架構師必會之-DBA級問題的資料庫底層設計思想
大家好,我是sulny_ann,這期想跟大家分享一下我之前在面試裡面問過比較難的資料庫相關的問題。
大家經常也在調侃後端好像就是技術資料庫的增刪改查,所以作為後端開發,你對應資料庫這一塊掌握的怎麼樣,是非常能看出你整個開發的技術能力水平。
接下來就分享 3 個我之前問到的關於資料庫的 3 個問題。
第一個問題就是如果一個事務當中有更新操作,也有查詢操作,那我是先更新好呢?還是先查詢好?
很多小夥伴一聽到這個問題不知道我想考啥,我印象比較深刻就是這個候選人他還是比較聰明的,他還先問我一下,你這個更新操作依不依賴這個查詢的操作。我也提示了這兩個是沒有什麼依賴關係的,所以這裡我的重點是開啟了一個事物,那對於事物它肯定是要消耗資源的,那消耗的資源有哪些東西?
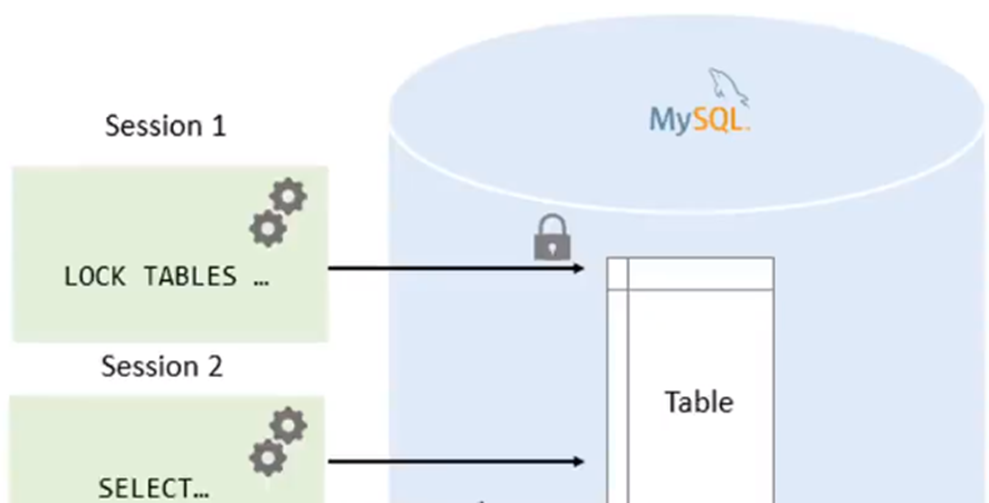
