從 DMAIC 方法論說起,記一個長連結 bug 的排查全過程

引
本文是我在前端團隊的第四次分享,在過去我曾做過一次關於 bug 排查的全流程的排查分析,檔案:客戶線上反饋:從資訊蒐集到疑難 bug 排查全流程經驗分享,但這個文章更側重我過去幾年的排查經驗,而非方法論,剛好最近一直在做專案質量改進的事,過程依賴了 DMAIC 方法論,後續我也總結了自己的排查方法,其實與這個方法論高度相似。恰好前段時間幫忙解決了一個長連結(websocket)的疑難問題,正好拿這個例子來證明方法論,所以原來的兩個分享,最終合併成了這篇文章,接下來就是分享原文了。
壹 ❀ 為什麼做這次分享?
大家都知道我們從六月開始就一直在做專案質量改進的事情,其實到現在,無論是迭代延期情況還是整體專案缺陷統計情況,我相信大家都多少能感受到我們的質量確實提升了,而且不是錯覺。不知道大家是否好奇質量改進我們到底是怎麼做的,迭代質量同步給大家時我們總是會附帶一些改進點以及在流程中去落實一些東西,這些結論是如何得到?總不能是拍腦袋想到的,其實這個過程就依賴了 DMAIC 方法論。
那麼為什麼要做這次分享?兩個原因:
- 第一是質量改進並不是這一個季度或者這半年的事情,而是未來我們一直要去做的一件事,即便迭代質量在未來得到了很好的改善,我們依舊需要去關注迭代以及工作流中的問題,發現缺陷並改進問題,所以讓大家都知曉方法論以及如何實操就非常重要(而不是面對盲目猜測沒任何依據)
- 第二點是 DMAIC 方法論其實不僅僅適用於流程改進這一個方向,我在之前做過 bug 分享心得的分享,後來我仔細思考了自己排查問題的方法,其實總結下來我的做法也是 DMAIC 的精簡版,這個我在本次分享的後續會順帶一起講。
所以說了這麼多,DMAIC 方法論在系統化解決問題上非常有效,它更像一種抽象經驗的總結,在一些問題解決上讓我們有套路可循,那麼什麼是 DMAIC 方法論呢?我們接著說。
貳 ❀ DMAIC 與迭代質量改進
貳 ❀ 壹 關於 DMAIC 方法論
DMAIC是六西格瑪管理中的五個關鍵步驟,它取自五個單詞的首字母,分別是定義(Define)、測量(Measure)、分析(Analyze)、改進(Improve)和控制(Control)這五個階段,我們分別解釋下五個步驟:
1. D(Define 階段)
Define 階段作為五個步驟的開始其實是非常重要的一步,旨在清晰明確的定義問題和目標。
需要前置讓大家知曉的是,DMAIC 能資料化可測量的幫助我們解決一些長期問題,但它同時需要團隊多方協助才能最終目的。設想下假設我們一開始的定義的目標就模稜兩可並難以衡量,那麼後續的步驟的展開你都會覺得困難,比如同一個目標定義模糊,達到目標的關鍵步驟,設定在團隊共同作業上不同人的理解可能都難達成一致。
除了清晰的問題以及目標定義上,我們還需要定義團隊分工以及不同職責的責任範圍,比如迭代質量宏觀來看好像就是專案質量不好,但問題可能出在研發程式碼質量,可能出在專案上線過於繁瑣,也可能出現在測試流程不完善上,包括現在我們現在所做的迭代資料分析,其中 bug 分佈以及用例通過率的資料統計分析其實都是不同團隊在分工合作。
而對於很多問題,如果我直接告訴你問題本質是什麼,大多數情況下你都知道這個問題怎麼解決,網際網路這麼發達,什麼問題都有解決方案。所以很多事難就難在問題是什麼都不知道,萬事開頭難不是嗎?像我們去排查一些疑難 bug 也是如此,這個後續我會專門講。
(題外話,DMAIC 很依賴團隊配合,包括 bug 問題記得提醒大家去選擇等等,這些都不是我一個人能推動的,都需要藉助大家的力量)
2. M(Measure 階段)
在定義問題或者目標後,我們就需要來到衡量(測量)問題,Measure 階段講究用資料說話,常見的有資料分析,問卷調查等等,依靠資料統計來證實問題,而不是憑空猜測。當然,資料蒐集需要保證資料的真實性以及完整性,所以在目前 bug 型別統計以及分析上,我們才多次要求大家理解不同型別的含義,對應的補全 bug 型別填寫等等。
