TIDB
TIDB(一)
重點
TIDB核心
TIDB 執行計劃
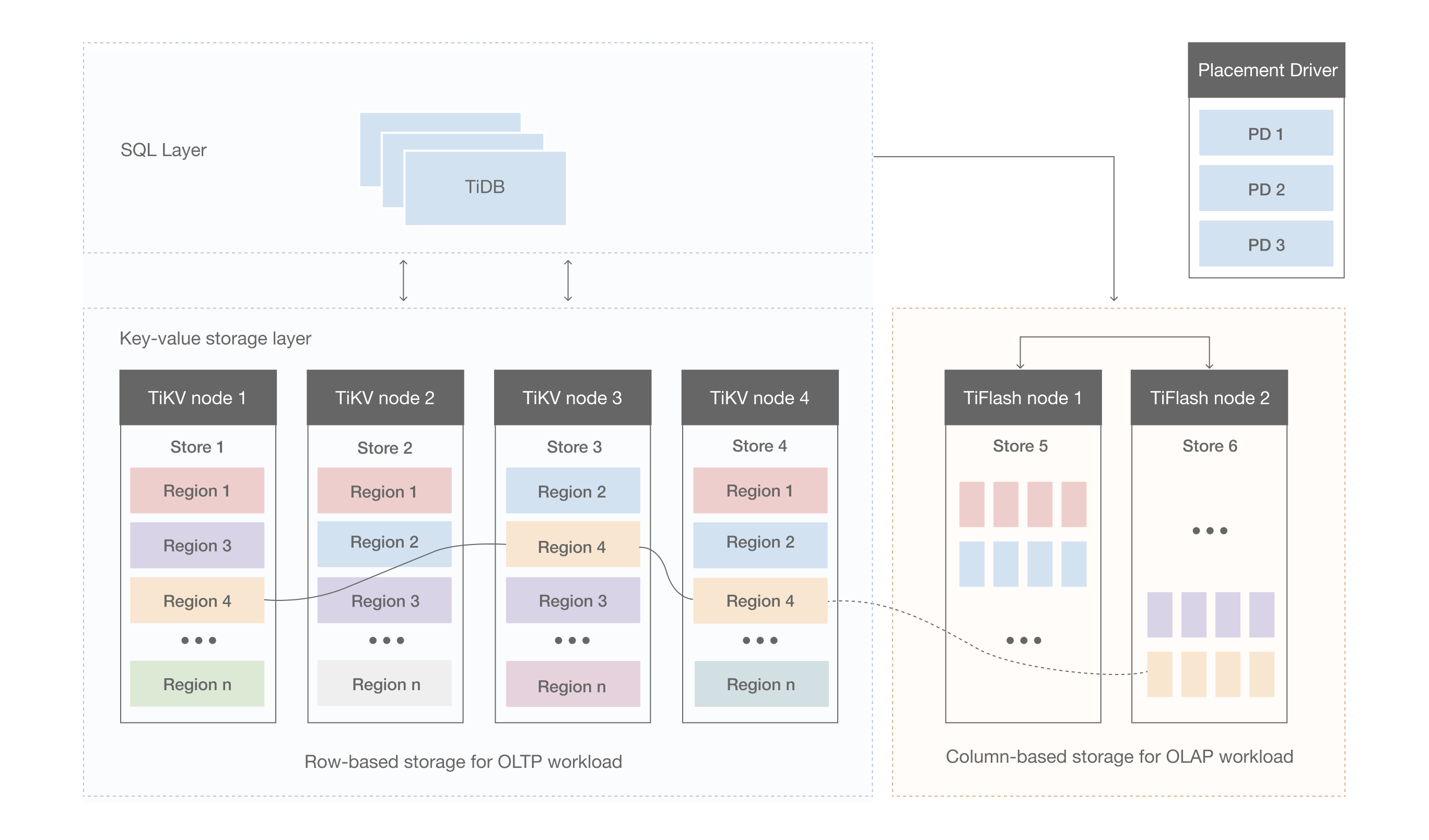
TiDB 整體架構
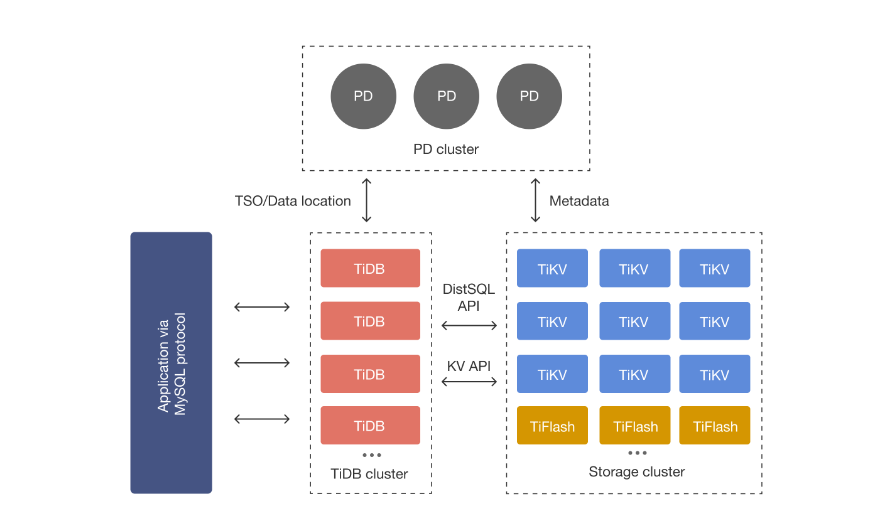
TiDB Server
TiDB Server 負責接受使用者端的連線,執行 SQL 解析和優化,最終生成分散式執行計劃,對外暴露 MySQL 協定的連線 endpoint,處理 SQL 相關的邏輯,並通過 PD 找到儲存計算所需資料的 TiKV 地址,與 TiKV 互動獲取資料,最終返回結果,TiDB 層本身是無狀態的,實踐中可以啟動多個 TiDB 範例,通過負載均衡元件(如 LVS、HAProxy 或 F5)對外提供統一的接入地址,使用者端的連線可以均勻地分攤在多個 TiDB 範例上以達到負載均衡的效果。TiDB Server 本身並不儲存資料,只是解析 SQL,將實際的資料讀取請求轉發給底層的儲存節點 TiKV(或 TiFlash)。
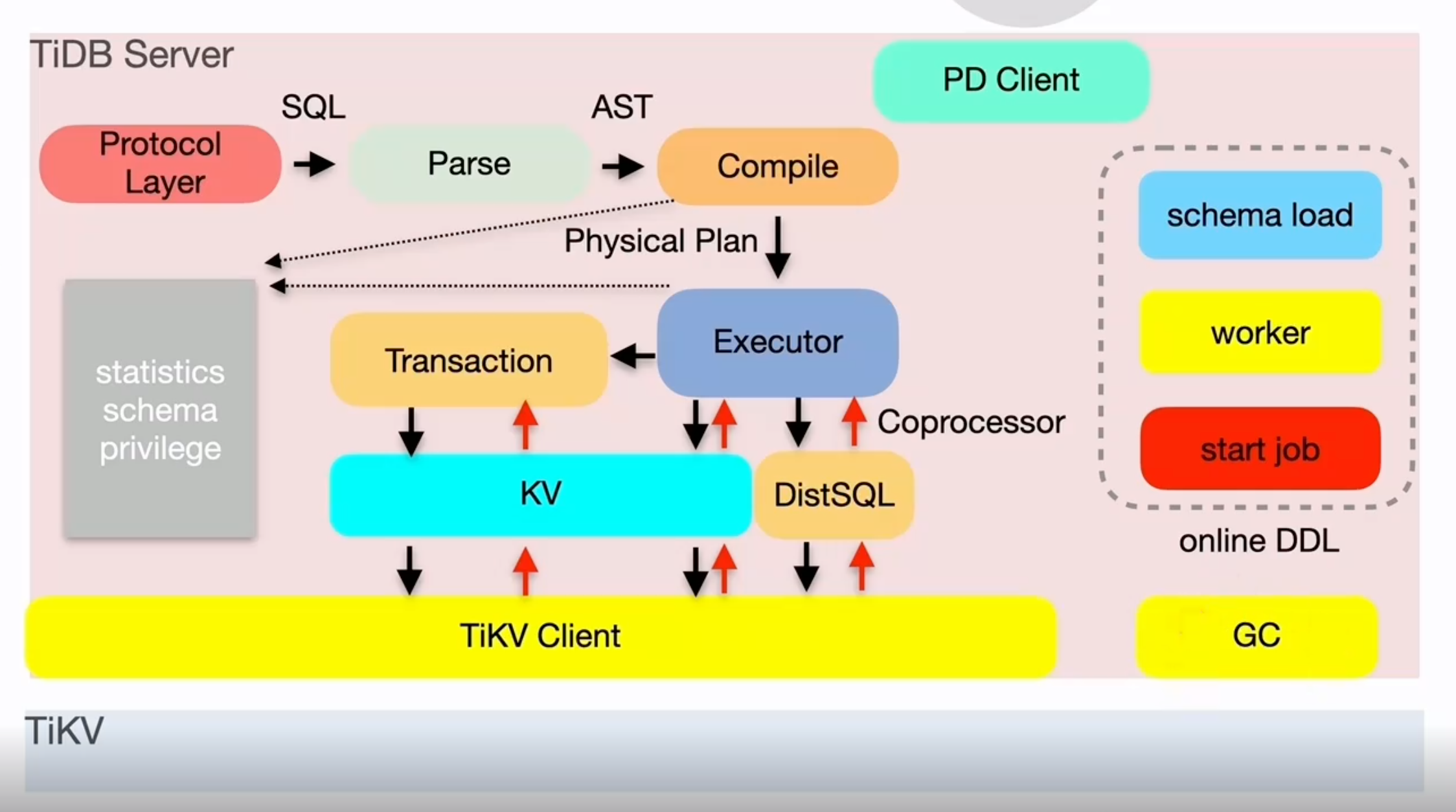
- 處理使用者端連線
- SQL語句解析和編譯
- 關係型資料與kv 的轉化
- SQL語句的執行
- 線上DDL執行
- 垃圾回收
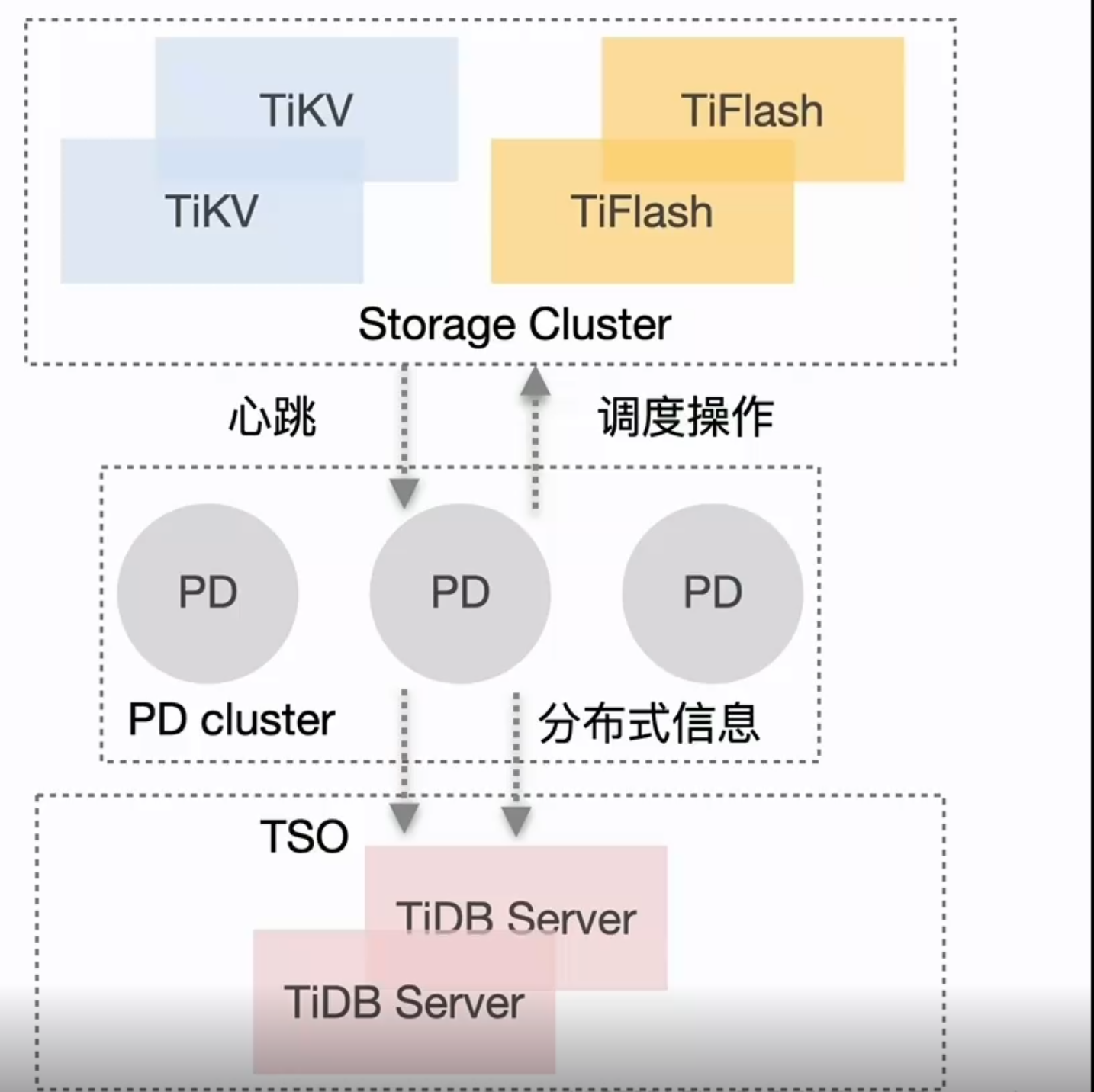
PD Server()
整個 TiDB 叢集的元資訊管理模組,負責儲存每個 TiKV 節點實時的資料分佈情況和叢集的整體拓撲結構,提供 TiDB Dashboard 管控介面,併為分散式事務分配事務 ID。PD 不僅儲存元資訊,同時還會根據 TiKV 節點實時上報的資料分佈狀態,下發資料排程命令給具體的 TiKV 節點,可以說是整個叢集的「大腦」。此外,PD 本身也是由至少 3 個節點構成,擁有高可用的能力。建議部署奇數個 PD 節點。其主要工作有三個:一是儲存叢集的元資訊(某個 Key 儲存在哪個 TiKV 節點);二是對 TiKV 叢集進行排程和負載均衡(如資料的遷移、Raft group leader 的遷移等);三是分配全域性唯一且遞增的事務 ID。
- 整個叢集TIKV的後設資料儲存
- 分配全域性ID和事務ID
- 生成全域性時間錯TSO
- 收集叢集資訊進行排程
- 提供TIDB Dashboard 服務
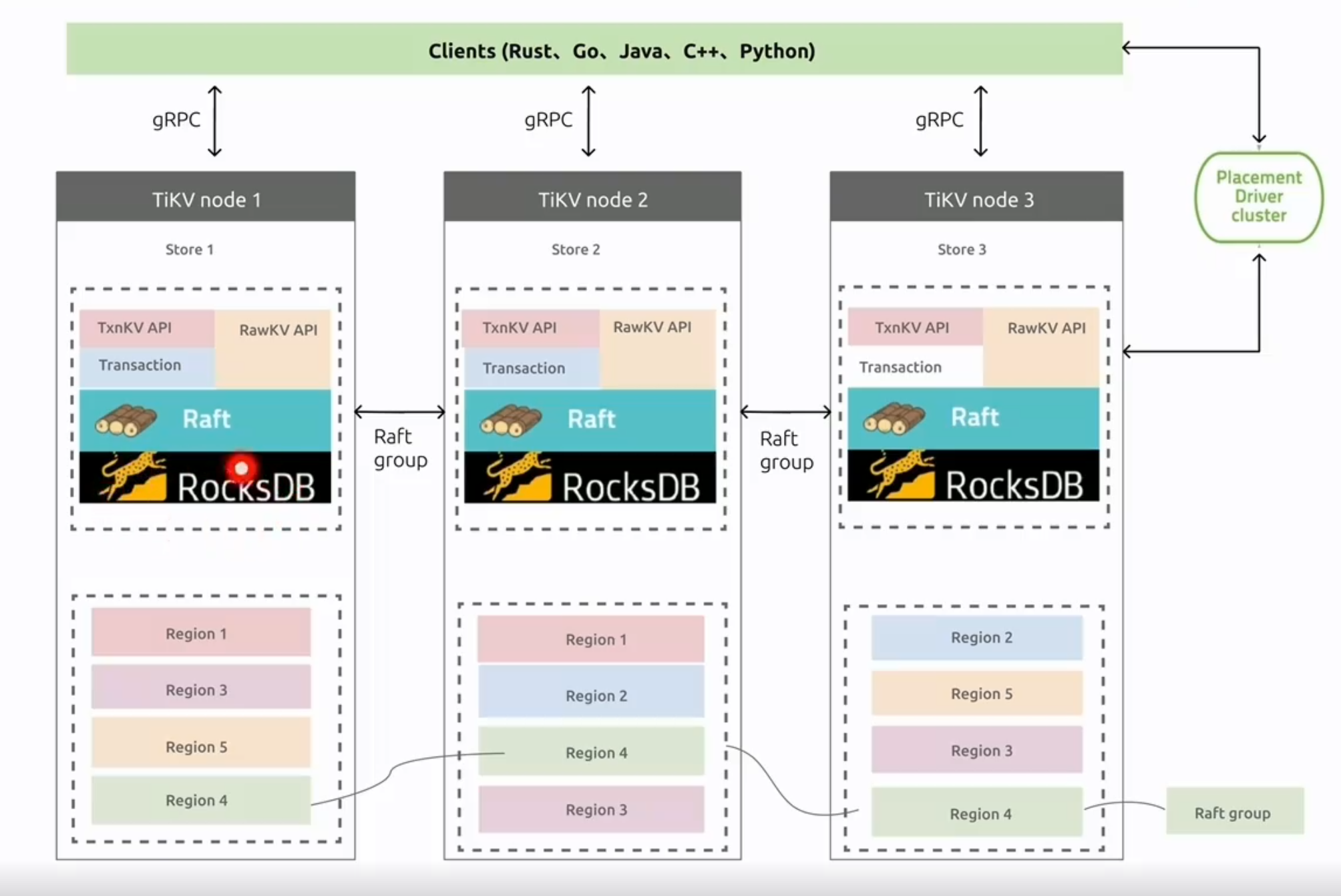
TiKV/TIFLASH Server
show table regions:檢視節點
- TiKV Server:負責儲存資料,從外部看 TiKV 是一個分散式的提供事務的 Key-Value 儲存引擎。儲存資料的基本單位是 Region,每個 Region 負責儲存一個 Key Range(從 StartKey 到 EndKey 的左閉右開區間)的資料,每個 TiKV 節點會負責多個 Region。TiKV 的 API 在 KV 鍵值對層面提供對分散式事務的原生支援,預設提供了 SI (Snapshot Isolation) 的隔離級別,這也是 TiDB 在 SQL 層面支援分散式事務的核心。TiDB 的 SQL 層做完 SQL 解析後,會將 SQL 的執行計劃轉換為對 TiKV API 的實際呼叫。所以,資料都儲存在 TiKV 中。另外,TiKV 中的資料都會自動維護多副本(預設為三副本),天然支援高可用和自動故障轉移。
- 資料持久化
- 分散式事務支援
- 副本的強一致性和高可用性
- MVCC
- 運算元下推 Coprocessor
- TiFlash:TiFlash 是一類特殊的儲存節點。和普通 TiKV 節點不一樣的是,在 TiFlash 內部,資料是以列式的形式進行儲存,主要的功能是為分析型的場景加速。
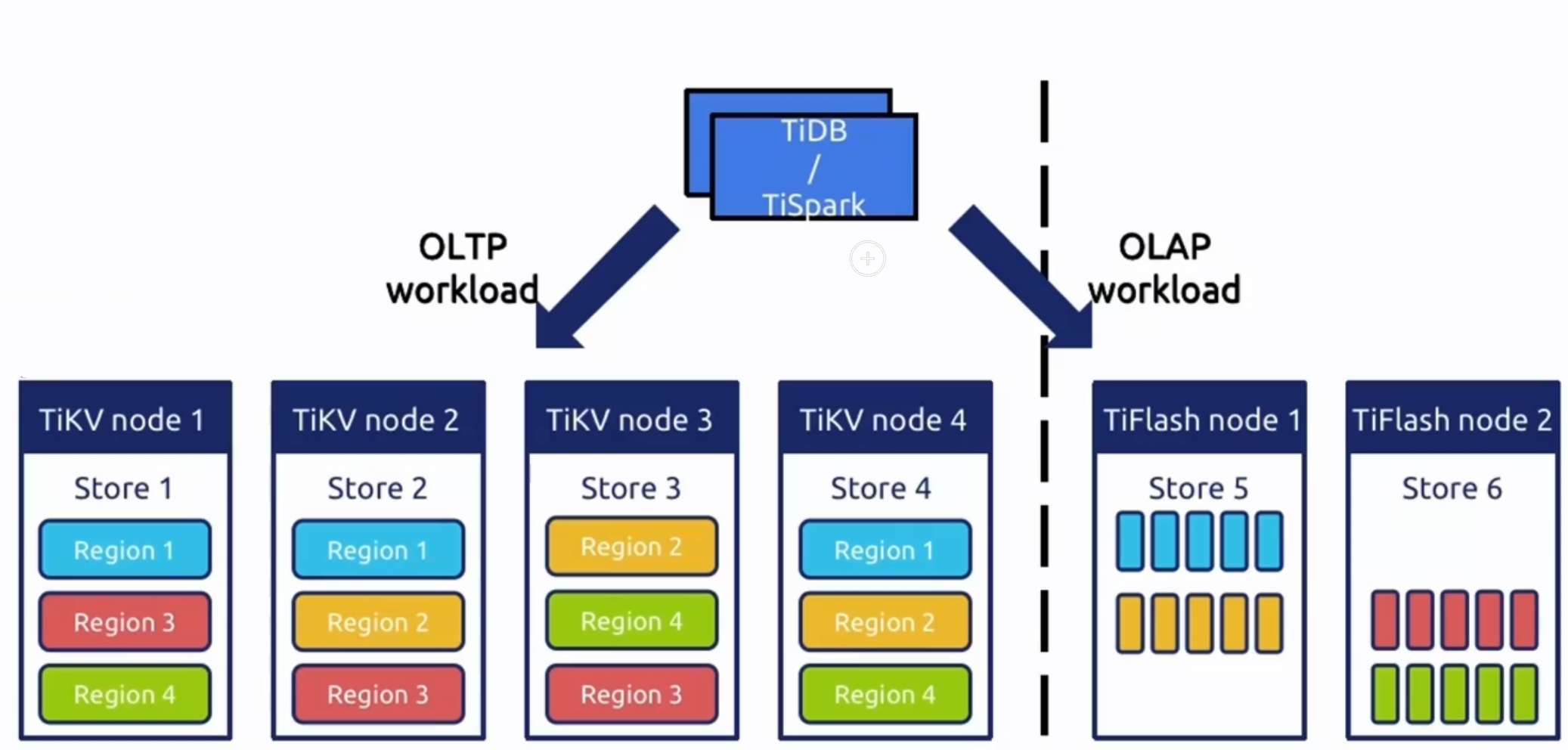
- 列式儲存提高分析查詢效率
- 支援強一致性和實時性
- 業務隔離
- 智慧選擇
TIDB 資料庫計算
TiDB 中資料到 (Key, Value) 鍵值對的對映方案
表資料與 Key-Value 的對映關係
背景:在關係型資料庫中,一個表可能有很多列。要將一行中各列資料對映成一個 (Key, Value) 鍵值對,需要考慮如何構造 Key。首先,OLTP 場景下有大量針對單行或者多行的增、刪、改、查等操作,要求資料庫具備快速讀取一行資料的能力。因此,對應的 Key 最好有一個唯一 ID(顯示或隱式的 ID),以方便快速定位。其次,很多 OLAP 型查詢需要進行全表掃描。如果能夠將一個表中所有行的 Key 編碼到一個區間內,就可以通過範圍查詢高效完成全表掃描的任務。3
基於上述考慮,TiDB 中的表資料與 Key-Value 的對映關係作了如下設計:
- 為了保證同一個表的資料放在一起,方便查詢,TiDB 會為每個表分配一個表 ID,用
TableID表示。表 ID 是一個整數,在整個叢集內唯一。 - TiDB 會為表中每行資料分配一個行 ID,用
RowID表示。行 ID 也是一個整數,在表內唯一。對於行 ID,TiDB 做了一個小優化,如果某個表有整數型的主鍵,TiDB 會使用主鍵的值當做這一行資料的行 ID。
每行資料按照如下規則編碼成 (Key, Value) 鍵值對:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
其中 tablePrefix 和 recordPrefixSep 都是特定的字串常數,用於在 Key 空間內區分其他資料。其具體值在後面的小結中給出。
索引資料和 Key-Value 的對映關係
TiDB 同時支援主鍵和二級索引(包括唯一索引和非唯一索引)。與表資料對映方案類似,TiDB 為表中每個索引分配了一個索引 ID,用 IndexID 表示。
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: RowID
對於不需要滿足唯一性約束的普通二級索引,一個鍵值可能對應多行,需要根據鍵值範圍查詢對應的 RowID。因此,按照如下規則編碼成 (Key, Value) 鍵值對:
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}indexedColumnsValue
Value: null
對映關係總結
上述所有編碼規則中的 tablePrefix、recordPrefixSep 和 indexPrefixSep 都是字串常數,用於在 Key 空間內區分其他資料,定義如下:
tablePrefix = []byte{'t'}
recordPrefixSep = []byte{'r'}
indexPrefixSep = []byte{'i'}
另外請注意,上述方案中,無論是表資料還是索引資料的 Key 編碼方案,一個表內所有的行都有相同的 Key 字首,一個索引的所有資料也都有相同的字首。這樣具有相同的字首的資料,在 TiKV 的 Key 空間內,是排列在一起的。因此只要小心地設計字尾部分的編碼方案,保證編碼前和編碼後的比較關係不變,就可以將表資料或者索引資料有序地儲存在 TiKV 中。採用這種編碼後,一個表的所有行資料會按照
RowID順序地排列在 TiKV 的 Key 空間中,某一個索引的資料也會按照索引資料的具體的值(編碼方案中的indexedColumnsValue)順序地排列在 Key 空間內。
Key-Value 對映關係範例
最後通過一個簡單的例子,來理解 TiDB 的 Key-Value 對映關係。假設 TiDB 中有如下這個表:
CREATE TABLE User (
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
KEY idxAge (Age)
);
假設該表中有 3 行資料:
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
首先每行資料都會對映為一個 (Key, Value) 鍵值對,同時該表有一個 int 型別的主鍵,所以 RowID 的值即為該主鍵的值。假設該表的 TableID 為 10,則其儲存在 TiKV 上的表資料為:
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", "Manager", 30]
除了主鍵外,該表還有一個非唯一的普通二級索引 idxAge,假設這個索引的 IndexID 為 1,則其儲存在 TiKV 上的索引資料為:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
元資訊管理
TiDB 中每個
Database和Table都有元資訊,也就是其定義以及各項屬性。這些資訊也需要持久化,TiDB 將這些資訊也儲存在了 TiKV 中。每個
