Empowering Long-tail Item Recommendation through Cross Decoupling Network (CDN)
Empowering Long-tail Item Recommendation through Cross Decoupling Network (CDN)
來源:
- KDD'2023
- Google Research
長尾問題是個老大難問題了。
在推薦中可以是使用者/物料冷啟動,在搜尋中可以是中低頻query、檔案,在分類問題中可以是類別不均衡。長尾資料就像機器學習領域的一朵烏雲,飄到哪哪裡就陰暗一片。今天就介紹來自Google的一篇解決長尾物品推薦的論文。
真實推薦場景下,大部分物品都是長尾物品,即小部分物品佔據了絕大部分的互動,大部分物品的互動次數很少。人們一直都致力解決這個問題,但往往不能在真實環境下部署,要麼對整體的效果大打折扣。在這篇論文裡,作者致力於維持整體效果、保成本的條件下提高長尾物品的推薦效果(是否需要專門評估在長尾物品上的推薦效果?)。為了達到這個目標,作者設計了Cross Decoupling Network (CDN)。
CDN借鑑了計算機視覺裡的一個想法[1](借鑑的這篇論文也是研究長尾問題的,感覺值得閱讀一下),該方法的核心思想是兩階段的學習策略:第一階段在長尾分佈的資料集上學習物品表徵,第二階段在平衡的資料集上訓練預測器(如分類器)。但是這種方法在推薦場景中,這種方法會導致嚴重的遺忘問題,即第一階段學到的知識會在第二階段遺忘。並且兩階段訓練比聯合訓練的成本更高。而CDN則兼顧瞭解耦(decoupling)的思想,並克服了遺忘問題。
長尾問題分析
長尾問題的本質是什麼呢?
先來拋個磚:個人認為長尾物品推薦效果不好的本質原因是否是因為物品的特徵計算不準確,由於互動較少,按照正常的計算邏輯得到的結果是有偏(biased)的。感覺現在推薦裡捲來捲去,如何去偏慢慢得到大家的重視了。
