微服務16:微服務治理之熔斷、限流
2023-09-01 18:01:09
★微服務系列
微服務1:微服務及其演進史
微服務2:微服務全景架構
微服務3:微服務拆分策略
微服務4:服務註冊與發現
微服務5:服務註冊與發現(實踐篇)
微服務6:通訊之閘道器
微服務7:通訊之RPC
微服務8:通訊之RPC實踐篇(附原始碼)
微服務9:服務治理來保證高可用
微服務10:系統服務熔斷、限流
微服務11:熔斷、降級的Hystrix實現(附原始碼)
微服務12:流量策略
微服務13:雲基礎場景下流量策略實現原理
微服務14:微服務治理之重試
微服務15:微服務治理之超時
1 介紹
在網際網路電商場景中,我們經常會遇到有計劃的流量洪峰,比如 雙11、618購物節,積分競拍和定時搶購的瘋狂場景。
這種是在預期內的,知道會發生並有一定的準備。而那些預期之外的突發流量異常,才是真正給我們帶來挑戰的部分,比如:
- 硬體故障:如伺服器宕機,機房斷電,光纖被挖斷等。
- 快取擊穿:一般發生在應用重啟導致的快取失效,以及短時間內大量快取過期失效時。大量的無法命中,使請求直擊後端服務,造成服務提供者超負荷執行,引起服務不可用。
- 程式BUG:如程式邏輯導致記憶體漏失;JVM長時間FullGC等。
- 新功能上線:未經過評估,導致非預期流量上漲 ( 某次功能上線,未進行有效的容量評估,導致ws長連線翻數倍)。
單個服務因為流量變化變得不可用,這種不可用如果持續可能是出現水平和垂直雙重的擴散。
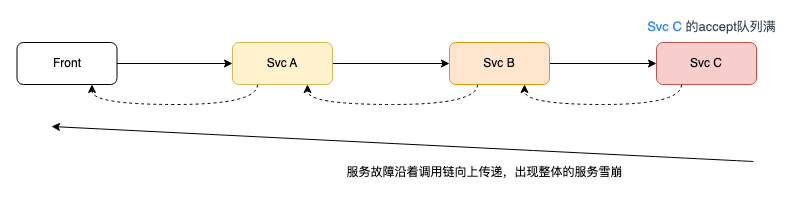
在分散式系中的某個服務故障沿著呼叫鏈向上傳遞,出現整體的服務雪崩,如下圖,這種情況如何提升系統的穩定性和健壯性是我們首要考慮的問題。
2 異常流量洪峰的常見治理手段
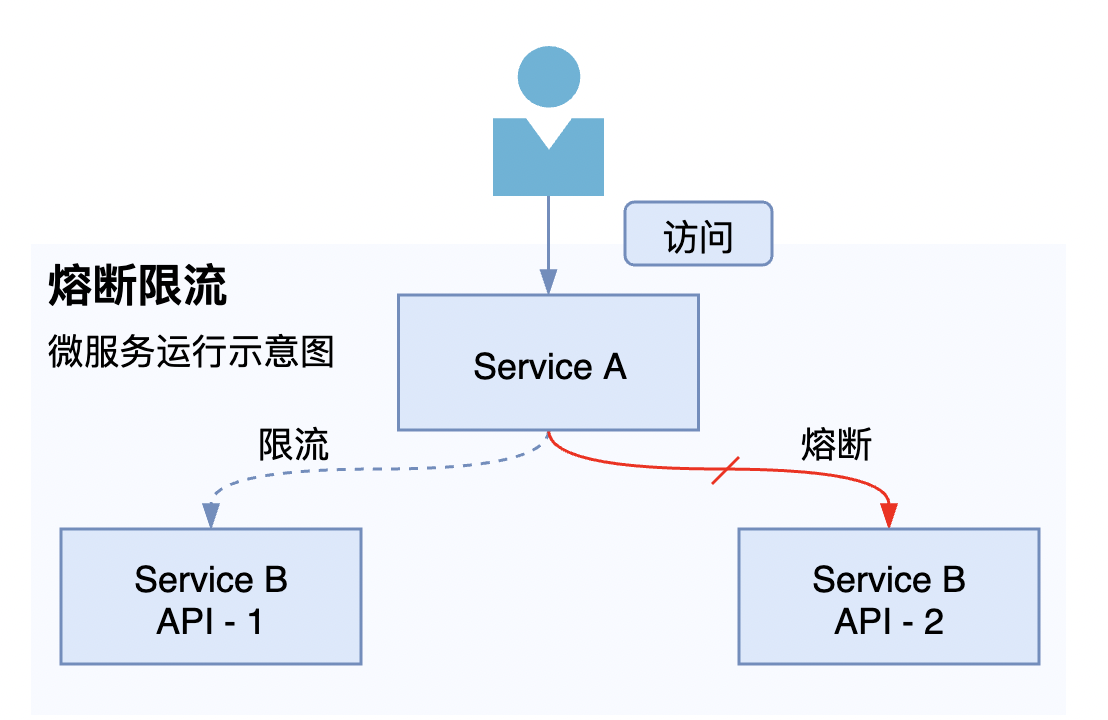
一般是採用限流或者熔斷:避免預期外流量或故障導致的流量洪峰引起服務雪崩,沿呼叫向上傳遞,造成整個鏈路崩潰。
2.1 限流手段
限流部分,對來路流量做了限制,不允許超過預期峰值。執行過程說明:
- 這邊以範例服務 Service A 向 Service B 發起存取為例子。
- 當Service A 感知到 Service B 的某個範例響應時間變慢或者異常返回變多之後,開始對Service B 發起限流。
- 比如使用令牌桶原理(定速流入),每秒鐘只提供N個令牌,每個請求攜帶一個令牌標識前行,用完即限行。

