高德Android高效能高穩定性程式碼覆蓋率技術實踐
程式碼覆蓋率(Code coverage)是軟體測試中的一種度量方式,用於反映程式碼被測試的比例和程度。
在軟體迭代過程中,除了應該關注測試過程中的程式碼覆蓋率,使用者使用過程中的程式碼覆蓋率也是一個非常有價值的指標,同樣不可忽視。因為伴隨著業務擴充套件和功能更新,產生了大量過時和廢棄的程式碼,這些程式碼或者很少甚至完全不再使用,或者「年久失修」,缺少維護,不僅對應用包體積有影響,還可能帶來穩定性風險。此時,能夠採集生產環境的程式碼覆蓋率,瞭解線上程式碼的使用情況,為下線無用程式碼提供依據,就十分重要了。
目標
我們的目標很明確:根據雲端設定,採集線上每個類的觸達和使用頻次,上傳到雲端,在平臺進行處理,並提供查詢和報表展示能力。

如上圖所示,我們期望程式碼覆蓋率資料能在平臺上進行查詢和直觀的展示,在需要時可以直接檢視,為下線舊程式碼、資源排程和分配等提供決策依據,最終為使用者提供更小的App安裝包,更好的功能使用體驗。
通過雲控中心,我們可以控制是否啟用覆蓋率採集,也可以根據覆蓋率(類使用頻次)動態調整App中金剛位、執行緒等資源的排程分配策略。其中覆蓋率採集方案是最為重要的一環,業界也有很多成熟的方案,但都有各自適合的場景,而我們的訴求是在儘量不影響使用者使用和App執行的前提下,採集類粒度的程式碼使用覆蓋率。使用的採集方案應該少Hack,實現簡單,兼顧穩定性和效能,同時也不會侵入打包流程,帶來包體積影響等,在經過深入探索後,我們自研出了一套完美滿足這些要求的全新方案。
方案對比
下表為常見方案與自研方案的各項指標對比,綠色表示更優。

從表格中可以看出:
Jacoco方案
類似的還有Emma、Cobertura等,他們都通過插樁實現,可以支援所有版本所有粒度的採集,但是插樁帶來了一定的包體積和效能影響,不適合線上大範圍使用。
Hook PathClassLoader方案
實現簡單,無原始碼侵入,且支援所有Android版本,但Hook PathClassLoader不僅帶來了效能影響,甚至可能波及App穩定性。
Hack存取ClassTable方案
能夠按需採集,對App效能幾乎沒有影響,但Hack可能帶來相容性問題,且實現較複雜。
自研方案
-
效能優異,支援按需採集,無失真App效能
-
實現簡單,未使用任何「黑科技」,穩定性和相容性極好
-
支援跨程序和外掛採集
對比得知自研方案能更好的滿足我們採集線上程式碼覆蓋率的訴求,因為它不僅有著很好的穩定性,而且有著優異的效能,幾乎不會對使用者產生任何影響。那麼它是如何做到高效能和高穩定性的呢?請看下文介紹。
方案介紹
原理
要採集類粒度的程式碼覆蓋率,其實就是要知道在App執行過程中,載入和使用了哪些類。在Java應用中,這可以通過呼叫ClassLoader的findLoadedClass方法直接查詢得到,而在Android App中卻沒那麼簡單。原因是Android系統做了這樣一個優化:
為了提升啟動效能,對於App自定義的類,即PathClassLoader載入的類,如果直接呼叫findLoadedClass進行查詢,即使這個類沒有載入,也會執行載入操作。
這不是我們期望的。
雖然我們沒辦法直接呼叫FindLoadedClass方法查詢類的載入狀態,但是經過深入研究和分析,我們發現ClassLoader最終是通過查詢它的ClassTable欄位得到類載入狀態的,如果我們也能存取ClassTable,問題不就迎刃而解了嗎?沿著這個思路,我們創新性地提出了複製ClassTable指標,通過標準API間接存取類載入狀態的方案。
該方案巧妙地實現了對ClassTable的無Hack存取;同時完美繞開了我們不需要的類載入優化,寥寥數行程式碼就實現了類載入情況的獲取,巧妙且簡潔,同時它還具備以下優勢:
- 採集速度是普通方案的5倍以上,效能優異
- 使用標準API存取ClassTable,相容性與穩定性極佳
- 僅使用一次反射,無任何「黑科技」,簡單穩定
- 不影響類載入及App執行
- 完美支援多程序和外掛的採集
不過有一點需要注意:
ClassTable欄位是從Android N開始引入的,所以該方法只適用於Android N及以上。出於必要性和ROI考慮,我們也未對Android N以下版本進行適配。
採集流程
基於上述的方案,我們設計了完整的程式碼覆蓋率採集功能,關鍵流程如下:
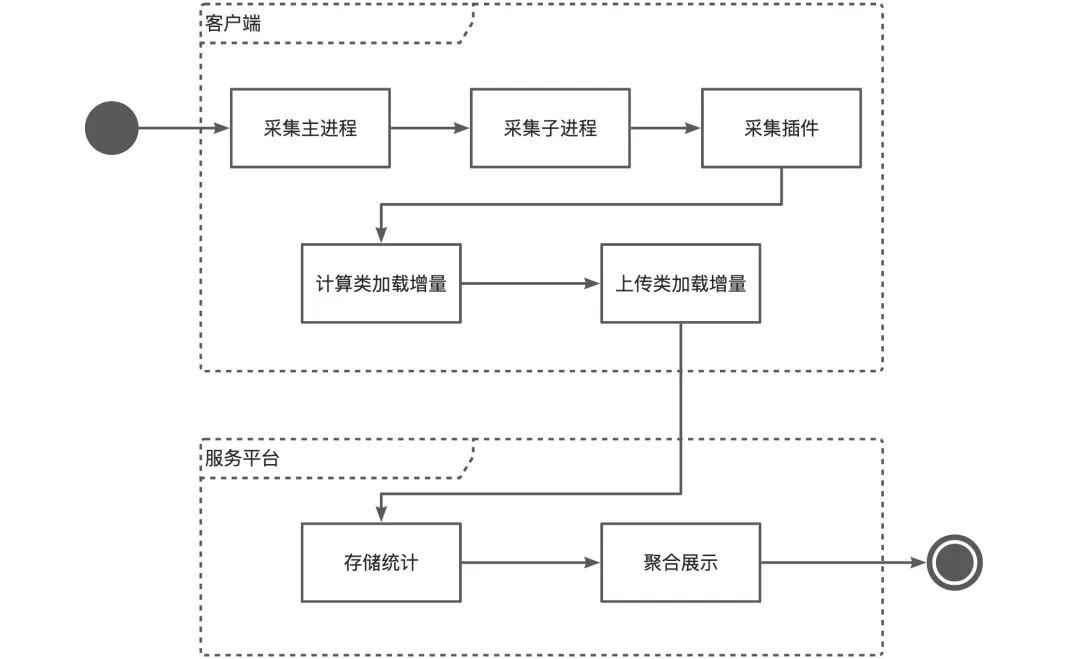
可以看到整個端側的採集流程是序列的,非常便於流程控制和資料整合。下面說明一下設計思路:
-
採集時將App分為兩部分,一部分是主程序和子程序使用的宿主類資料,另一部分是外掛類資料。
-
基於查詢方式採集,主程序、子程序、外掛分別提供查詢類載入狀態的介面。
-
流程基於序列方式,由主程序控制,依次呼叫相應的介面採集主程序、子程序和外掛的資料。
-
每個版本只採集和上報未載入過的類資料,首次採集時,以類全集為輸入;後續的每次採集,以上一版本未載入的類為輸入,採集次數越多,需要查詢的類越少。
-
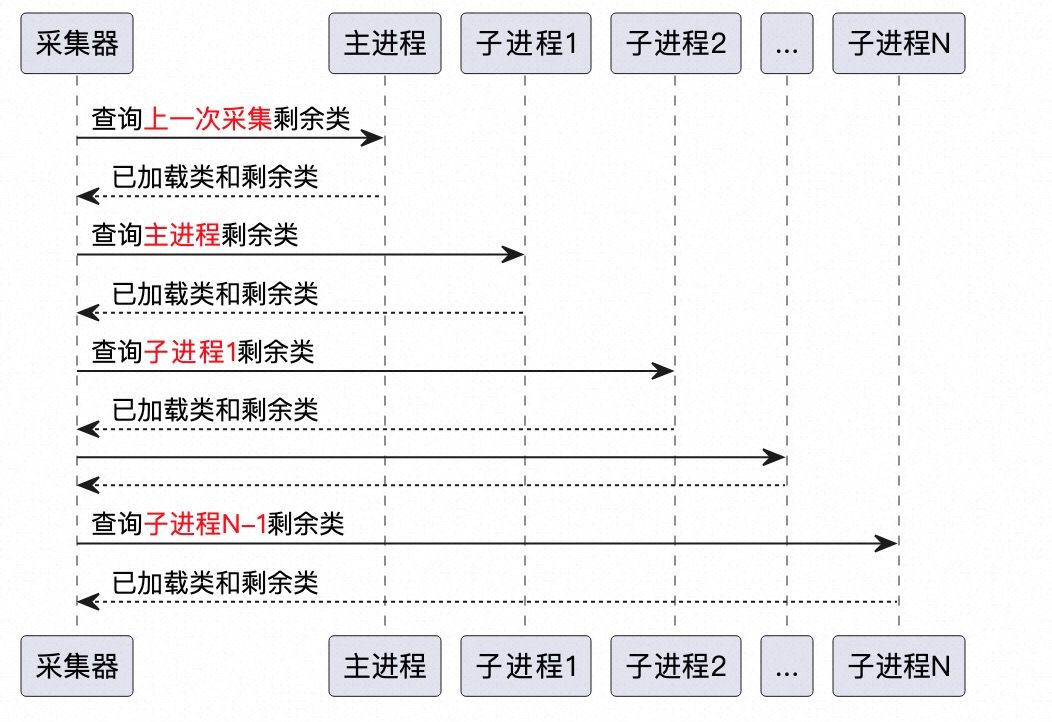
主程序和子程序依次查詢,查詢都以上一次查詢後剩餘的未載入類為輸入,因此越靠後的子程序所需查詢的數量越少,同一個外掛在不同程序的範例的查詢也與此類似。
如下圖所示:
-
採集結束時,會生成一份宿主類資料和N份外掛類資料(假如有N個外掛)。這些資料會分別與之前的採集結果做Diff,將增量資料上傳服務。
-
服務平臺進行儲存、解Mapping、模組關聯等處理,最後以報表形式聚合展示。
值得注意的是:
-