有連線池,還有底層的鎖,那大家想一下,更新它可能是會持有什麼鎖呢?有可能是行鎖,也有可能是間隙鎖,甚至可能是表鎖。那既然這個事物加鎖,那其他的事物只能在這些資源上去做一個等待,這就可能降低整個資料庫的並行效能。
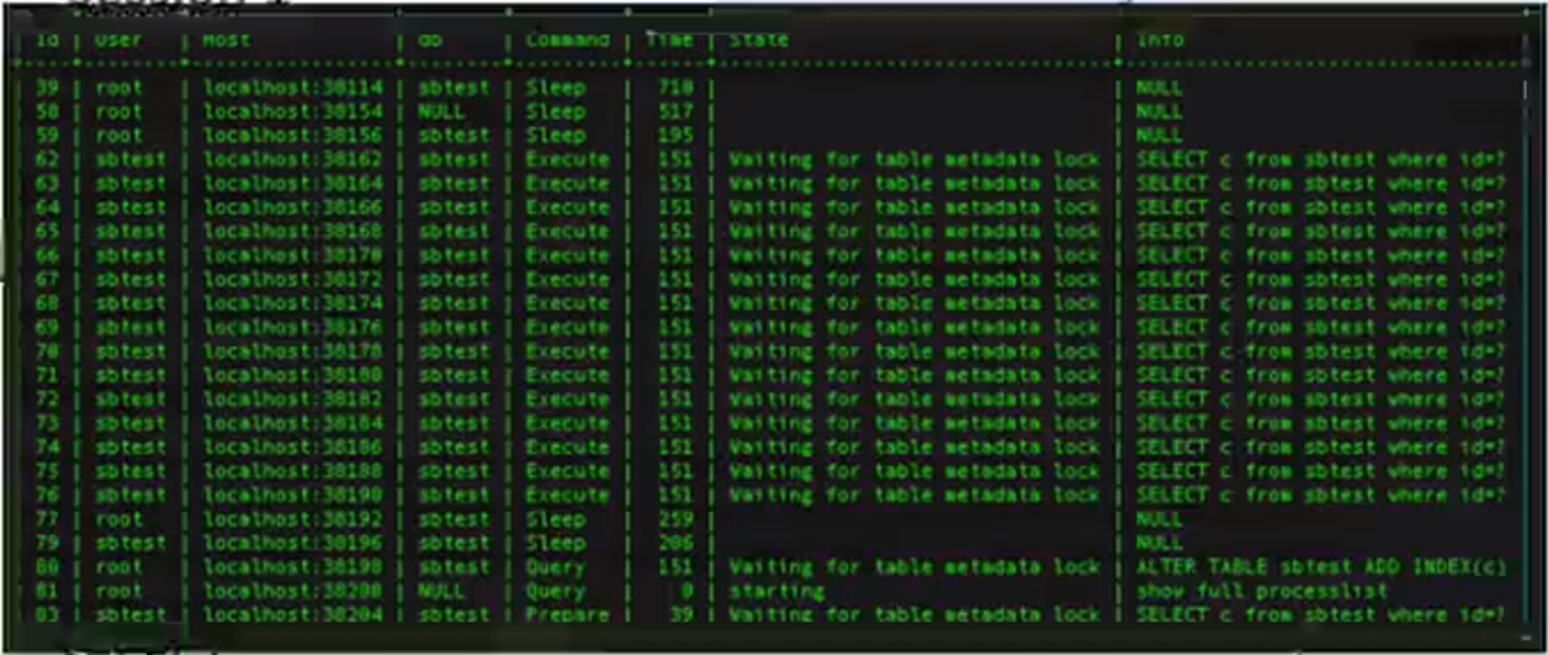
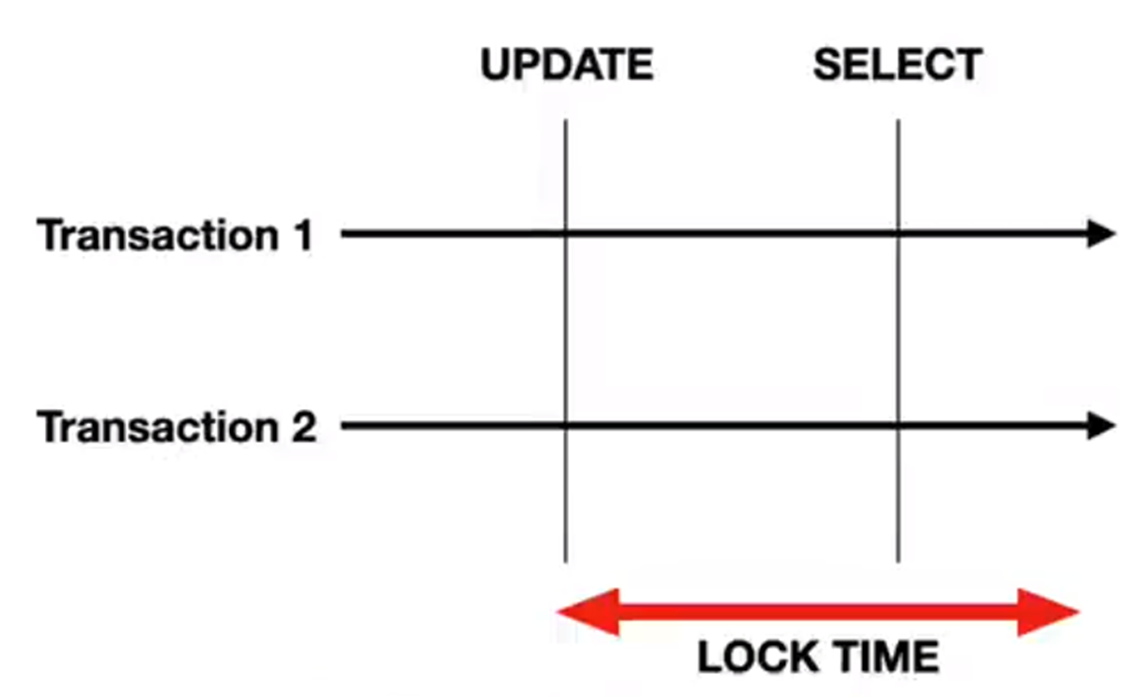
所以這個問題應該怎麼去回答呢?其實在大部分的情況就應該先去查詢,再去更新,但這裡的查詢預設是不會去加鎖的。如果先更新,再去查詢,如果這個查詢是一個慢SQL,那這個更新操作它持有的資源是會一直阻塞在這裡。
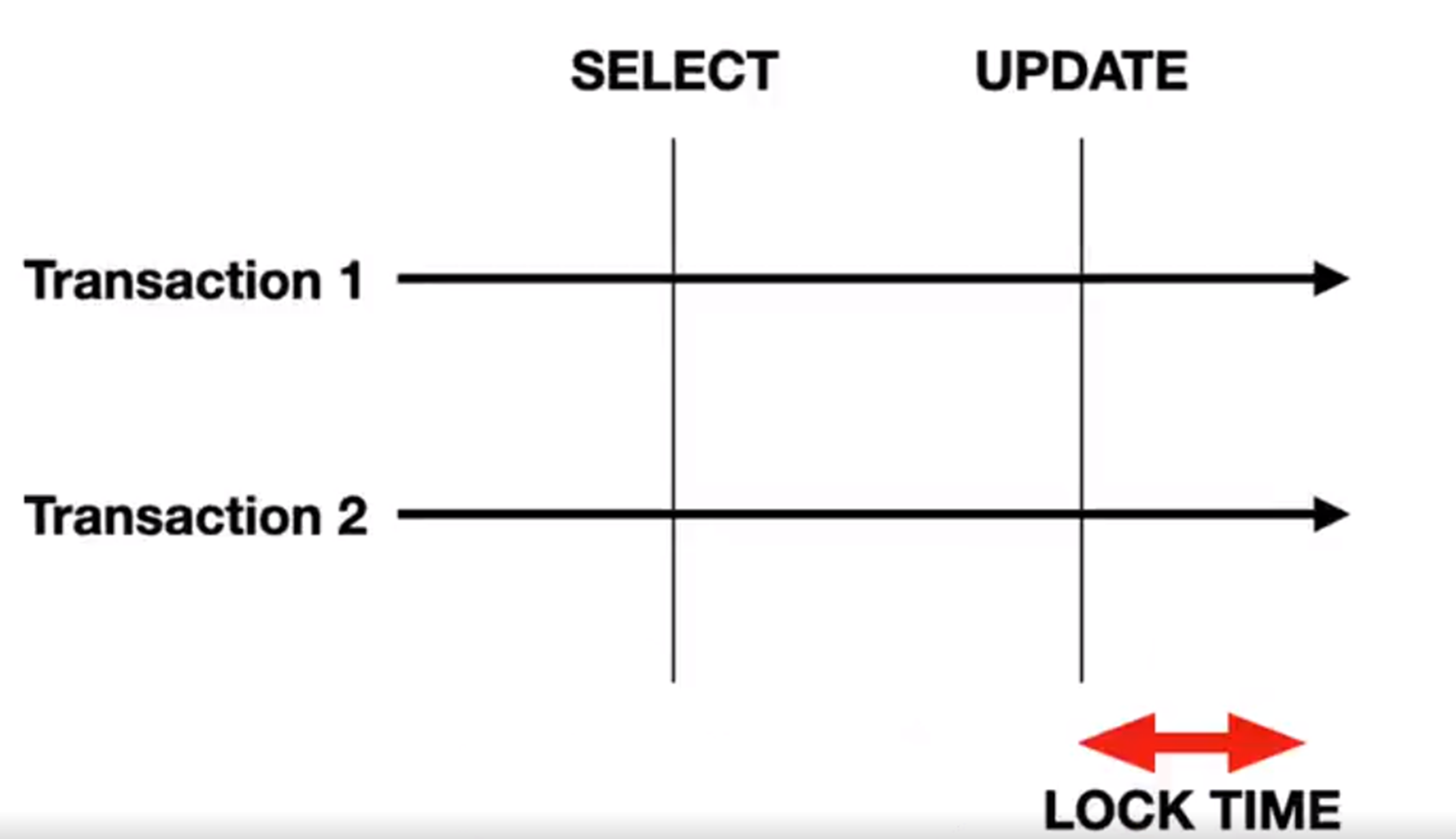
那先查詢再更新,那你 select 就算是一個慢SQL,在這個查詢執行過程當中其實是沒有加鎖的,這能夠一定程度提升整個資料庫的並行能力。我之前線上上確實也做過類似的優化,只要把他們執行的順序稍微改一下,在一些並行比較高的介面確實能夠提升很大的效能。
第二個問題就是我們經常在設計資料庫表的時候,經常會做一些欄位的冗餘,你覺得這樣做有什麼優缺點?
這其實也是非常常見的一種反正規化設計。做欄位冗餘大部分情況下是為了便於去查詢,例如商品跟店鋪之間的關係,我可能有一個關係表,但是我在業務上有很多查詢,就是要基於店鋪去查詢他所有的商品,那難道每一次查詢都要去做一個join嗎?或者查兩次嗎?如果說我在商品這個表裡面去加一個店鋪的欄位,做這麼一個欄位的冗餘就能夠很大程度提升整個查詢的效能。
那做欄位冗餘有什麼缺點嗎?也有就是如果你要去更新這個關係,你可能要改多個地方,這個就有點類似於快取的一致性問題,而且這種問題如果在同一個資料庫可能還比較好控制,如果是在多個資料庫,那你這個風險就非常大了。
所以這裡你還要看你的業務場景,就是查詢的佔比比較高,還是寫的佔比比較高。如果說是寫的佔比比較高,那你這個帶來事物還有不一致的風險可能會更大。
第三個問題確實也比較有挑戰,就是我們的 MySQL 裡面的 binlog 跟redolog,哪一個是先產生的?