3. A(Analyze 階段)
Analyze 表示分析階段。資料蒐集後其實大多數情況下我們也只能看到問題的表現而不是本質。比如我們在之前某個迭代發現 web 端很多介面失敗業務提示文案錯誤,展示不對的 bug,這些問題照理說研發在自測階段問題就應該能直接發現,通過資料分析以及對應的溝通獲取資訊,然後我們就得知研發在根據用例自測時,本能的只考慮了邏輯最正確的樣子,而沒有主動去留意功能失敗,介面失敗這些異常情況的表現,這其實是研發思維的通病,所以我們才需要以資料支撐去做分析,找出問題並想辦法解決問題。
4. I(Improve 階段)
承接分析階段,如果我們找出了問題,就應該對應的得出改進建議了,需要注意的是,我們的改進理論上應該是可衡量,可觀測,可驗收的。
還是拿 bug 舉例,比如我們之前發現引數效驗的問題非常多,伺服器端也經常出現介面情況引數不匹配出現的報錯,在分析後我們在web 端統一做了介面效驗的封裝,那麼這個改進在後續我們能直接通過接下來迭代引數效驗問題佔比的情況來衡量此問題是否被有效解決。
5. C(Control 階段)
簡單理解,其實大多數問題並不能短期內直接看到效果以及得到改善,大多數情況下,我們可能需要打持久戰,在保證改進落實的同時,持續改進方案對於問題的改善,以及持續對於方案進行改進,而我們現在做的專案質量改進本質上也是一個長期任務,它並能通過一個迭代的分析來徹底解決,而是需要不斷迭代不斷優化不斷改善以達到最終提升整體專案質量的目的。
貳 ❀ 貳 質量改進如何融入 DAMIC
聊了 DMAIC ,我們來說說目前專案質量改進是如何落實 DMAIC 的。
前提是,我們都知道目前專案質量有一些問題,但是如果讓大家定義專案質量差的問題是什麼,我相信大家其實都很難答出來。因為壞的結果只是結果,而造成如此的原因可能是整個工作流中的任意一環,因為缺乏資料支撐,我們很難精準定義問題,更別說提出改進建議來落實了。
DMAIC 講的就是資料支撐,既然如此,我們就先不定義問題,而是將質量改進分散到半年或者一年的迭代中。我們會分別統計每個迭代的資料,包括測試通過率,bug 型別分佈等等資料,再分析資料定義問題,再根據問題討論出可觀測的解決策略,再為大家做同步。
這會是一個非常長期的過程,很多東西都需要反覆提醒去強化大家的記憶,做流程其實是個非常的痛苦的事,但目前我們正在號召大家一起去落實,而且已經很明顯的看到改善了。
關於目前我們的 DAMIC ,流程基本如下:
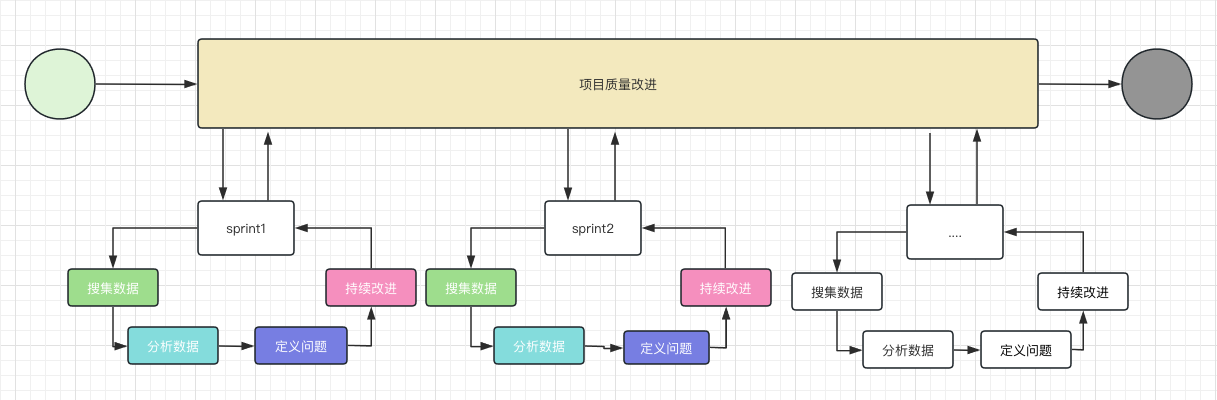
叄 ❀ 現象、原因與問題的定義
我在幾個月前曾分享過我解決問題以及排查問題的思路,與其說是思路,不如說是直接總結了排查問題的一些固有套路,算經驗而非方法論。方法論其實是較為抽象的東西,它有點像概念,目的相同,但不同人落實下去可能做法均有差異。
我在瞭解完 DAMIC 方法後也仔細思考過自己解決 bug 的思維方式,仔細總結下來,我發現我的思維其實就是 DAMIC 的精簡版(所以我說這個方法不僅能用於解決流程之類的罐體),大致做法是 分析現象 --- 定義問題 --- 提出猜想 --- 驗證,如果一個思路錯誤,那就繼續從分析現象開始不斷迴圈直到找到最終真相。
這聽起來很簡單,但事實上大多數研發在看待問題時都會停留在現象這一層,而沒辦法走到問題是什麼這一步,就更別提如何解決了。你可能不知道我在說什麼,我來舉幾個例子。
以專案質量差為例,即便我們將專案問題拆解到一個一個迭代來看,我想問的是,迭代 bug 多以及迭代延期導致專案質量差,這裡的迭代延期以及 bug 多是造成專案質量差的原因嗎?這兩個問題是造成專案質量差的問題所在嗎?
