Ascend C保姆級教學:我的第一份Ascend C程式碼
本文分享自華為雲社群《Ascend C保姆級教學:我的第一份Ascend C程式碼》,作者:昇騰CANN 。
Ascend C是昇騰AI異構計算架構CANN針對運算元開發場景推出的程式語言,原生支援C和C++標準規範,最大化匹配使用者開發習慣;通過多層介面抽象、自動平行計算、孿生偵錯等關鍵技術,極大提高運算元開發效率,助力AI開發者低成本完成運算元開發和模型調優部署。
本文提供Ascend C保姆級教學,從一個簡單的範例出發,帶你體驗Ascend C運算元開發的基本流程。
完成範例開發之前,需要先了解一些必備的背景知識。
1. 背景知識
- 多核並行
使用Ascend C開發的運算元執行在AI Core上,AI Core是昇騰NPU硬體平臺的計算核心,NPU內部有多個AI Core。Ascend C程式設計過程中會將需要處理的資料拆分同時在多個AI Core上執行,從而獲取更高的效能。多個AI Core共用相同的指令程式碼,每個核上的執行範例唯一的區別是block_idx不同,開發者只需要關注單核上的處理程式,也就是核函數。
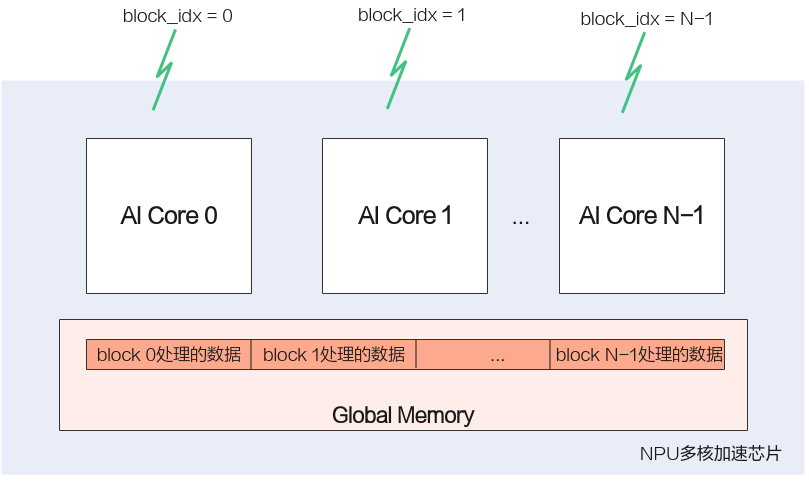
- 流水並行
上文提到,開發者只需要關注單核處理程式(核函數),那麼如何實現核函數的具體邏輯呢?Ascend C提供流水線式的程式設計正規化,基於程式設計正規化可以快速搭建運算元實現的程式碼框架,實現流水並行。
流水線並行的概念和工業生產中的流水線是類似的,任務1完成對某片資料的處理後,將其加入到通訊佇列,任務2空閒時就會從佇列中取出資料繼續處理;可以類比為生產流水線中的工人只完成某一項固定工序,完成後就交由下一項工序負責人繼續處理。
Ascend C程式設計正規化是一種流水線式的程式設計正規化,把運算元核內的處理程式,分成多個流水任務:「搬入、計算、搬出」,通過佇列(Queue)完成任務間通訊和同步,並通過統一的記憶體管理模組(Pipe)管理任務間通訊記憶體。開發者只需聚焦實現「搬入、計算、搬出」內容。
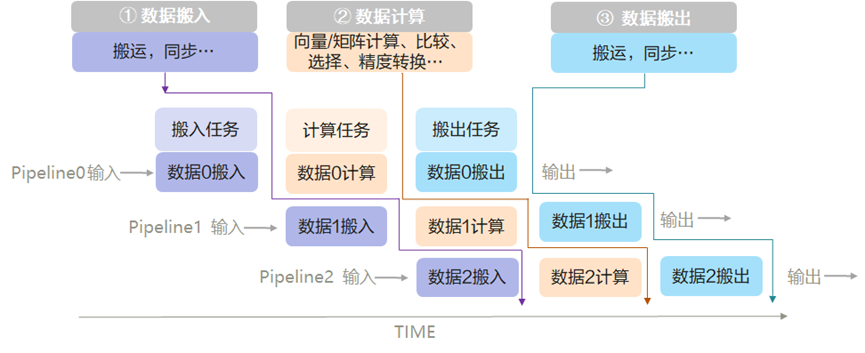
- 孿生偵錯
基於NPU域運算元的呼叫介面編寫程式,通過畢昇編譯器編譯後執行,可以完成運算元NPU域的執行驗證;基於CPU域運算元的呼叫介面編寫程式,通過標準的GCC編譯器進行編譯後執行,並通過GDB通用偵錯工具進行單步偵錯,精準驗證程式執行流程是否符合預期。孿生偵錯的能力,大大提升了運算元的偵錯效率。下文的範例開發,僅介紹核函數CPU側和NPU側的執行驗證,具體的偵錯步驟將會在後續的文章中詳細介紹。
2. 開發流程
本文將引導你完成以下任務,體驗Ascend C運算元開發的基本流程。
- 使用Ascend C完成Add運算元核函數開發;