Database/Table都被分配了一個唯一的 ID,這個 ID 作為唯一標識,並且在編碼為 Key-Value 時,這個 ID 都會編碼到 Key 中,再加上m_字首。這樣可以構造出一個 Key,Value 中儲存的是序列化後的元資訊。除此之外,TiDB 還用一個專門的 (Key, Value) 鍵值對儲存當前所有表結構資訊的最新版本號。這個鍵值對是全域性的,每次 DDL 操作的狀態改變時其版本號都會加 1。目前,TiDB 把這個鍵值對持久化儲存在 PD Server 中,其 Key 是 "/tidb/ddl/global_schema_version",Value 是型別為 int64 的版本號值。TiDB 採用 Online Schema 變更演演算法,有一個後臺執行緒在不斷地檢查 PD Server 中儲存的表結構資訊的版本號是否發生變化,並且保證在一定時間內一定能夠獲取版本的變化。
SQL 層簡介
TiDB 的 SQL 層,即 TiDB Server,負責將 SQL 翻譯成 Key-Value 操作,將其轉發給共用的分散式 Key-Value 儲存層 TiKV,然後組裝 TiKV 返回的結果,最終將查詢結果返回給使用者端。
這一層的節點都是無狀態的,節點本身並不儲存資料,節點之間完全對等。
SQL 運算
最簡單的方案就是通過上一節所述的表資料與 Key-Value 的對映關係方案,將 SQL 查詢對映為對 KV 的查詢,再通過 KV 介面獲取對應的資料,最後執行各種計算。
比如
select count(*) from user where name = "TiDB"這樣一個 SQL 語句,它需要讀取表中所有的資料,然後檢查name欄位是否是TiDB,如果是的話,則返回這一行。具體流程如下:
- 構造出 Key Range:一個表中所有的
RowID都在[0, MaxInt64)這個範圍內,使用0和MaxInt64根據行資料的Key編碼規則,就能構造出一個[StartKey, EndKey)的左閉右開區間。 - 掃描 Key Range:根據上面構造出的 Key Range,讀取 TiKV 中的資料。
- 過濾資料:對於讀到的每一行資料,計算
name = "TiDB"這個表示式,如果為真,則向上返回這一行,否則丟棄這一行資料。 - 計算
Count(*):對符合要求的每一行,累計到Count(*)的結果上面。
整個流程示意圖如下:
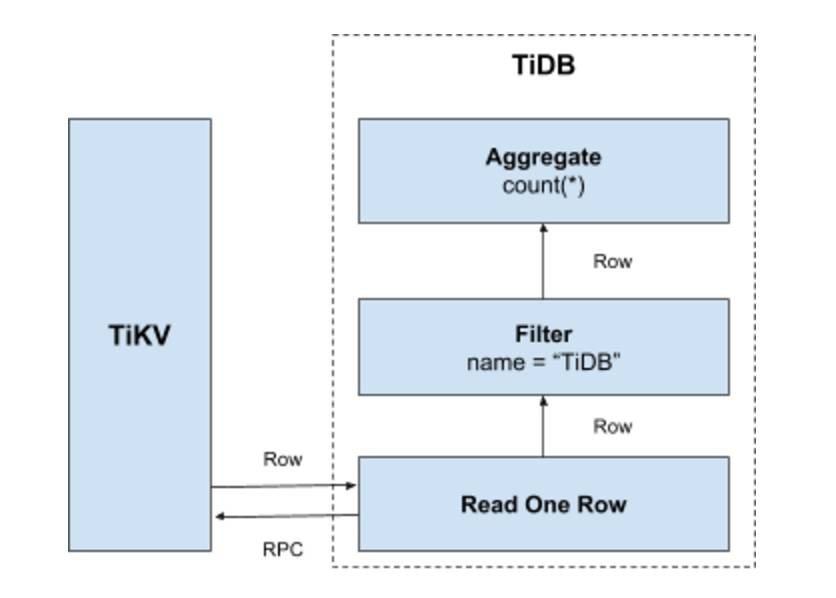
這個方案是直觀且可行的,但是在分散式資料庫的場景下有一些顯而易見的問題:
- 在掃描資料的時候,每一行都要通過 KV 操作從 TiKV 中讀取出來,至少有一次 RPC 開銷,如果需要掃描的資料很多,那麼這個開銷會非常大。
- 並不是所有的行都滿足過濾條件
name = "TiDB",如果不滿足條件,其實可以不讀取出來。- 此查詢只要求返回符合要求行的數量,不要求返回這些行的值。
分散式 SQL 運算
為了解決上述問題,計算應該需要儘量靠近儲存節點,以避免大量的 RPC 呼叫。首先,SQL 中的謂詞條件
name = "TiDB"應被下推到儲存節點進行計算,這樣只需要返回有效的行,避免無意義的網路傳輸。然後,聚合函數Count(*)也可以被下推到儲存節點,進行預聚合,每個節點只需要返回一個Count(*)的結果即可,再由 SQL 層將各個節點返回的Count(*)的結果累加求和。
以下是資料逐層返回的示意圖:
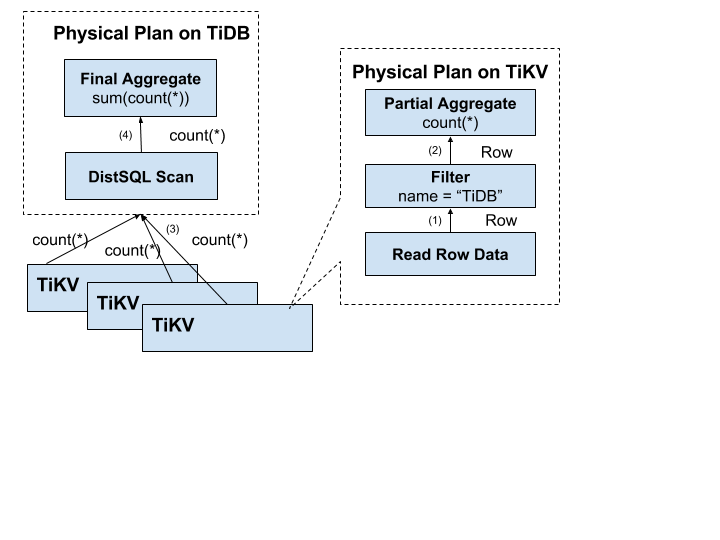
SQL 層架構
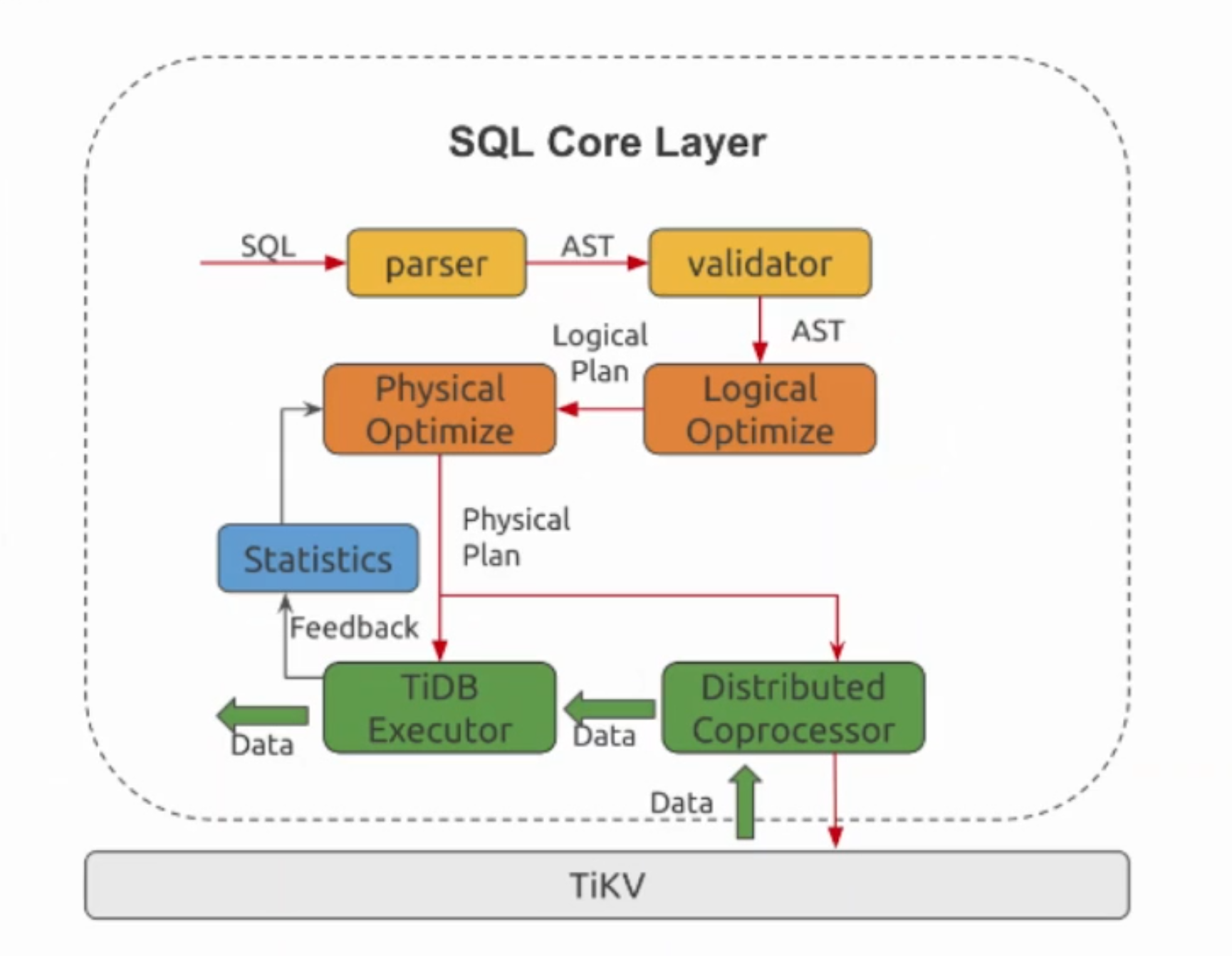
通過上面的例子,希望大家對 SQL 語句的處理有一個基本的瞭解。實際上 TiDB 的 SQL 層要複雜得多,模組以及層次非常多,下圖列出了重要的模組以及呼叫關係:

- AST 語法樹 - 邏輯優化 - 邏輯執行計劃 - 物理優化 - 本地執行器 - 異地執行器
使用者的 SQL 請求會直接或者通過
Load Balancer傳送到 TiDB Server,TiDB Server 會解析MySQL Protocol Packet,獲取請求內容,對 SQL 進行語法解析和語意分析,制定和優化查詢計劃,執行查詢計劃並獲取和處理資料。資料全部儲存在 TiKV 叢集中,所以在這個過程中 TiDB Server 需要和 TiKV 互動,獲取資料。最後 TiDB Server 需要將查詢結果返回給使用者。
AUTO_INCREMENT
AUTO_INCREMENT 是用於自動填充預設列值的列屬性。當 INSERT 語句沒有指定 AUTO_INCREMENT 列的具體值時,系統會自動地為該列分配一個值。
出於效能原因,自增編號是系統批次分配給每臺 TiDB 伺服器的值(預設 3 萬個值),因此自增編號能保證唯一性,但分配給 INSERT 語句的值僅在單臺 TiDB 伺服器上具有單調性。
實現原理
TiDB 實現 AUTO_INCREMENT 隱式分配的原理是,對於每一個自增列,都使用一個全域性可見的鍵值對用於記錄當前已分配的最大 ID。由於分散式環境下的節點通訊存在一定開銷,為了避免寫請求放大的問題,每個 TiDB 節點在分配 ID 時,都申請一段 ID 作為快取,用完之後再去取下一段,而不是每次分配都向儲存節點申請。例如,對於以下新建的表:
CREATE TABLE t(id int UNIQUE KEY AUTO_INCREMENT, c int);
假設叢集中有兩個 TiDB 範例 A 和 B,如果向 A 和 B 分別對 t 執行一條插入語句:
INSERT INTO t (c) VALUES (1)
範例 A 可能會快取 [1,30000] 的自增 ID,而範例 B 則可能快取 [30001,60000] 的自增 ID。各自範例快取的 ID 將隨著執行將來的插入語句被作為預設值,順序地填充到 AUTO_INCREMENT 列中。
基本特性
唯一性保證
警告
在叢集中有多個 TiDB 範例時,如果表結構中有自增 ID,建議不要混用顯式插入和隱式分配(即自增列的預設值和自定義值),否則可能會破壞隱式分配值的唯一性。
例如在上述範例中,依次執行如下操作:
- 使用者端向範例 B 插入一條將
id設定為2的語句INSERT INTO t VALUES (2, 1),並執行成功。 - 使用者端向範例 A 傳送
INSERT語句INSERT INTO t (c) (1),這條語句中沒有指定id的值,所以會由 A 分配。當前 A 快取了[1, 30000]這段 ID,可能會分配2為自增 ID 的值,並把本地計數器加1。而此時資料庫中已經存在id為2的資料,最終返回Duplicated Error錯誤。
單調性保證
TiDB 保證 AUTO_INCREMENT 自增值在單臺伺服器上單調遞增。以下範例在一臺伺服器上生成連續的 AUTO_INCREMENT 自增值 1-3:
CREATE TABLE t (a int PRIMARY KEY AUTO_INCREMENT, b timestamp NOT NULL DEFAULT NOW());
INSERT INTO t (a) VALUES (NULL), (NULL), (NULL);
SELECT * FROM t;
Query OK, 0 rows affected (0.11 sec)
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
+---+---------------------+
| a | b |
+---+---------------------+
| 1 | 2020-09-09 20:38:22 |
| 2 | 2020-09-09 20:38:22 |
| 3 | 2020-09-09 20:38:22 |
+---+---------------------+
3 rows in set (0.00 sec)
TiDB 能保證自增值的單調性,但並不能保證其連續性。參考以下範例:
CREATE TABLE t (id INT NOT NULL PRIMARY KEY AUTO_INCREMENT, a VARCHAR(10), cnt INT NOT NULL DEFAULT 1, UNIQUE KEY (a));
INSERT INTO t (a) VALUES ('A'), ('B');
SELECT * FROM t;
INSERT INTO t (a) VALUES ('A'), ('C') ON DUPLICATE KEY UPDATE cnt = cnt + 1;
SELECT * FROM t;
Query OK, 0 rows affected (0.00 sec)
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
+----+------+-----+
| id | a | cnt |
+----+------+-----+
| 1 | A | 1 |
| 2 | B | 1 |
+----+------+-----+
2 rows in set (0.00 sec)
Query OK, 3 rows affected (0.00 sec)
Records: 2 Duplicates: 1 Warnings: 0
+----+------+-----+
| id | a | cnt |
+----+------+-----+
| 1 | A | 2 |
| 2 | B | 1 |
| 4 | C | 1 |
+----+------+-----+
3 rows in set (0.00 sec)
