Redis系列21:快取與資料庫的資料一致性討論
Redis系列1:深刻理解高效能Redis的本質
Redis系列2:資料持久化提高可用性
Redis系列3:高可用之主從架構
Redis系列4:高可用之Sentinel(哨兵模式)
Redis系列5:深入分析Cluster 叢集模式
追求效能極致:Redis6.0的多執行緒模型
追求效能極致:使用者端快取帶來的革命
Redis系列8:Bitmap實現億萬級資料計算
Redis系列9:Geo 型別賦能億級地圖位置計算
Redis系列10:HyperLogLog實現海量資料基數統計
Redis系列11:記憶體淘汰策略
Redis系列12:Redis 的事務機制
Redis系列13:分散式鎖實現
Redis系列14:使用List實現訊息佇列
Redis系列15:使用Stream實現訊息佇列
Redis系列16:聊聊布隆過濾器(原理篇)
Redis系列17:聊聊布隆過濾器(實踐篇)
Redis系列18:過期資料的刪除策略
Redis系列19:LRU淘汰記憶體淘汰演演算法分析
Redis系列20:LFU淘汰記憶體淘汰演演算法分析
1 介紹
1.1 資料一致性的概念
快取與資料庫的資料一致性指的是,快取中儲存的資料與資料庫中儲存的資料需保持一致。
即快取中存有資料,快取的資料值 = 資料庫中的值;快取中沒有該資料,資料庫中的值 = 最新值。資料一致性主要包含以下兩種情況:
- 快取中有資料,那麼快取中的值需要和資料庫中值相同。
- 快取中本身沒有資料,那麼,資料庫中的值必須是最新值。
如果存在以下情況,則說明存在不一致性情況:
- 快取中有資料,但是快取中的資料與資料庫中的資料不一致。
- 快取或者資料庫中存在舊的資料,導致單個執行緒讀到的資料是舊的。
1.2 資料不一致的原因