- 使用ICPU_RUN_KF CPU調測宏完成運算元核函數CPU側執行驗證;
- 使用<<<>>>核心呼叫符完成運算元核函數NPU側執行驗證。
在正式的開發之前,還需要先完成環境準備和運算元分析工作,開發Ascend C運算元的基本流程如下圖所示:
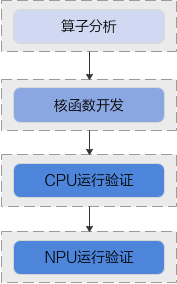
參考本文進行開發之前請先獲取樣例程式碼目錄quick-start,該樣例程式碼只保留了部分程式碼框架,核心程式碼在下文的指導步驟中體現。您可以在閱讀本文時,將指導步驟中的程式碼拷貝至對應位置,即可快速完成Ascend C運算元的開發。
3. 環境準備
- CANN軟體安裝
開發運算元前,需要先準備好開發環境和執行環境,開發環境和執行環境的介紹和具體的安裝步驟可參見昇騰社群檔案的CANN軟體安裝指南。
- 環境變數設定
安裝CANN軟體後,使用CANN執行使用者編譯、執行時,需要以CANN執行使用者登入環境,執行source ${install_path}/set_env.sh命令設定環境變數,其中${install_path}為CANN軟體的安裝目錄。
4. 運算元分析
主要分析運算元的數學表示式、輸入、輸出以及計算邏輯的實現,明確需要呼叫的Ascend C介面。
1. 明確運算元的數學表示式及計算邏輯。
Add運算元的數學表示式為:
z = x + y
計算邏輯是:要完成AI Core上的資料計算,輸入資料需要先從外部儲存Global Memory搬運進AI Core的內部儲存Local Memory,然後使用計算介面完成兩個輸入引數相加,得到最終結果,再搬出到外部儲存Global Memory上。
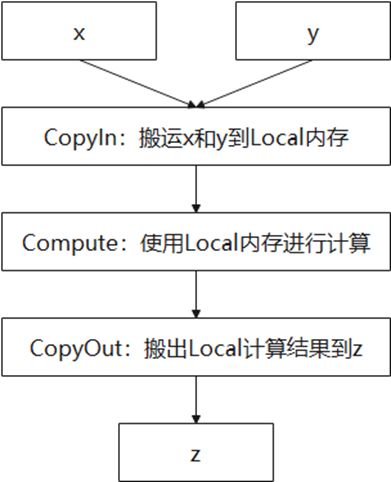
2. 明確輸入和輸出。
- Add運算元有兩個輸入:x與y,輸出為z。
- 本樣例中運算元的輸入支援的資料型別為half(float16),運算元輸出的資料型別與輸入資料型別相同。
- 運算元輸入支援shape(8,2048),輸出shape與輸入shape相同。
- 運算元輸入支援的format為:ND。
3. 確定核函數名稱和引數。
- 您可以自定義核函數名稱,本樣例中核函數命名為add_custom。
- 根據對運算元輸入輸出的分析,確定核函數有3個引數x,y,z;x,y為輸入在Global Memory上的記憶體地址,z為輸出在Global Memory上的記憶體地址。
- 確定運算元實現所需介面。
- 實現涉及外部儲存和內部儲存間的資料搬運,檢視Ascend C API參考中的資料搬移介面,需要使用DataCopy來實現資料搬移。
- 本樣例只涉及向量計算的加法操作,檢視Ascend C API參考中的向量計算介面,初步分析可使用雙目指令Add介面實現x+y。
