Java爬蟲實戰系列——常用的Java網路爬蟲庫
常用的Java網路爬蟲庫
Java開發語言是業界使用最廣泛的開發語言之一,在網際網路從業者中具有廣泛的使用者,Java網路爬蟲可以幫助Java開發人員以快速、簡單但廣泛的方式為各種目的抓取資料。平常我們在討論網路爬蟲的時候,很多人都會想到使用Python語言,因為與Python相關的網路爬蟲資料很多,框架也有不少,上手會方便不少。但實際上,Java網路爬蟲家族裡面也有很多優秀的開源框架或者開源庫供大家使用。下圖是國外某個網站在某年度篩選出來的最受歡迎的 50 個網路爬蟲開源框架或者開源庫,從這個排名中我們可以看出 Java 網路爬蟲的應用也是很廣泛的。
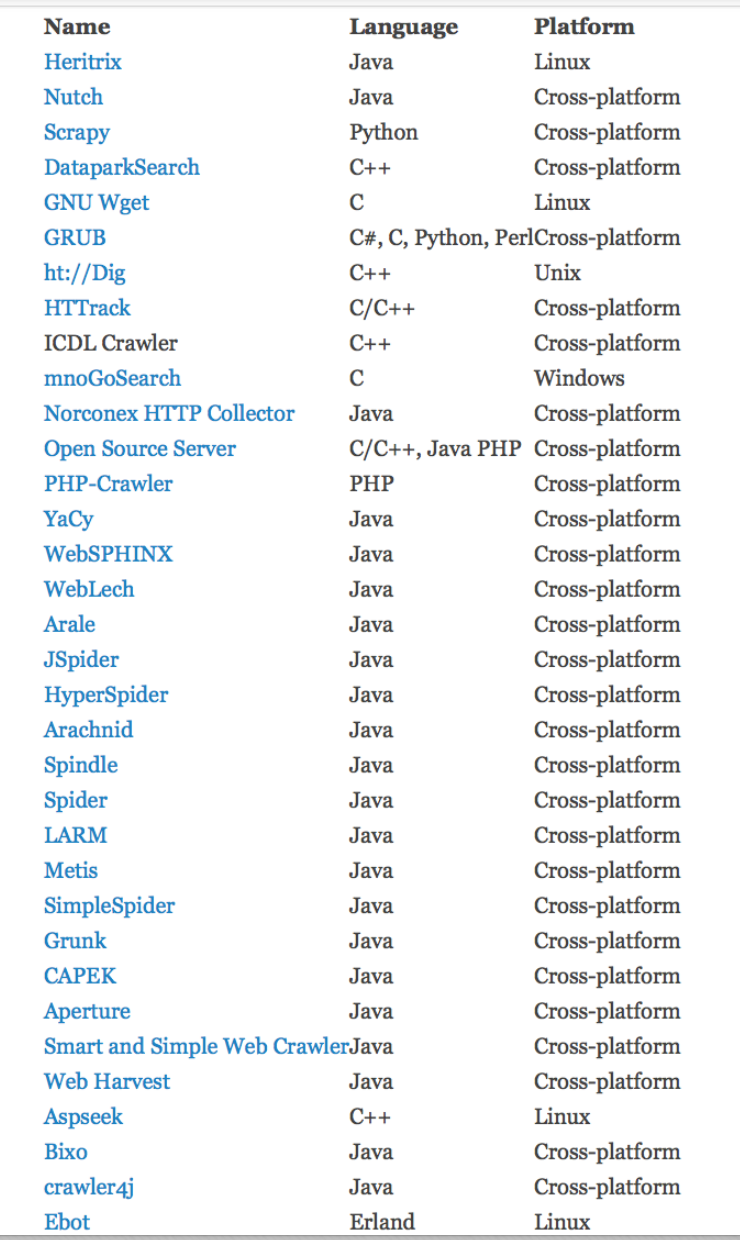
接下來給大家介紹幾個常用的Java開源網路爬蟲庫:
1.Heritrix
Heritrix是一個完全由Java開發的、開源網路爬蟲工具,使用者可以使用它從網路上面抓取想要的資源。它的主要元件包括Web Administrative Console、Crawl Order、Crawl Controller、Frontier、Scope、ToeThreads和Processor等。在國內,Heritrix 也有著十分廣泛的使用者,很多開發人員和研究人員都在使用 Heritrix來採集資料,為進一步的資料分析和資料探勘工作做準備。Heritrix的最出色之處在於開發者可以在現有框架的基礎上面對各個元件進行擴充套件,實現自己需要的抓取邏輯。其整體結構如下圖所示:
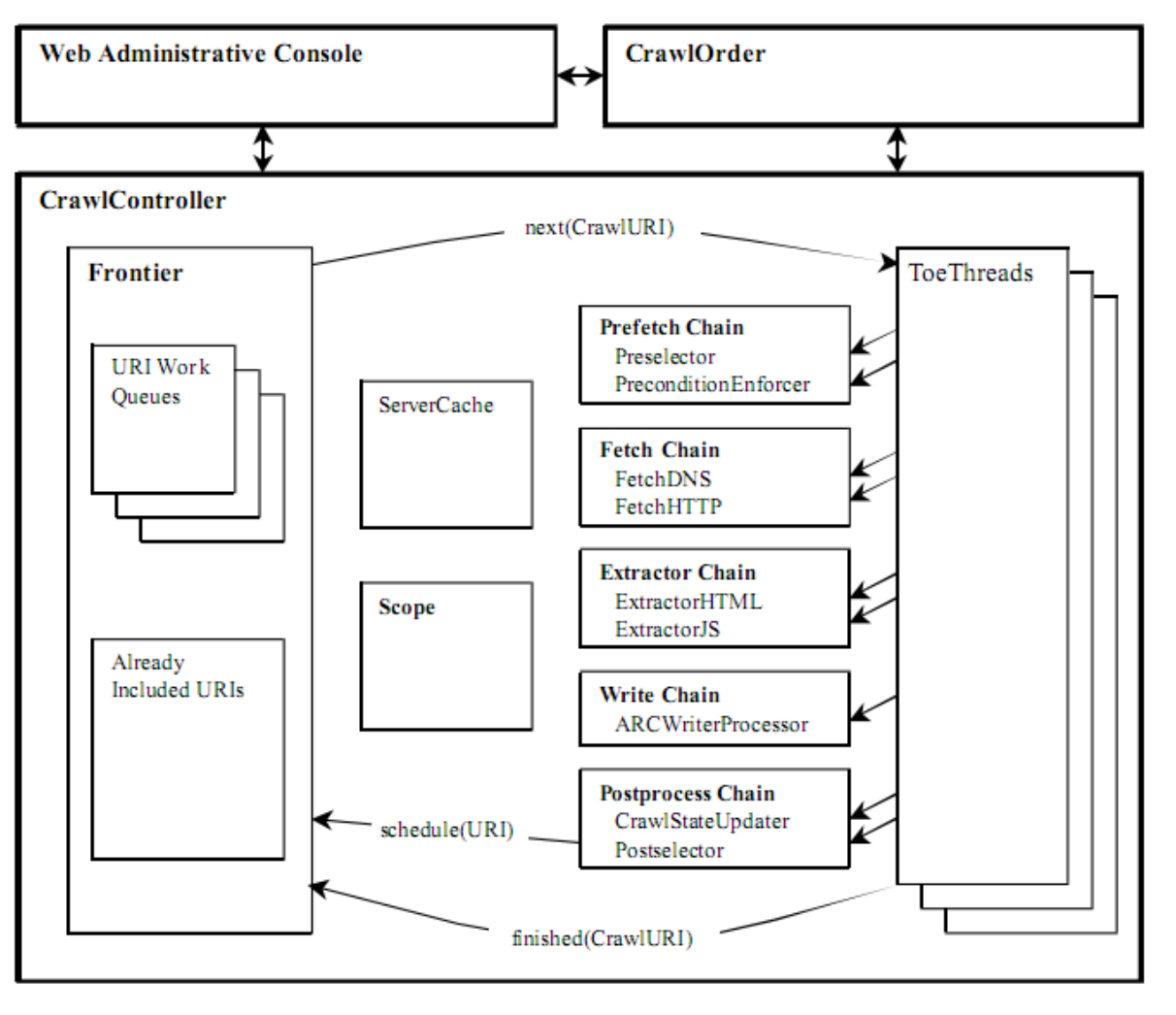
一個完整的網頁採集任務是從CrawlOrder開始的。使用者可以通過多種不同方法建立一個網頁採集任務,例如複製已經存在的任務、手動建立新的任務等,其中最方便的方法是利用預設的組態檔order.xml來建立一個任務。這個檔案中記錄了抓取任務的所有屬 性,每次設定一個新的任務都會產生一個新的order.xml檔案,Heritrix中的CrawlOrder元件就是用來儲存order.xml檔案中的內容。