快取(Redis)和 資料庫(MySQL)是兩套系統,所以任何一方的資料改寫,都需要另一方的協同來保證。但這種協同可能存在一定的失敗率,如下:
- 資料庫更新出錯:在更新資料庫時發生錯誤,導致快取中的資料與資料庫中的資料不一致。
- 快取重新整理機制錯誤:一些快取系統可能存在重新整理機制的問題,導致快取中的資料沒有及時更新,從而與資料庫資料出現不一致的情況。
- 並行請求:當有多個請求同時進行操作時,由於快取、資料庫操作的順序和時機不同,可能造成不一致的情況。
- 資料一致性策略不當:在實現快取和資料庫的資料一致性策略時,如果選擇不當的資料一致性策略,可能會導致資料不一致的情況。
為了保持快取和資料庫的資料一致性,需要採取適當的一致性策略(如引入 2PC 或 Paxos 等分散式一致性協定,或者分散式鎖),並及時處理資料庫更新和快取重新整理中的錯誤。同時,在實現並行請求時,需要合理控制操作的順序和時機,以避免不一致的情況發生。
2 快取的執行策略
我們先來了解下快取常用的執行策略,再分析下那種策略最適合一致性保障。
- Cache-Aside(快取旁路):這是最廣泛使用的快取策略之一。在讀取資料時,先從快取中讀取資料,如果快取中沒有資料,則從資料庫中讀取資料,並將讀取到的資料儲存到快取中。在寫入資料時,先寫入資料庫,然後更新快取中的資料。這個策略可以極大地提高讀取效能,但是可能會降低寫入效能。
- Read-Through(讀穿透):這個策略類似於Cache-Aside,但是它會自動從快取中讀取資料,而不需要先從資料庫中讀取資料。如果快取中沒有資料,則自動從資料庫中讀取資料,並將讀取到的資料儲存到快取中。這個策略可以提高讀取效能,但是可能會增加資料庫的負載。
- Write-Through(寫貫穿):這個策略類似於Cache-Aside,但是在寫入資料時,它會直接寫入快取和資料庫,而不是先寫入資料庫再更新快取。這個策略可以提高寫入效能,但是可能會降低快取的利用率。