在以上範例 INSERT INTO t (a) VALUES ('A'), ('C') ON DUPLICATE KEY UPDATE cnt = cnt + 1; 語句中,自增值 3 被分配為 A 鍵對應的 id 值,但實際上 3 並未作為 id 值插入進表中。這是因為該 INSERT 語句包含一個重複鍵 A,使得自增序列不連續,出現了間隙。該行為儘管與 MySQL 不同,但仍是合法的。MySQL 在其他情況下也會出現自增序列不連續的情況,例如事務被中止和回滾時。
AUTO_ID_CACHE
如果在另一臺伺服器上執行插入操作,那麼 AUTO_INCREMENT 值的順序可能會劇烈跳躍,這是由於每臺伺服器都有各自快取的 AUTO_INCREMENT 自增值。
CREATE TABLE t (a INT PRIMARY KEY AUTO_INCREMENT, b TIMESTAMP NOT NULL DEFAULT NOW());
INSERT INTO t (a) VALUES (NULL), (NULL), (NULL);
INSERT INTO t (a) VALUES (NULL);
SELECT * FROM t;
Query OK, 1 row affected (0.03 sec)
+---------+---------------------+
| a | b |
+---------+---------------------+
| 1 | 2020-09-09 20:38:22 |
| 2 | 2020-09-09 20:38:22 |
| 3 | 2020-09-09 20:38:22 |
| 2000001 | 2020-09-09 20:43:43 |
+---------+---------------------+
4 rows in set (0.00 sec)
以下範例在最先的一臺伺服器上執行一個插入 INSERT 操作,生成 AUTO_INCREMENT 值 4。因為這臺伺服器上仍有剩餘的 AUTO_INCREMENT 快取值可用於分配。在該範例中,值的順序不具有全域性單調性:
INSERT INTO t (a) VALUES (NULL);
Query OK, 1 row affected (0.01 sec)
SELECT * FROM t ORDER BY b;
+---------+---------------------+
| a | b |
+---------+---------------------+
| 1 | 2020-09-09 20:38:22 |
| 2 | 2020-09-09 20:38:22 |
| 3 | 2020-09-09 20:38:22 |
| 2000001 | 2020-09-09 20:43:43 |
| 4 | 2020-09-09 20:44:43 |
+---------+---------------------+
5 rows in set (0.00 sec)
AUTO_INCREMENT 快取不會持久化,重啟會導致快取值失效。以下範例中,最先的一臺伺服器重啟後,向該伺服器執行一條插入操作:
INSERT INTO t (a) VALUES (NULL);
Query OK, 1 row affected (0.01 sec)
SELECT * FROM t ORDER BY b;
+---------+---------------------+
| a | b |
+---------+---------------------+
| 1 | 2020-09-09 20:38:22 |
| 2 | 2020-09-09 20:38:22 |
| 3 | 2020-09-09 20:38:22 |
| 2000001 | 2020-09-09 20:43:43 |
| 4 | 2020-09-09 20:44:43 |
| 2030001 | 2020-09-09 20:54:11 |
+---------+---------------------+
6 rows in set (0.00 sec)
TiDB 伺服器頻繁重啟可能導致 AUTO_INCREMENT 快取值被快速消耗。在以上範例中,最先的一臺伺服器本來有可用的快取值 [5-3000]。但重啟後,這些值便丟失了,無法進行重新分配。
使用者不應指望 AUTO_INCREMENT 值保持連續。在以下範例中,一臺 TiDB 伺服器的快取值為 [2000001-2030000]。當手動插入值 2029998 時,TiDB 取用了一個新快取區間的值:
INSERT INTO t (a) VALUES (2029998);
Query OK, 1 row affected (0.01 sec)
INSERT INTO t (a) VALUES (NULL);
Query OK, 1 row affected (0.01 sec)
INSERT INTO t (a) VALUES (NULL);
Query OK, 1 row affected (0.00 sec)
INSERT INTO t (a) VALUES (NULL);
Query OK, 1 row affected (0.02 sec)
INSERT INTO t (a) VALUES (NULL);
Query OK, 1 row affected (0.01 sec)
SELECT * FROM t ORDER BY b;
+---------+---------------------+
| a | b |
+---------+---------------------+
| 1 | 2020-09-09 20:38:22 |
| 2 | 2020-09-09 20:38:22 |
| 3 | 2020-09-09 20:38:22 |
| 2000001 | 2020-09-09 20:43:43 |
| 4 | 2020-09-09 20:44:43 |
| 2030001 | 2020-09-09 20:54:11 |
| 2029998 | 2020-09-09 21:08:11 |
| 2029999 | 2020-09-09 21:08:11 |
| 2030000 | 2020-09-09 21:08:11 |
| 2060001 | 2020-09-09 21:08:11 |
| 2060002 | 2020-09-09 21:08:11 |
+---------+---------------------+
11 rows in set (0.00 sec)
以上範例插入 2030000 後,下一個值為 2060001,即順序出現跳躍。這是因為另一臺 TiDB 伺服器獲取了中間快取區間 [2030001-2060000]。當部署有多臺 TiDB 伺服器時,AUTO_INCREMENT 值的順序會出現跳躍,因為對快取值的請求是交叉出現的。
快取大小控制
TiDB 自增 ID 的快取大小在早期版本中是對使用者透明的。從 v3.1.2、v3.0.14 和 v4.0.rc-2 版本開始,TiDB 引入了 AUTO_ID_CACHE 表選項來允許使用者自主設定自增 ID 分配快取的大小。例如:
CREATE TABLE t(a int AUTO_INCREMENT key) AUTO_ID_CACHE 100;
Query OK, 0 rows affected (0.02 sec)
INSERT INTO t VALUES();
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
SELECT * FROM t;
+---+
| a |
+---+
| 1 |
+---+
1 row in set (0.01 sec)
此時如果將該列的自增快取無效化,重新進行隱式分配:
DELETE FROM t;
Query OK, 1 row affected (0.01 sec)
RENAME TABLE t to t1;
Query OK, 0 rows affected (0.01 sec)
INSERT INTO t1 VALUES()
Query OK, 1 row affected (0.00 sec)
SELECT * FROM t;
+-----+
| a |
+-----+
| 101 |
+-----+
1 row in set (0.00 sec)
可以看到再一次分配的值為 101,說明該表的自增 ID 分配快取的大小為 100。
此外如果在批次插入的 INSERT 語句中所需連續 ID 長度超過 AUTO_ID_CACHE 的長度時,TiDB 會適當調大快取以便能夠保證該語句的正常插入。
自增步長和偏移量設定
從 v3.0.9 和 v4.0.rc-1 開始,和 MySQL 的行為類似,自增列隱式分配的值遵循 session 變數 @@auto_increment_increment 和 @@auto_increment_offset 的控制,其中自增列隱式分配的值 (ID) 將滿足式子 (ID - auto_increment_offset) % auto_increment_increment == 0。
