基於bert-base-chinese訓練bert模型(最後附上整體程式碼)
目錄:
一、bert-base-chinese模型下載
二、資料集的介紹
三、完成類的程式碼
四、寫訓練方法
五、總原始碼及原始碼參考出處
一、bert-base-chinese模型下載
對於已經預訓練好的模型bert-base-chinese的下載可以去Hugging face下載,網址是:Hugging Face – The AI community building the future.
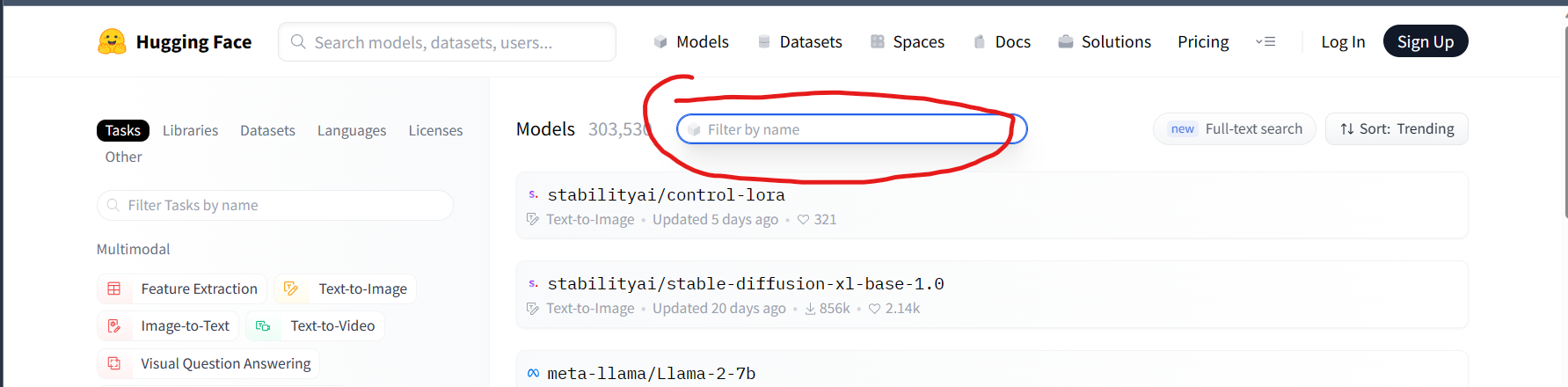
開啟網址後,選擇上面的Model

然後在右下的搜尋方塊輸入bert
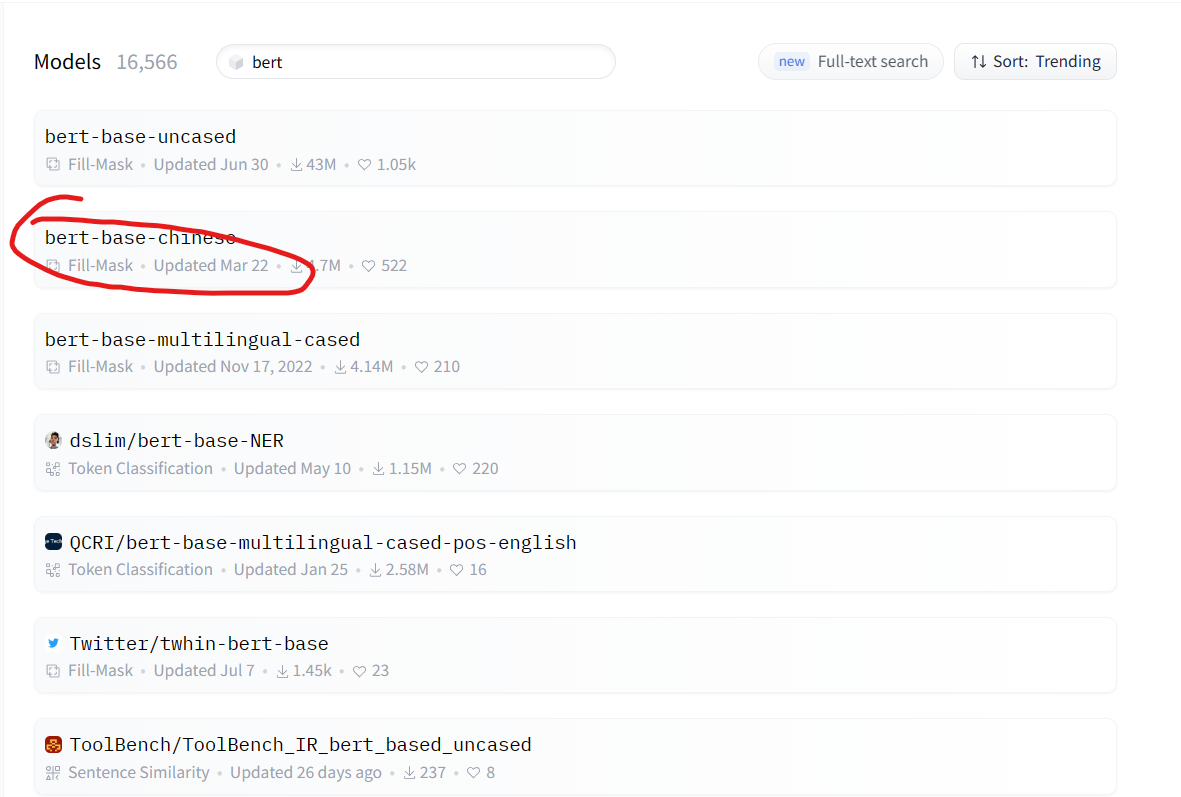
接著下載自己所需要的模型就可以了,uncase是指不區分大小寫。這裡作者下載的是bert-base-chinese,用於處理中文。
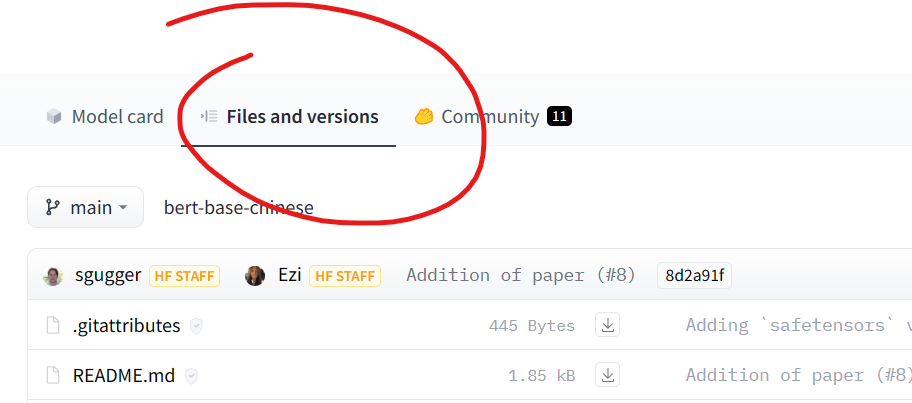
開啟後,選擇如下圖
然後下載下圖對應名字的檔案即可

二、對於資料集的介紹
我使用的資料集是從DataWhale下載的,我也忘了叫啥[手動滑稽],好像是根據評論來決定是否推薦該店家給存取者
我在這留下我的資料集吧,用百度網路硬碟的
連結:https://pan.baidu.com/s/1AW3CMzuRHD3WQToxL7v0fw
提取碼:eq1p
在資料集裡面,它是把資料一個一個文字分開的
這裡作者給讀者提供一程式碼,可以實現把分散.txt檔案合併為一個.txt文字,其實也不難,也可以自己寫
import os meragefiledir = '替換成對應資料夾的絕對路徑' #獲取當前資料夾中的檔名稱列表 filenames=os.listdir(meragefiledir) #開啟當前目錄下的result.txt檔案,如果沒有則建立 file=open('這就是合併後的檔名','+w', encoding='utf8') #向檔案中寫入字元 #先遍歷檔名 for filename in filenames: filepath=meragefiledir+'\\' filepath=filepath+filename #遍歷單個檔案,讀取行數 for line in open(filepath, encoding='utf8'): file.writelines(line) file.write('\n') #關閉檔案 file.close()
然後把檔案字尾改為.csv,千萬別忘了在資料集的頭部加上索引,這個是自己決定的,你可以隨意取,只不過下面的程式碼對應的地方也要改而已,記得是英文符號的逗號哦


前面的1 0代表的是是否推薦該店,後面的是每一家的顧客評論
對於資料集的劃分,作者是在寫程式碼前手動劃分的,畢竟資料集並不大[狗頭]
作者把資料集劃分為以下(隨便劃分即可,畢竟作者不可能用一臺小筆電就跑完所有資料集的,保證每個資料集不少於500個即可,因為作者在後續程式碼中會取每個資料集的前五百個來訓練模型)
三、完成類的程式碼
注:程式碼中的地址按自己的實際情況更改
一共要實現兩個類,一個是Dataset類,另一個是BertClassifier
接下來實現Dataset,總體來說程式碼是這樣的
from torch.utils.data import DataLoader, Dataset # 先準備分詞器和標籤 tokenizer = BertTokenizer.from_pretrained('bert-chinese') # 重寫Dataset class Dataset(Dataset): def __init__(self, df): self.labels = df['YN'] self.texts = [tokenizer(text, padding='max_length', max_length = 512, truncation=True, return_tensors="pt") for text in df['V']] def __len__(self): return len(self.labels) def __getitem__(self, idx): batch_texts = self.get_batch_texts(idx) batch_y = self.get_batch_labels(idx) return batch_texts, batch_y def classes(self): # 返回文字標籤 return self.labels def get_batch_labels(self, idx): # 獲取標籤 return np.array(self.labels[idx]) def get_batch_texts(self, idx): # 獲取inputs return self.texts[idx]