- Write-Behind(寫後置):這個策略類似於Write-Through,但是在寫入資料時,它會非同步地更新快取和資料庫,而不是立即更新。這個策略可以提高寫入效能,但是可能會增加資料庫的負載和快取的不一致性。
- Update-In-Place(原地更新):這種策略在快取中直接更新資料,而不是先刪除舊資料再新增新資料。這樣可以減少快取的衝突,但是可能會增加快取的大小和記憶體消耗。
- Write-Back(回寫):這種策略在寫入資料時,先更新快取,然後再非同步地更新資料庫。這樣可以提高寫入效能,但是可能會增加快取的不一致性和資料庫的負載。
- Partitioning(分割區):這種策略將快取分成多個分割區,不同的資料分割區採用不同的快取策略,以適應不同的存取模式和負載情況。
2.1 Cache-Aside(快取旁路)
快取旁路策略也是目前業務系統最常用的策略。在Cache-Aside機制中,系統將快取視為一個輔助的儲存媒介,所有的讀取快取、讀取資料庫和更新快取的操作都由應用服務來完成。
2.1.1 讀取資料
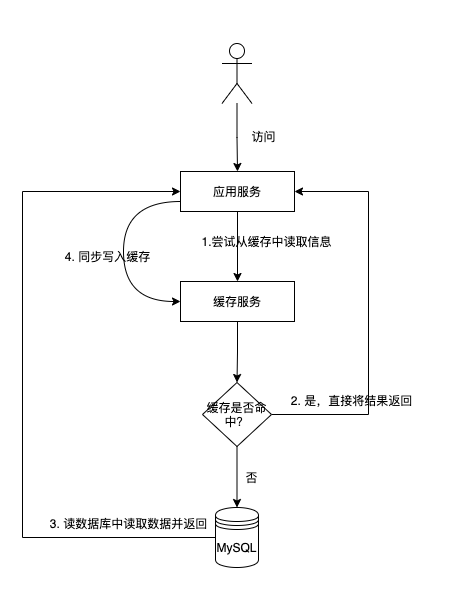
讀取快取資料的步驟如下:
- 當需要存取某個資料時,系統首先嚐試從快取中獲取該資料,檢查快取是否命中。
- 如果快取中不存在該資料,則從資料庫等資料來源中獲取資料,並將資料進行快取更新。此時,快取中就有了該資料的副本,下次需要存取該資料時就可以直接從快取中獲取,而無需再次查詢資料庫。
- 如果快取中存在該資料,則代表快取命中,直接返回。
程式實現如下(go 語言版本虛擬碼):
func main() {
// 嘗試從快取獲取資料
cacheValue := getFromCache("testinfo")
if cacheValue != "" {