主程序與子程序使用的類都屬於宿主,採集結果應該合併為一份資料;同理,一個外掛無論在多少個程序載入,最後也只應生成一份該外掛的資料。
-
採集時我們將資料分為兩部分,這樣可以提高採集效率,也方便後續解混淆;在平臺展示時,合併展示更有意義。
版本管理
Android App的程式碼大都會經過混淆處理,混淆後的類名會因版本而異,這就需要根據App版本來管理覆蓋率資料。
按版本管理資料後,每個版本會清除上一版本的資料,避免資料錯亂;一個特定的類,在當前版本已經使用過之後,會記錄下來,後續此版本的採集不再重複查詢它的使用情況。
每個版本首次採集時,需要以App的類名全集作為輸入,每一次採集會產生一個未使用類的集合,作為下一次採集的輸入。這樣,一個版本中每次採集需要關注的類數量會逐步減少,可避免無意義的查詢,提升採集效能。
類名資料獲取
類名資料可以通過兩種方式獲取:
1.從安裝包獲取
安裝包內的類名資料可以從PathClassLoader中獲取,外掛則可以從對應的BaseDexClassLoader中獲取,使用如下方法即可:
public static List<String> getClassesFromClassLoader(BaseDexClassLoader classLoader) throws ClassNotFoundException, IllegalAccessException {
//類名資料位於BaseDexClassLoader.pathList.dexElements.dexFile中,可以通過反射獲取
//先獲取pathList欄位
Field pathListF = ReflectUtils.getField("pathList", BaseDexClassLoader.class);
pathListF.setAccessible(true);
Object pathList = pathListF.get(classLoader);
//獲取pathList中的dexElements欄位
Field dexElementsF = ReflectUtils.getField("dexElements", Class.forName("dalvik.system.DexPathList"));
dexElementsF.setAccessible(true);
Object[] array = (Object[]) dexElementsF.get(pathList);
//獲取dexElements中的dexFile欄位
Field dexFileF = ReflectUtils.getField("dexFile", Class.forName("dalvik.system.DexPathList$Element"));
dexFileF.setAccessible(true);