Heritrix採用了良好的模組化設計,這些模組由一個採集控制器類(CrawlerController)來協調排程,CrawlerController在架構中處於核心地位,其主要工作結構如下圖所示:
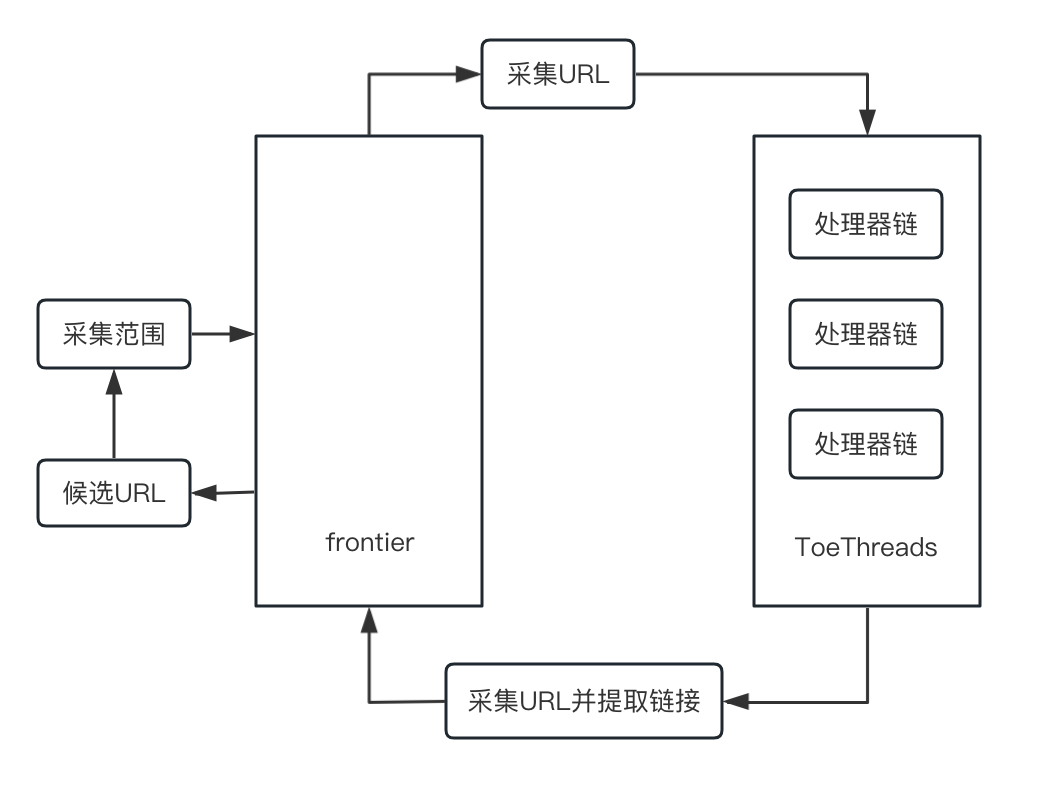
接下來,給大家稍微介紹一下上圖中提到的各個工作元件。
CrawlController在執行抓取任務的過程中,作為一個主執行緒在工作,CrawlController決定著如何開始抓取工作,並決定著何時開始、何時結束資料採集工作。
Frontier元件的任務是為執行緒提供連結,它藉助一些演演算法來判斷採集到的URI是否會被處理,同時它也負責記錄紀錄檔和報告爬蟲的執行狀態。
Frontier元件中有一個屬性叫做scope,它決定了當前抓取範圍的元件。通過設定抓取範圍,可以決定爬蟲是在一個域名下抓取還是在多個域名下抓取。
Heritrix支援多執行緒執行,因此Heritrix內部維護了標準執行緒池ToePool, 這個執行緒池用於管理爬蟲中的所有執行緒,每一個執行緒在處於執行狀態時只處理一個URL。 採用多執行緒的技術可以提高爬蟲採集網頁的效率,以便更快速有效地抓取網頁內容。負責處理的執行緒叫做ToeThread,ToeThread從Frontier中請求待處理的URL 後,傳送給處理器進行處理。
在Heritrix中,處理器被分組為處理器鏈。每個處理器鏈都會對URL進行一些處理。當一個處理器處理完一個URL後,ToeThread會將URL傳送給下一個處理器,直到URL被所有處理器處理完畢。處理器可以選擇告訴URL跳轉到某個特定的鏈。此外,如果處理器出現致命錯誤,處理將跳至後處理鏈。處理器鏈的工作流程如下圖所示:
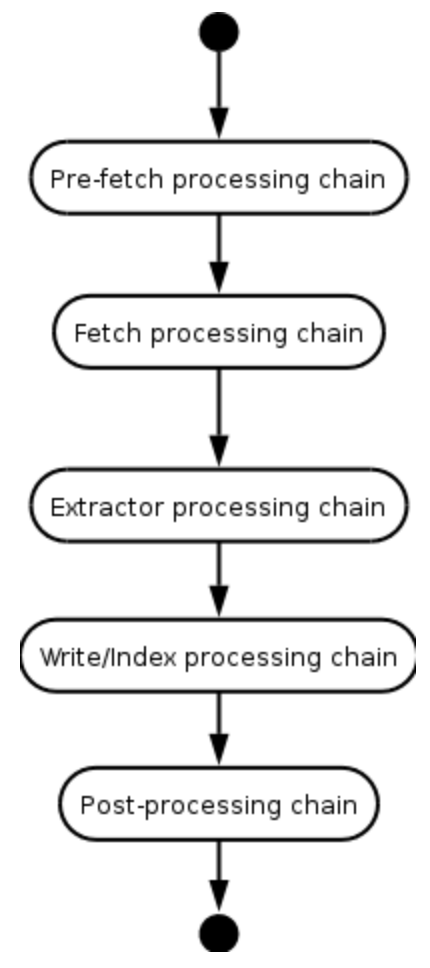
下面對各個處理鏈進行一下簡單介紹:
(1)Pre-fetch processing chain(預處理鏈)
預處理鏈負責檢查URL是否符合抓取規則,是否在抓取範圍內。在預處理鏈中,包含兩個主要的處理器,Preselector和PreconditionEnforcer。
PreSelector用來檢查URL是否符合採集任務的需要,以便判斷是否要繼續處理該URL,它可以將一部分不滿足需求的URL過濾掉。這裡主要是通過正規表示式匹配 URL,如果一個URL滿足正規表示式,這個URL會進入下一步的處理;否則就拋棄這個URL。