return cacheValue
} else {
// 如果快取缺失,則從資料庫獲取資料
cacheValue = getDataFromDB()
// 將資料寫入快取
setInCache(cacheValue)
return cacheValue
}
}
2.1.2 更新資料
更新資料的步驟如下:
- 當進行資料更新時,先將資料更新到資料庫中
- 還需要同時更新快取或者將快取進行失效(寫時更新)
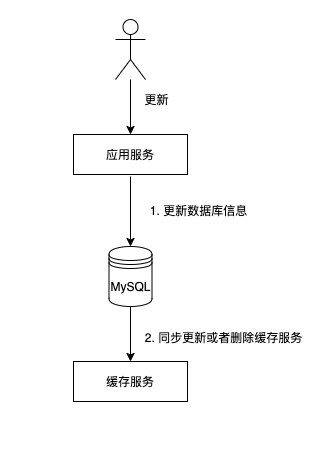
可以看到資料庫更新之後,讓快取與資料庫的同步的方式有兩種,一種是同步去更新快取的value,一種是直接刪除資料庫。
因為高頻模式下,更新夠頻繁,更新執行緒的執行先後可能導致髒資料情況,所以比較常用的方式是刪除快取使快取資料失效來實現同步。具體優勢如下:
- 效能優勢
如果快取的更新成本很高,存取頻率不高,建議直接刪除快取,而不是更新快取資料來保證一致性。因為可能你的快取更新之後長時間沒有被使用,那還不如使用的時候建立。 - 安全優勢
在高並行場景下,多執行緒可能會造成查詢查到的資料是舊值。
程式實現如下(go 語言版本虛擬碼):
func main() {
_, err = db.Save(&user) // 儲存更新後的資料到資料庫
if err != nil {
log.Fatal(err)
} else {
// 更新成功之後,刪除快取
err = deleteCache(id)
}
}
整體優勢:
Cache-Aside機制可以有效地提高系統的效能,因為快取可以減少資料庫等資料來源的存取量,從而減少了系統的響應時間。同時,它還可以提高資料的可靠性和一致性,避免髒資料的出現。
2.2 Read-Through(讀穿透)
當快取未命中,從資料庫讀取資料,同時寫到快取中並返回給應用服務。