這個問題大家又覺得我是想問什麼東西呢?要回答好這個問題,你首先要知道 binlog 跟 read log 它們分別是用來幹嘛的,解決什麼問題的。
簡單介紹一下, MySQL 底層其實是分了好幾個結構的,其中有 Server 層,還有 engine 層。
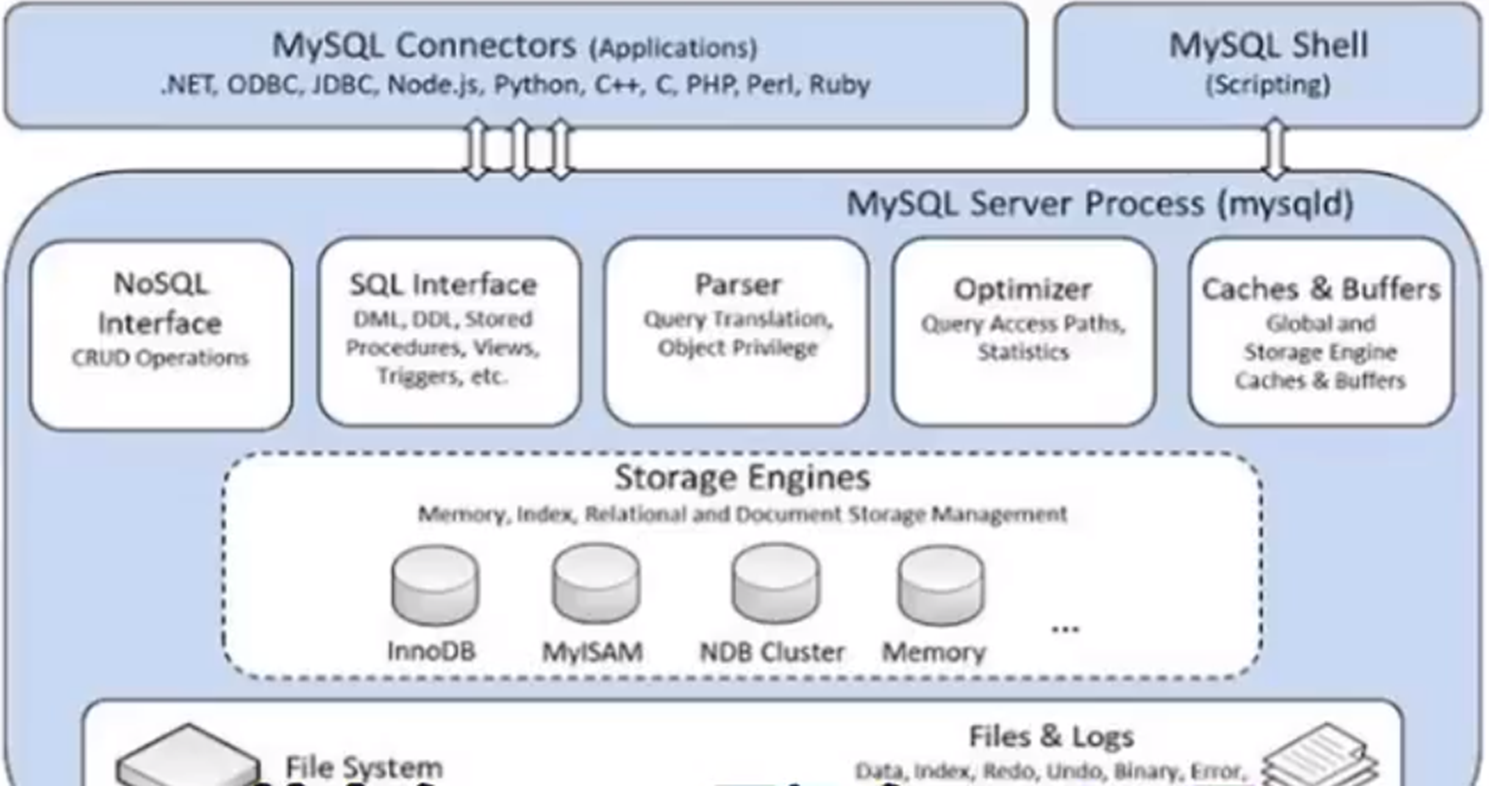
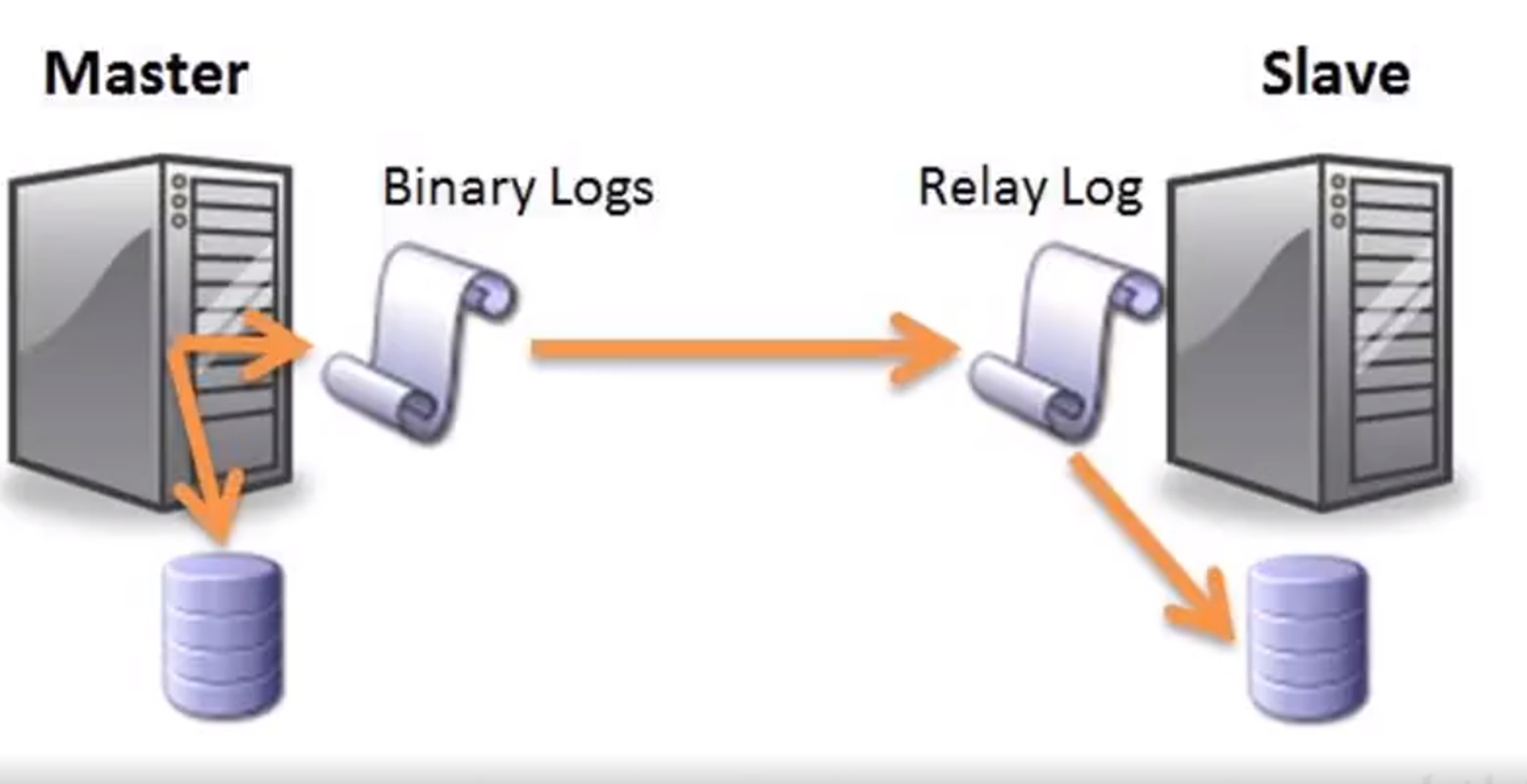
binlog它就是產生在 Server 層,是用來記錄資料庫DML 產生的二進位制紀錄檔,主要是用來做主從主備他們之間的一些資料備份。
那 redolog 它是產生在 MySQL 的 engine 層的,主要是用來保證資料操作的原子性。那這兩種紀錄檔他們其實都有自己的一個緩衝區。