ArrayList<String> classes = new ArrayList<>(256);
for (int i = 0; i < array.length; i++) {
//獲取dexFile
DexFile dexFile = (DexFile) dexFileF.get(array[i]);
//遍歷DexFile獲取類名資料
Enumeration<String> enumeration = dexFile.entries();
while (enumeration.hasMoreElements()) {
classes.add(enumeration.nextElement());
}
}
return classes;
}

這種方式簡單直接,不過會一次性將DexFile中的所有類名載入到記憶體中,而根據我們的測試,每一萬個類大約佔0.8mb記憶體,對於動輒數萬個類的大型App來說,會是一個不小的記憶體開銷。所以還可以考慮第二種方式。
2.雲化下載
從構建平臺獲取類名資料,上傳到雲化平臺,App在需要的時候下載使用。
至於選用哪種方式,直接根據類數量來選取就好。類數量特別多時,如大型App場景,建議使用雲化方式;普通App或外掛,直接從安裝包類獲取即可。
子程序採集
主程序未載入的類,我們會交給子程序再次查詢。這就需要子程序提供支援跨程序呼叫的查詢介面,我們選擇了簡單可靠,且容易複用的AIDL方案來實現。
具體做法是:
通過AIDL定義查詢介面,並定義對應的Action,在Service的onBind方法中根據Action返回查詢介面的Binder實現類用於遠端呼叫。
同時考慮到跨程序的成本較高,如果對每個類都呼叫一次查詢介面,無疑是難以接受的。於是我們想到了檔案+批次查詢的方式:利用檔案作為資料載體,將已載入的類和未載入的類都寫入到檔案中,在介面間傳遞檔案路徑。檔案操作還可以採用BufferedReader和BufferedWriter以提升效能。
呼叫過程如圖:
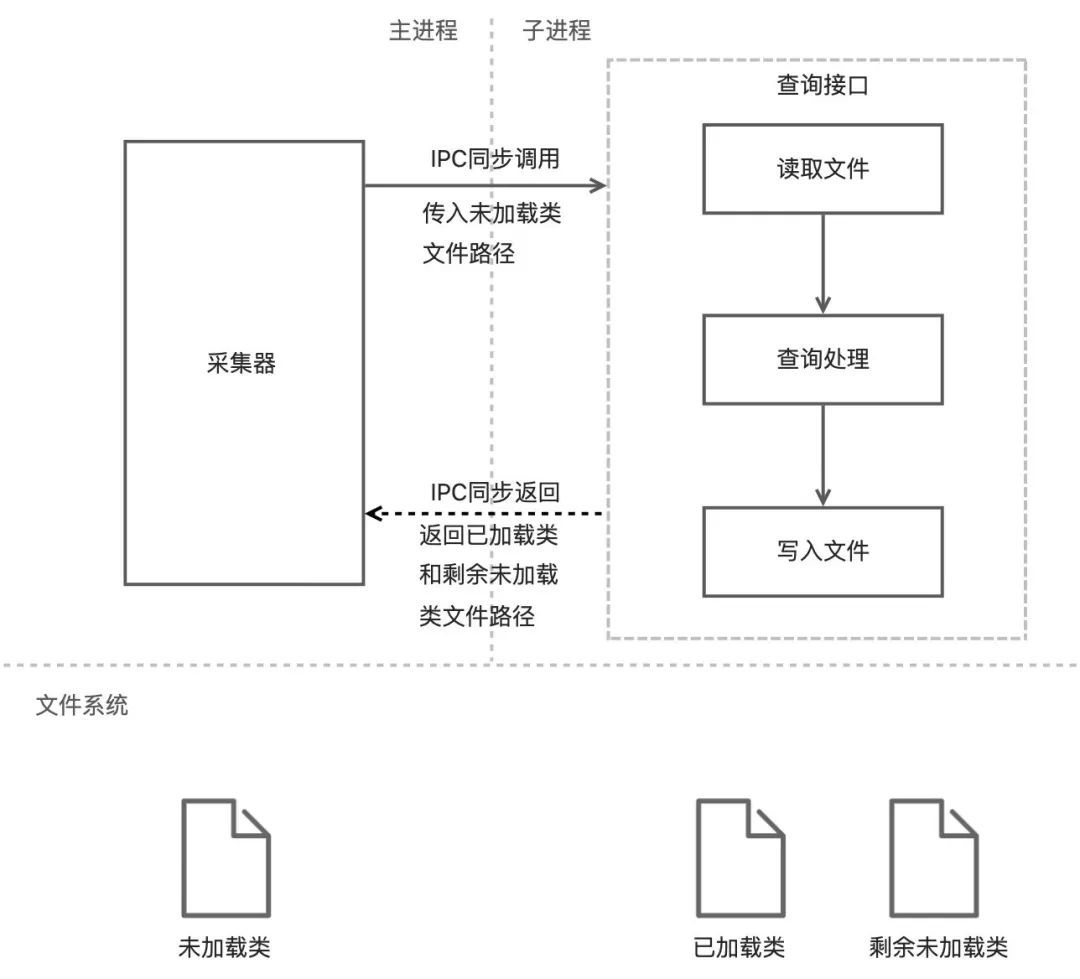
這樣做的好處也顯而易見:
-
採集一個程序僅需一次跨程序呼叫,成本極低
-
避免資料序列化的記憶體開銷
-
繞開巨量資料無法直接跨程序傳遞的問題
-
採集流程更簡單,可按需採集需要的程序
-
方便資料過濾,避免重複查詢已載入類,提升採集效能
外掛採集
對於宿主類,查詢PathClassLoader對應的ClassTable即可。
而外掛一般通過BaseDexClassLoader或其派生類進行載入,需要查詢相應ClassLoader的ClassTable。
對於在子程序中使用的外掛,只是多了跨程序介面呼叫,將已載入類和剩餘類返回給主程序進行處理的操作。
採集步驟如下:
-
查詢子程序類時,會同時查詢該程序中執行的外掛類,將資料寫入按外掛名劃分的檔案。
-