論文中,作者理論上分析(有點意思,具體分析可以參考論文,但是感覺有點牽強)得到長尾問題不利於整體效果的原因是因為對使用者偏好的預測是有偏的,這個偏差又來自兩部分(這裡借鑑石塔西大佬的解釋和觀點[2]):
- 物品本身特徵學習的質量與其分佈有關。對於熱門物品,是那些容易記憶的特徵發揮作用,比如item id embedding,如果學好了,是最個性化的特徵。但是對於長尾物品,恰恰是在模型看重這些特徵上都沒有學習好(因為缺少訓練資料,不可能將長尾item id embedding學好)。
- 使用者對物品的偏好不容易學好。訓練集中正樣本以熱門物品居多,從而讓user embedding也向那些高熱物品靠攏,而忽視長尾物品。
對於第一種偏差,要解決模型對那些冷啟友好特徵不重視的問題。對於冷啟,單單增加一些對冷啟友好的特徵是沒用的,因為模型已經被老使用者、老物料綁架了。以物料冷啟為例,模型看重的item id embedding這些最個性化的物料特徵,但是恰恰是長尾物品沒有學好的。長尾物品希望模型多看重一些可延伸性好的特徵,比如tag / category,但是模型卻不看重。
CDN從以下兩個方面解決長尾問題:
- 物品側,解耦頭部和尾部物品的表徵的學習,即記憶(memorization)和泛化(generalization)解耦。具體做法是把記憶相關的特徵和泛化相關的特徵分別喂進兩個MOE中,讓這兩個MOE分別專注於記憶和泛化,然後通過門控機制對二者的輸出進行加權。
- 使用者側,通過正則化的雙邊分支網路(regularized bilateral branch network[3])解耦使用者的取樣策略。該網路分成有兩個分支,一個分支在全域性資料上學習使用者偏好,另一個分支在相對平衡的資料上學習。
CDN
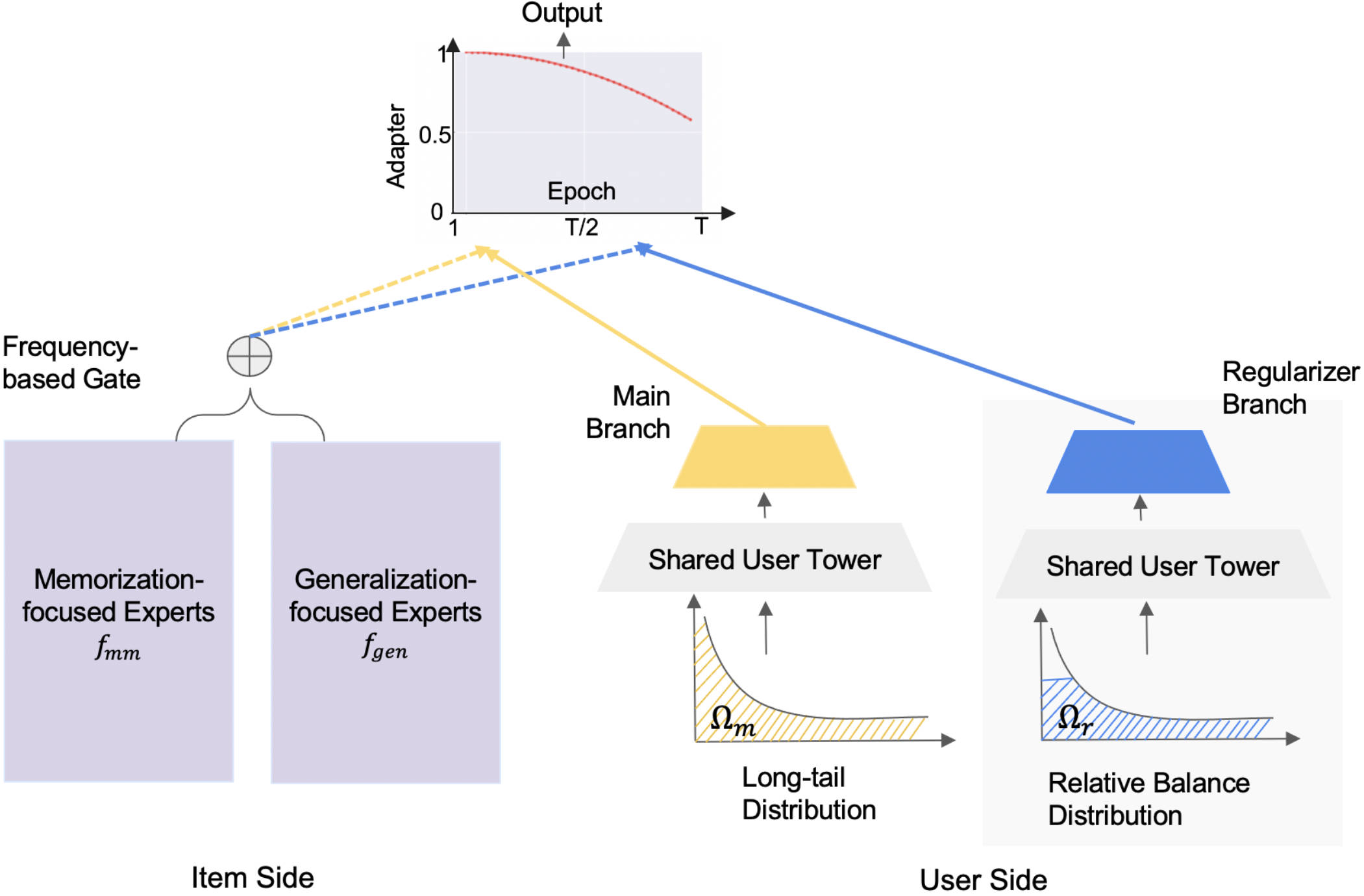
CDN的整體結構如上圖所示,左右兩邊分別對應物品側和使用者側。
Item Memorization and Generalization Decoupling
既然要通過劃分記憶和繁華特徵來解耦,那麼怎麼劃分輸入的特徵呢?