PreconditionEnforcer的作用是確保抓取一個URL的所有先決條件都已經滿足,例如驗證DNS是否成功解析、robots資訊是否已經獲取等。
(2)Fetch processing chain(抓取處理鏈)
抓取處理鏈中的處理器中的處理器主要負責從伺服器獲取資料,Heritrix支援的每個網路協定都有一個與之對應的處理器,例如HTTP協定對應的是FetchHTTP處理器。
(3)Extractor processing chain(提取器處理鏈)
在提取器處理鏈中,URL所參照的檔案內容處於可用的狀態,多個處理器將依次嘗試從中獲取新連結。與抓取處理鏈一樣,每個網路協定都有一個與之對應的提取處理器,例如:ExtractorHTTP、ExtractorFTP 等。
(4)Write/index processing chain(存檔處理鏈)
該鏈負責將資料寫入歸檔檔案。Heritrix自帶的ARCWriterProcessor可將資料寫入ARC格式。還可以編寫新的處理器來支援其他格式,甚至建立索引。
(5)Post-processing chain(後處理鏈)
URL應始終通過該處理鏈,即使在該鏈中較早的處理器已決定不抓取該URL。後處理鏈必須包含以下處理器:
- CrawlStateUpdater: 用於更新每一臺可能在採集過程中受到爬蟲影響的主機的資訊,這裡的資訊包括robots資訊和IP地址。
- LinksScoper: 主要用於驗證連結的範圍。驗證從網頁中抽取出來的URL是否在規定的範圍內,並過濾掉不在該範圍內的URL。
- FrontierScheduler: 將提取到的連結放入到Frontier中,以便後續排程抓取。
優缺點
優點:開發者可以方便地在現有框架基礎上進行擴充套件
缺點:單範例的爬蟲,無法在分散式環境下進行工作;應對反爬蟲的機制比較薄弱
實戰篇:
安裝及設定
下載地址: https://github.com/internetarchive/heritrix3
我這裡使用的版本是3.4.0,安裝方法簡單,只要參考官方檔案就可以了。
啟動及執行
啟動的時候,我們可以選擇通過命令列啟動:
$HERITRIX_HOME/bin/heritrix -a admin:123456
也可以選擇將工程原始碼匯入到IDE後,在IDE中啟動。無論選擇哪種啟動方式,都需要注意新增引數-a來設定使用者名稱和密碼。
engine listening at port 8443
operator login set per command-line
NOTE: We recommend a longer, stronger password, especially if your web interface will be internet-accessible.
Heritrix version: 3.4.0-20220727
執行之後看到上面的紀錄檔資訊就代表啟動成功了。
在瀏覽器中存取: https://localhost:8443 ,可以進入到管理介面。
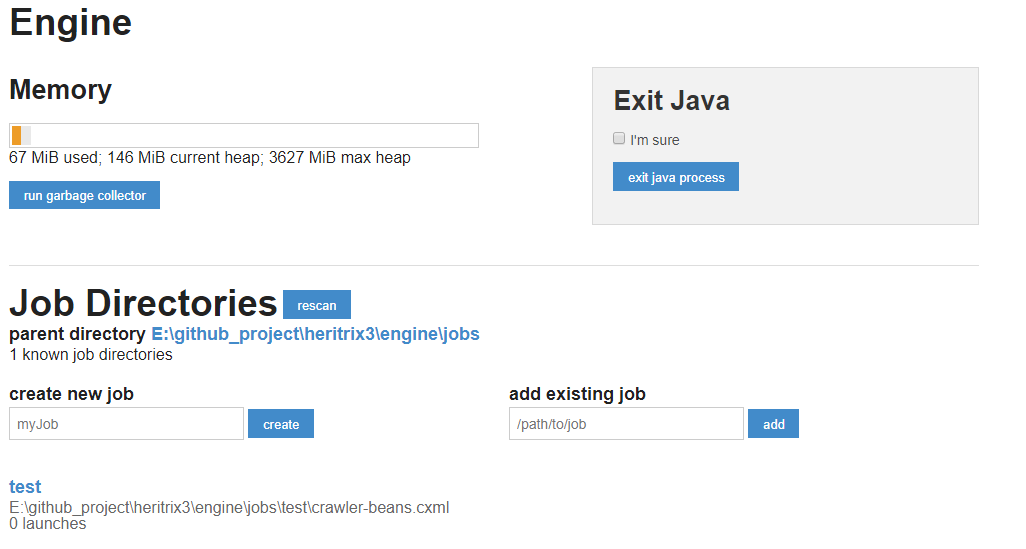
注意:一定要是https連結才可以,因為Heritrix在啟動web容器的時候只支援了https協定,而沒有支援http協定,因為本地沒有設定證書,所以會出現安全警告,忽略繼續存取就可以的。
抓取任務建立與設定
啟動成功以後,我們就可以建立和設定抓取任務了。

在建立任務的過程中,最重要的就是通過configuration選項設定抓取任務。通過一個名為crawler-beans.cxml的組態檔控制整個抓取過程。crawler-beans.cxml 採用Spring來管理,裡面的設定都是spring bean。下面對crawler-beans.cxml檔案中涉及到的spring bean進行簡單介紹。
| bean id | class | 作用 |
|---|---|---|
| simpleOverrides和longerOverrides | org.springframework.beans.factory.config.PropertyOverrideConfigurer | 屬性資源設定器覆蓋應用程式上下文定義中的 bean 屬性值。它將屬性檔案中的值推播到 bean 定義中。 |