這個類的主要作用就是把主要資料和標籤存入這個類的物件裡,然後用這個類的屬性和方法去描述這個資料集,例如labels是所有的標籤,_len_()是獲取資料集長度的方法
在該類裡面,_init_(),_len_(),_getiem_()是魔術方法,分別用來構造類的物件的屬性,得到Dataset類的物件裡面的資料量,取得idx對應的資料的資訊,classes()用來獲取資料的所有標籤,get_batch_labels()和get_batch_texts()分別是用來獲取idx對應的標籤或主要資料
對於BertClassifier類的重寫程式碼如下
1 from torch import nn 2 from transformers import BertModel 3 4 # 構建實際模型 5 class BertClassifier(nn.Module): 6 def __init__(self, dropout=0.5): 7 super(BertClassifier, self).__init__() 8 self.bert = BertModel.from_pretrained('bert-chinese') 9 self.dropout = nn.Dropout(dropout) 10 self.linear = nn.Linear(768, 5) 11 self.relu = nn.ReLU() 12 13 def forward(self, input_id, mask): 14 _, pooled_output = self.bert(input_ids= input_id, 15 attention_mask=mask, 16 return_dict=False) 17 dropout_output = self.dropout(pooled_output) 18 linear_output = self.linear(dropout_output) 19 final_layer = self.relu(linear_output) 20 return final_layer
在該類裡面,其繼承自torch.model
寫了_init_()魔術方法和forward()
_init_()方法:
第7行,其裡面的super是指在建立 BertClassifier 類的新範例時,首先呼叫其父類別的建構函式,需要繼承其父類別的建構函式的原因是,其父類別的建構函式可以預設設定一些值,這樣就不用我們自己去把寫含有所 有引數的建構函式。
第8行,其程式碼的作用是從預訓練模型庫中載入中文BERT模型,並將其賦值給self.bert,也就是匯入前文在Huggingface下載預訓練模型,裡面填的是路徑。
第9行,該行程式碼的作用是為模型新增一個Dropout層,其中dropout是丟棄率,表示在訓練過程中隨機丟棄神經元的概率。Dropout層通常用於防止過擬合。
第10行,這行程式碼定義了一個全連線層(線性層),輸入特徵數為768,輸出特徵數為5。全連線層通常用於將前一層的輸出對映到更復雜的空間。
第11行,這行程式碼定義了一個ReLU啟用函數層。ReLU函數的特徵是,小於零的輸入,會得到輸出為0,如若輸入大於零,者輸出輸入。
forward()方法:
第14行,input_ids是輸入序列的ID,attention_mask是用於遮蓋輸入序列中的填充符號的掩碼(例子:「[CLS] 你好,世界! 這個序列包含了一個填充符號。 [MASK]」,[MASK]就是掩碼,需要掩碼的原因是在輸入資料時,資料長短不一,通常會填充一些符號來使所有輸入長度一致),return_dict是一個布林值,表示是否返回每個標記的隱藏狀態。函數的第一個返回值是每個輸入標記的隱藏狀態,第二個返回值是整個句子的隱藏狀態。如果return_dict為True,則還返回每個標記的隱藏狀態。該行程式碼的主要是接受整個句子的狀態,以便用於句子分類。
第17行,是使用dropout()來把pooled_output正則化,以防止過擬合。
第18行,是把正則化後的資料放入全連線層