記憶特徵(Memorization features)
記憶特徵使模型能夠記住資料集中出現頻繁的模式,通常是滿足以下性質的類別特徵:
- Uniqueness。對於特徵空間\(\mathcal{V}\),存在單射函數\(f_{in}:\ \mathcal{I} \rightarrow \mathcal{V}\);
- Independence,即特徵空間的任意兩個元素之間是獨立的,互不影響的。
對於記憶特徵的embedding,其一般只會被指定的物品更新(uniqueness),並且不同物品的記憶特徵一般不同(independence)。因此,記憶特徵一般只記住與物特定品相關的資訊。物品ID就是一種很強的記憶特徵(還有哪些記憶特徵呢?)。
泛化特徵(Generalization features)
泛化特徵通常是那些能學習到使用者偏好和物品之間關係的特徵,這些特徵通常是物品間共用的特徵,如物品的類別、標籤等。
物品表徵學習
作者採用基於頻率的門控的MoE(Mixture of Expert)來解耦記憶和泛化。
對於一個訓練樣本\((u, i)\),物品表徵表示如下(方便起見,向量沒有用黑體):
其中\(E_k^{mm}(\cdot)\)表示專注於記憶的第\(k\)個專家網路,輸入為記憶特徵\(i_{mm}\);\(E_k^{gen}(\cdot)\)表示專注於泛化的第\(k\)個專家網路,輸入為泛化特徵\(i_{gen}\)。注意,這些特徵一般是把對應特徵的嵌入拼接起來。\(G(\cdot)\)為門控函數(輸出為向量),\(G(i)_{k}\)表示門控輸出的第\(k\)個元素,且\(\sum_{k=1}^{n_1 + n_2} G(i) = 1\)。簡單的理解,就是門控的輸出對記憶和泛化網路的輸出進行動態加權。此處的動態加權即是關鍵,即根據物品的熱度動態調整記憶和泛化的比例。作者建議用物品頻率作為門控的輸入,即\(g(i) = softmax(W i_{freq})\)。
記憶和泛化解耦後,泛化的專家網路的更新將主要來自於長尾物品,而不會損害記憶專家網路從而導致整體效能的下降。
User Sample Decoupling
這一部分解耦的是使用者的互動,提出了正則化的雙邊網路(Regularized Bilateral Branch Network):
- main分支在原始資料\(\Omega_m\)上訓練。顯然這個資料集中物品的互動是有偏的,這對使用者在長尾物品上的偏好的學習是有偏的;
- regularizer分支在均衡後的資料上\(\Omega_r\)訓練,即對熱門物品的互動進行降取樣。顯然,使用者對長尾物品的偏好學習被提權了。
這兩個分支有一個共用的基座(User Tower),以及各自一個分支特定的網路。在訓練階段,對於\((u_m, i_m) \in \Omega_m\)和\((u_r, i_r) \in \Omega_r\)分別進入main和regularizer分支,不同分支計算出來的使用者表示為:
其中\(f(\cdot)\)就是兩個分支共用的基座,\(h_m(\cdot), h_r(\cdot)\)分別是兩個分支特有的。main和regularizer可以同時訓練,但是在推理時只使用main分支。
Cross Learning
最終物品和使用者的表徵通過一個\(\gamma\)-adapter來融合,並控制訓練過程中模型的注意力轉移到長尾物品上。訓練時的logit計算方式為:
其中\(\alpha_t\)就是\(\gamma\)-adapter,它是訓練輪數的函數:
其中\(T\)是總的訓練輪數,\(t\)是當前輪數,\(\gamma\)是正則化率,對於越不平衡的資料集,\(\gamma\)的取值一般越大。得到\(s(i_m, i_r)\)後,使用者對物品的偏好通過以下方式計算:
損失函數為:
其中\(\hat{d}(u_m, i_m), \hat{d}(u_r, i_r) \in \{0, 1\}\)分別表示\(\Omega_m, \Omega_r\)中的使用者偏好(這裡論文描述的不是很清楚)。
吐槽以下:論文在訓練資料構造和訓練過程講的都不是很清楚。比如同時訓練main和regularizer,輸入的樣本分別是什麼,\(u_m, u_r\)是同一個使用者嗎,\(i_m, i_r\)是用一個物品嗎?還有就是\(s(i_m, i_r)\)計算結果是什麼含義?
總結
總體來說,這篇論文對長尾問題的認識還是很深的,也確實讓人有所啟發。特別關於特徵解耦的那一部分,感覺以後可以實踐一下。但是在後續的兩個分支部分語焉不詳,且缺乏相關的實現細節,或許是本人公里不夠,一些細節錯過了。還請路過的大佬指正。
參考
Decoupling representation and classifier for long-tailed recognition, ICLR 2020. ↩︎
https://zhuanlan.zhihu.com/p/651731184:似曾相識:談Google CDN長尾物料推薦. ↩︎
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition, CVPR 2020. ↩︎