| metadata | org.archive.modules.CrawlMetadata | 該bean的主要作用是記錄抓取job的基本屬性,名稱、抓取地址和robots協定規則的遵循。 |
| seeds | org.archive.modules.seeds.TextSeedModule | 該bean的主要作用是設定種子地址的讀取位置 |
| acceptSurts | org.archive.modules.deciderules.surt.SurtPrefixedDecideRule | surtprefixeddeciderule是Heritrix3中的一個決策規則(DecideRule),它的作用是允許或禁止基於URL字首的抓取。 |
| scope | org.archive.modules.deciderules.DecideRuleSequence | Deciderulesequence的作用是定義和控制抓取流程中的決策規則序列。 |
| candidateScoper | org.archive.crawler.prefetch.CandidateScoper | Candidatescoper會根據一系列的規則或演演算法,對網頁進行判斷和打分。例如,它可以根據網頁的URL結構、網頁內容的關鍵詞匹配、連結的可用性等因素,來評估網頁的重要性和質量。根據這些評估標準,Candidatescoper會給每個網頁打上一個分數,分數高的網頁將被優先保留。 |
| preparer | org.archive.crawler.prefetch.FrontierPreparer | FrontierPreparer主要作用是設定URL的抓取深度,佇列,成本控制等。 |
| candidateProcessors | org.archive.modules.CandidateChain | 主要作用是管理待爬取的URL,CandidateChain參照了candidateScoper來決定相關的URL是否會保留並生成CrawlURI,同時還參照了prepare bean來控制抓取的深度並進行成本控制等。 |
| preselector | org.archive.crawler.prefetch.Preselector | 預先選擇器,這裡會過濾掉一部分URL.如blockByRegex為拒絕正則,allowByRegex為允許正則 |