其實不是,準確來說,這兩個問題只是專案質量差的現象,如果我立刻提出改進建議,其實你會有種隔霧看花的感覺,你知道這兩個問題,但真要去做會有點無力。
因此我們統計資料,通過資料支撐來撥開迷霧,與對應的研發溝通,找到延期或者 某種 bug 型別多的原因,從而定義問題。準確來說現象只是發現問題引子,你不能以現象作為依據來定義以及解決問題。
再比如某次上線發版出現事故,當有人問為什麼出現此問題,可能有同學就說這個問題是因為服務部署遺漏了一個服務所導致,我想說的是,遺漏了一個服務是問題所在嗎?它只能代表這一次事故的原因而已,核心問題也許是我們部署流程檔案不完善,缺少了部署檢查的核心資訊,多思考一層也許離問題就更進一步了。
同樣,舉一個研發都非常熟悉的例子,測試給我提的 bug 單描述其實都是現象,原因是什麼,問題是什麼其實很多我們也不清楚,需要去復現去讀程式碼,這些都是為了去定位原因找出問題,知曉了問題所在才知道解決問題的辦法。
那麼現象是毫無用處的嗎?其實並不是,現象是找出問題的觸發器,我就經常通過現象來作為定位問題的靈感,比如一些非常疑***鑽的問題,我都會習慣去對應技術的 GitHub 倉庫 issues 列表或者 Google 問題列表來搜有沒有人遇到我們類似的問題,我這麼做其實就是在通過現象來找現象,如果運氣好你就是能通過現象匹配知道別人對於問題的描述,通過這種辦法我們再來根據自己的現象場景來清晰自己的問題。
再舉個例子,前端時間測試跟我提到音訊播放 option + space 快捷鍵暫停失效了,但是我怎麼都復現不了。測試甚至跟我說音訊分享出去作為分享連結開啟就能快捷鍵暫停,自己不分享暫停就是不行,聽起來撲朔迷離。有同學肯定就已經在思考分享和不分享的區別,這個思路是對的,找差異是解決 bug 非常重要的手段,但問題是這就是完全相同的邏輯,快捷鍵怎麼可能受這個影響,測試給提供的線索可能是他在多種瀏覽器多套環境下混亂記憶的線索。
於是我去 Safari 論壇看了下,根據快捷鍵大致搜了下 issues 清單,發現一年前有人提到過可能跟輸入法可能有關係,我用的是搜過,那麼測試復現問題時用的是什麼瀏覽器以及什麼輸入法呢?於是抱著這個疑問我找到了測試,簡單的對比發現,原來問題只有是在 Safari 瀏覽器以及 mac 自帶輸入法的日語模式下才會有這個問題,如果切到英語就正常,以及如果換瀏覽器或者輸入法也都正常,那這就證明這就是 Safari 加 mac 自帶輸入法日語模式下的快捷鍵 bug,而整個問題下來,我其實用的就是現象去提出猜想,問題是什麼?其實我至今都不知道,也許只有 Safari 自己的開發才知道。
聊了這麼多,我知道這些都顯得很抽象,但我還是在很多問題上不要把現象當成是問題本身,但我也希望你能善於利用現象。
關於現象的利用,正好我在之前幫忙排查了一個非常疑難的長連結連線失敗的問題,接下來藉助方法論,我想通過此問題的排查思路來做個分享。
肆 ❀ 長連結連結失敗排查思路分享
在分享之前,先給大家說下這個 bug 是什麼。我們在長連結推播上依賴了一個 socket.io 的庫(做 websocket 通訊),但從做了紀錄檔監控以來,我們發現一直都有客戶偶現長連結連線失敗的問題,導致功能使用異常,此問題偶現,而且我們自己完全無法復現。
我前面說了,我對於很多問題的排查思路都是 分析現象 --- 定義問題 --- 提出猜想 --- 驗證,使用現象來驅動排查能幫我更快的找到關鍵問題點,現在我有兩個問題問大家的是:
- 第一個問題是,如果讓大家來排查這個問題,大家是否會覺得自己需要非常瞭解 websocket 底層協定,以及瞭解 socket 庫的底層原理呢?事實上我在後續確實淺讀了 socket 的原始碼,但我非常清楚自己需要看什麼,以及關注點在哪,我看原始碼僅僅是驗證自己的猜想以及定義下一步行動,直到最後問題解決,我其實都不知道什麼 websocket 底層原理到底幹了啥。而我在整個排查中,其實就是不斷髮現現象,提出問題以及驗證猜想。
- 第二個問題是,如果現在要讓你讀 socket 原始碼,你怎麼讀?從哪裡開始讀?難道從初始化開始一點點跟?那效率就太低了,而且中間一定會被各種不重要的邏輯影響自己的判斷。
