XV6中的鎖:MIT6.s081/6.828 lectrue10:Locking 以及 Lab8 locks Part1 心得
這節課程的內容是鎖(本節只討論最基礎的鎖)。其實鎖本身就是一個很簡單的概念,這裡的簡單包括 3 點:
- 概念簡單,和實際生活中的鎖可以類比,不像學習虛擬記憶體時,現實世界中幾乎沒有可以類比的物件,所以即使這節課偏向於理論介紹,也一點不會感覺晦澀。
- 使用簡單,幾乎所有的鎖都實現了非常簡單的api,acquire 就是獲取鎖,release 就是釋放鎖,作為使用者,用起來鎖來非常簡單(甚至比你現實中拿鑰匙開一把鎖還要簡單)
- 實現簡單,本節展示瞭如何實現一個最基礎的 spin lock,實現起來甚至一句話就可以概括:將軟體鎖轉換為硬體鎖,利用CPU的低層指令atomic swap 實現鎖。
至於CPU底層如何保證 atomic,這個話題已經超出了本節的討論範圍,甚至我的看法更加激進:如果不是CPU的設計者,壓根沒必要了解這一點,因為即使詳盡如 CPU 的 data sheet,也不會和使用者說明 atomic swap 是如何實現的,不過想要了解的童鞋看這裡:atomic的底層實現
這裡順便說一下,Lab8本來是後面的lab,但是和這一節相關度較高,所以拿到這裡講解,Lab8有兩個part,其中part1要求重新設計記憶體分配器,而part2涉及到檔案系統,所以講到檔案系統時再來講解。
鎖
為什麼要用鎖
首先考慮一個問題,單執行緒的效能是由什麼決定:是CPU的時脈頻率,頻率越快,執行一條指令所需的時間越短,從下圖可以看出,大概從2000年開始:
- CPU的時脈頻率就沒有再增加過了(綠線)。
- 這樣的結果是,CPU的單執行緒效能達到了一個極限並且也沒有再增加過(藍線)。
- 但是另一方面,CPU中的電晶體數量在持續的增加 (深紅色線)。
- 所以現在不能通過使用單核來讓程式碼執行的更快,要想執行的更快,唯一的選擇就是使用多個CPU核。所以從2000年開始,處理器上核的數量開始在增加(黑線)。
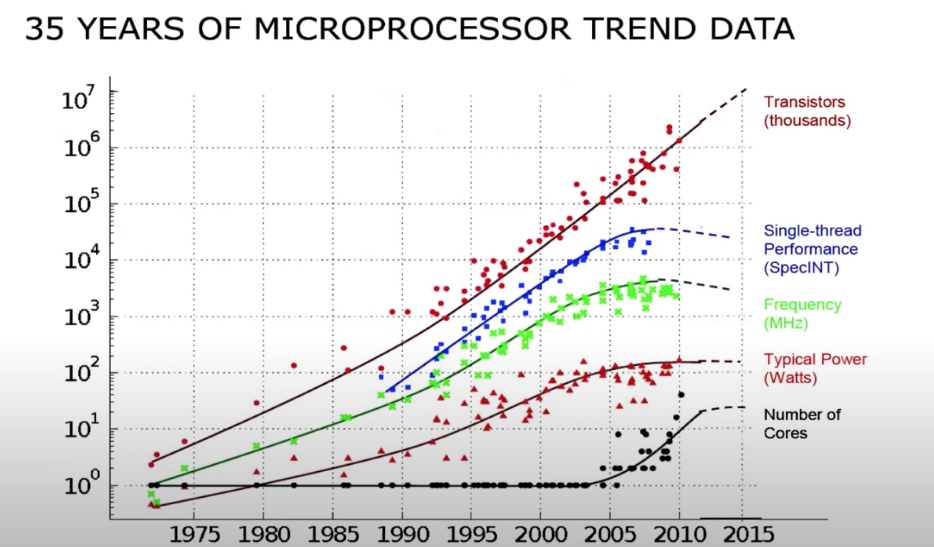
但是多核帶來的問題就是會有多個程序存取共用的資料結構,所以需要鎖,鎖可以保證共用資料的正確性
鎖是怎麼生效的
鎖就是一個物件,有一個結構體叫做 lock,它包含了一些欄位,這些欄位中維護了鎖的狀態,最典型也是最基本的一個鎖應該有以下三個欄位:是否加鎖?鎖的名字?哪個cpu核持有鎖?
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
};
鎖應該有非常直觀的API:
- acquire,接收指向lock的指標作為引數,表示要獲取這把鎖。acquire確保了在任何時間,只會有一個程序能夠成功的獲取鎖。
- release,也接收指向lock的指標作為引數,表示要釋放這把鎖。在同一時間嘗試獲取鎖的其他程序需要等待,直到持有鎖的程序對鎖呼叫release。
鎖的acquire和release之間的程式碼,通常被稱為critical section,稱為臨界區,而鎖就是保護這部分程式碼的原子性的
這裡的關鍵問題是鎖到底是怎麼做到原子性的?即鎖為什麼不能被兩個程序同時 acquire?要解答這個問題。就需要深入原始碼,看一看 acquire是如何實現的
// Acquire the lock.
