詳解 canal 同步 MySQL 增量資料到 ES
canal 是阿里知名的開源專案,主要用途是基於 MySQL 資料庫增量紀錄檔解析,提供增量資料訂閱和消費。
這篇文章,我們手把手向同學們展示使用 canal 將 MySQL 增量資料同步到 ES 。
1 叢集模式
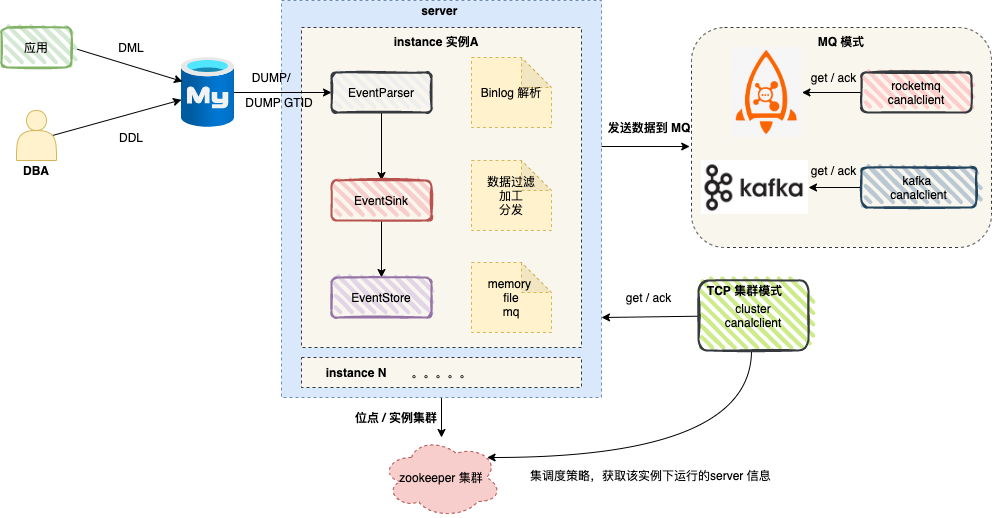
圖中 server 對應一個 canal 執行範例 ,對應一個 JVM 。
server 中包含 1..n 個 instance , 我們可以將 instance 理解為設定任務。
instance 包含如下模組 :
-
eventParser
資料來源接入,模擬 slave 協定和 master 進行互動,協定解析
-
eventSink
Parser 和 Store 連結器,進行資料過濾,加工,分發的工作
-
eventStore
資料儲存
-
metaManager
增量訂閱 & 消費資訊管理器
真實場景中,canal 高可用依賴 zookeeper ,筆者將使用者端模式可以簡單劃分為:TCP 模式 和 MQ 模式 。
MQ 模式的優勢在於解耦 ,將資料變更資訊傳送到訊息佇列 kafka 或者 RocketMQ ,消費者消費訊息,順序執行相關邏輯即可。
順序消費:
對於指定的一個 Topic ,所有訊息根據 Sharding Key 進行區塊分割區,同一個分割區內的訊息按照嚴格的先進先出(FIFO)原則進行釋出和消費。同一分割區內的訊息保證順序,不同分割區之間的訊息順序不做要求。

2 MySQL設定
1、對於自建 MySQL , 需要先開啟 Binlog 寫入功能,設定 binlog-format 為 ROW 模式,my.cnf 中設定如下
[mysqld]
log-bin=mysql-bin # 開啟 binlog
binlog-format=ROW # 選擇 ROW 模式
server_id=1 # 設定 MySQL replaction 需要定義,不要和 canal 的 slaveId 重複
注意:針對阿里雲 RDS for MySQL , 預設開啟了 binlog , 並且賬號預設具有 binlog dump 許可權 , 不需要任何許可權或者 binlog 設定,可以直接跳過這一步。