肆 ❀ 壹 分析紀錄檔現象,找到原始碼閱讀切入點
我在接手問題的時候,前端已經開啟了 socket.io 的紀錄檔,我們在 logRocket(一個記錄和replay使用者操作的平臺)上能看到部分失敗使用者的錄屏,以及錄屏控制檯 socket.io 的輸出紀錄檔,雖然都是連結失敗的紀錄檔提示。我們在自己的環境控制檯也能看到 socket.io 的紀錄檔,只是我們無法復現問題,所以看到的控制檯紀錄檔都是成功的。
在看原始碼前,我的第一個關注點是 socket.io 連結成功和連結失敗的紀錄檔區別在哪裡,紀錄檔有沒有共同點,比如紀錄檔是否相同,是否初始化就出了問題,還是初始化完全相同,是在後續執行產生了差異。差異是在哪一步產生的,那麼這個點就是我原始碼閱讀的切入點,只要從這裡開始去讀一讀原始碼上下文,理解起來就非常高了(關注完全相同的紀錄檔沒意義,它又沒出問題),這就是對於問題現象的利用。
除此對比紀錄檔之外,我還去查閱了socket.io-client 與 engine.io-client 兩個 GitHub 倉庫的 issue 列表,看看有沒有類似歷史 issue 可以參考,目的前面說過了,看看是否有跟我們現象匹配的問題,以及從別人的提問中去拓展自己對於問題的看法和思路。
在看完 GitHub 倉庫的 issue 後,看下來只有兩條與無限重試但一直連結失敗的問題有關,這個使用者的 issue 的 socket.io 版本是 4.X,問題描述跟我們不太相同,不過 issue 中表示有 ping 超時的情況導致無法連線,我檢視了我們這邊關於 ping 的時間設定,分別為 "pingTimeout":60000,"pingInterval":25000 ,所以後續我找伺服器端確認了我們超時的時間情況,後續證明跟這塊肯定沒關係,所以這個點直接排除了。
而關於成功和失敗的紀錄檔對比我們可以看看下圖
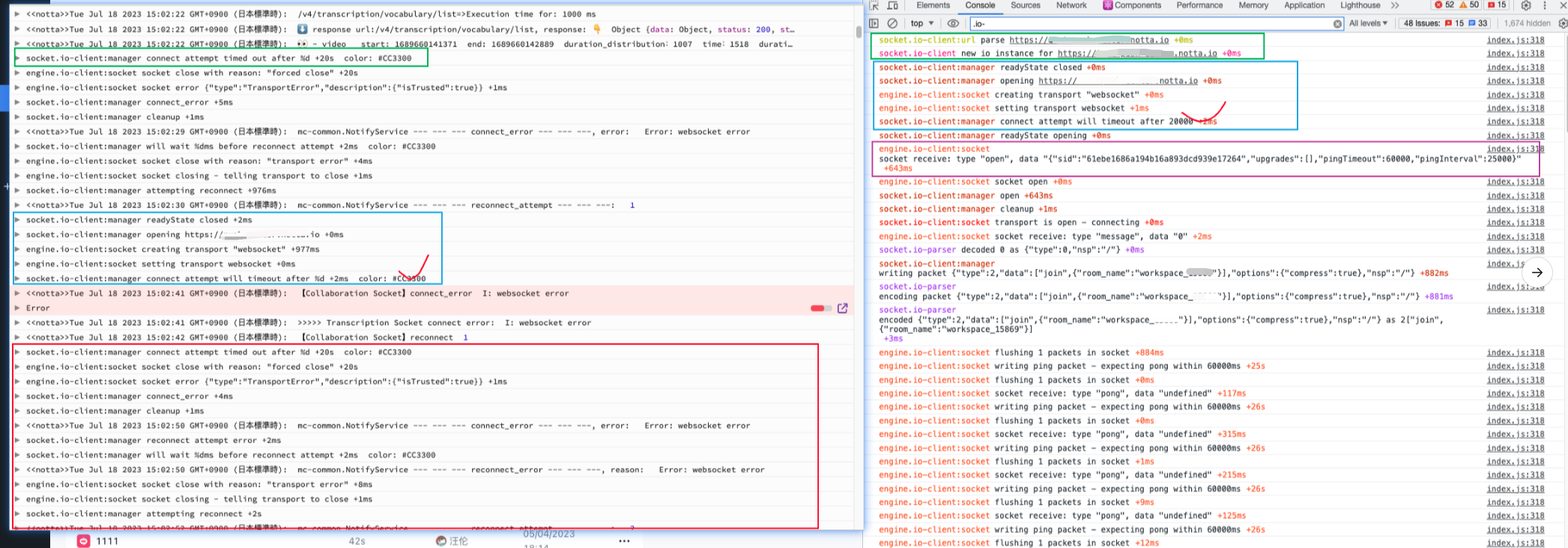
右邊是成功的紀錄檔資訊,左邊是 logRocket 某個使用者失敗的資訊,我們可以關注這幾點:
-
兩邊都是以綠色框作為整個 socket 紀錄檔記錄的開始,比較奇怪的是左邊綠框相對於右邊綠框,它缺少了
socket.io-client:url parse https://xxx.notta.io與socket.io-client new io instance for ``https://xxx.notta.io這兩步,我問了相關同學,他說 logRocket 記錄的可能不全,後面補全了紀錄檔,但是控制檯輸出的還是不全,那麼這裡到底是 logRocket 紀錄檔缺失?還是前端少了幾個步驟導致連線失敗?(後續確認就是 logRocket 紀錄檔自己丟了) -
兩邊紀錄檔的共同點在藍色框區域,可以發現都存在
readyState的關閉,開啟一個連結,建立和設定transport "websocket",然後在五步後差異來了(紅色打勾處),左邊通知多少毫秒後即將超時,但是右邊通知多少毫秒後即將連結,這裡的差異是什麼,為什麼一個即將成功,另一個即將失敗,原始碼層我會跟一下這兩處的程式碼執行。 -
如果連結成功,伺服器端一定會推播一條
{"sid":"71416fef44354581af6837df95b15bbe","upgrades":[],"pingTimeout":60000,"pingInterval":25000}的資料過來,這裡可以看上圖右邊紫色方框區域,以及 websocket 通訊原生的截圖,那麼我對於伺服器端就有幾個問題 :
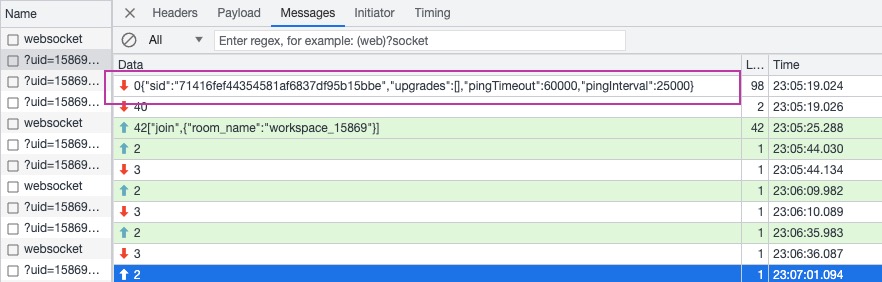
-
伺服器端真的有收到使用者端的通知嗎?(因為 logRocket 失敗紀錄檔開頭有幾條缺失,伺服器端能否確認有沒有接收到)
-
伺服器端能對比成功和失敗情況下伺服器端接收的步驟差異嗎,知曉了步驟差異,可能才好決定接下來的動作。
-
伺服器端真的有返回上面這條資料回來嗎?或者說伺服器端有走到返回資料
"sid":"61ebe1686a194b16a893dcd939e17264","upgrades...這一步嗎?