// Loops (spins) until the lock is acquired.
void
acquire(struct spinlock *lk)
{
push_off(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
while(__sync_lock_test_and_set(&lk->locked, 1) != 0)
;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Record info about lock acquisition for holding() and debugging.
lk->cpu = mycpu();
}
這裡的關鍵是:while(__sync_lock_test_and_set(&lk->locked, 1) != 0),註釋中已經給出了提示,__sync_lock_test_and_set 是一個C 標準庫中的函數,用來實現 atomic swap,或者說用來實現原子性的 test and set。
這裡是需要重點解釋的地方:
-
首先解釋什麼是 test and set,就和他的名字一樣,test locked 是否為1,是 1 則說明該鎖已經被獲取,是 0 則說明該鎖沒有被獲取,就可以獲取到鎖,所謂獲取鎖就是 set locked 的值為 1,這樣其他程序就 test 到 locked 值為1,從而無法獲取鎖。
-
然後解釋 atomic swap 是什麼,這是一種底層硬體指令,幾乎所有真實的CPU都會支援這個指令,可以在硬體層面保證「原子交換」。在RISC-V中,這個特殊的指令叫 amoswap(atomic memory swap),這個指令接收3個引數,分別是address,暫存器r1,暫存器r2。這條指令可以會先鎖定住address,將address中的資料儲存在一個臨時變數中(tmp),之後將r1中的資料寫入到address中,之後再將tmp變數中的資料寫入到r2中,最後再對於地址解鎖。
相當於原子性地實現了 address->r2, r1->address -
test and set 和 atomic swap 什麼關係?答案就是 atomic swap 就可以實現 test and set :
看下面的 test and set 函數,做的工作就是 *ptr->old, new->*ptr,然後返回old,這個模式是不是和上面的 address->r2, r1->address 一模一樣?test 就是將locked的值取出賦值到old並返回,set就是將new值set到locked中
//test-and-set的C程式碼模擬 int TestAndSet(int *ptr, int new) { int old = *ptr; //抓取舊值 *ptr = new; //設定新值 return old; //返回舊值 } typedef struct __lock_t { int locked; } lock_t; void init (lock_t *lock) { lock->flag = 0; } void lock(lock_t *lock) { // 如果為 1,說明鎖被其他程序獲取 // 如果為 0,說明該程序可以獲取鎖 while (TestAndSet(&lock->flag, 1) == 1) ; //spin-wait (do noting) } void unlock (lock_t *lock) { lock->flag = 0; }
什麼時候用鎖
什麼時候才必須要加鎖呢?課程給出了一個非常保守同時也是非常簡單的規則:如果兩個程序存取了一個共用的資料結構,並且其中一個程序會更新共用的資料結構,那麼就需要對於這個共用的資料結構加鎖。
死鎖的場景
死鎖的兩個常見情形:
- 重入導致死鎖:即多次 acquire 同一個鎖,一個死鎖的最簡單的場景就是:首先acquire一個鎖,然後進入到critical section;在critical section中,再acquire同一個鎖;第二個acquire必須要等到第一個acquire狀態被release了才能繼續執行,但是不繼續執行的話又走不到第一個release,所以程式就一直卡在這了。這就是一個死鎖。(但如果是可重入鎖的話,這種情況就不會死鎖)