- 計算中使用到的Tensor資料結構(資料操作的基礎資料結構),使用AllocTensor、FreeTensor進行申請和釋放。
- 並行流水任務之間使用Queue佇列完成通訊和同步,會使用到EnQue、DeQue等介面。
通過以上分析,得到Ascend C Add運算元的設計規格如下:
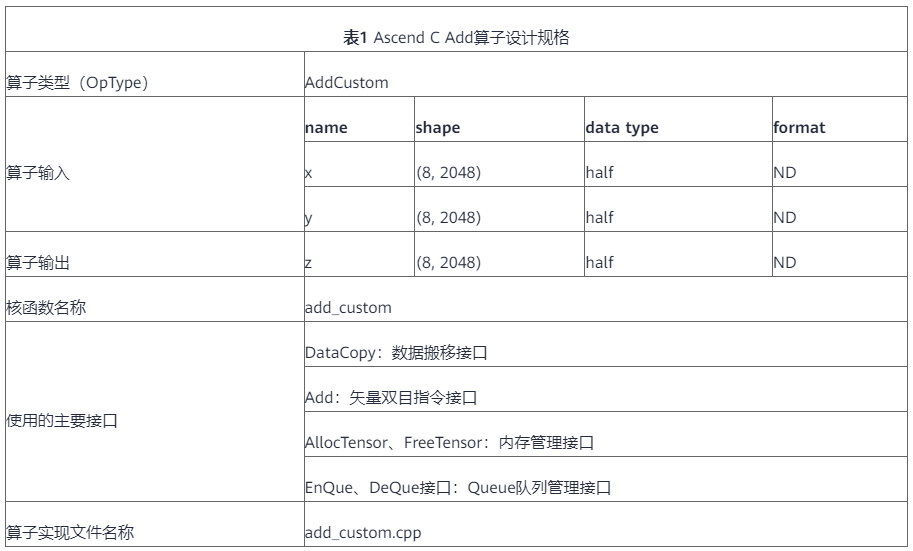
5 核函數開發
完成環境準備和初步的運算元分析後,即可開始Ascend C核函數的開發。開發之前請先獲取樣例程式碼目錄quick-start,以下核函數開發的樣例程式碼在add_custom.cpp中實現。
本樣例中使用多核平行計算,即把資料進行分片,分配到多個核上進行處理。Ascend C核函數是在一個核上的處理常式,所以只處理部分資料。分配方案是:資料整體長度TOTAL_LENGTH為8* 2048,平均分配到8個核上執行,每個核上處理的資料大小BLOCK_LENGTH為2048。下文的核函數,只關注長度為BLOCK_LENGTH的資料應該如何處理。
5.1 核函數的定義
進行核函數的定義,並在核函數中呼叫運算元類的Init和Process函數。請將下文程式碼新增至add_custom.cpp的「核函數實現」註釋處。
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z) { KernelAdd op; op.Init(x, y, z); op.Process(); }
1. 使用__global__函數型別限定符來標識它是一個核函數,可以被<<<...>>>呼叫;使用__aicore__函數型別限定符來標識該核函數在裝置端AI Core上執行。指標入參變數需要增加變數型別限定符__gm__,表明該指標變數指向Global Memory上某處記憶體地址為了統一表達,使用GM_ADDR宏來修飾入參,GM_ADDR宏定義如下:
#define GM_ADDR __gm__ uint8_t* __restrict__
2. 運算元類的Init函數,完成記憶體初始化相關工作,Process函數完成運算元實現的核心邏輯。
5.2 運算元類定義
本樣例中定義KernelAdd運算元類,其具體成員如下。請將下文程式碼新增至add_custom.cpp的「運算元類實現」註釋處。
class KernelAdd { public: __aicore__ inline KernelAdd(){} // 初始化函數,完成記憶體初始化相關操作 __aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z){} // 核心處理常式,實現運算元邏輯,呼叫私有成員函數CopyIn、Compute、CopyOut完成向量運算元的三級流水操作 __aicore__ inline