2、授權 canal 連結 MySQL 賬號具有作為 MySQL slave 的許可權, 如果已有賬戶可直接 grant 。
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
3、建立資料庫商品表 t_product 。
CREATE TABLE `t_product` (
`id` BIGINT ( 20 ) NOT NULL AUTO_INCREMENT,
`name` VARCHAR ( 255 ) COLLATE utf8mb4_bin NOT NULL,
`price` DECIMAL ( 10, 2 ) NOT NULL,
`status` TINYINT ( 4 ) NOT NULL,
`create_time` datetime NOT NULL,
`update_time` datetime NOT NULL,
PRIMARY KEY ( `id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin
3 Elasticsearch設定
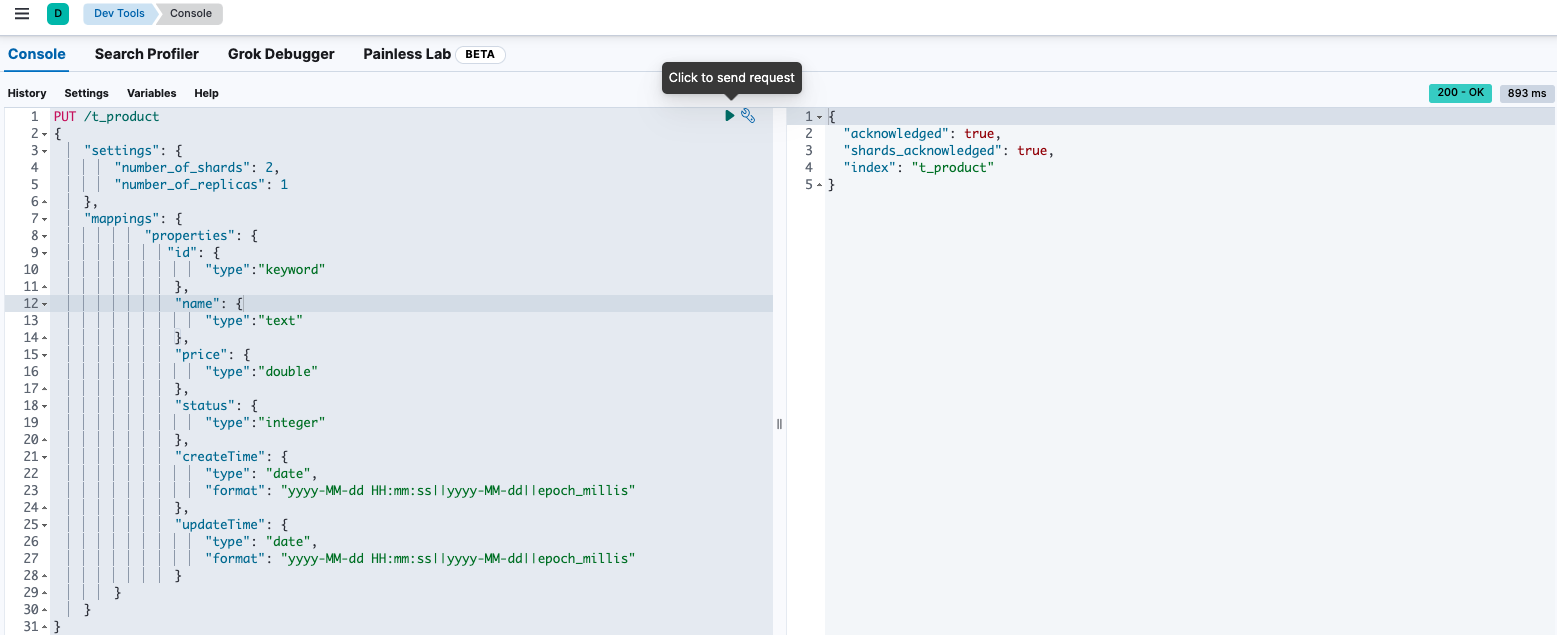
使用 Kibana 建立商品索引 。
PUT /t_product
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"id": {
"type":"keyword"
},
"name": {
"type":"text"
},
"price": {
"type":"double"
},
"status": {
"type":"integer"
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"updateTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
執行完成,如圖所示 :
4 RocketMQ 設定
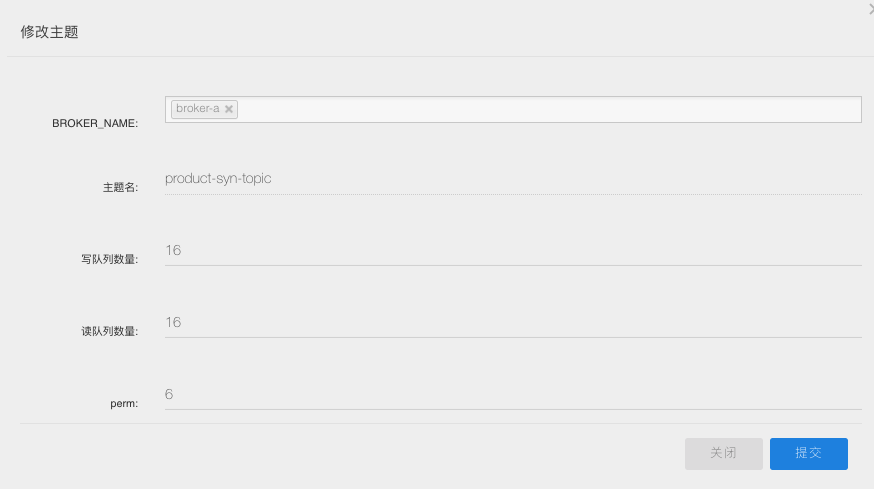