- 相互等待導致死鎖:兩個程序,兩個鎖,A程序需要獲取鎖1和2,B程序需要獲取鎖2和1,A獲取了1,B獲取了2;A要獲取2,B要獲取1,相互等待導致死鎖
避免死鎖的方法:使用鎖定策略(locking strategy),對鎖進行排序,所有的操作都必須以相同的順序獲取鎖。
Lab8 Part1 Memory allocator
這個lab要求重新設計記憶體分配器,原來的記憶體分配器實現如下,可以看到使用了一個連結串列 freelist 來儲存所有的空閒物理 page
// kernel/kalloc.c
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
下圖解釋了 kalloc 的執行過程,如果有程序需要記憶體空間,就呼叫kalloc函數,kalloc就會返回一個page的地址
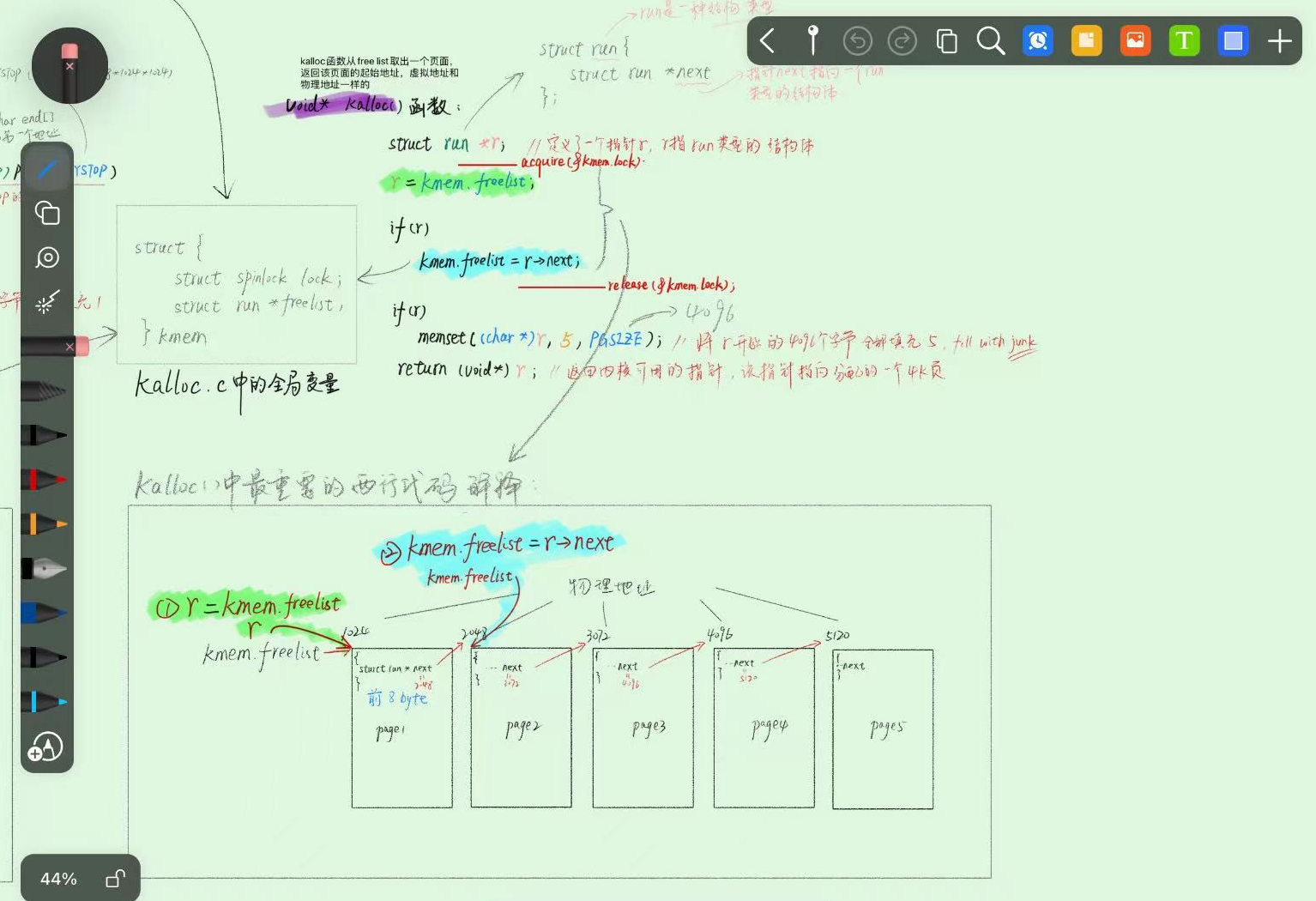
可以看到 kalloc 加了一把大鎖(即在kalloc首尾acquire和release鎖),來保護所有程序共用的資料結構 freelist,但是這樣做會有效率問題,所以lab要求在保證正確性的前提下優化這把鎖的效能。優化方式也給出來了,只需要為每個cpu core維護一個freelist就好了,然後每個freelist都有自己的鎖,之所以還要設計鎖,是因為在一個 CPU core 的 freelist 中空閒頁不足的情況下,仍需要從其他 CPU 的 freelist 中「偷」記憶體頁,所以一個 CPU core 的 freelist 還可能在「偷」記憶體頁的時候被其他 CPU core 存取,故仍然需要使用單獨的鎖來保護每個 CPU core 的 freelist。
至於怎麼偷?雨露均沾地偷?還是全部從一個 other cpu core 中偷?lab就沒有要求了,自己設計即可。
這裡的一個關鍵、也是guide中沒有提到的就是:要清楚首次初始化時所有的page都被分配給了一個 core,所以其他 core 首次呼叫 kalloc 時一定會執行 steal 動作,這裡給出修改後的kalloc程式碼:
void *
kalloc(void)
{
struct run *r;
push_off();
int cpu_id = cpuid();
acquire(&kmem[cpu_id].lock);
//steal pages form other cpu's freelist
if(!kmem[cpu_id].freelist) {
int steal_page = 32;
for(int i = 0; i < NCPU; i++) {
if(i == cpu_id) continue;
acquire(&kmem[i].lock);
struct run *rr = kmem[i].freelist;
while(rr && steal_page) {//該cpu的freelist有page,且steal_page不為0
kmem[i].freelist = rr->next;
rr->next = kmem[cpu_id].freelist;
kmem[cpu_id].freelist = rr;
rr = kmem[i].freelist;
steal_page--;
}
release(&kmem[i].lock);
if(steal_page == 0) break;
}
}
r = kmem[cpu_id].freelist;
if(r)
kmem[cpu_id].freelist = r->next;
release(&kmem[cpu_id].lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
pop_off();
return (void*)r;
}
獲得更好的閱讀體驗,這裡是我的部落格,歡迎存取:byFMH - 部落格園
所有程式碼見:我的GitHub實現(記得切換到相應分支)