第19行,是把全連線層的輸出通過ReLU函數進行轉化
四、寫訓練函數
程式碼如下
1 from torch.optim import Adam 2 from tqdm import tqdm 3 4 def train(model, train_data, val_data, learning_rate, epochs): 5 # 處理資料 6 # 通過Dataset類獲取訓練和驗證集 7 train, val = Dataset(train_data), Dataset(val_data) 8 # DataLoader根據batch_size獲取資料,訓練時選擇打亂樣本 9 train_dataloader = DataLoader(train, batch_size=2,shuffle=True) 10 val_dataloader = DataLoader(val, batch_size=2) 11 12 # 判斷是否使用GPU 13 use_cuda = torch.cuda.is_available() 14 device = torch.device("cuda" if use_cuda else "cpu") 15 16 # 定義損失函數和優化器 17 criterion = nn.CrossEntropyLoss() 18 optimizer = Adam(model.parameters(), lr=learning_rate) 19 20 if use_cuda: 21 model = model.cuda() 22 criterion = criterion.cuda() 23 24 # 開始進入訓練迴圈 25 for epoch_num in range(epochs): 26 # 定義兩個變數,用於儲存訓練集的準確率和損失 27 total_acc_train = 0 28 total_loss_train = 0 29 # 進度條函數tqdm 30 for train_input, train_label in tqdm(train_dataloader): 31 32 train_label = train_label.to(device) 33 mask = train_input['attention_mask'].to(device) 34 input_id = train_input['input_ids'].squeeze(1).to(device) 35 # 通過模型得到輸出 36 output = model(input_id, mask) 37 # 計算損失 38 batch_loss = criterion(output, train_label) 39 total_loss_train += batch_loss.item() 40 # 計算精度 41 acc = (output.argmax(dim=1) == train_label).sum().item() 42 total_acc_train += acc 43 # 模型更新 44 model.zero_grad() 45 batch_loss.backward() 46 optimizer.step() 47 # ------ 驗證模型 ----------- 48 # 定義兩個變數,用於儲存驗證集的準確率和損失 49 total_acc_val = 0 50 total_loss_val = 0 51 # 不需要計算梯度 52 with torch.no_grad(): 53 # 迴圈獲取資料集,並用訓練好的模型進行驗證 54 for val_input, val_label in val_dataloader: 55 # 如果有GPU,則使用GPU,接下來的操作同訓練 56 val_label = val_label.to(device) 57 mask = val_input['attention_mask'].to(device) 58 input_id = val_input['input_ids'].squeeze(1).to(device) 59 60 output = model(input_id, mask) 61 62 batch_loss = criterion(output, val_label) 63 total_loss_val += batch_loss.item() 64 65 acc = (output.argmax(dim=1) == val_label).sum().item() 