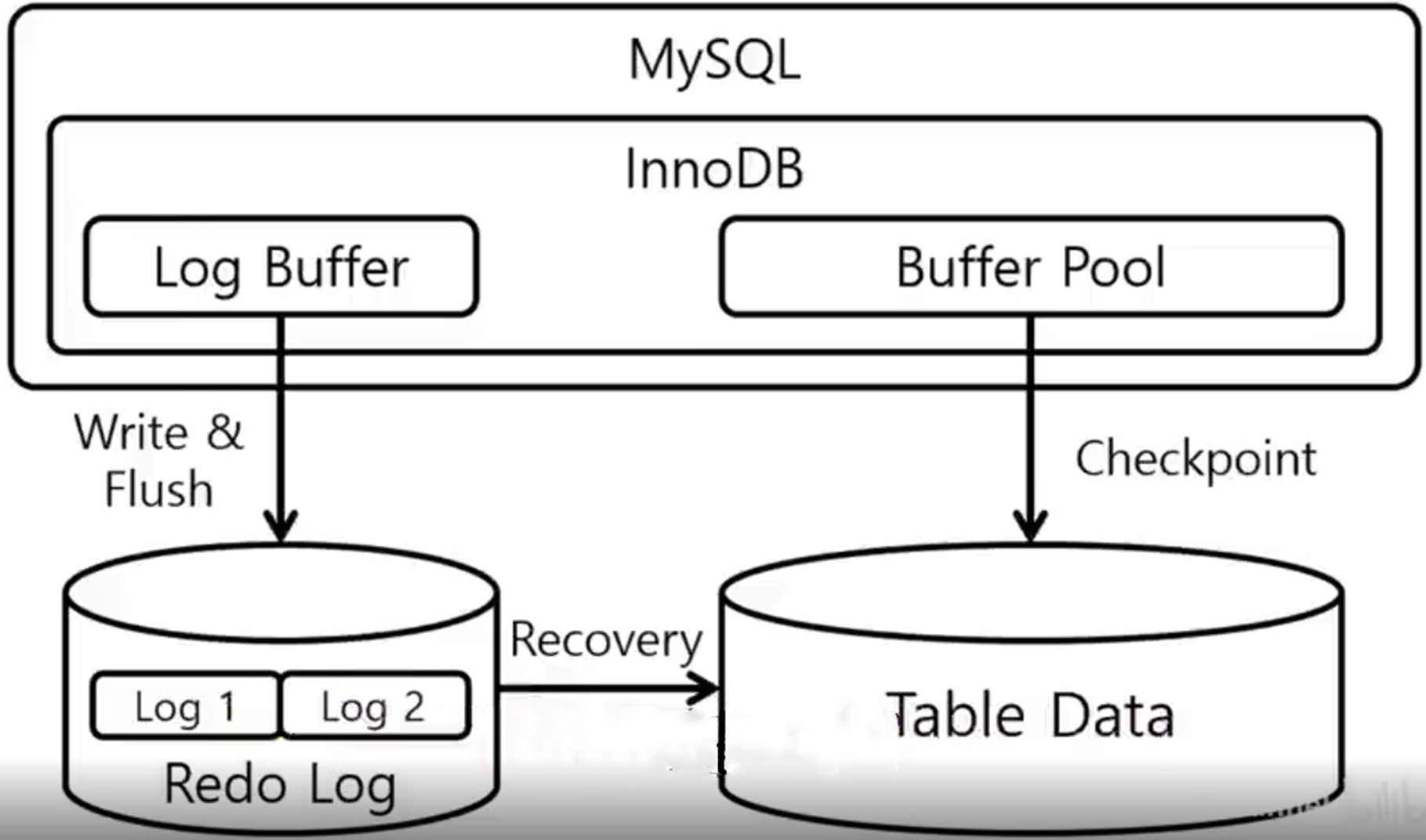
但是他們持久化一般都是分兩個步驟:先寫在作業系統的核心區,再去做一個刷盤操作。

如果對可行性要求比較高,那我們每次產生事物的時候都是去做一個持久化,但是我們一般情況只會考慮把它刷在作業系統的核心層,因為這種情況是效能跟它的資料可靠性做一個折中,只要作業系統層面沒有宕機,那這個資料一般是不會丟失的。
說到這裡我們好像並沒回答這個問題,就是這兩個操作哪個先產生?那這裡產生是站在什麼角度?是站在磁碟的角度,還是說站在 MySQL 程序的角度?如果說是程序,他們兩個基本上是同時產生的,但是坐在磁碟的角度,其實redolog 它可能先產生,為什麼說是可能呢?因為 binlog 他一定說是事物提交之後才會去做一個持久化。
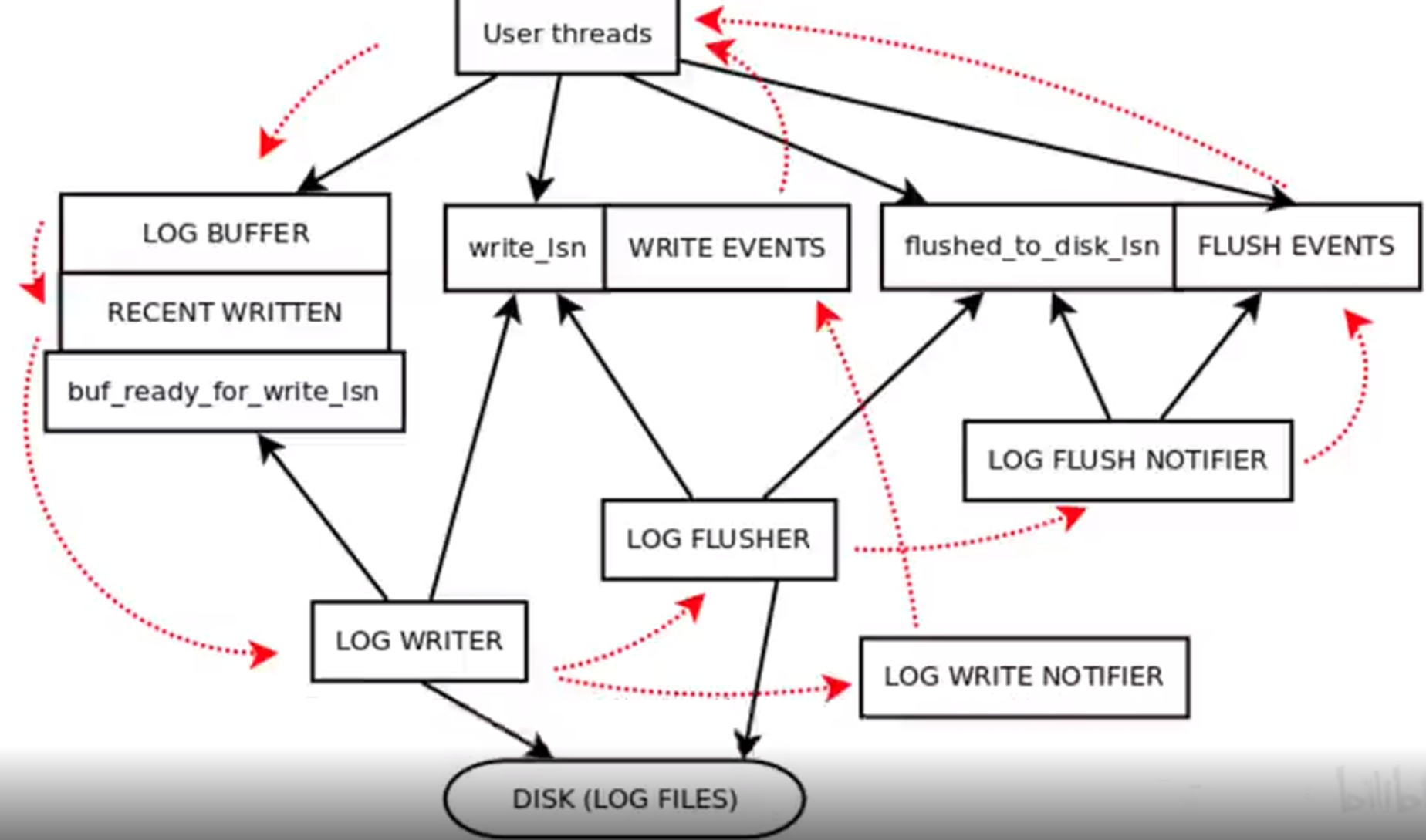