void Process(){} private: // 搬入函數,完成CopyIn階段的處理,被核心Process函數呼叫 __aicore__ inline void CopyIn(int32_t progress){} // 計算函數,完成Compute階段的處理,被核心Process函數呼叫 __aicore__ inline void Compute(int32_t progress){} // 搬出函數,完成CopyOut階段的處理,被核心Process函數呼叫 __aicore__ inline void CopyOut(int32_t progress){} private: TPipe pipe; //Pipe記憶體管理物件 TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; //輸入資料Queue佇列管理物件,QuePosition為VECIN TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ; //輸出資料Queue佇列管理物件,QuePosition為VECOUT GlobalTensor<half> xGm, yGm, zGm; //管理輸入輸出Global Memory記憶體地址的物件,其中xGm, yGm為輸入,zGm為輸出 };
內部函數的呼叫關係示意圖如下:
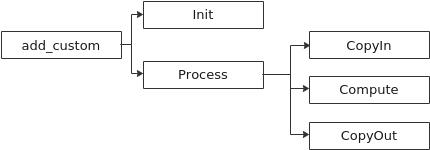
由此可見除了Init函數完成初始化外,Process中完成了對流水任務:「搬入、計算、搬出」的呼叫,開發者可以重點關注三個流水任務的實現。
5.3 Init 函數實現
初始化函數Init主要完成以下內容:設定輸入輸出Global Tensor的Global Memory記憶體地址,通過Pipe記憶體管理物件為輸入輸出Queue分配記憶體。
上文我們介紹到,本樣例將資料切分成8塊,平均分配到8個核上執行,每個核上處理的資料大小BLOCK_LENGTH為2048。那麼我們是如何實現這種切分的呢?
每個核上處理的資料地址需要在起始地址上增加GetBlockIdx()*BLOCK_LENGTH(每個block處理的資料長度)的偏移來獲取。這樣也就實現了多核平行計算的資料切分。
以輸入x為例,x + BLOCK_LENGTH * GetBlockIdx()即為單核處理程式中x在Global Memory上的記憶體偏移地址,獲取偏移地址後,使用GlobalTensor類的SetGlobalBuffer介面設定該核上Global Memory的起始地址以及長度。具體示意圖如下。
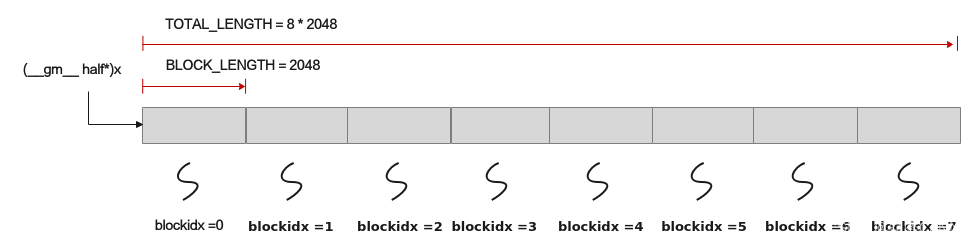
上面已經實現了多核資料的切分,那麼單核上的處理資料如何進行切分?