MySQL 相容模式
從 v6.4.0 開始,TiDB 實現了中心化分配自增 ID 的服務,可以支援 TiDB 範例不快取資料,而是每次請求都存取中心化服務獲取 ID。
當前中心化分配服務內建在 TiDB 程序,類似於 DDL Owner 的工作模式。有一個 TiDB 範例將充當「主」的角色提供 ID 分配服務,而其它的 TiDB 範例將充當「備」角色。當「主」節點發生故障時,會自動進行「主備切換」,從而保證中心化服務的高可用。
MySQL 相容模式的使用方式是,建表時將 AUTO_ID_CACHE 設定為 1:
CREATE TABLE t(a int AUTO_INCREMENT key) AUTO_ID_CACHE 1;
注意:
在 TiDB 各個版本中,
AUTO_ID_CACHE設定為1都表明 TiDB 不再快取 ID,但是不同版本的實現方式不一樣:
- 對於 TiDB v6.4.0 之前的版本,由於每次分配 ID 都需要通過一個 TiKV 事務完成
AUTO_INCREMENT值的持久化修改,因此設定AUTO_ID_CACHE為1會出現效能下降。- 對於 v6.4.0 及以上版本,由於引入了中心化的分配服務,
AUTO_INCREMENT值的修改只是在 TiDB 服務程序中的一個記憶體操作,相較於之前版本更快。- 將
AUTO_ID_CACHE設定為1表示 TiDB 使用預設的快取大小30000。
使用 MySQL 相容模式後,能保證 ID 唯一、單調遞增,行為幾乎跟 MySQL 完全一致。即使跨 TiDB 範例存取,ID 也不會出現回退。只有當中心化服務的「主」 TiDB 範例異常崩潰時,才有可能造成少量 ID 不連續。這是因為主備切換時,「備」 節點需要丟棄一部分之前的「主」 節點可能已經分配的 ID,以保證 ID 不出現重複。
使用限制
目前在 TiDB 中使用 AUTO_INCREMENT 有以下限制:
- 對於 v6.6.0 及更早的 TiDB 版本,定義的列必須為主鍵或者索引字首。
- 只能定義在型別為整數、
FLOAT或DOUBLE的列上。 - 不支援與列的預設值
DEFAULT同時指定在同一列上。 - 不支援使用
ALTER TABLE來新增AUTO_INCREMENT屬性。 - 支援使用
ALTER TABLE來移除AUTO_INCREMENT屬性。但從 TiDB 2.1.18 和 3.0.4 版本開始,TiDB 通過 session 變數@@tidb_allow_remove_auto_inc控制是否允許通過ALTER TABLE MODIFY或ALTER TABLE CHANGE來移除列的AUTO_INCREMENT屬性,預設是不允許移除。 ALTER TABLE需要FORCE選項來將AUTO_INCREMENT設定為較小的值。- 將
AUTO_INCREMENT設定為小於MAX(<auto_increment_column>)的值會導致重複鍵,因為預先存在的值不會被跳過。
熱點問題
AUTO_RANDOM
TiDB 資料庫的排程
PD (Placement Driver) 是 TiDB 叢集的管理模組,同時也負責叢集資料的實時排程。
場景描述
TiKV 叢集是 TiDB 資料庫的分散式 KV 儲存引擎,資料以 Region 為單位進行復制和管理,每個 Region 會有多個副本 (Replica),這些副本會分佈在不同的 TiKV 節點上,其中 Leader 負責讀/寫,Follower 負責同步 Leader 發來的 Raft log。
需要考慮以下場景:
- 為了提高叢集的空間利用率,需要根據 Region 的空間佔用對副本進行合理的分佈。
- 叢集進行跨機房部署的時候,要保證一個機房掉線,不會丟失 Raft Group 的多個副本。
- 新增一個節點進入 TiKV 叢集之後,需要合理地將叢集中其他節點上的資料搬到新增節點。
- 當一個節點掉線時,需要考慮快速穩定地進行容災。
- 從節點的恢復時間來看
- 如果節點只是短暫掉線(重啟服務),是否需要進行排程。
- 如果節點是長時間掉線(磁碟故障,資料全部丟失),如何進行排程。
- 假設叢集需要每個 Raft Group 有 N 個副本,從單個 Raft Group 的副本個數來看
- 副本數量不夠(例如節點掉線,失去副本),需要選擇適當的機器的進行補充。
- 副本數量過多(例如掉線的節點又恢復正常,自動加入叢集),需要合理的刪除多餘的副本。
- 從節點的恢復時間來看
- 讀/寫通過 Leader 進行,Leader 的分佈只集中在少量幾個節點會對叢集造成影響。
- 並不是所有的 Region 都被頻繁的存取,可能存取熱點只在少數幾個 Region,需要通過排程進行負載均衡。
- 叢集在做負載均衡的時候,往往需要搬遷資料,這種資料的遷移可能會佔用大量的網路頻寬、磁碟 IO 以及 CPU,進而影響線上服務。
以上問題和場景如果多個同時出現,就不太容易解決,因為需要考慮全域性資訊。同時整個系統也是在動態變化的,因此需要一箇中心節點,來對系統的整體狀況進行把控和調整,所以有了 PD 這個模組。
排程的需求
對以上的問題和場景進行分類和整理,可歸為以下兩類:
第一類:作為一個分散式高可用儲存系統,必須滿足的需求,包括幾種
- 副本數量不能多也不能少
- 副本需要根據拓撲結構分佈在不同屬性的機器上
- 節點宕機或異常能夠自動合理快速地進行容災
第二類:作為一個良好的分散式系統,需要考慮的地方包括
- 維持整個叢集的 Leader 分佈均勻
- 維持每個節點的儲存容量均勻
- 維持存取熱點分佈均勻
- 控制負載均衡的速度,避免影響線上服務
- 管理節點狀態,包括手動上線/下線節點
滿足第一類需求後,整個系統將具備強大的容災功能。滿足第二類需求後,可以使得系統整體的資源利用率更高且合理,具備良好的擴充套件性。
為了滿足這些需求,首先需要收集足夠的資訊,比如每個節點的狀態、每個 Raft Group 的資訊、業務存取操作的統計等;其次需要設定一些策略,PD 根據這些資訊以及排程的策略,制定出儘量滿足前面所述需求的排程計劃;最後需要一些基本的操作,來完成排程計劃。
排程的基本操作
排程的基本操作指的是為了滿足排程的策略。上述排程需求可整理為以下三個操作:
- 增加一個副本
- 刪除一個副本
- 將 Leader 角色在一個 Raft Group 的不同副本之間 transfer(遷移)
剛好 Raft 協定通過 AddReplica、RemoveReplica、TransferLeader 這三個命令,可以支撐上述三種基本操作。
資訊收集
排程依賴於整個叢集資訊的收集,簡單來說,排程需要知道每個 TiKV 節點的狀態以及每個 Region 的狀態。TiKV 叢集會向 PD 彙報兩類訊息,TiKV 節點資訊和 Region 資訊:
每個 TiKV 節點會定期向 PD 彙報節點的狀態資訊
TiKV 節點 (Store) 與 PD 之間存在心跳包,一方面 PD 通過心跳包檢測每個 Store 是否存活,以及是否有新加入的 Store;另一方面,心跳包中也會攜帶這個 Store 的狀態資訊,主要包括:
- 總磁碟容量
- 可用磁碟容量
- 承載的 Region 數量
- 資料寫入/讀取速度
- 傳送/接受的 Snapshot 數量(副本之間可能會通過 Snapshot 同步資料)
- 是否過載
- labels 標籤資訊(標籤是具備層級關係的一系列 Tag,能夠感知拓撲資訊)
通過使用
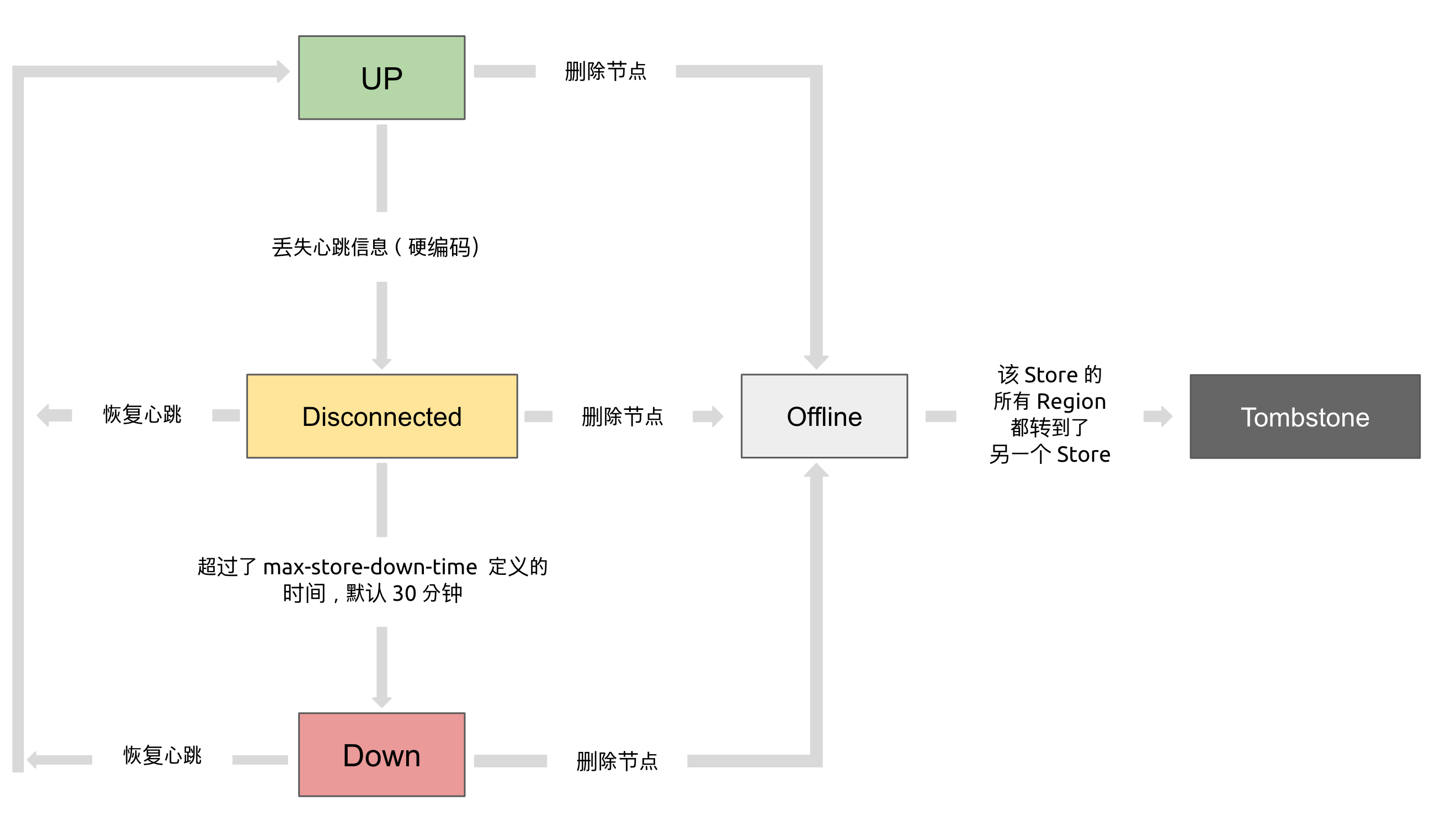
pd-ctl可以檢視到 TiKV Store 的狀態資訊。TiKV Store 的狀態具體分為 Up,Disconnect,Offline,Down,Tombstone。各狀態的關係如下:
- Up:表示當前的 TiKV Store 處於提供服務的狀態。
- Disconnect:當 PD 和 TiKV Store 的心跳資訊丟失超過 20 秒後,該 Store 的狀態會變為 Disconnect 狀態,當時間超過
max-store-down-time指定的時間後,該 Store 會變為 Down 狀態。 - Down:表示該 TiKV Store 與叢集失去連線的時間已經超過了
max-store-down-time指定的時間,預設 30 分鐘。超過該時間後,對應的 Store 會變為 Down,並且開始在存活的 Store 上補足各個 Region 的副本。 - Offline:當對某個 TiKV Store 通過 PD Control 進行手動下線操作,該 Store 會變為 Offline 狀態。該狀態只是 Store 下線的中間狀態,處於該狀態的 Store 會將其上的所有 Region 搬離至其它滿足搬遷條件的 Up 狀態 Store。當該 Store 的
leader_count和region_count(在 PD Control 中獲取) 均顯示為 0 後,該 Store 會由 Offline 狀態變為 Tombstone 狀態。在 Offline 狀態下,禁止關閉該 Store 服務以及其所在的物理伺服器。下線過程中,如果叢集裡不存在滿足搬遷條件的其它目標 Store(例如沒有足夠的 Store 能夠繼續滿足叢集的副本數量要求),該 Store 將一直處於 Offline 狀態。 - Tombstone:表示該 TiKV Store 已處於完全下線狀態,可以使用