這個策略類似於Cache-Aside,但是它會自動從快取中讀取資料,而不需要先從資料庫中讀取資料。如果快取中沒有資料,則自動從資料庫中讀取資料,並將讀取到的資料儲存到快取中。
值得注意的是,Read-Through 不對資料庫與快取的同步關注,程式碼只與快取互動,由快取元件來管理自身與資料庫之間的資料同步。所以說這個策略雖然可以提高讀取效能,但是可能會增加資料庫的負載。
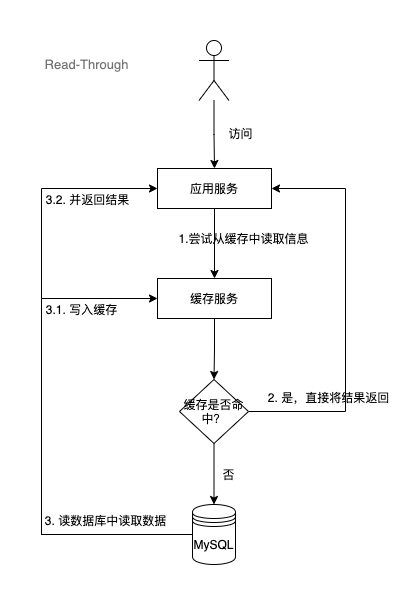
2.3 Write-Through(寫貫穿)
這個策略類似於Cache-Aside,但是在寫入資料時,Write-Through 將寫入責任轉移到快取系統,由快取服務來執行更新,而不是先寫入資料庫再更新快取。
將同步可能產生的故障處理和重試邏輯,交給快取層來管理實現。
流程圖如下:

這個策略可以提高寫入效能,但是可能會降低快取的利用率。
可以看出與Cache-Aside最大不通就是對調了順序,更新資料時,資料先寫快取,接著由快取元件將資料同步到資料庫。
2.4 Write-Behind(寫後置)
這個策略類似於Write-Through,但是在寫入資料時,它會非同步地更新快取和資料庫,而不是立即更新。這個策略可以提高寫入效能,但是可能會增加資料庫的負載和快取的不一致性。
流程如下:
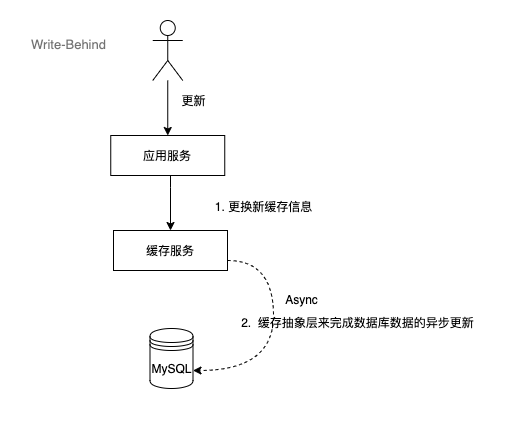
這種策略下,快取與資料庫存在一定程度的不一致性,對強要求一致的系統不建議使用。
3 Cache-Aside策略下的一致性
我們在業務場景中最經常使用的是 Cache-Aside 策略。在該策略下,先從快取中讀取資料,如果快取中沒有資料,則從資料庫中讀取資料,並將讀取到的資料儲存到快取中。在寫入資料時,先寫入資料庫,然後更新快取中的資料。