66 total_acc_val += acc 67 68 print( 69 f'''Epochs: {epoch_num + 1} 70 | Train Loss: {total_loss_train / len(train_data): .3f} 71 | Train Accuracy: {total_acc_train / len(train_data): .3f} 72 | Val Loss: {total_loss_val / len(val_data): .3f} 73 | Val Accuracy: {total_acc_val / len(val_data): .3f}''')
在這個方法裡面有五個引數,分別是:預訓練好的模型,訓練集,測試集,學習率(一般的級數都是十的負五次方)和訓練次數。
而方法有三個大塊:資料處理,呼叫GPU或CPU,訓練模型。
首先是資料處理。先把傳進來的dataframe型別資料轉成dataset型別,也就是我們在上文寫的第一個類。然後把dataset型別的資料作為引數傳入dataloader的範例裡面,dataloader的作用是把傳入的資料自動分成一個個batch(即將資料分成多個小組,每個小組裡面有batch_size個資料,在使用時,它會每次丟擲一組資料,直到拋完。用dataloader是因為可以很方便的生成迭代資料)。
其次是是否使用GPU。13行是檢視電腦是否有可用的GPU,如果有則返回True,反之就是False。14行是決定張量是放在GPU還是CPU,optimizer = Adam(model.parameters(), lr=learning_rate)建立了一個Adam優化器物件,其中model.parameters()返回一個迭代器,裡面包含了模型中所有可訓練的引數,也就是要在後續訓練中不斷迭代的資料。20、21、22行是實現把模型和損失函數移到GPU上面(如果存在)
最後也是最重要的訓練模型時間了。這裡把程式碼拿出來來講
1 # 開始進入訓練迴圈 2 for epoch_num in range(epochs): 3 # 定義兩個變數,用於儲存訓練集的準確率和損失 4 total_acc_train = 0 5 total_loss_train = 0 6 # 進度條函數tqdm 7 for train_input, train_label in tqdm(train_dataloader): 8 9 train_label = train_label.to(device) 10 mask = train_input['attention_mask'].to(device) 11 input_id = train_input['input_ids'].squeeze(1).to(device) 12 # 通過模型得到輸出 13 output = model(input_id, mask) 14 # 計算損失 15 batch_loss = criterion(output, train_label) 16 total_loss_train += batch_loss.item() 17 # 計算精度 18 acc = (output.argmax(dim=1) == train_label).sum().item() 19 total_acc_train += acc 20 # 模型更新 21 model.zero_grad() 22 batch_loss.backward() 23 optimizer.step() 24 # ------ 驗證模型 ----------- 25 # 定義兩個變數,用於儲存驗證集的準確率和損失 26 total_acc_val = 0 27 total_loss_val = 0 28 # 不需要計算梯度 29 with torch.no_grad(): 30 # 迴圈獲取資料集,並用訓練好的模型進行驗證 31 for val_input, val_label in val_dataloader: 32 # 如果有GPU,則使用GPU,接下來的操作同訓練 33 val_label = val_label.to(device) 34 mask = val_input['attention_mask'].to(device) 35 input_id = val_input['input_ids'].squeeze(1).to(device) 36 37 output = model(input_id, mask) 38 39 batch_loss = criterion(output, val_label) 40 total_loss_val += batch_loss.item() 41 42 acc = (output.argmax(dim=1) == val_label).sum().item() 43 total_acc_val += acc 44 45 print( 46 f'''Epochs: {epoch_num + 1} 47 | Train Loss: {total_loss_train / len(train_data): .3f} 48 | Train Accuracy: {total_acc_train / len(train_data): .3f} 49 | Val Loss: {total_loss_val / len(val_data): .3f} 50 | Val Accuracy: {total_acc_val / len(val_data): .3f}''')
首先是把控制訓練次數也就是模型迭代次數的epochs設為迴圈次數,控制模型訓練的次數(過低過高都會造成過擬合)。
第一個步驟沒什麼好說的
然後是用訓練集來訓練模型
tqdm進度條函數怎麼用可以上網搜,主要是用來實現把訓練進度視覺化,to(device)是把資料傳到指定裝置(CPU或GPU)。
1、得到輸出
想要通過模型得到輸出的話是直接傳入input_id和mask即可,input_id代表的是經過分詞器處理後得到的資料。
2、獲取損失值和精確值
計算損失是用前面定義的損失函數criterion()來計算的,然後下一行的.item()是用來把包含一個張量資料提取出標量來。計算精確度中,output,argmax(dim=0)會返回預測值,判斷是否與原標籤相等後,sum()會把True和False相加起來。他們都是通過累加來把每一小組的損失值和精確值加入到總損失值和總精確值。
3、更新模型
model.zero_grad()將模型中的梯度快取清零,以便開始新的一輪反向傳播。
batch_loss.backward()對損失函數進行反向傳播,計算每個引數的梯度。
optimizer.step()根據計算出的梯度更新模型引數。在每個引數上呼叫該函數會將該引數向其最優值移動一步。
當進度條函數的迴圈完成後,就來到了驗證模型的程式碼了
同樣,定義變數沒什麼好說的
不需要計算梯度是因為這是驗證集用來驗證模型的,不用更新模型什麼的,接下來的思路與什麼訓練集訓練模型的一樣
最後就是輸出這個模型在訓練集和驗證集上面的精確值和損失值
# 獲得資料集,並拆分為訓練集和測試集 _train = pd.read_csv( 'C:\\Users\\xie zhou yao\\bert\\data\\train.csv') _val = pd.read_csv( 'C:\\Users\\xie zhou yao\\bert\\data\\val.csv') _test = pd.read_csv( 'C:\\Users\\xie zhou yao\\bert\\data\\test.csv') _test_handout = pd.read_csv( 'C:\\Users\\xie zhou yao\\bert\\data\\test_handout.csv') _train = _train[0:500] _val = _val[0:500] _test = _test[0:500] _test_handout = _test_handout[0:500] EPOCHS = 3 model = BertClassifier() LR = 1e-5 train(model, _train, _val, LR, EPOCHS)
最後的最後 ,我們的長征已經來到最後了,直接設引數,呼叫train方法,最後模型訓練王成!!!!
注意,本文並未實現模型的儲存!!!
五、總原始碼及原始碼參考出處
我參考了這位大佬的程式碼:保姆級教學,用PyTorch和BERT進行文字分類 - 知乎 (zhihu.com)
如若介意,聯絡即刪[手動滑稽]