但是 Redo log 它其實有多種刷盤的機制,例如 MySQL 層面,它提供了一個同步的引數,你只要每次事務都操作,都去做一個提交,這個效能可能是比較差的。
但是它還有另外兩種刷盤的機制,它預設有一個 1 秒鐘去重新整理整個核心緩衝區的一個程序,那這個時候你就算事務沒有提交,它也會把緩衝區的這個redolog進行刷盤操作。
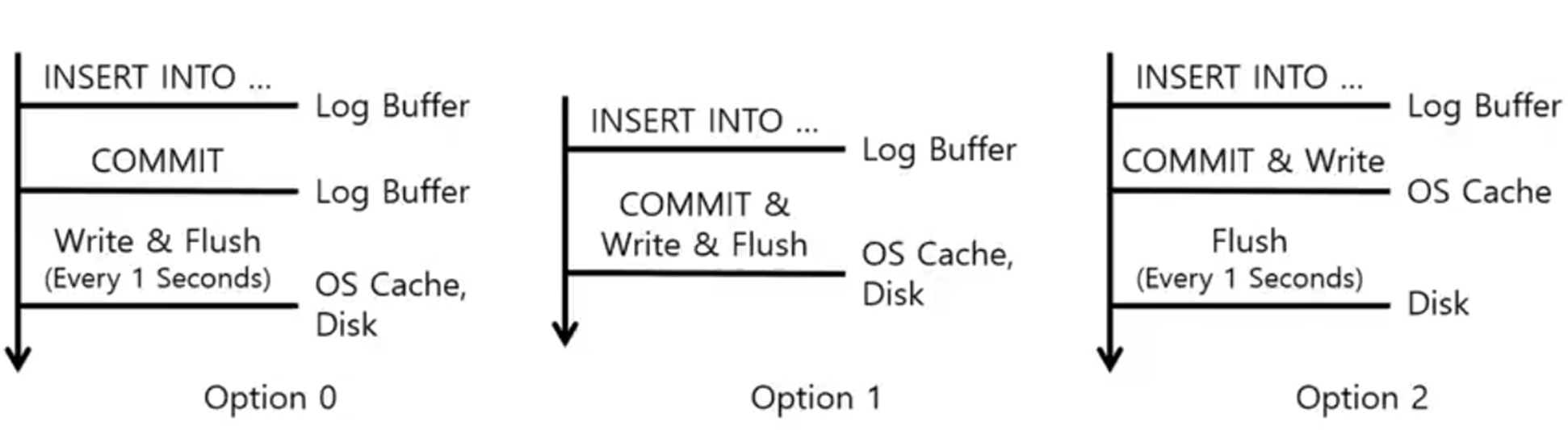
那在這個過程當中,可能事務還沒有提交,那 redolog 已經放在磁碟上了。
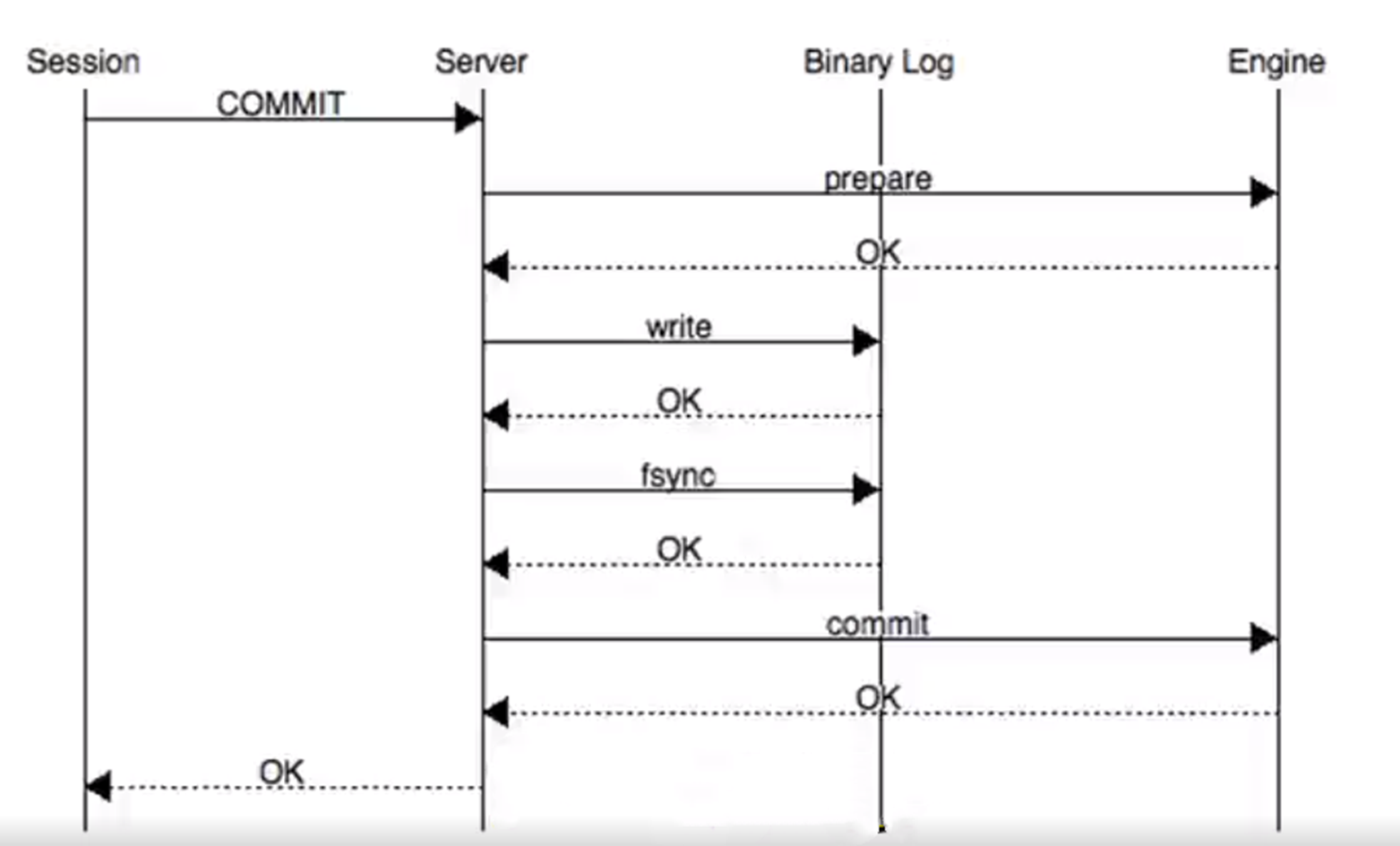
當然有些小夥伴可能會覺得如果這個過程當中斷電了怎麼辦?那會不會有 redolog,然後binlog不一致?這就是 MySQL 它為什麼要去實現一個二階段提交這麼一個過程,這裡時間有限,就不去做過多展開了。