對主程序外掛的採集是整個流程的最後一個環節,此時會檢測每個外掛對應的資料檔案(子程序生成),並進行合併處理,最後將資料檔案刪除。
-
最後再處理剩餘的外掛資料檔案,這部分檔案屬於只在子程序執行的外掛。
到此,就得到了所有外掛的類載入資料。
解Mapping
檢視程式碼覆蓋率資料時,我們期望看到原始的類名,所以解Mapping是必經之路。
解Mapping操作可以在端上進行,也可以在服務側進行,出於安全性考慮,我們選擇了服務側。
Mapping檔案由打包過程生成,每個安裝包對應一份。我們的做法是在構建平臺打正式包的時候通過指令碼生成混淆類與明文類的對映檔案,伺服器端在需要的時候通過App版本資訊獲取對應的對映檔案,反解出原始類名,並與模組進行關聯。
最終展示到平臺的就是解完Mapping,並與模組、外掛完成關聯的程式碼覆蓋率資料。
資料儲存及增量計算
採集的資料需要儲存起來,為了方便計算增量資料,我們選擇了資料庫作為儲存方案,因為它天生具備去重及排序功能,而且效能也不錯。具體的做法是:
-
建立一張資料表,只需包含一個名為class的列就行,該列宣告為主鍵,不接受空值和重複。
-
每次採集前,獲取其中的行數,採集過程中,將已載入的類名資料更新到表中,讓資料庫自動完成去重。採集完成後,再次獲取資料行數,與採集前的行數相減得出的offset就是增量部分,我們只需要將這部分資料上傳到服務。
效能和穩定性
經過我們的反覆測試和調優,對5w+類的採集平均耗時約0.5s/次,採集期間記憶體增長在500kb左右,CPU無明顯上漲。
同時也經過高德地圖線上多個版本驗證,未發現相關崩潰及ANR。
其他
繞開黑灰名單
Android P以後,官方將ClassTable成員變數加入了黑灰名單,在使用反射存取之前,需繞開SDK限制。我們採用的是元反射+設定豁免的方式,具體的實現可以參考GitHub上的開源專案FreeReflection,想要了解更多可自行Google查詢。
採集時機和頻率
雖然採集過程短暫無感,但為了最小的影響App的執行,我們將採集工作放在子執行緒中,並選擇在App退後臺一段時間後開始執行。
同時由於我們只需要知道程式碼使用的比例和大致情況,每次冷啟後只採集一次即可。
多位使用者多次冷啟後的資料,已經足以反映真實的程式碼使用情況了。如果需要每個類的使用頻次資料,在伺服器端聚合統計也能得到。
寫在最後
程式碼覆蓋率作為一種度量方式,不僅能為我們下線舊程式碼提供依據,同時還能反映某個功能的使用熱度,可以為資源分配、排程決策等提供依據,是軟體開發中一項不可或缺的重要工具。
我們這套全新的方案,簡潔而不簡單,巧妙地實現了無Hack採集,在保證高穩定性和不侵入原始碼的前提下,優雅地實現了生產環境程式碼覆蓋率的高效能採集,已經過高德地圖多版本驗證,是一套成熟、穩定且高效的方案。在此分享出來,希望能為有同樣訴求的同學提供一些借鑑和思路。