# 匯入所需庫 import torch import torch.nn as nn import pandas as pd import numpy as np from torch.utils.data import DataLoader, Dataset from transformers import BertTokenizer, BertForSequenceClassification, AdamW # 準備資料集 # 先準備分詞器和標籤 tokenizer = BertTokenizer.from_pretrained('bert-chinese') #定義一個類 class Dataset(Dataset): def __init__(self, df): self.labels = df['YN'] self.texts = [tokenizer(text, padding='max_length', max_length = 512, truncation=True, return_tensors="pt") for text in df['V']] def __len__(self): return len(self.labels) def __getitem__(self, idx): batch_texts = self.get_batch_texts(idx) batch_y = self.get_batch_labels(idx) return batch_texts, batch_y def classes(self): # 返回文字標籤 return self.labels def get_batch_labels(self, idx): # 獲取一批標籤 return np.array(self.labels[idx]) def get_batch_texts(self, idx): # 獲取一批inputs return self.texts[idx] from torch import nn from transformers import BertModel # 構建實際模型 class BertClassifier(nn.Module): def __init__(self, dropout=0.5): super(BertClassifier, self).__init__() self.bert = BertModel.from_pretrained('bert-chinese') self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(768, 5) self.relu = nn.ReLU() def forward(self, input_id, mask): _, pooled_output = self.bert(input_ids= input_id, attention_mask=mask, return_dict=False) dropout_output = self.dropout(pooled_output) linear_output = self.linear(dropout_output) final_layer = self.relu(linear_output) return final_layer from torch.optim import Adam from tqdm import tqdm def train(model, train_data, val_data, learning_rate, epochs): ##處理資料 # 通過Dataset類獲取訓練和驗證集 train, val = Dataset(train_data), Dataset(val_data) # DataLoader根據batch_size獲取資料,訓練時選擇打亂樣本 train_dataloader = DataLoader(train, batch_size=2, shuffle=True) val_dataloader = DataLoader(val, batch_size=2) # 判斷是否使用GPU use_cuda = torch.cuda.is_available() device = torch.device("cuda" if use_cuda else "cpu") # 定義損失函數和優化器 criterion = nn.CrossEntropyLoss() optimizer = Adam(model.parameters(), lr=learning_rate) if use_cuda: model = model.cuda() criterion = criterion.cuda() # 開始進入訓練迴圈 for epoch_num