可以看出,讀操作不會導致快取與資料庫的不一致。而寫操作則存在風險,資料庫和快取畢竟是兩套系統,如果都需要進行修改,它們的先後順序可能導致資料不一致。
上面其實我們有討論過,更新的時候有兩種辦法,一種是將資料庫的修改更新到快取;一種是直接刪除快取,等有需要呼叫的時候再去更新快取。
所以規避一致性風險的時候,我們需要考慮的有:
- 先更新快取還是更新資料庫?哪種順序是最優選
- 資料庫更新完我們是選擇更新快取(modify)還是刪除快取(drop)?
這兩個需要考慮的問題,我們可以得到4種組合方案:
- 先更新快取,再更新資料庫。
- 先更新資料庫,再更新快取。
- 先刪除快取,再更新資料庫。
- 先更新資料庫,再刪除快取。
在對這四種的方案的分析過程中,我們考慮兩個點:
- 操作原子性問題,其中一個操作失敗會有什麼問題。
- 資料一致性問題,高並行下會否有資料不一致情況。
3.1 先更新快取,再更新資料庫
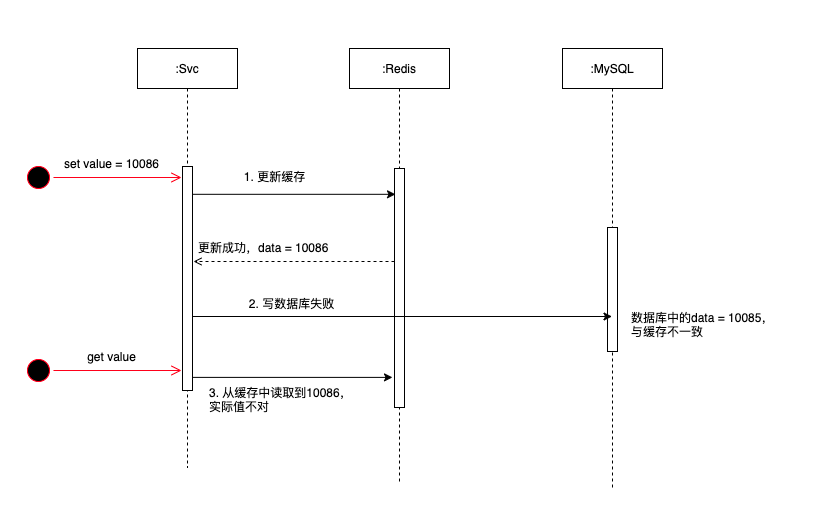
如圖可以看出:如果快取更新成功,資料庫更新失敗,就會導致資料庫和快取的資料不一致,那快取就是髒資料了。
而查詢的時候,會從快取中查詢到資料庫不一致的資料,這樣的資料是不正確的。
3.2 先更新資料庫,再更新快取
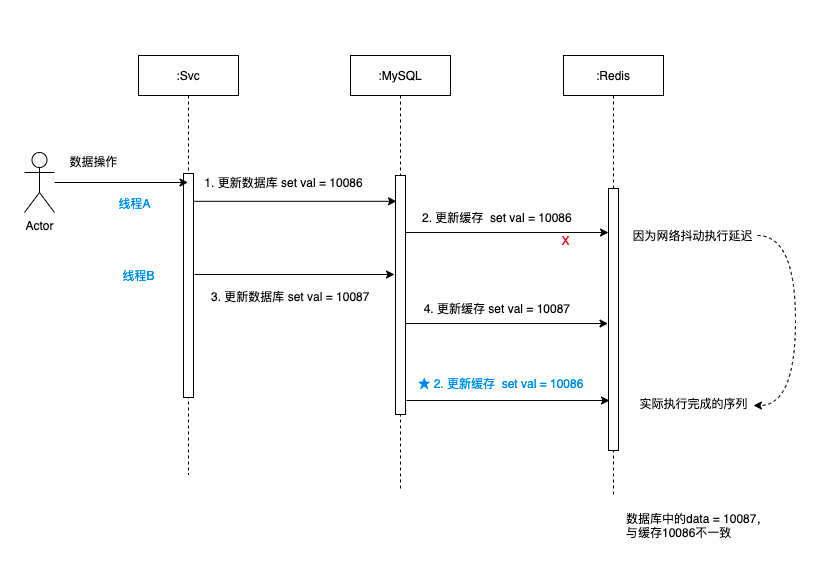
如圖可以看出:
- 10086先傳送,更新完成資料庫之後,更新快取遇到網路抖動,有延遲。
- 10087緊接著傳送,更新完資料庫之後,繼續更新快取,很快更新完成,10087 寫到快取中了。
- 這時候10086在快取更新那邊響應過來了,將10086寫到快取中了。
- 最後發現,資料庫的值 = 10087,而快取的值 = 10086,出現不一致的情況。
綜上,高並行場景中,多執行緒同時寫快取寫資料庫時,很容易出現雙值不一致的情況。
3.3 先刪除快取,再更新資料庫