對於單核上的處理資料,可以進行資料切塊(Tiling),在本範例中,僅作為參考,將資料切分成8塊(並不意味著8塊就是效能最優)。切分後的每個資料塊再次切分成2塊,即可開啟double buffer,實現流水線之間的並行。
這樣單核上的資料(2048個數)被切分成16塊,每塊TILE_LENGTH(128)個資料。Pipe為inQueueX分配了兩塊大小為TILE_LENGTH * sizeof(half)個位元組的記憶體塊,每個記憶體塊能容納TILE_LENGTH(128)個half型別資料。資料切分示意圖如下。

具體的初始化函數程式碼如下:
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z) { // 多核並行,設定當前核上Global Memory的起始地址以及長度 xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); // 通過pipe為queue分配記憶體,單位為Bytes pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half)); pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half)); pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half)); }
5.4 核心處理常式實現
基於向量程式設計正規化,將核函數的實現分為3個基本任務:CopyIn,Compute,CopyOut。任務之間通過佇列進行通訊,互動示意圖如下:
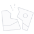
Process函數中通過如下方式呼叫這三個函數。
__aicore__ inline void Process() { // 開啟double buffer後迴圈次數需要乘以2 constexpr int32_t loopCount = TILE_NUM * BUFFER_NUM; // 多個任務實現流水並行 for (int32_t i = 0; i < loopCount; i++) { CopyIn(i); Compute(i); CopyOut(i); } }
- CopyIn函數實現。
__aicore__ inline void CopyIn(int32_t progress) { // 1、從佇列中分配Tensor LocalTensor<half> xLocal = inQueueX.AllocTensor<half>(); LocalTensor<half> yLocal = inQueueY.AllocTensor<half>(); // 2、使用DataCopy介面將GlobalTensor資料拷貝到LocalTensor DataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH); DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH); // 3、將LocalTensor放入搬入資料的存放位置VecIn的Queue中 inQueueX.EnQue(xLocal); inQueueY.EnQue(yLocal); }
- Compute函數實現。
__aicore__ inline void Compute(int32_t progress) { // 1、使用DeQue從VecIn中取出LocalTensor LocalTensor<half> xLocal = inQueueX.DeQue<half>(); LocalTensor<half> yLocal = inQueueY.DeQue<half>(); LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>(); // 2、呼叫Add指令完成雙目向量計算 Add(zLocal, xLocal, yLocal, TILE_LENGTH); // 3、使用EnQue將計算結果LocalTensor放入到搬出資料的存放位置VECOUT的Queue中 outQueueZ.EnQue<half>(zLocal); // 4、使用FreeTensor將釋放不再使用的LocalTensor inQueueX.FreeTensor(xLocal); inQueueY.FreeTensor(yLocal); }
- CopyOut函數實現。
__aicore__ inline void CopyOut(int32_t progress) { // 1、使用DeQue介面從VecOut的Queue中取出LocalTensor LocalTensor<half> zLocal = outQueueZ.DeQue<half>(); // 2、使用DataCopy介面將LocalTensor拷貝到GlobalTensor上 DataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH); // 3、使用FreeTensor將不再使用的LocalTensor進行回收 outQueueZ.FreeTensor(zLocal); }
6 核函數執行驗證
異構計算架構中,NPU(kernel側)與CPU(host側)是協同工作的,完成了kernel側核函數開發後,即可編寫host側的核函數呼叫程式,實現從host側的APP程式呼叫運算元,執行計算過程。
除了上文核函數實現檔案add_custom.cpp外,核函數的呼叫與驗證還需要需要準備以下檔案:
- 呼叫運算元的應用程式:main.cpp。
- 輸入資料和真值資料生成指令碼檔案:add_custom.py。
- 編譯cpu側或npu側執行的運算元的編譯工程檔案:CMakeLists.txt。
- 編譯執行運算元的指令碼:run.sh。
本文僅介紹呼叫運算元的應用程式的編寫,該應用程式在main.cpp中體現,其他內容您可以在quick-start中直接獲取。
6.1 host側應用程式框架編寫
內建宏__CCE_KT_TEST__ 是區分執行CPU模式或NPU模式邏輯的標誌,在同一個main函數中通過對__CCE_KT_TEST__宏定義的判斷來區分CPU和NPU側的執行程式。
int32_t main(int32_t argc, char* argv[]) { size_t inputByteSize = 8 * 2048 * sizeof(uint16_t); // uint16_t represent half size_t outputByteSize = 8 * 2048 * sizeof(uint16_t); // uint16_t represent half uint32_t blockDim = 8; #ifdef __CCE_KT_TEST__ // 用於CPU偵錯的呼叫程式 #else // NPU側執行運算元的呼叫程式 #endif return 0; }
6.2 CPU執行驗證
完成運算元核函數CPU側執行驗證的步驟如下:
- 分配共用記憶體,並進行資料初始化;