| preconditions | org.archive.crawler.prefetch.PreconditionEnforcer | 先決條件設定,如設定IP有效期,爬蟲協定檔案robots.txt有效期 |
| fetchDns | org.archive.modules.fetcher.FetchDNS | FetchDNS主要用於處理域名解析功能 |
| extractorHttp | org.archive.modules.extractor.ExtractorHTTP | URL提取器 |
| extractorRobotsTxt | org.archive.modules.extractor.ExtractorRobotsTxt | 檢視Robots協定 |
| ExtractorSitemap | org.archive.modules.extractor.ExtractorSitemap | extractorsitemap是heritrix中的一個用來處理網站地圖(sitemap)的抽取器。 |
| ExtractorHTML | org.archive.modules.extractor.ExtractorHTML | HTML內容提取器 |
設定好各個選項之後,我們就可以開始真正執行抓取任務了。因為篇幅的關係這裡就不展開描述了,感興趣的讀者可以自行實踐。
2.Norconex Web Crawler
官方地址: https://opensource.norconex.com/crawlers/web/
Norconex也是一款非常優秀的開源爬蟲工具,與之相關的中文資料比較少。但是,如果你正在尋找一個開源的企業級爬蟲工具,那你一定不能錯過它。作者認為 Norconex Web Crawler有兩個功能最值得關注:
- 支援多種型別的HTML檔案下載器。當我們要採集網頁中的特定資訊時,我們首先要能夠下載網頁的內容,Norconex提供了GenericHttpFetcher來滿足大部分場景下的需求,但是在某些情況下,可能需要更專業的方式來獲取網路資源。例如:通過Javascript非同步載入的網頁內容,則通過WebDriverHttpFetcher來獲取網頁內容更加合理。當然,你也可以開發自定義的HTML檔案下載器。