remove-tombstone介面安全地清理該狀態的 TiKV。
每個 Raft Group 的 Leader 會定期向 PD 彙報 Region 的狀態資訊
每個 Raft Group 的 Leader 和 PD 之間存在心跳包,用於彙報這個 Region 的狀態,主要包括下面幾點資訊:
- Leader 的位置
- Followers 的位置
- 掉線副本的個數
- 資料寫入/讀取的速度
PD 不斷的通過這兩類心跳訊息收集整個叢集的資訊,再以這些資訊作為決策的依據。
除此之外,PD 還可以通過擴充套件的介面接受額外的資訊,用來做更準確的決策。比如當某個 Store 的心跳包中斷的時候,PD 並不能判斷這個節點是臨時失效還是永久失效,只能經過一段時間的等待(預設是 30 分鐘),如果一直沒有心跳包,就認為該 Store 已經下線,再決定需要將這個 Store 上面的 Region 都排程走。
但是有的時候,是運維人員主動將某臺機器下線,這個時候,可以通過 PD 的管理介面通知 PD 該 Store 不可用,PD 就可以馬上判斷需要將這個 Store 上面的 Region 都排程走。
排程的策略
PD 收集了這些資訊後,還需要一些策略來制定具體的排程計劃。
一個 Region 的副本數量正確
當 PD 通過某個 Region Leader 的心跳包發現這個 Region 的副本數量不滿足要求時,需要通過 Add/Remove Replica 操作調整副本數量。出現這種情況的可能原因是:
- 某個節點掉線,上面的資料全部丟失,導致一些 Region 的副本數量不足
- 某個掉線節點又恢復服務,自動接入叢集,這樣之前已經補足了副本的 Region 的副本數量過多,需要刪除某個副本
- 管理員調整副本策略,修改了 max-replicas 的設定
一個 Raft Group 中的多個副本不在同一個位置
注意這裡用的是『同一個位置』而不是『同一個節點』。在一般情況下,PD 只會保證多個副本不落在一個節點上,以避免單個節點失效導致多個副本丟失。在實際部署中,還可能出現下面這些需求:
- 多個節點部署在同一臺物理機器上
- TiKV 節點分佈在多個機架上,希望單個機架掉電時,也能保證系統可用性
- TiKV 節點分佈在多個 IDC 中,希望單個機房掉電時,也能保證系統可用性
這些需求本質上都是某一個節點具備共同的位置屬性,構成一個最小的『容錯單元』,希望這個單元內部不會存在一個 Region 的多個副本。這個時候,可以給節點設定 labels 並且通過在 PD 上設定 location-labels 來指名哪些 label 是位置標識,需要在副本分配的時候儘量保證一個 Region 的多個副本不會分佈在具有相同的位置標識的節點上。
副本在 Store 之間的分佈均勻分配
由於每個 Region 的副本中儲存的資料容量上限是固定的,通過維持每個節點上面副本數量的均衡,使得各節點間承載的資料更均衡。
Leader 數量在 Store 之間均勻分配
Raft 協定要求讀取和寫入都通過 Leader 進行,所以計算的負載主要在 Leader 上面,PD 會盡可能將 Leader 在節點間分散開。
存取熱點數量在 Store 之間均勻分配
每個 Store 以及 Region Leader 在上報資訊時攜帶了當前存取負載的資訊,比如 Key 的讀取/寫入速度。PD 會檢測出存取熱點,且將其在節點之間分散開。
各個 Store 的儲存空間佔用大致相等
每個 Store 啟動的時候都會指定一個
Capacity引數,表明這個 Store 的儲存空間上限,PD 在做排程的時候,會考慮節點的儲存空間剩餘量。
控制排程速度,避免影響線上服務
排程操作需要耗費 CPU、記憶體、磁碟 IO 以及網路頻寬,需要避免對線上服務造成太大影響。PD 會對當前正在進行的運算元量進行控制,預設的速度控制是比較保守的,如果希望加快排程(比如停服務升級或者增加新節點,希望儘快排程),那麼可以通過調節 PD 引數動態加快排程速度。
排程的實現
PD 不斷地通過 Store 或者 Leader 的心跳包收集整個叢集資訊,並且根據這些資訊以及排程策略生成排程操作序列。每次收到 Region Leader 發來的心跳包時,PD 都會檢查這個 Region 是否有待進行的操作,然後通過心跳包的回覆訊息,將需要進行的操作返回給 Region Leader,並在後面的心跳包中監測執行結果。
注意這裡的操作只是給 Region Leader 的建議,並不保證一定能得到執行,具體是否會執行以及什麼時候執行,由 Region Leader 根據當前自身狀態來定。
TiDB 資料庫的儲存
TiKV 的一些設計思想和關鍵概念。
Key-Value Pairs(鍵值對)
作為儲存資料的系統,首先要決定的是資料的儲存模型,也就是資料以什麼樣的形式儲存下來。TiKV 的選擇是 Key-Value 模型,並且提供有序遍歷方法。
TiKV 資料儲存的兩個關鍵點:
- 這是一個巨大的 Map(可以類比一下 C++ 的 std::map),也就是儲存的是 Key-Value Pairs(鍵值對)
- 這個 Map 中的 Key-Value pair 按照 Key 的二進位制順序有序,也就是可以 Seek 到某一個 Key 的位置,然後不斷地呼叫 Next 方法以遞增的順序獲取比這個 Key 大的 Key-Value。
注意, TiKV 的 KV 儲存模型和 SQL 中的 Table 無關。
本地儲存 (RocksDB)
任何持久化的儲存引擎,資料終歸要儲存在磁碟上,TiKV 也不例外。但是 TiKV 沒有選擇直接向磁碟上寫資料,而是把資料儲存在 RocksDB 中,具體的資料落地由 RocksDB 負責。這個選擇的原因是開發一個單機儲存引擎工作量很大,特別是要做一個高效能的單機引擎,需要做各種細緻的優化,而 RocksDB 是由 Facebook 開源的一個非常優秀的單機 KV 儲存引擎,可以滿足 TiKV 對單機引擎的各種要求。這裡可以簡單的認為 RocksDB 是一個單機的持久化 Key-Value Map。
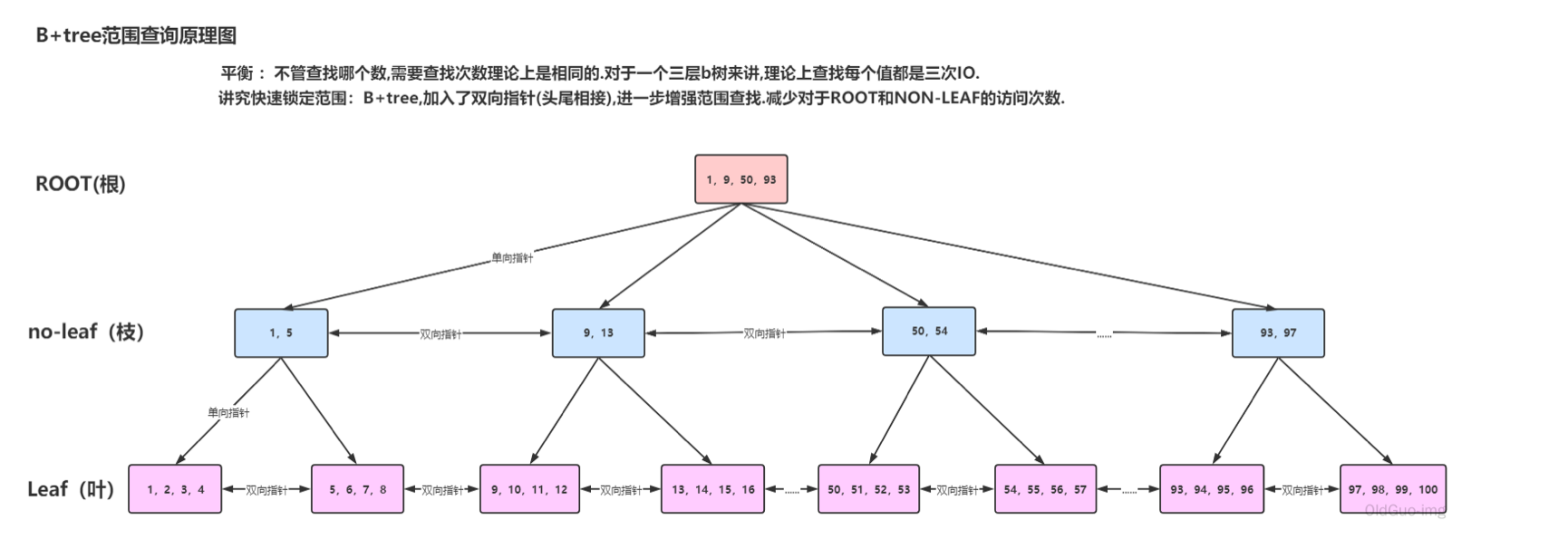
LSM 樹
-
傳統B+Tree 資料結構
wal log 預寫紀錄檔 不經過系統快取,直接寫入磁碟
查詢 分配key, bloom
LSM樹和B+Tree 最大的不同在於資料更新的方式,在B+Tree 中,資料的更新是直接在原資料所在的位置進行修改,而LSM樹中,資料的更新是通過追加紀錄檔形式完成的。這種追加方式使得LSM樹可以順序寫,避免了頻繁的隨機寫,從而提高了寫的效能。
在LSM樹中,資料被儲存在不同的層次中,每個層次對應一組SSTable檔案。當MemTable中的資料達到一定的大小時,會被刷寫(flush)到磁碟上,生成一個新的SSTable檔案。由於SSTable檔案是不可變的,因此所有的更新都被追加到新的SSTable檔案中,而不是在原有的檔案中進行修改。
這種追加式的更新方式會導致資料冗餘的問題,即某個Key在不同的SSTable檔案中可能存在多個版本。這些版本中,只有最新的版本是有效的,其他的版本都是冗餘的。為了解決這個問題,需要定期進行SSTable的合併(Compaction)操作,將不同的SSTable檔案中相同Key的資料進行合併,並將舊版本的資料刪除,從而減少冗餘資料的儲存空間。
LSM樹壓縮策略需要圍繞三個問題進行考量(讀放大、寫放大、空間放大):
- 讀放大(Read Amplification)是指在讀取資料時,需要讀取的資料量大於實際的資料量。在LSM樹中,需要先在MemTable中檢視是否存在該key,如果不存在,則需要繼續在SSTable中查詢,直到找到為止。如果資料被分散在多個SSTable中,則需要遍歷所有的SSTable,這就導致了讀放大。如果資料分佈比較均勻,則讀放大不會很嚴重,但如果資料分佈不均,則可能需要遍歷大量的SSTable才能找到目標資料。
- 寫放大(Write Amplification)是指在寫入資料時,實際寫入的資料量大於真正的資料量。在LSM樹中,寫入資料時可能會觸發Compact操作,這會導致一些SSTable中的冗餘資料被清理回收,但同時也會產生新的SSTable,因此實際寫入的資料量可能遠大於該key的資料量。
- 空間放大(Space Amplification)是指資料實際佔用的磁碟空間比資料的真正大小更多。在LSM樹中,由於資料的更新是以紀錄檔形式進行的,因此同一個key可能在多個SSTable中都存在,而只有最新的那條記錄是有效的,之前的記錄都可以被清理回收。這就導致了空間的浪費,也就是空間放大。為了減少空間浪費,LSM樹需要定期進行Compact操作,將多個SSTable中相同的key進行合併,去除冗餘資料,減少磁碟空間的佔用。
-
TiKV如何做到高並行讀寫
-
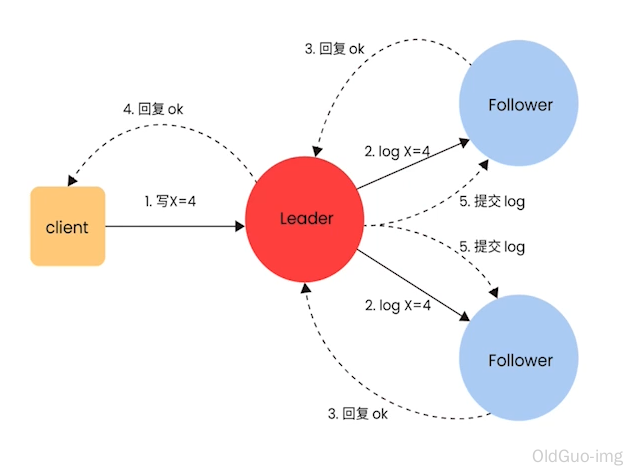
TIDB如何保證多副本一致性和高可用
Raft 協定
http://thesecretlivesofdata.com/raft/
接下來 TiKV 的實現面臨一件更難的事情:如何保證單機失效的情況下,資料不丟失,不出錯?