當然不同的 MySQL 它底層的版本引數也會有一些不一樣,比如說它有些可能還是基於你事物提交多少個它就進行一個刷盤,或者中間你可以去設計一個緩衝區,容量達到多少它也會進行一個強制刷盤。
這個在不同的 MySQL 版本之間,它們的預設值,還有這些緩衝區的引數可能都不太一樣。然後這裡很多同學可能就會想,我學這些有什麼用,平時在工作當中又用不上。
怎麼說呢,還是有一定用途的,你會發現這些很多引數基本上都是在可用性跟效能之間去做一個選擇,所以如果你在特定的業務場景下,你確實是可以在資料庫層面去做這麼一些調優。這也是為什麼很多高階的DBA,他必須要去了解一定的業務場景。可能站在開發的角度就覺得 DBA 你只要管好運維就行了,你不用去關心我的業務。那同樣呢,開發其實也可以去基於你的業務場景去反向給 DBA 提供一些建議,可以去調整哪些引數?可能在大部分小夥伴的工作環境下,其實並沒有必要去調整這些東西,你的業務也可以正常的執行,所以大家就沒有學習這些東西的積極性了。
但是我認為作為後端開發,你還是要去了解底層的一些結構的,這些設定的引數名你沒必要去記,但是你至少知道大概有這麼一個東西,然後用的時候你可以快速的去查,然後學到這些東西,你還可以把這種比較好的思想應用在你的專案實際的工作當中,他很多思想跟設計哲學其實是可以借鑑過來的,這也是我們對於技術專家和架構師他需要的一個通用能力。
好,這一期就分享我之前在面試當中問到這幾個資料庫比較複雜的問題,如果大家認為寫的還不錯,也希望大家點贊轉發,沒關注的小夥伴也別忘了關注下,後面就不會錯過很多技術的乾貨了。