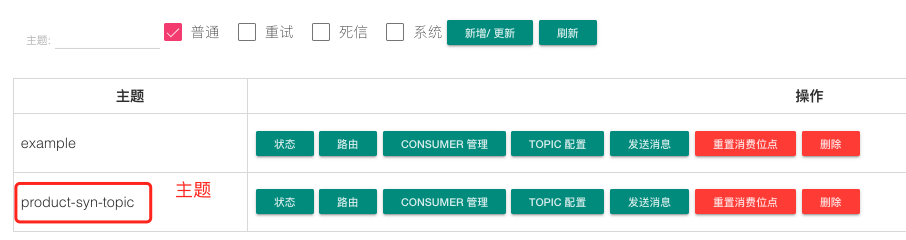
建立主題:product-syn-topic ,canal 會將 Binlog 的變化資料傳送到該主題。
5 canal 設定
我們選取 canal 版本 1.1.6 ,進入 conf 目錄。
1、設定 canal.properties
#叢集模式 zk地址
canal.zkServers = localhost:2181
#本質是MQ模式和tcp模式 tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ
canal.serverMode = rocketMQ
#instance 列表
canal.destinations = product-syn
#conf root dir
canal.conf.dir = ../conf
#全域性的spring設定方式的元件檔案 生產環境,叢集化部署
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
###### 以下部分是預設值 展示出來
# Canal的batch size, 預設50K, 由於kafka最大訊息體限制請勿超過1M(900K以下)
canal.mq.canalBatchSize = 50
# Canal get資料的超時時間, 單位: 毫秒, 空為不限超時
canal.mq.canalGetTimeout = 100
# 是否為 flat json格式物件
canal.mq.flatMessage = true
2、instance 組態檔
在 conf 目錄下建立範例目錄 product-syn , 在 product-syn 目錄建立組態檔 :instance.properties。
# 按需修改成自己的資料庫資訊
#################################################
...
canal.instance.master.address=192.168.1.20:3306
# username/password,資料庫的使用者名稱和密碼
...
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