簡單來說,需要想辦法把資料複製到多臺機器上,這樣一臺機器無法服務了,其他的機器上的副本還能提供服務;複雜來說,還需要這個資料複製方案是可靠和高效的,並且能處理副本失效的情況。TiKV 選擇了 Raft 演演算法。Raft 是一個一致性協定,本文只會對 Raft 做一個簡要的介紹,細節問題可以參考它的論文。Raft 提供幾個重要的功能:
-
Leader(主副本)選舉
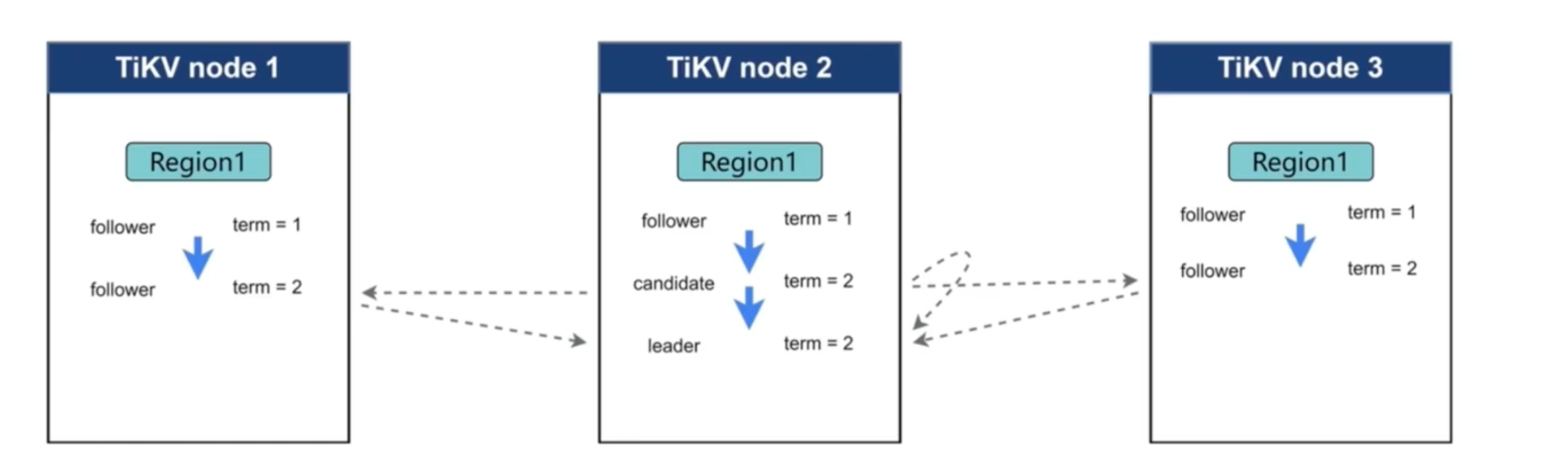
-
成員變更(如新增副本、刪除副本、轉移 Leader 等操作)
-
紀錄檔複製
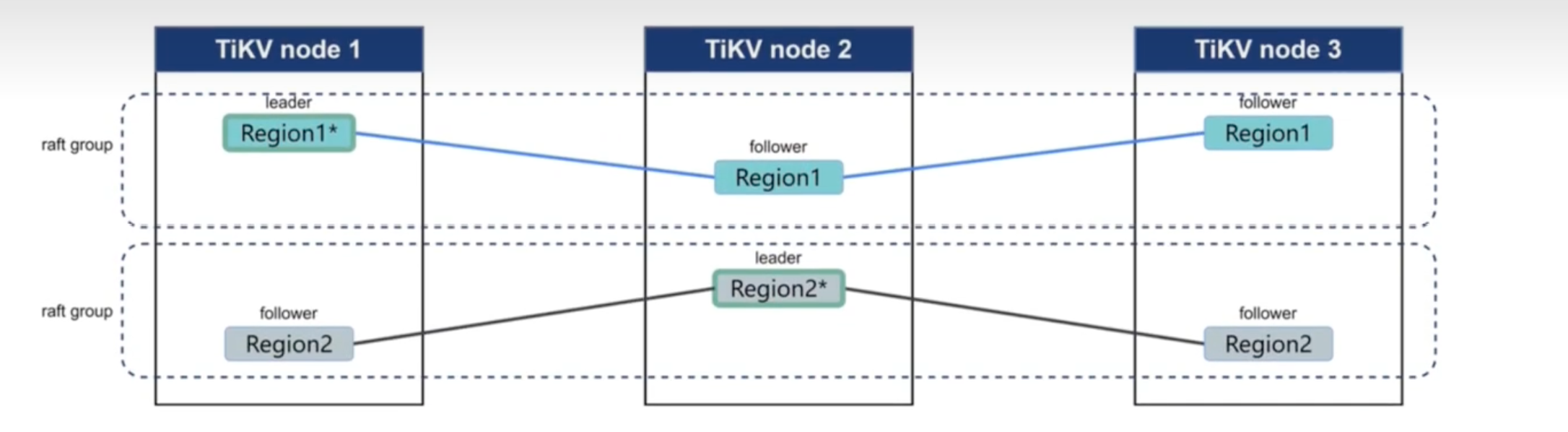
TiKV 利用 Raft 來做資料複製,每個資料變更都會落地為一條 Raft 紀錄檔,通過 Raft 的紀錄檔複製功能,將資料安全可靠地同步到複製組的每一個節點中。不過在實際寫入中,根據 Raft 的協定,只需要同步複製到多數節點,即可安全地認為資料寫入成功。
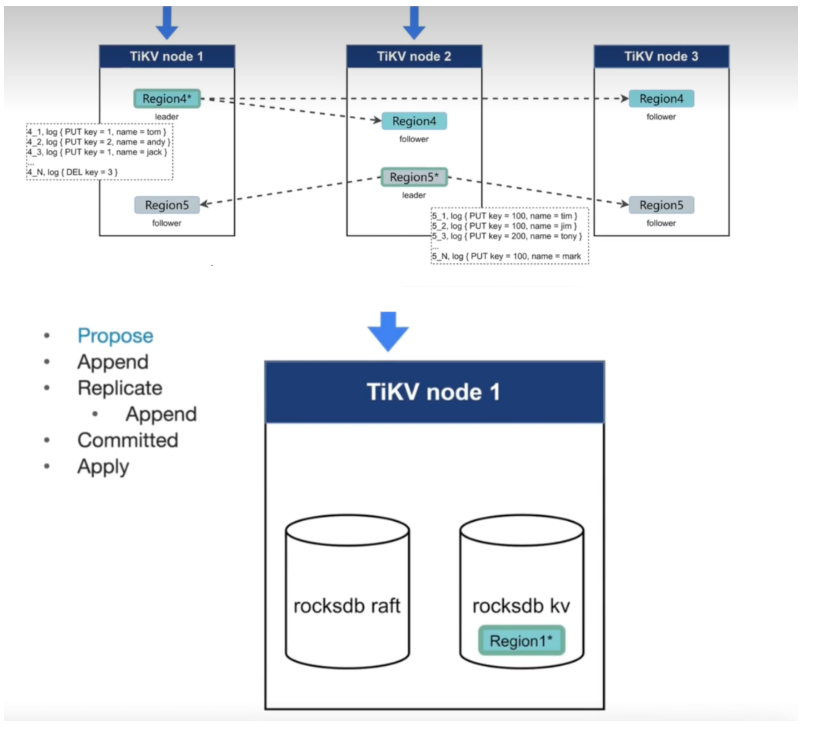
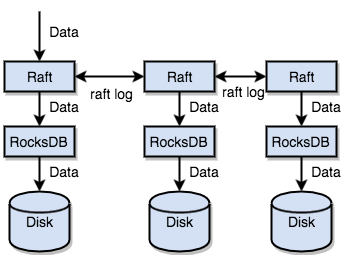
總結一下,通過單機的 RocksDB,TiKV 可以將資料快速地儲存在磁碟上;通過 Raft,將資料複製到多臺機器上,以防單機失效。資料的寫入是通過 Raft 這一層的介面寫入,而不是直接寫 RocksDB。通過實現 Raft,TiKV 變成了一個分散式的 Key-Value 儲存,少數幾臺機器宕機也能通過原生的 Raft 協定自動把副本補全,可以做到對業務無感知。
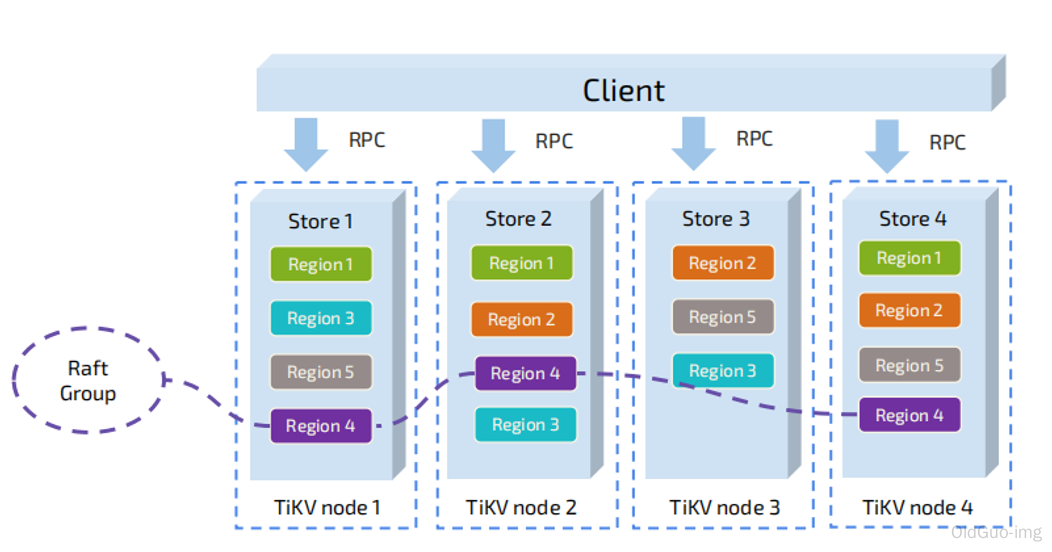
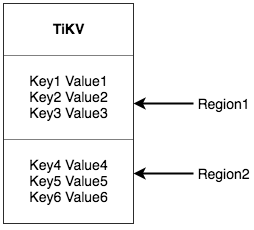
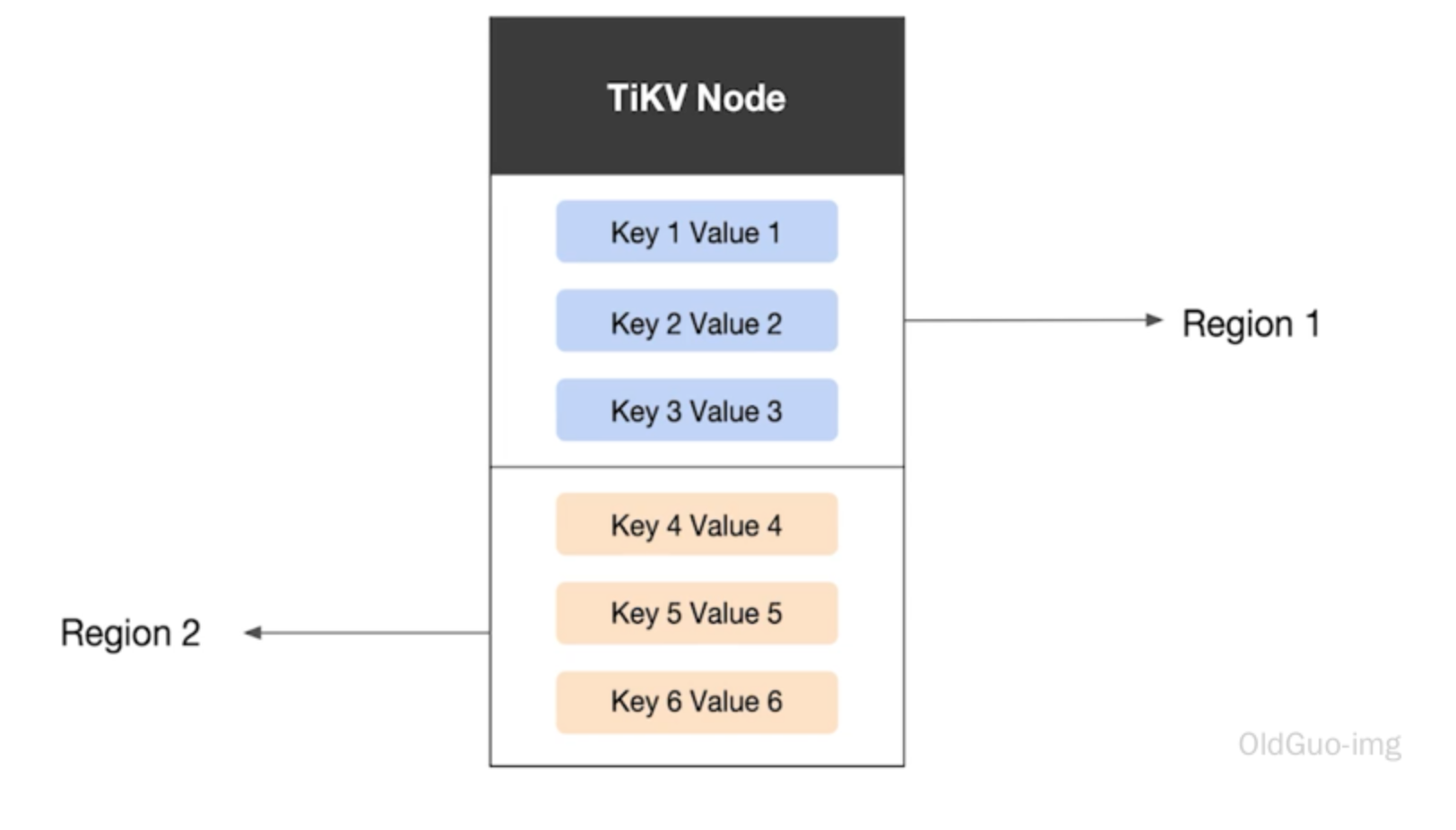
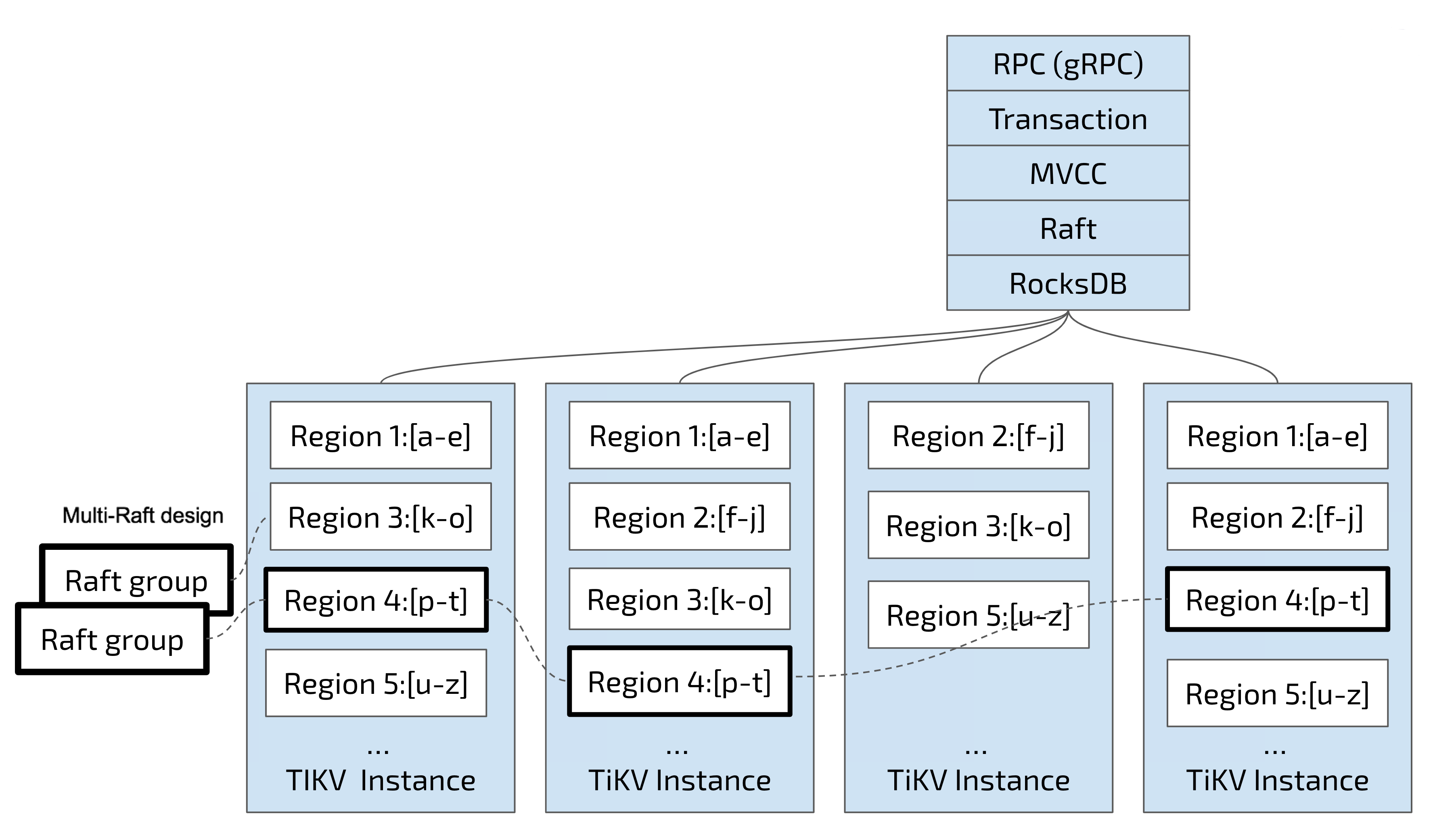
Region
首先,假設所有的資料都只有一個副本。前面提到,TiKV 可以看做是一個巨大的有序的 KV Map,那麼為了實現儲存的水平擴充套件,資料將被分散在多臺機器上。對於一個 KV 系統,將資料分散在多臺機器上有兩種比較典型的方案:
- Hash:按照 Key 做 Hash,根據 Hash 值選擇對應的儲存節點。
- Range:按照 Key 分 Range,某一段連續的 Key 都儲存在一個儲存節點上。
TiKV 選擇了第二種方式,將整個 Key-Value 空間分成很多段,每一段是一系列連續的 Key,將每一段叫做一個 Region,可以用 [StartKey,EndKey) 這樣一個左閉右開區間來描述。每個 Region 中儲存的資料量預設維持在 96 MiB 左右(可以通過設定修改)。
注意,這裡的 Region 還是和 SQL 中的表沒什麼關係。 這裡的討論依然不涉及 SQL,只和 KV 有關。