- 提供了HTTP 請求頭和HTTP響應頭監聽器和修改器。Norconex基於BrowserMobProxy實現了HTTP請求頭和HTTP響應頭監聽器和修改器(HttpSniffer)。HttpSniffer使得對HttpFetcher請求和響應內容的監控更加方便,也可以使HTTP的請求更加規範化,而且可以多一種方式獲取到web服務響應的內容。
接下來,我們重點介紹一下BrowserMobProxy(簡稱 BMP),它是一款由Java編寫開源的網路存取代理工具,在後面我們自己編寫的Java網路爬蟲中也會用到該工具。通過BMP,我們可以修改、設定和捕獲到網路的請求和響應,BMP甚至可以將網路請求的所有細節記錄到HAR檔案中。Har是一種用於匯出HTTP跟蹤資訊的開放格式,稱為HTTP存檔 (HAR)。資料儲存格式為JSON檔案。具體資訊可以參見( RFC 4627 )。BMP有兩種工作模式,嵌入式模式和獨立啟動模式。嵌入式模式是通過Java程式碼呼叫使用。嵌入式模式是利用Java程式碼來啟動代理,並通過Java程式碼來捕獲修改請求資訊和響應資訊。另一種是獨立啟動模式,可以通過命令列來啟動,通過RestAPI來進行操作。
3. Crawler4j
Crawler4j是用Java編寫的開源專案,它支援多執行緒方式採集網站資訊,並利用正規表示式限制採集物件。Crawler4j具有完整的爬蟲功能框架,小巧靈活並可以獨立執行。因此,易於整合到專案中,或者將第三方業務邏輯嵌入工作流中自定義爬行。其主要工作流程如下所示:
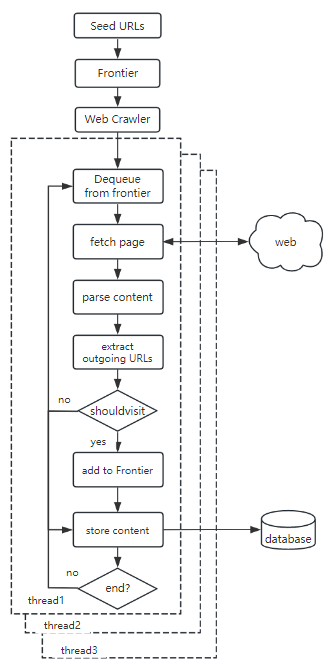
Crawler4j最主要的缺點是不支援動態網頁的抓取,但是我們可以基於Crawler4j進行二次開發對WebCrawlerFactory進行擴充套件使其支援動態網頁內容的抓取。
總結
本章中,我們介紹了幾個目前仍然比較活躍的爬蟲開源框架,Heritrix,Norconex和Crawler4j。在後面的章節裡面,我們會參考這些開源的框架和軟體,開發一套屬於我們自己的Java爬蟲軟體。