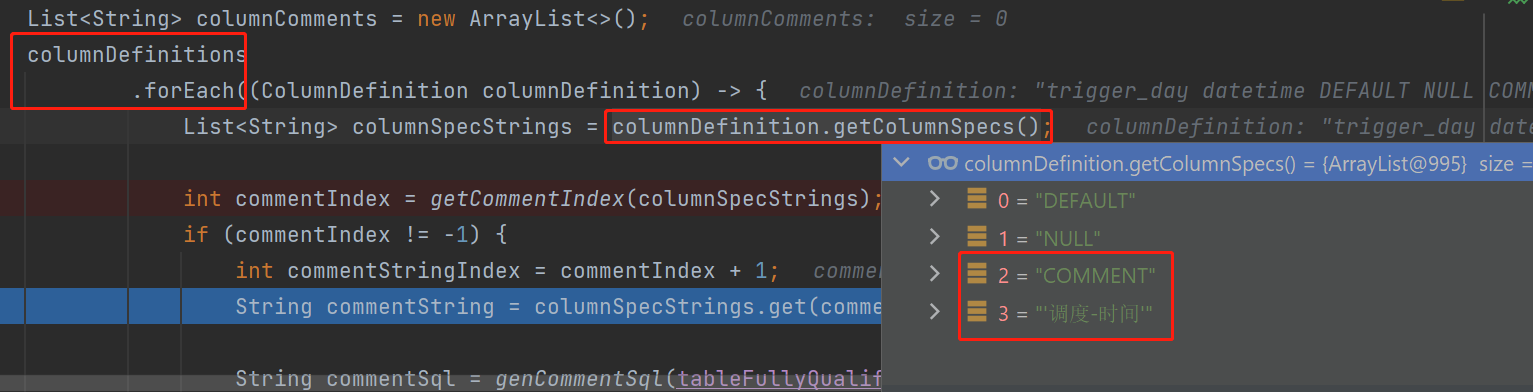
提取出來後,格式化為pg語法:
String.format("COMMENT ON COLUMN %s.%s IS %s;", table, column, commentValue);
資料準備:提取主鍵
Index primaryKey = createTable.getIndexes().stream()
.filter((Index index) -> Objects.equals("PRIMARY KEY", index.getType()))
.findFirst().orElse(null);
組裝sql:建表第一行
String createTableFirstLine = String.format("CREATE TABLE %s (", tableFullyQualifiedName);
組裝sql:主鍵列
這裡涉及資料型別轉換,如mysql中的bigint,在pg中,使用bigserial即可:
String dataType = primaryKeyColumnDefinition.getColDataType().getDataType();
if (Objects.equals("bigint", dataType)) {
primaryKeyType = "bigserial";
} else if (Objects.equals("int", dataType)) {
primaryKeyType = "serial";
} else if (Objects.equals("varchar", dataType)){
primaryKeyType = primaryKeyColumnDefinition.getColDataType().toString();
}
String sql = String.format("%s %s PRIMARY KEY", primaryKeyColumnName, primaryKeyType);
組裝sql:其他列
這部分有幾塊:
-
型別轉換,mysql的型別,轉換為pg的,我這邊定義了一個map,大致如下:
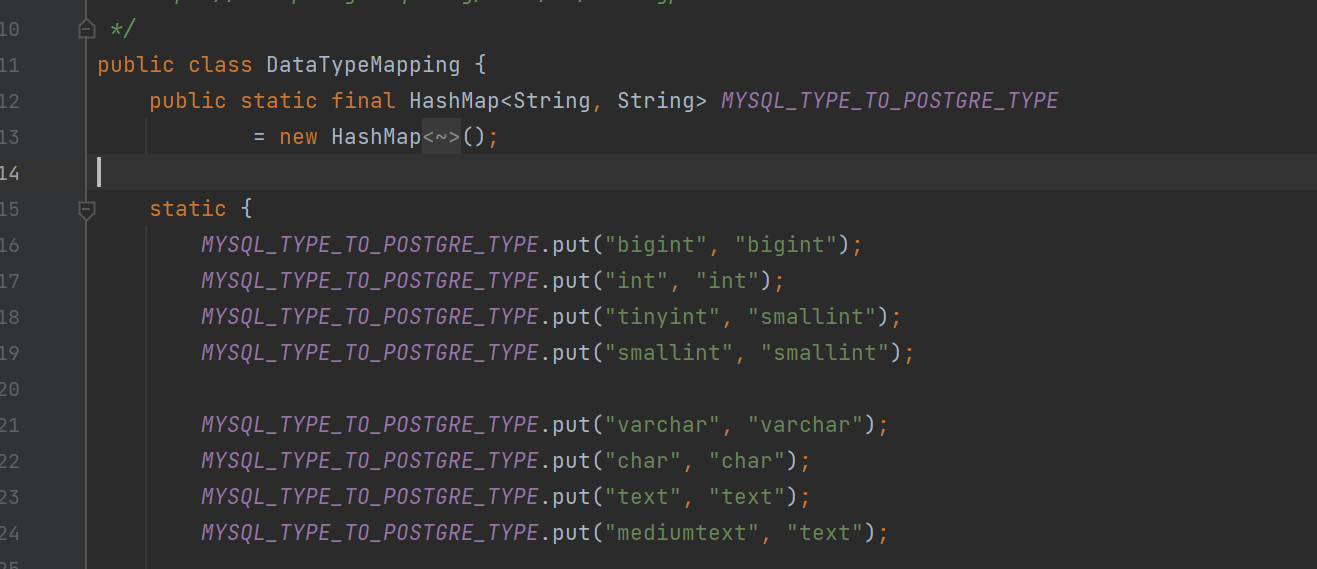
以上僅是部分,具體檢視程式碼
-
預設值處理
這塊也比較麻煩,比如mysql中的函數這種,如CURRENT_TIMESTAMP這種預設值,轉換為pg中的對應函數,我大概定義了幾個,滿足當前需要:
static { MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("NULL", "NULL"); MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("CURRENT_TIMESTAMP", "CURRENT_TIMESTAMP"); MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("CURRENT_DATE", "CURRENT_DATE"); MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("CURRENT_TIME", "CURRENT_TIME"); } -
刪除pg不支援的mysql語法
// postgre不支援unsigned sourceSpec = sourceSpec.replaceAll("unsigned", ""); // postgre不支援ON UPDATE CURRENT_TIMESTAMP sourceSpec = sourceSpec.replaceAll("ON UPDATE CURRENT_TIMESTAMP", "");
列印完整的pg語法sql
這塊就不說了,上面效果展示部分有。