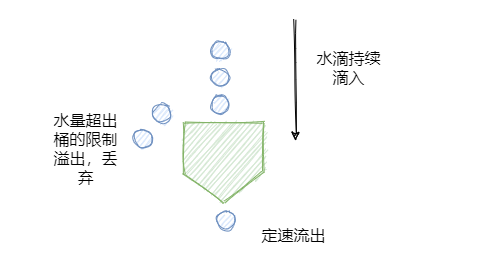
- 或者使用漏桶演演算法(漏斗池演演算法),無論請求多少,請求的速率有多大,都按照固定的速率流出,對應的就是服務按照固定的速率處理請求。
- 這樣就不會超過預期我們的服務能夠承載的QPS,避免被打穿的風險 。
2.2 熔斷手段
熔斷部分,則是直接斷流,流量就不會再負載過去了。執行過程說明:
- 這邊以範例服務 Service A 向 Service B 發起存取為例子。
- 當Service A 感知到 Service B 的某個範例響應時間變慢或者異常數不符合我們預期的,開始對Service B 發起熔斷。
- 熔斷並不是對整個服務都熔斷掉,而是對服務中的某個範例進行熔斷,其他健康範例還是可以負載流量的。
- 這樣就避免了我們的流量持續打到的異常的範例上,造成請求有損的體驗 。
3 策略實現(Service Mesh方案)
註釋比較清晰了,這邊就不解釋了。
# DestinationRule
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: xx-svc-b-vs
namespace: kube-ns-xx
spec:
host: svc_b.google.com # 治理髮往svc_b服務的流量
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
connectionPool:
http:
http1MaxPendingRequests: 50000 # 等待佇列,超額熔斷
http2MaxRequests: 40000 # http請求數限制,超額熔斷
maxRetries: 2 # 同一個請求的超時次數上限限制,超過即熔斷。應用於當前所有的host。
tcp:
maxConnections: 40000 # 後端叢集總的TCP連線數,超額熔斷
4 總結
雲基礎場景下的治理手段各種各樣,這邊講解了初級版的熔斷/限流方案,讓使用者有一個更優良的使體驗。
同時在系統大面積崩潰的時候,進行系統保護,不至於全面崩塌。
在後續的章節我們逐一瞭解下異常驅逐、異常自動重啟等高階用法。

架構與思維·公眾號:撰稿者為bat、位元組的幾位高階研發/架構。不做廣告、不賣課、不要打賞,只分享優質技術
★ 加公眾號獲取學習資料和麵試集錦
碼字不易,歡迎關注,歡迎轉載
作者:翁智華
本文采用「CC BY 4.0」知識共用協定進行許可,轉載請註明作者及出處。