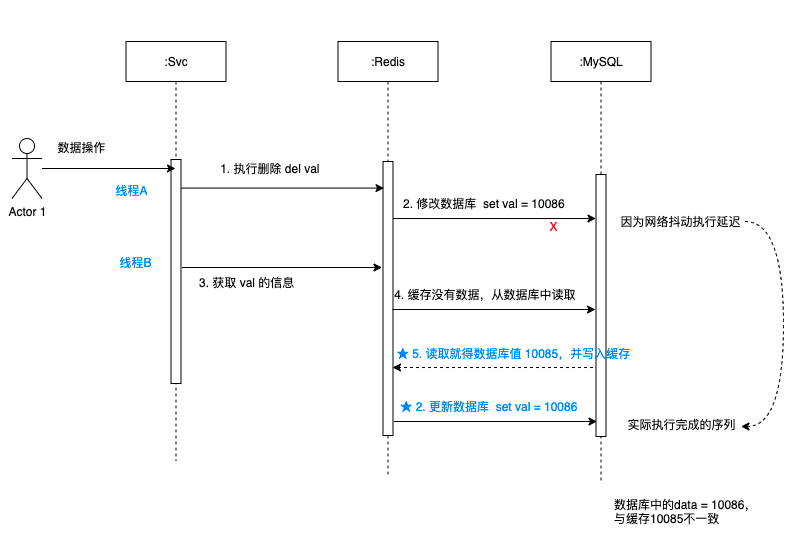
如圖可以看出:
- 先刪除快取val,然後更新資料庫,遇到網路抖動,有延遲。
- 緊接著獲取 val的值,因為快取是空的,所以從資料庫中取出舊的值 10085,並更新到快取中。
- 這時候更新資料庫的操作響應過來了,把資料庫修改成10086。
- 更新完資料庫中的data = 10086,又與快取10085不一致了。
綜上,這種情況也有很大缺陷,不論是異常情況還是高並行場景,都可能導致資料不一致。
3.4 先更新資料庫,再刪快取
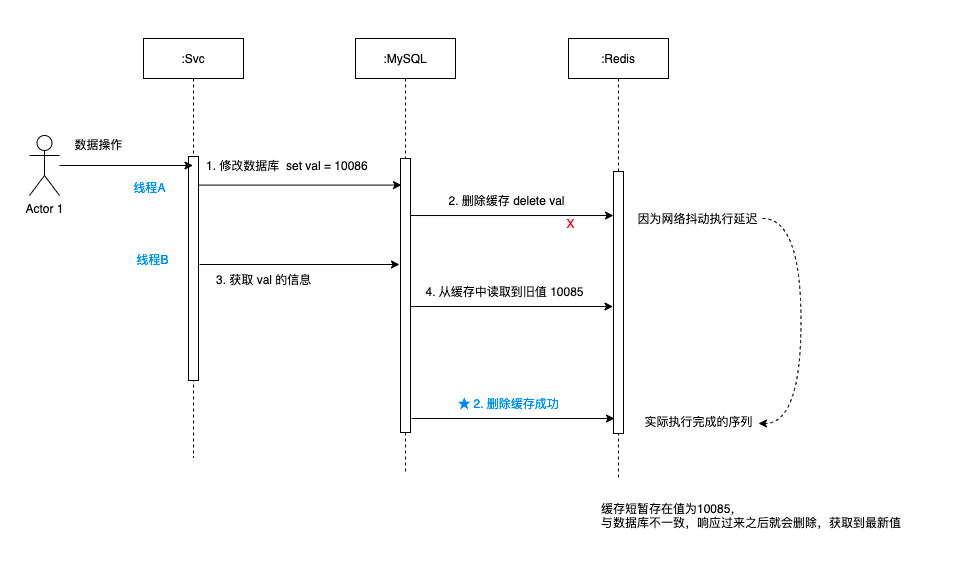
如圖可以看出:
- 先修改資料庫,資料庫修改之後刪除快取,這時候遇到網路抖動,有延遲。
- 緊接著獲取 val的值,因為快取未被刪除,所以從快取中取出舊的值 10085。
- 這時候更新快取的操作響應過來了,直接把 key = value 的快取刪除。
- 後續拿到的值都應該是最新的值,就不會有問題了,
可以看出,可能出現短暫的少量讀取舊值的情況,但是很快快取就會被刪除,然後從資料庫獲取最新的值並更新到快取。
之後的請求都能獲取最新資料,這個方案比之前的三種都好很多。
4 一致性的解決方案
4.1 延遲雙刪策略
延遲雙刪策略主要是是應對先刪除快取,再更新資料庫的場景。
我們知道在這種場景中,很容易因為刪除資料庫太慢導致重新獲取的快取依舊讀是資料庫舊值,讀完舊值之後,資料庫才更新完畢。這時候快取的資料就跟資料庫不一致了。參考 3.3 節。
所以這邊多加了一個步驟,就是在資料庫更新完成之後,再刪除一次快取。所以步驟如下:
- 刪除快取
- 快取刪除完成之後,更新資料庫
- 資料庫更新完成之後,休眠 n ms,二次刪除快取