in range(epochs): # 定義兩個變數,用於儲存訓練集的準確率和損失 total_acc_train = 0 total_loss_train = 0 # 進度條函數tqdm for train_input, train_label in tqdm(train_dataloader): train_label = train_label.to(device) mask = train_input['attention_mask'].to(device) input_id = train_input['input_ids'].squeeze(1).to(device) # 通過模型得到輸出 output = model(input_id, mask) # 計算損失 batch_loss = criterion(output, train_label) total_loss_train += batch_loss.item() # 計算精度 acc = (output.argmax(dim=1) == train_label).sum().item() total_acc_train += acc # 模型更新 model.zero_grad() batch_loss.backward() optimizer.step() # ------ 驗證模型 ----------- # 定義兩個變數,用於儲存驗證集的準確率和損失 total_acc_val = 0 total_loss_val = 0 # 不需要計算梯度 with torch.no_grad(): # 迴圈獲取資料集,並用訓練好的模型進行驗證 for val_input, val_label in val_dataloader: # 如果有GPU,則使用GPU,接下來的操作同訓練 val_label = val_label.to(device) mask = val_input['attention_mask'].to(device) input_id = val_input['input_ids'].squeeze(1).to(device) output = model(input_id, mask) batch_loss = criterion(output, val_label) total_loss_val += batch_loss.item() acc = (output.argmax(dim=1) == val_label).sum().item() total_acc_val += acc print( f'''Epochs: {epoch_num + 1} | Train Loss: {total_loss_train / len(train_data): .3f} | Train Accuracy: {total_acc_train / len(train_data): .3f} | Val Loss: {total_loss_val / len(val_data): .3f} | Val Accuracy: {total_acc_val / len(val_data): .3f}''') # 獲得資料集,並拆分為訓練集和測試集 _train = pd.read_csv( 'C:\\Users\\xie zhou yao\\bert\\data\\train.csv') _val = pd.read_csv( 'C:\\Users\\xie zhou yao\\bert\\data\\val.csv') _test = pd.read_csv( 'C:\\Users\\xie zhou yao\\bert\\data\\test.csv') _test_handout = pd.read_csv( 'C:\\Users\\xie zhou yao\\bert\\data\\test_handout.csv') _train = _train[0:500] _val = _val[0:500] _test = _test[0:500] _test_handout = _test_handout[0:500]
# 訓練模型 EPOCHS = 3 model = BertClassifier() LR = 1e-5 train(model, _train, _val, LR, EPOCHS)
(ps:該隨筆是作者一邊學習一邊寫的,裡面有一些自己的拙見,如果有錯誤或者哪裡可以改正的話,還請大家指出並批評改正!)