-
-
關於其它的驗證,我在 logRocket 紀錄檔中看到了一條
ResizeObserver loop limit exceeded的報錯,處於好奇我去搜了下,在一些問題記錄中我發現了 loom 外掛的字眼,而 loom 業務也是做音視訊錄製,所以突發奇想,會不會我們的客戶也安裝了其它類似競品的外掛,偶現導致我們部分業務崩潰,然後我嘗試安裝了 loom 外掛,不過驗證失敗了,連線還是能成功,此問題在後續確認是其它的報錯,可以排除。
除此之外,有幾點我之前的排查會議沒參加,有其它的幾點我也比較關注,比如:
-
socket 前後端版本是否完全一致?是否是因為前後端版本不相容才導致的偶現問題?(次猜測後續確認版本匹配)
-
連結失敗的問題是一直存在的嗎?還是在某個時期或者某個迭代突然出現的?如果能找到這個時間節點,我們就能通過需求改動來縮小範圍,逐步確定可能造成的影響的功能。(此猜測後續確認問題一直存在,可以說是一個歷史問題)
-
如果是前者,那可能跟我們前後端實現有關係,或者是版本的特定 bug。
-
如果是後者,這個時期我們有什麼變數?改了什麼業務沒?
-
肆 ❀ 貳 根據切入點梳理原始碼,尋找問題點
因為上次已經對比了兩份紀錄檔的差異,還是看下圖。
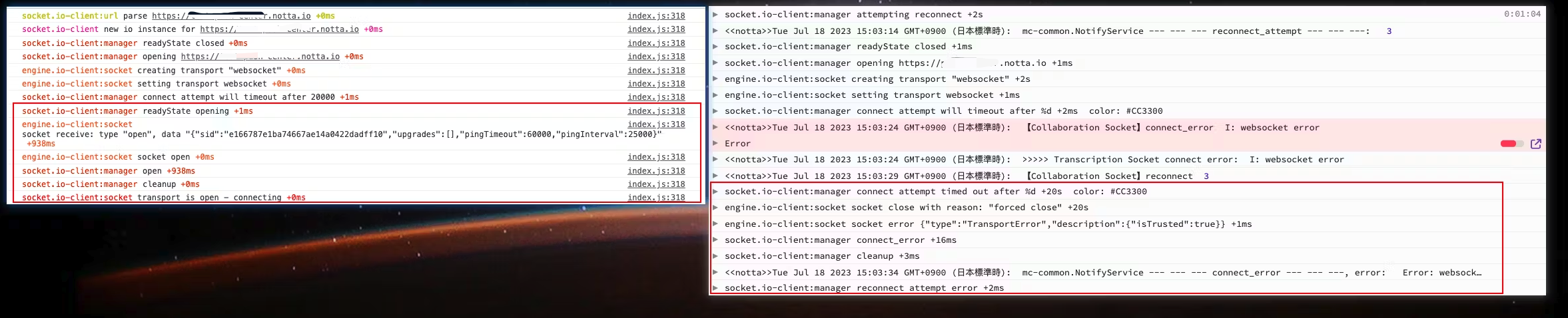
左邊是直接一次連線成功,右邊是經歷失敗後的重新連線,在紅框之前其實兩邊的行為完全一致,直到來到 socket.io-client:manager connect attempt will timeout after 這一句之後,兩邊產生了差異,成功的一邊提示
readyState opening,而失敗紀錄檔提示 20S 都未連線成功因此超時,差異點在這裡,所以原始碼切入點也就從這裡開始,socket.io-client 與 engine.io-client 的原始碼邏輯相關程式碼如下:
// 紀錄檔輸出 debug 字首定義
var debug = require('debug')('socket.io-client:manager');
// 初次連線或者失敗後重連走的都是同一個方法,方便梳理,刪除了部分不影響理解的程式碼
Manager.prototype.open =
Manager.prototype.connect = function (fn, opts) {
// 這裡對應紀錄檔 socket.io-client:manager readyState closed,this.readyState 預設值就是 false
debug('readyState %s', this.readyState);
// 這裡對應紀錄檔 socket.io-client:manager opening https://test-push-center.notta.io
debug('opening %s', this.uri);
// 開始連線,因此 readyState 設定為 opening
this.readyState = 'opening';
// socket 連線成功的監聽
var openSub = on(socket, 'open', function () {
// 執行具體的 open 方法
self.onopen();
fn && fn();
});
// socket 連線失敗的監聽
var errorSub = on(socket, 'error', function (data) {
// 這裡對應紀錄檔 socket.io-client:manager connect_error
debug('connect_error');
//
self.cleanup();
// 重置 readyState 狀態
self.readyState = 'closed';
self.emitAll('connect_error', data);
});
// 定時器核心邏輯
if (false !== this._timeout) {
var timeout = this._timeout;
// 這裡對應紀錄檔 socket.io-client:manager connect attempt will timeout after %d +2ms
debug('connect attempt will timeout after %d', timeout);
// 定義定時器
var timer = setTimeout(function () {
// 這裡對應紀錄檔 socket.io-client:manager connect attempt timed out after %d +20s
debug('connect attempt timed out after %d', timeout);
// 派發事件,socket 連線失敗的監聽被觸發
socket.emit('error', 'timeout');
}, timeout);
this.subs.push({
// 為定時器新增銷燬方法
destroy: function () {
clearTimeout(timer);
}
});
}
上述程式碼我按照 debug 紀錄檔補充了註釋,我們關注的超時的紀錄檔輸出其實就在 var timer = setTimeout 這個定時器裡,且在this.subs.push中還提前定義了一個定時器銷燬方法,定時器時間預設 20s 。