這時候唯一存在的一個問題就是,在(更新據庫 + 休眠 n ms) 這個時間視窗中,依舊能讀取到舊值,而這個短暫時間控制的好的話,是可以接受的。

4.2 事務保證
無論是先更新資料庫,再刪除快取;還是先刪除快取,在更新資料庫。
保持事務性都是一種方案,如果刪除快取失敗,則資料庫更新會被回滾;如果更新資料庫失敗,則快取也不會被刪除。這個需要一致性策略接入。不過無論怎麼做,這個都會在一定程度上影響執行完成的效能。
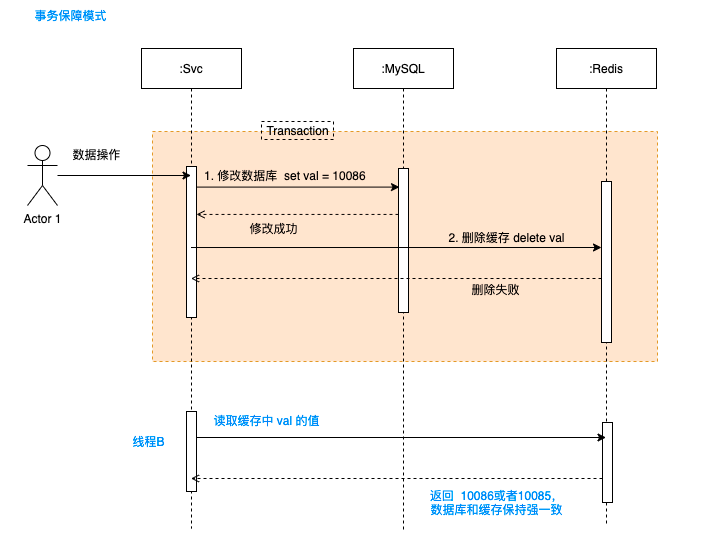
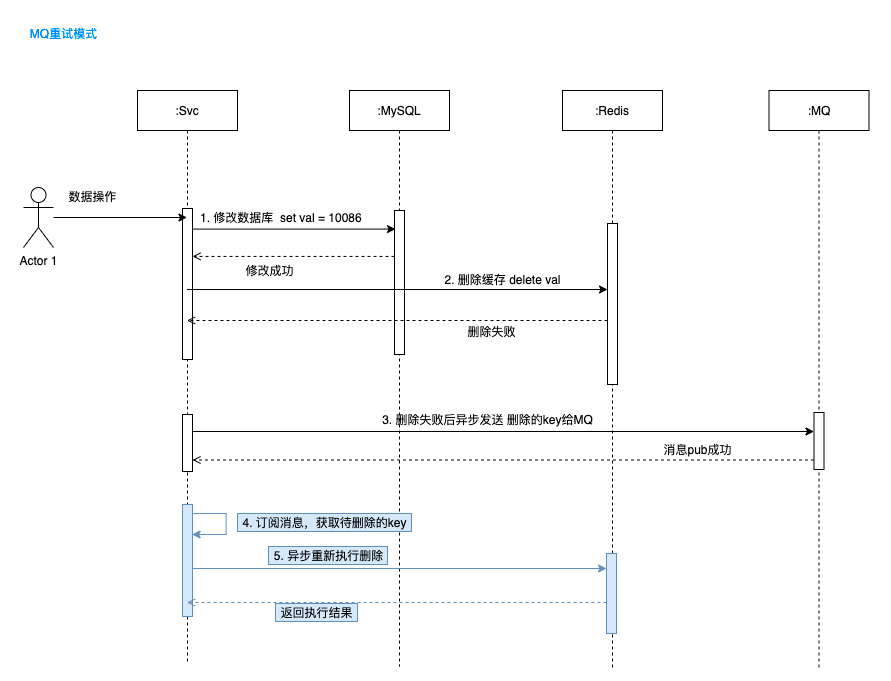
4.3 快取刪除重試保障機制
接著 4.1 的模式,如果雙刪還是失敗呢,那可咋整,還是會產生快取和資料庫資料不一致的現象。
一般的做法是做一層兜底,比如記錄紀錄檔,人工來處理;或者通過MQ來發布訊息,然後開發一個獨立的服務來訂閱,專門用於資料清理,這就將操作非同步化了。
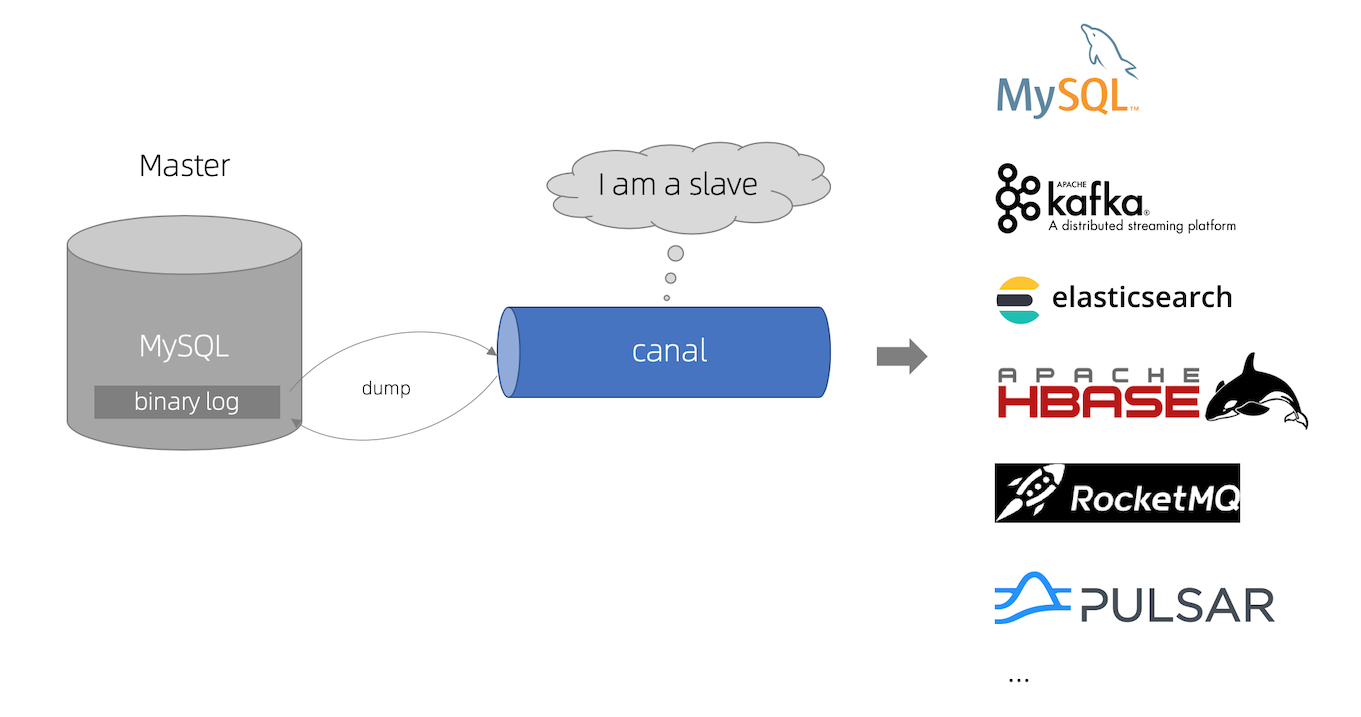
4.4 binlog獨立刪除能力
我們知道,資料庫有類似Binlog之類的東西,記錄每次資料的更新。所以我們有另外一種方案,就是把同步快取的操作交給獨立的能力中,從應用層解耦。
圖中我們可以看到步驟如下:
- 更新資料庫資料
- 資料庫更新完成之後會把變更記錄在 binlog 中
- 使用 canal 訂閱 binlog 紀錄檔獲取待刪除的key(或者更完整的資料物件)
- 消費者(快取刪除服務)獲取到 canal 資料,獲得待刪除的key,並刪除快取
5 總結
- 快取策略的最常用模式是 Cache Aside Pattern。
- 讀快取最優策略:讀取快取,命中則返回結果;未命中則查詢資料庫,寫快取,再返回。
- 寫快取最優策略是:先寫資料庫,再直接刪除快取
- 在實踐中,建議使用延遲雙刪和刪除重試兜底的模式為資料一致性做保障。