...
# table regex
canal.instance.filter.regex=mytest.t_product
# mq config
canal.mq.topic=product-syn-topic
# 針對庫名或者表名傳送動態topic
#canal.mq.dynamicTopic=mytest,.*,mytest.user,mytest\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#庫名.表名: 唯一主鍵,多個表之間用逗號分隔
#canal.mq.partitionHash=mytest.person:id,mytest.role:id
#################################################
3、服務啟動
啟動兩個 canal 服務,我們從 zookeeper gui 中檢視服務執行情況 。
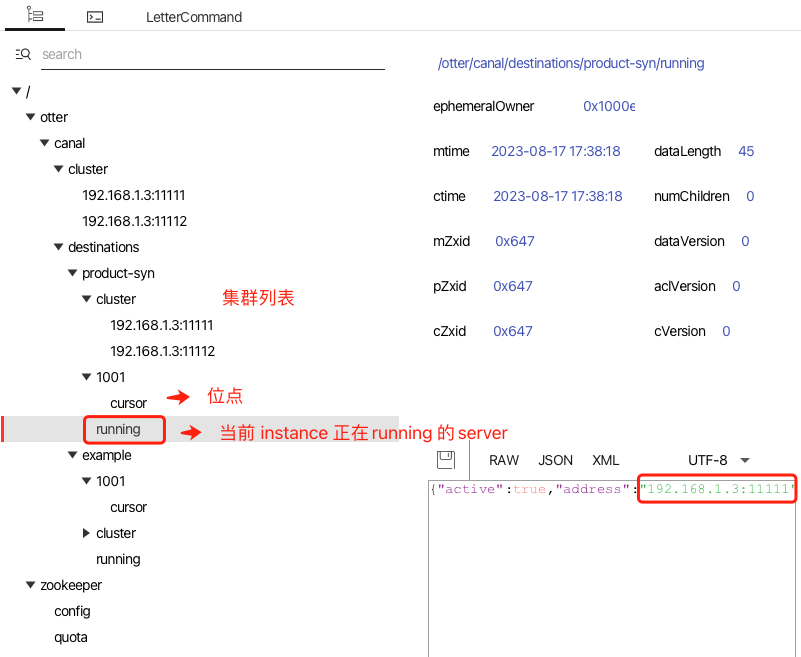
修改一條 t_product 表記錄,可以從 RocketMQ 控制檯中觀測到新的訊息。

6 消費者
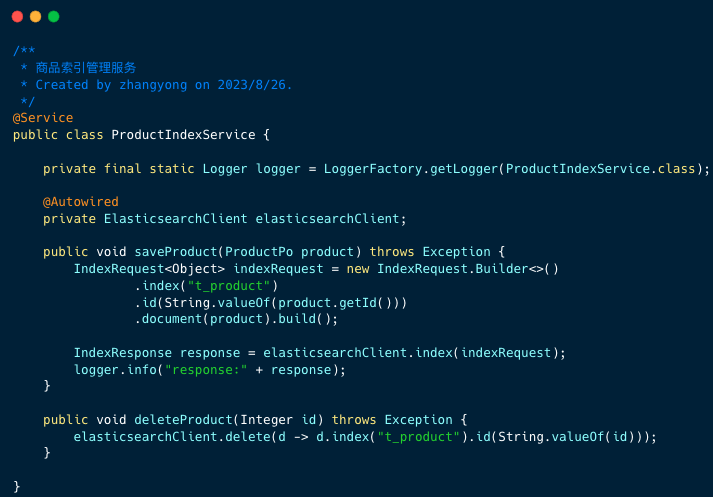
1、產品索引操作服務
2、消費監聽器
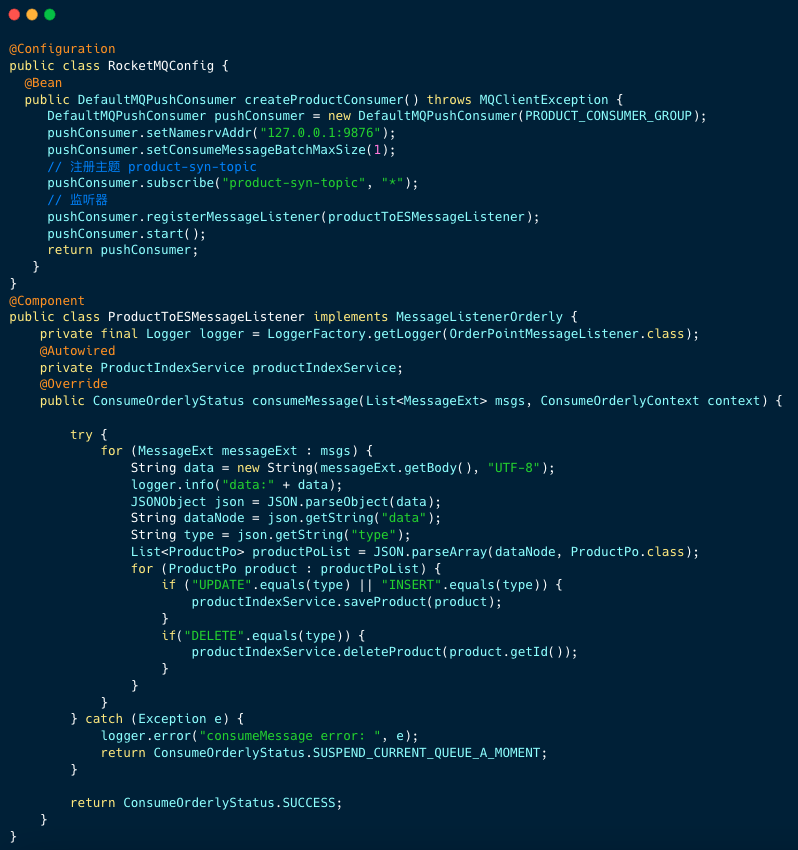
消費者邏輯重點有兩點:
- 順序消費監聽器
- 將訊息資料轉換成 JSON 字串,從
data節點中獲取表最新資料(批次操作可能是多條)。然後根據操作型別UPDATE、INSERT、DELETE執行產品索引操作服務的方法。
7 寫到最後
canal 是一個非常有趣的開源專案,很多公司使用 canal 構建資料傳輸服務( Data Transmission Service ,簡稱 DTS ) 。
推薦大家閱讀這個開源專案,你可以從中學習到網路程式設計、多執行緒模型、高效能佇列 Disruptor 等。
這篇文章涉及到的程式碼已收錄到下面的工程中,有興趣的同學可以一看。

如果我的文章對你有所幫助,還請幫忙點贊、在看、轉發一下,你的支援會激勵我輸出更高質量的文章,非常感謝!