生成出來的sql,會在專案根路徑下的target.sql檔案中
總結
生成的target.sql檔案,在idea中開啟,如果有語法錯誤會飄紅,如果大家有java開發能力,直接debug改就行,不行就提issue,我看到了空了就改;
我之前拿著有語法錯誤的sql就去dbeaver執行了,報錯也不詳細,看得一臉懵,idea還是厲害。
參考資料
mysql官方的遷移指南,裡面包含了pg的各種型別對應到mysql的什麼型別
https://dev.mysql.com/doc/workbench/en/wb-migration-database-postgresql-typemapping.html
mysql中的各種型別查閱
https://dev.mysql.com/doc/refman/8.0/en/data-types.html
pg中的各種型別查閱,我看得低版本的,誰讓我們的信創資料庫是基於pg 9版本的呢
https://www.postgresql.org/docs/11/datatype-numeric.html#DATATYPE-INT
這邊直接貼一下吧,方便大家看:
| Pg Source Type | Taret MySQL Type | Comment |
| INT | INT | |
| SMALLINT | SMALLINT | |
| BIGINT | BIGINT | |
| SERIAL | INT | Sets AUTO_INCREMENT in its table definition. |
| SMALLSERIAL | SMALLINT | Sets AUTO_INCREMENT in its table definition. |
| BIGSERIAL | BIGINT | Sets AUTO_INCREMENT in its table definition. |
| BIT | BIT | |
| BOOLEAN | TINYINT(1) | |
| REAL | FLOAT | |
| DOUBLE PRECISION | DOUBLE | |
| NUMERIC | DECIMAL | |
| DECIMAL | DECIMAL | |
| MONEY | DECIMAL(19,2) | |
| CHAR | CHAR/LONGTEXT | |
| NATIONAL CHARACTER | CHAR/LONGTEXT | |
| VARCHAR | VARCHAR/MEDIUMTEXT/LONGTEXT | |
| NATIONAL CHARACTER VARYING | VARCHAR/MEDIUMTEXT/LONGTEXT | |
| DATE | DATE | |
| TIME | TIME | |
| TIMESTAMP | DATETIME | |
| INTERVAL | TIME | |
| BYTEA | LONGBLOB | |
| TEXT | LONGTEXT | |
| CIDR | VARCHAR(43) | |
| INET | VARCHAR(43) | |
| MACADDR | VARCHAR(17) | |
| UUID | VARCHAR(36) | |
| XML | LONGTEXT | |
| JSON | LONGTEXT | |
| TSVECTOR | LONGTEXT | |
| TSQUERY | LONGTEXT | |
| ARRAY | LONGTEXT | |
| POINT | POINT | |
| LINE | LINESTRING | |
| LSEG | LINESTRING | |
| BOX | POLYGON | |
| PATH | LINESTRING | |
| POLYGON | POLYGON | |
| CIRCLE | POLYGON | |
| TXID_SNAPSHOT | VARCHAR |