也就是說,一旦我們呼叫 connect 或者重連的 open 方法,這個方法內部都會內建一個超時報錯定時器,只要等待 timeout 定時器沒被主動銷燬那就會報錯,而現在生產環境的情況其實就是不斷嘗試 connect,不斷等待 20S 超時然後報錯。
在定時器上方,同時定義了一個 connect 連線成功的監聽 var openSub = on 與連線失敗的監聽var errorSub = on,這兩個方法內部都有呼叫一個cleanup方法,其實在這裡裡面就包含了清除定時器的邏輯,簡而言之,只要成功了,socket 會主動清除報錯定時器,這也是兩邊差異的原因。
關於cleanup的定義:
Manager.prototype.cleanup = function () {
// 這裡對應紀錄檔 socket.io-client:manager cleanup
debug('cleanup');
var subsLength = this.subs.length;
for (var i = 0; i < subsLength; i++) {
// 取出之前定義的定時器銷燬方法
var sub = this.subs.shift();
// 銷燬定時器
sub.destroy();
}
};
那麼現在問題就聚焦到了,什麼情況下由哪裡派發成功的監聽,來清除定時器以及處理接下來的連線邏輯呢?我們再聚焦到如下程式碼:
// 響應伺服器端推播的封包所執行的方法
Socket.prototype.onPacket = function (packet) {
if ('opening' === this.readyState || 'open' === this.readyState ||
'closing' === this.readyState) {
// 這裡對應關鍵紀錄檔 engine.io-client:socket socket receive: type "open", data "{"sid":"e166787e1ba74667ae14a0422dadff10","upgrades":[],"pingTimeout":60000,"pingInterval":25000}"
debug('socket receive: type "%s", data "%s"', packet.type, packet.data);
this.emit('packet', packet);
// 心跳監聽的派發
this.emit('heartbeat');
// 昨天我說了,使用者端需要響應一條資料,其中就包含了一個 type 欄位,這個欄位直接決定是建立連線,還是保持心跳,或者報錯
switch (packet.type) {
// 開始連線的派發
case 'open':
this.onHandshake(JSON.parse(packet.data));
break;
// 心跳的派發
case 'pong':
this.setPing();
this.emit('pong');
break;
// 報錯的處理
case 'error':
var err = new Error('server error');
err.code = packet.data;
this.onError(err);
break;
case 'message':
this.emit('data', packet.data);
this.emit('message', packet.data);
break;
}
}
};
上面我說了,如果想連線成功,伺服器端必須推播一條{"sid":"324690113e864a68b0709bbb06f25d9e","upgrades":[],"pingTimeout":60000,"pingInterval":25000}資料過來,它同時對應了關鍵紀錄檔 engine.io-client:socket socket receive: type "open", data "{"sid":"e166787e1ba74667ae14a0422dadff10","upgrades":[],"pingTimeout":60000,"pingInterval":25000}"
在這條紀錄檔中有一個非常重要的欄位 type,這將決定此時跟使用者端的通訊是建立連線還是保持心跳,亦或者報錯或者訊息通知。
但目前我在 logRocket 的失敗紀錄檔中,沒找到這條資訊的推播,因此使用者端沒辦法走到上面程式碼中的open操作,自然沒辦法連線成功了,以及 websocket 的["join",{"room_name":"workspace_15869"}]也沒辦法推播到伺服器端了。
後續我與伺服器端確認了當前可觀察的紀錄檔,由於安全問題,目前生產並未新增 info 紀錄檔列印,所以我們也沒有這塊的紀錄檔,並不知道是以下哪種情況下:
{"sid":"324690113e864a68b0709bbb06f25d9e","upgrades這條關鍵資料伺服器端是否未推播?- 伺服器端有推播,但是
type型別並不是open? - 伺服器端有推播且
type是open,但使用者端與伺服器端協定不一致導致並未成功接收? - 或者其它原因.....