- 呼叫ICPU_RUN_KF調測宏,完成核函數CPU側的呼叫;
- 釋放申請的資源。
請將下文程式碼新增至上面程式碼框架的「用於CPU偵錯的呼叫程式」註釋處。
uint8_t* x = (uint8_t*)AscendC::GmAlloc(inputByteSize); uint8_t* y = (uint8_t*)AscendC::GmAlloc(inputByteSize); uint8_t* z = (uint8_t*)AscendC::GmAlloc(outputByteSize); ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize); ReadFile("./input/input_y.bin", inputByteSize, y, inputByteSize); AscendC::SetKernelMode(KernelMode::AIV_MODE); ICPU_RUN_KF(add_custom, blockDim, x, y, z); // use this macro for cpu debug WriteFile("./output/output_z.bin", z, outputByteSize); AscendC::GmFree((void *)x); AscendC::GmFree((void *)y); AscendC::GmFree((void *)z);
6.3 NPU側執行驗證
完成運算元核函數NPU側執行驗證的步驟如下:
- 初始化Device裝置;
- 建立Context繫結裝置;
- 分配Host記憶體,並進行資料初始化;
- 分配Device記憶體,並將資料從Host上拷貝到Device上;
- 用核心呼叫符<<<>>>呼叫核函數完成指定的運算;
- 將Device上的運算結果拷貝回Host;
- 釋放申請的資源。
請將下文程式碼新增至上面程式碼框架的「NPU側執行運算元的呼叫程式」註釋處。
// AscendCL初始化 CHECK_ACL(aclInit(nullptr)); // 建立Context繫結裝置 aclrtContext context; int32_t deviceId = 0; CHECK_ACL(aclrtSetDevice(deviceId)); CHECK_ACL(aclrtCreateContext(&context, deviceId)); aclrtStream stream = nullptr; CHECK_ACL(aclrtCreateStream(&stream)); // 分配Host記憶體,並進行資料初始化 uint8_t *xHost, *yHost, *zHost; uint8_t *xDevice, *yDevice, *zDevice; CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize)); CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize)); CHECK_ACL(aclrtMallocHost((void**)(&zHost), outputByteSize)); // 分配Device記憶體,並將資料從Host上拷貝到Device上 CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST)); CHECK_ACL(aclrtMalloc((void**)&yDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST)); CHECK_ACL(aclrtMalloc((void**)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST)); ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize); ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize); CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE)); CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE)); // 用核心呼叫符<<<>>>呼叫核函數完成指定的運算 add_custom_do(blockDim, nullptr, stream, xDevice, yDevice, zDevice); CHECK_ACL(aclrtSynchronizeStream(stream)); // 將Device上的運算結果拷貝回Host CHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST)); WriteFile("./output/output_z.bin", zHost, outputByteSize); // 釋放申請的資源 CHECK_ACL(aclrtFree(xDevice)); CHECK_ACL(aclrtFree(yDevice)); CHECK_ACL(aclrtFree(zDevice)); CHECK_ACL(aclrtFreeHost(xHost)); CHECK_ACL(aclrtFreeHost(yHost)); CHECK_ACL(aclrtFreeHost(zHost)); CHECK_ACL(aclrtDestroyStream(stream)); CHECK_ACL(aclrtDestroyContext(context)); CHECK_ACL(aclrtResetDevice(deviceId)); CHECK_ACL(aclFinalize());
6.4 執行一鍵式編譯執行指令碼,編譯和執行應用程式
指令碼執行方式如下:
bash run.sh <kernel_name> <soc_version> <core_type> <run_mode>
- <kernel_name>表示需要執行的運算元。
- <soc_version>表示運算元執行的AI處理器型號。
- <core_type>表示在AiCore上或者VectorCore上執行。
- <run_mode>表示運算元以cpu模式或npu模式執行。
1. CPU模式下執行如下命令(運算元執行的AI處理器型號以Ascend 910為例):
bash run.sh add_custom ascend910 AiCore cpu
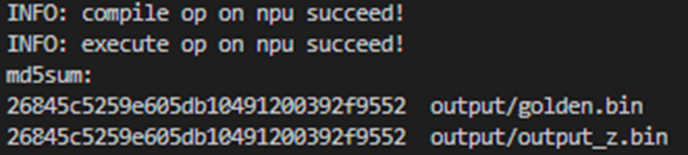
執行結果如下,當前使用md5sum對比了所有輸出bin檔案,md5值一致表示實際的輸出資料和真值資料相符合。

2. NPU模式下執行如下命令:bash run.sh add_custom ascend910 AiCore npu
執行結果如下,當前使用md5sum對比了所有輸出bin檔案,md5值一致表示實際的輸出資料和真值資料相符合。
至此,你已經完成了Ascend C運算元開發的快速入門,更多內容請參考:《Ascend C 官方教學》