之後為了方便伺服器端打紀錄檔,我查閱了伺服器端 socket 庫的原始碼,確定了跟使用者端 open 通訊的程式碼塊。
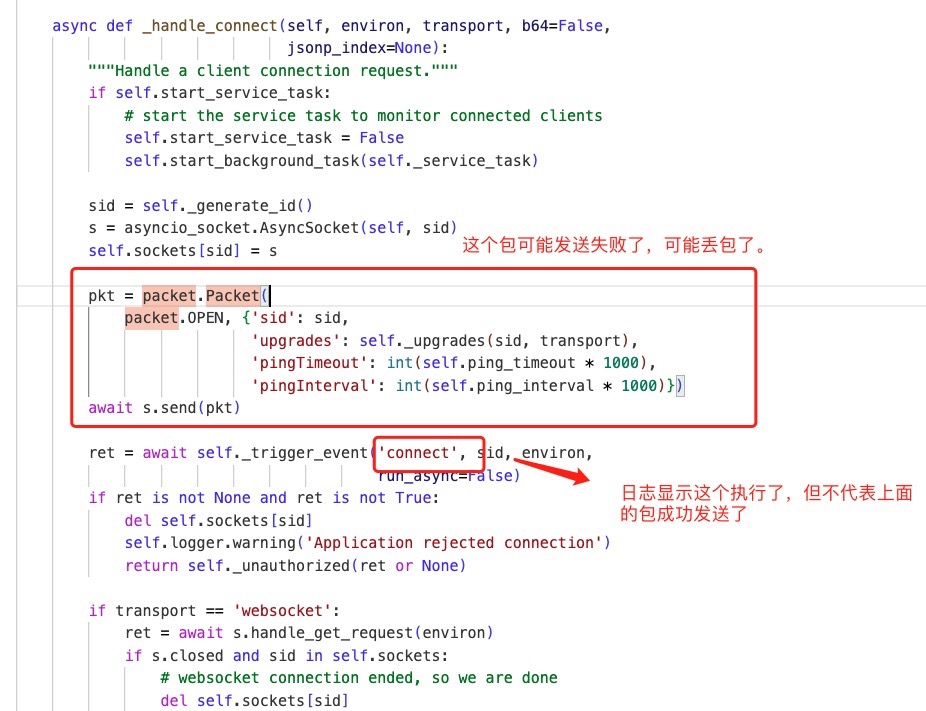
在此之前,伺服器端曾說他們看到紀錄檔中出現了connect欄位,所以覺得是連上了,但是程式碼看下來,我們真正關心的是上圖 connect 上面的 packet.OPEN,這個直接決定了給使用者端的包到底有沒有發,以及型別發的對不對。
那麼到這裡排查接力就來到了伺服器端,之後伺服器端也針對我的提問提出了猜想以及下一步紀錄檔驗證計劃:
- 關於使用者端沒有觸發傳送open包,伺服器端也可以通過跟蹤
"Sending packet OPEN data"紀錄檔觀察確定,等待info紀錄檔上線可以確定。 - 關於伺服器端傳送的open包沒有送達使用者端,get 請求到達伺服器端,伺服器端會先給使用者端傳送一個open包的推播資訊。伺服器端傳送包是通過寫到訊息佇列裡面,這裡會列印傳送資訊紀錄檔,訊息佇列的資料通過長輪訓的方式給到使用者端,查了下長輪訓不能完成保證這裡的訊息包送達使用者端。接著伺服器端會有一個非同步等待前端 ping 包的任務,當收到這個包後才會真正切換協定,並列印升級成websocket協定成功紀錄檔。
之後伺服器端在紀錄檔補充後也證明了 packet.OPEN 確實沒發給使用者端。
既然伺服器端發包失敗,那麼此刻我們的關注點自然要聚焦到連線更上方的部分,比如 websocket 初始化建立時是否就出現了問題,之後伺服器端留意到初始化建立連線時,失敗的紀錄檔中請求nginx返回 400 連線失敗,而正常情況下,如果 websocket 建立成功伺服器端應該返回 101 狀態碼,那說明可能在最初的握手就出現了問題。
很巧的是我想起來我在 socket.io 的 issues 列表中有看到過因為 nginx 設定問題導致的 websocket 連線 400 的問題,於是伺服器端同學去確認了設定,最終結論也是確定沒問題,畢竟設定同一份程式碼也基本沒人會改動。
大家都知道請求 400 還可能跟請求引數,請求頭請求體不匹配有關係,於是伺服器端同學又仔細對比了成功和失敗情況下的請求頭,最終發現連線失敗下的請求頭部分資訊丟失了,但需要說明的是這絕對不是我們業務本身的行為,而是跟使用者的環境或者防火牆有關係,其實排查到這裡原因就定位出來了,但是我們很難干預,最後我們決定考慮降級 http 長輪訓來緩解此問題。
肆 ❀ 叄 如何解決?降級策略還是升級策略
我在排查此問題之前,其實就已經知道 socket.io 支援降級策略,比如 websocket 連線失敗無法使用,那就降級到 http 長輪訓來保證業務,而且這個庫本身就支援這一點。有同學可能就會想,排查這麼久還是走降級,那為啥不一開始直接上降級呢?其實有幾個原因在裡面:
- 如果要做長連線且雙向通訊,websocket 相對長輪訓有著極大的優勢,我們肯定希望排查出問題並解決問題且繼續採用最優解。
- Websocket 的通訊壓力相對於長輪訓要小很多,在使用者量較大的情況下冒然降級可能對伺服器造成過大壓力。
- 在排查問題之前我們並不知道根本原因是什麼,也許就是單純用法的不對呢?這種情況下降級不一定能處理,反而有種無頭蒼蠅的感覺。(結合上面說的伺服器壓力)。
所以最終採用長輪訓兜底是我們確定了原因之後的一種兜底手段,不然客戶防火牆之類的干預 websoket 連結,我們毫無辦法。且在之後我們也專門做了長訓練的壓測,考慮到目前並不是非常大的使用者量會遇到此問題,即便他們全部長輪訓,目前伺服器也頂得住,所以我們決定採用長輪訓兜底。
那麼問題來了,我們做降級策略怎麼做?websocket 連線超時一次預設是20S,我們 retry 幾次後降呢?如果設定 5 次,也就是說使用者接近要等待 100s 才能觸發降級策略,那假設這個過程中使用者重新整理了頁面,那就又要重走 retry,導致使用者永遠都進入不到降級了。
改連線等待時間?20S 是 socket.io 預設值肯定是有原因的,考慮到使用者網路不好的情況,假設你設定的太短,本來能用 websocket 的全因為這個原因走到了 http 長輪訓,那伺服器不是被迫抗壓。
其實考慮下來,我們走的其實不是 socket 的降級,而是預設的升級策略,socket 官網有這樣一段描述(官網也提到了 websocket 雖然好用,但是防火牆,防毒軟體都會造成連不上....):

如果採用預設策略(升級策略),socket 會預設先試用http長輪詢保證業務,之後就會立刻嘗試升級 websocket ,如果升級成功就立馬暫停終止長輪訓並切換到 websocket,否則繼續使用長輪訓保證正常連線,這樣使用者確實無感升級過程,而業務也始終是可用的了。
下圖是走升級策略後的紀錄檔,可以很清楚的看到從長輪訓到 websocket 的升級過程。
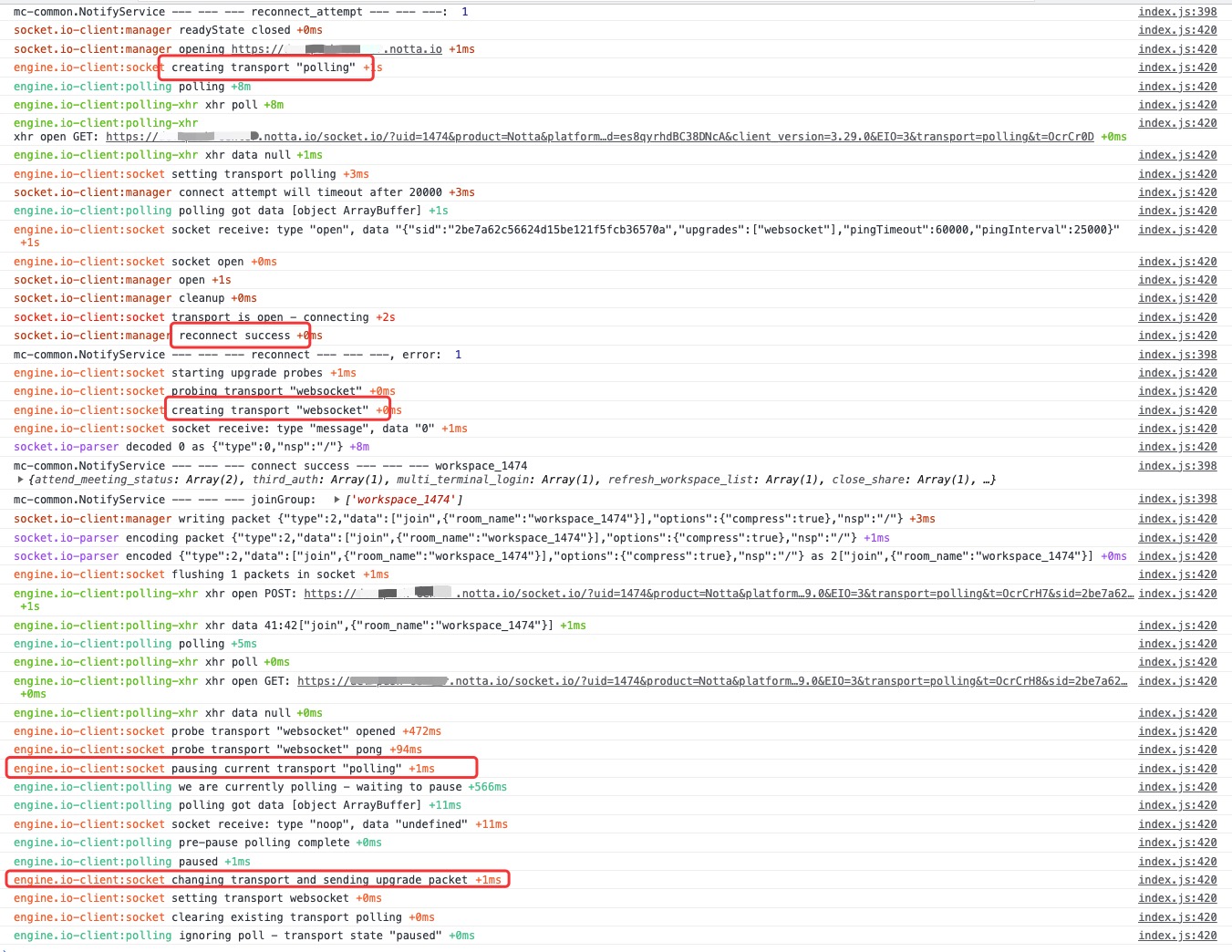
至於為什麼業務底層封裝寫死了 socket 只能用 websocket 模式進行連線,歷史原因也沒辦法追溯了。
在經歷了壓測以及灰度測試後,我們通過紀錄檔觀察也證明了之前 sentry 記錄無法使用業務的使用者現在業務均正常,在之後上生產後,sentry 的上報統計工作日數量對比已經直線下降了,而 sentry 還存在的上報我們也挑了數十位使用者去查了對應紀錄檔,發現均正常使用,這些上報更多是嘗試升級 websocket 失敗的上報。(以前用不了 websocket 的現在還是用不了,但起碼業務能跑了)
那麼到這裡,此問題完美解決,其實整個排查下來,我確實依舊不知道 socket 咋用,我也不知道它封裝到底做了什麼,甚至連官網檔案我也只是粗略看了幾眼,然後發現了上面升級策略的說明。
但整個排查思路,大家應該能感受到是非常清晰的,不斷利用線上來提出猜想,定義下一步計劃並驗證,非常順利一步步接近真相,這就是我想表達利用現象來發現問題,如果知道問題是什麼,自然知道下一步動作是什麼,難的是發現問題,要學會分析現象。
那麼接下來是提問環節。