將資料劃分成 Region 後,TiKV 將會做兩件重要的事情:
- 以 Region 為單位,將資料分散在叢集中所有的節點上,並且儘量保證每個節點上服務的 Region 數量差不多。
- 以 Region 為單位做 Raft 的複製和成員管理。
這兩點非常重要:
- 先看第一點,資料按照 Key 切分成很多 Region,每個 Region 的資料只會儲存在一個節點上面(暫不考慮多副本)。TiDB 系統會有一個元件 (PD) 來負責將 Region 儘可能均勻的散佈在叢集中所有的節點上,這樣一方面實現了儲存容量的水平擴充套件(增加新的節點後,會自動將其他節點上的 Region 排程過來),另一方面也實現了負載均衡(不會出現某個節點有很多資料,其他節點上沒什麼資料的情況)。同時為了保證上層使用者端能夠存取所需要的資料,系統中也會有一個元件 (PD) 記錄 Region 在節點上面的分佈情況,也就是通過任意一個 Key 就能查詢到這個 Key 在哪個 Region 中,以及這個 Region 目前在哪個節點上(即 Key 的位置路由資訊)。
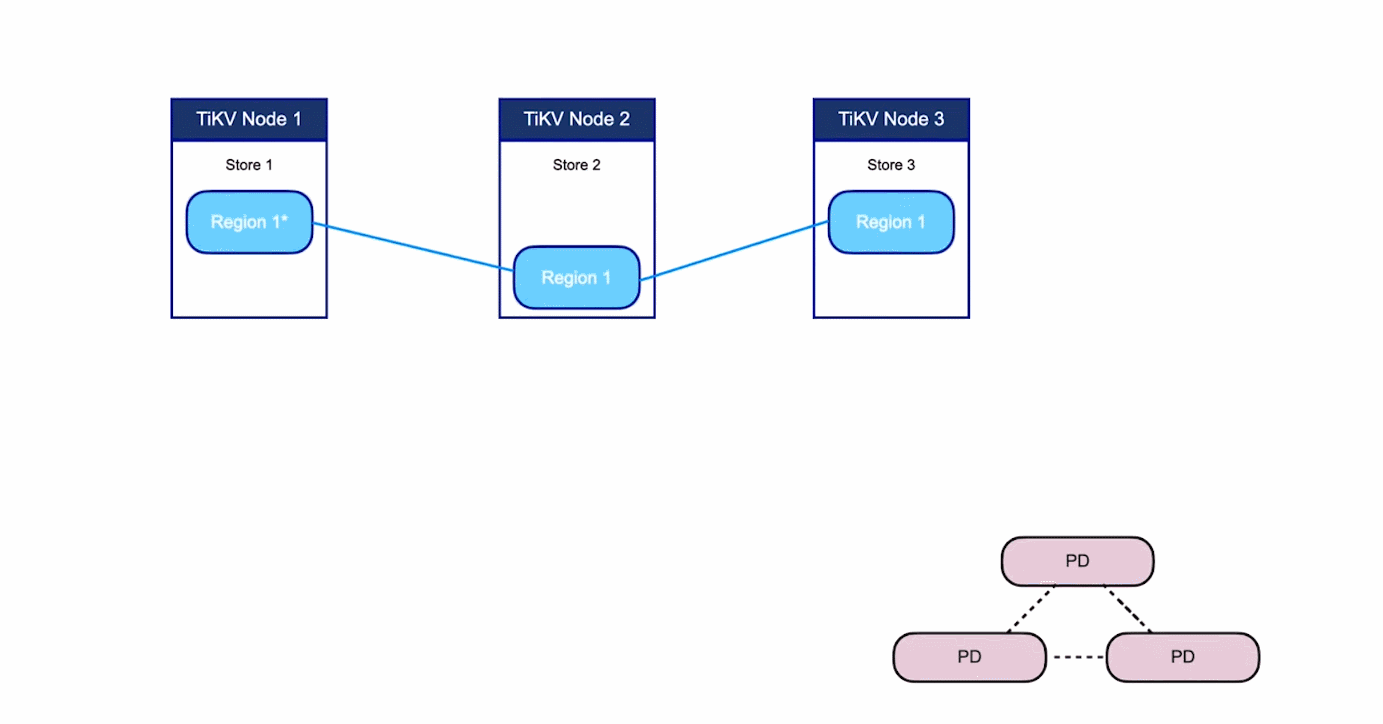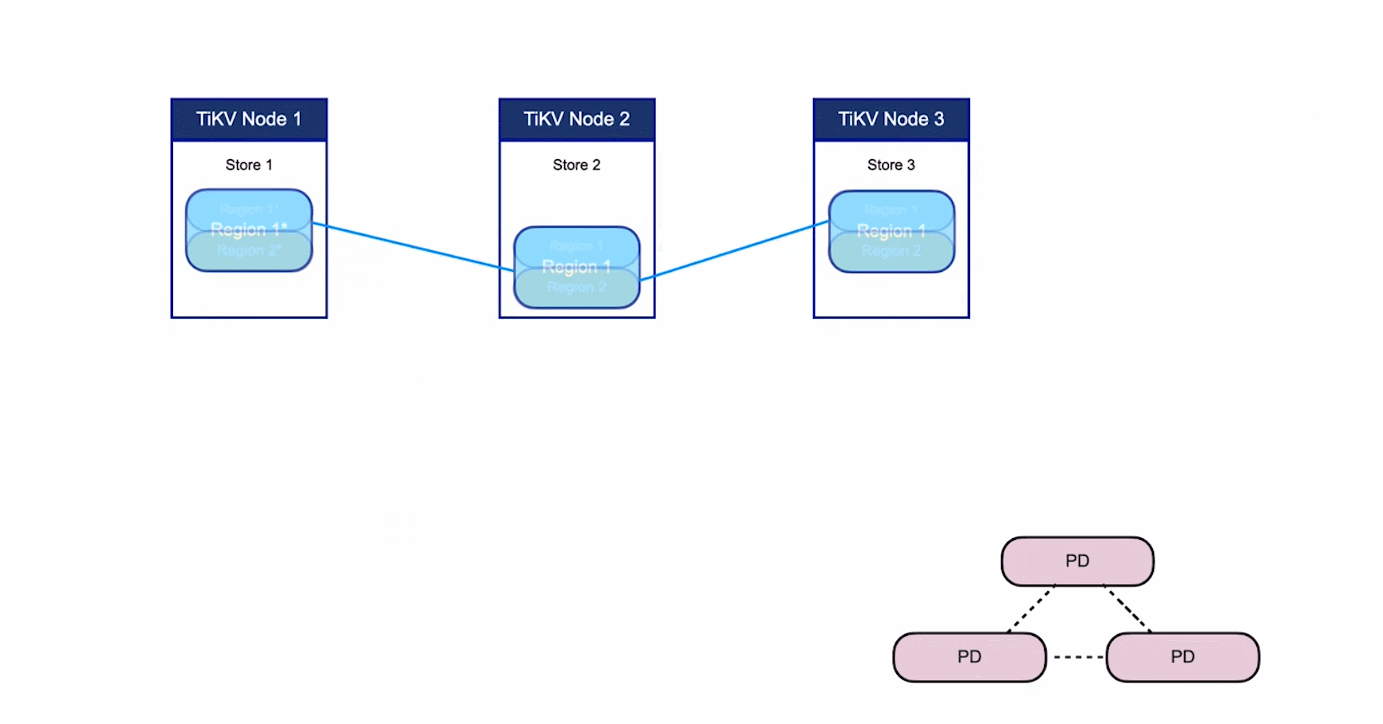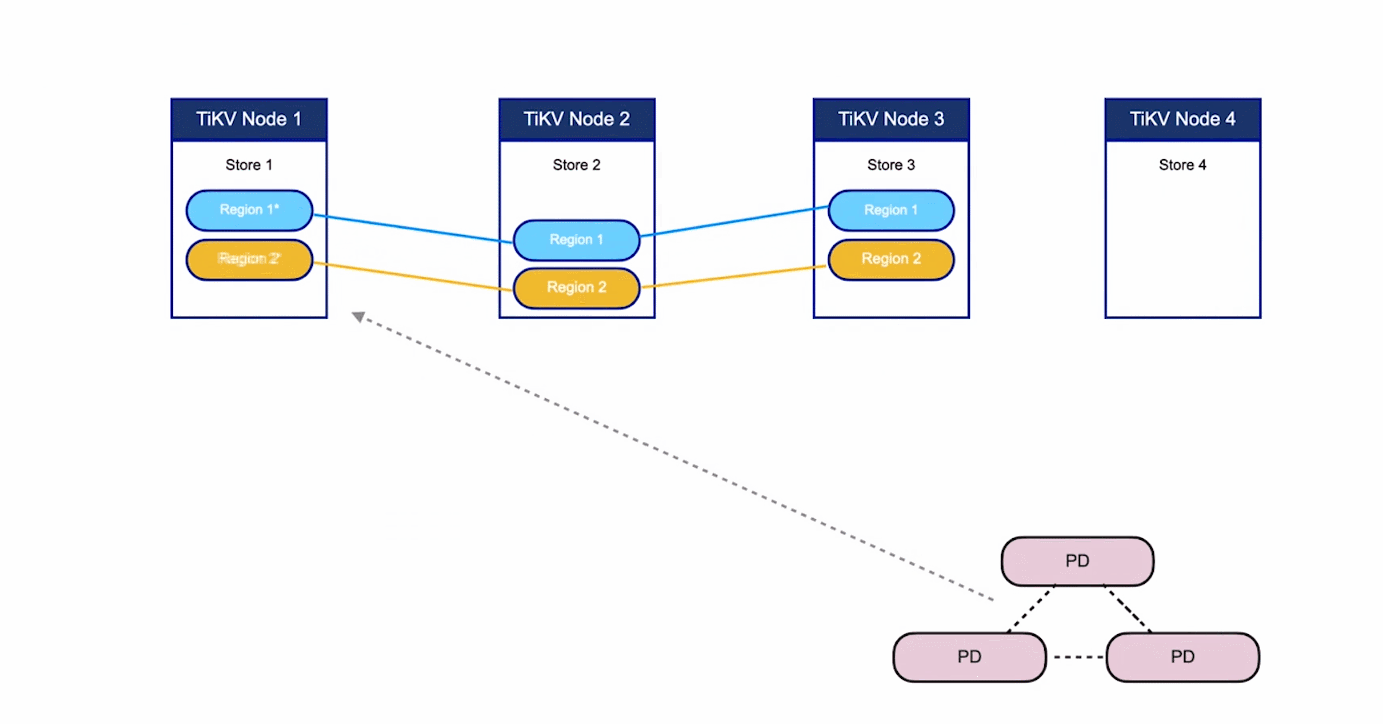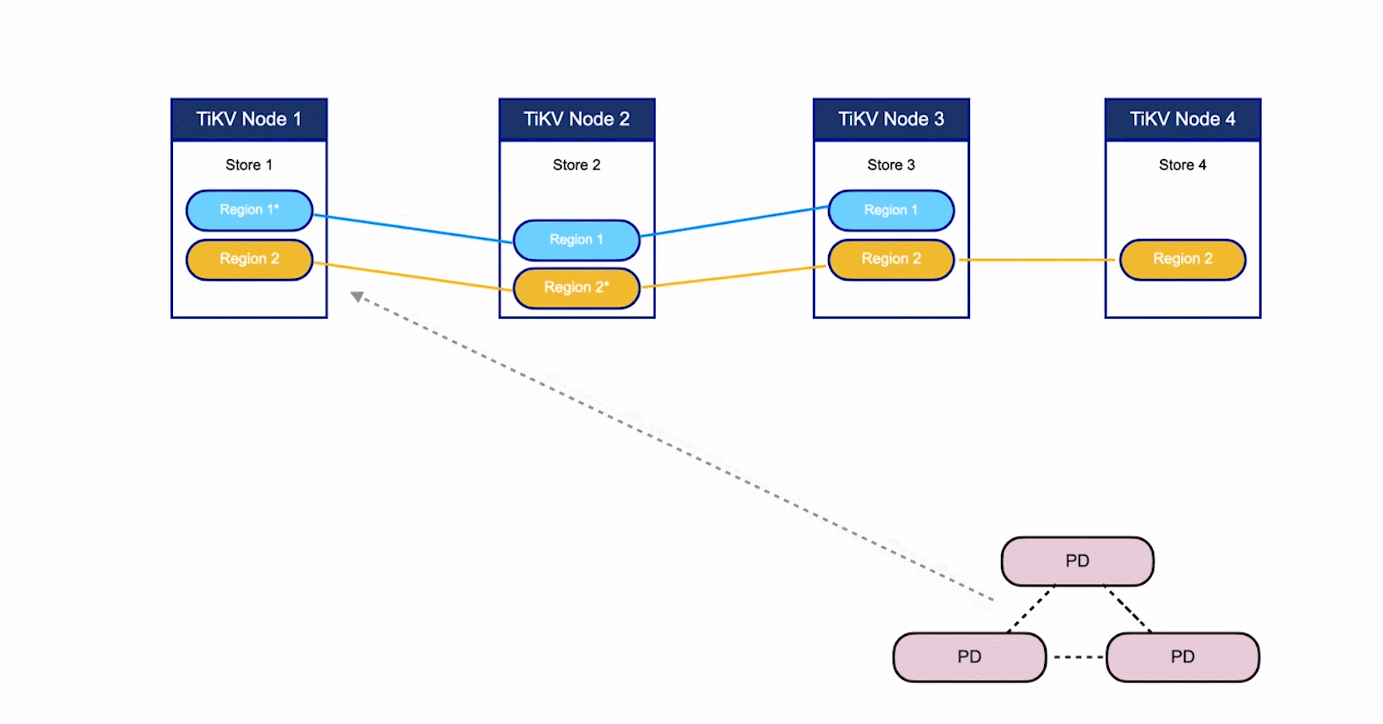
- 對於第二點,TiKV 是以 Region 為單位做資料的複製,也就是一個 Region 的資料會儲存多個副本,TiKV 將每一個副本叫做一個 Replica。Replica 之間是通過 Raft 來保持資料的一致,一個 Region 的多個 Replica 會儲存在不同的節點上,構成一個 Raft Group。其中一個 Replica 會作為這個 Group 的 Leader,其他的 Replica 作為 Follower。預設情況下,所有的讀和寫都是通過 Leader 進行,讀操作在 Leader 上即可完成,而寫操作再由 Leader 複製給 Follower。
大家理解了 Region 之後,應該可以理解下面這張圖:
以 Region 為單位做資料的分散和複製,TiKV 就成為了一個分散式的具備一定容災能力的 KeyValue 系統,不用再擔心資料存不下,或者是磁碟故障丟失資料的問題。
MVCC
很多資料庫都會實現多版本並行控制 (MVCC),TiKV 也不例外。設想這樣的場景:兩個使用者端同時去修改一個 Key 的 Value,如果沒有資料的多版本控制,就需要對資料上鎖,在分散式場景下,可能會帶來效能以及死鎖問題。
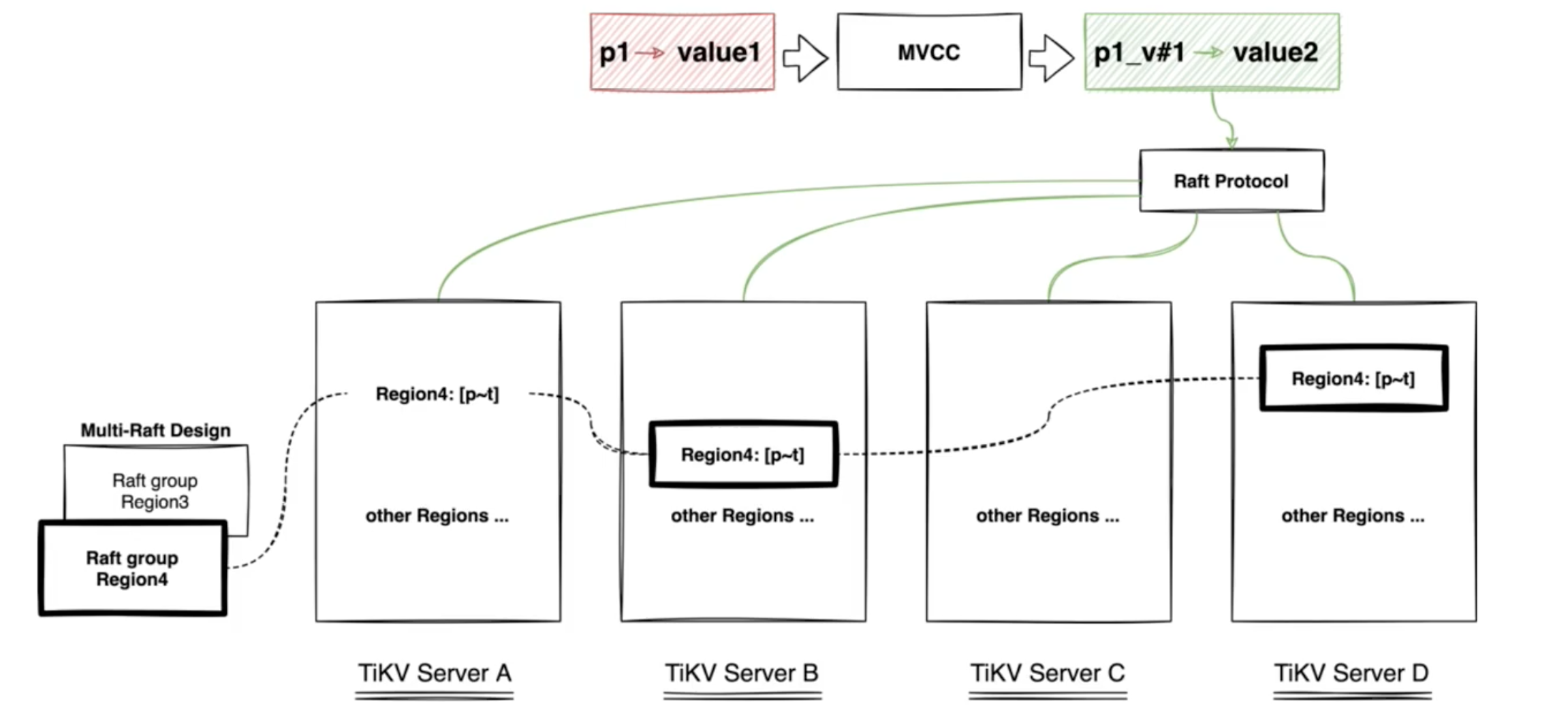
TiKV 的 MVCC 實現是通過在 Key 後面新增版本號來實現,簡單來說,沒有 MVCC 之前,可以把 TiKV 看做這樣的:
Key1 -> Value Key2 -> Value …… KeyN -> Value有了 MVCC 之後,TiKV 的 Key 排列是這樣的:
Key1_Version3 -> Value Key1_Version2 -> Value Key1_Version1 -> Value …… Key2_Version4 -> Value Key2_Version3 -> Value Key2_Version2 -> Value Key2_Version1 -> Value …… KeyN_Version2 -> Value KeyN_Version1 -> Value ……注意,對於同一個 Key 的多個版本,版本號較大的會被放在前面,版本號小的會被放在後面(見 Key-Value 一節,Key 是有序的排列),這樣當用戶通過一個 Key + Version 來獲取 Value 的時候,可以通過 Key 和 Version 構造出 MVCC 的 Key,也就是 Key_Version。然後可以直接通過 RocksDB 的 SeekPrefix(Key_Version) API,定位到第一個大於等於這個 Key_Version 的位置。
分散式 ACID 事務
TiKV 的事務採用的是 Google 在 BigTable 中使用的事務模型:Percolator,TiKV 根據這篇論文實現,並做了大量的優化。詳細介紹參見事務概覽。
TiFlash 架構特性
TIDB可執行計劃
運算元簡介
運算元是為返回查詢結果而執行的特定步驟。真正執行掃表(讀盤或者讀 TiKV Block Cache)操作的運算元有如下幾類:
- TableFullScan:全表掃描。
- TableRangeScan:帶有範圍的表資料掃描。
- TableRowIDScan:根據上層傳遞下來的 RowID 掃描表資料。時常在索引讀操作後檢索符合條件的行。
- IndexFullScan:另一種「全表掃描」,掃的是索引資料,不是表資料。
- IndexRangeScan:帶有範圍的索引資料掃描操作。
TiDB 會匯聚 TiKV/TiFlash 上掃描的資料或者計算結果,這種「資料匯聚」運算元目前有如下幾類:
- TableReader:將 TiKV 上底層掃表運算元 TableFullScan 或 TableRangeScan 得到的資料進行彙總。
- IndexReader:將 TiKV 上底層掃表運算元 IndexFullScan 或 IndexRangeScan 得到的資料進行彙總。
- IndexLookUp:先彙總 Build 端 TiKV 掃描上來的 RowID,再去 Probe 端上根據這些
RowID精確地讀取 TiKV 上的資料。Build 端是IndexFullScan或IndexRangeScan型別的運算元,Probe 端是TableRowIDScan型別的運算元。 - IndexMerge:和
IndexLookupReader類似,可以看做是它的擴充套件,可以同時讀取多個索引的資料,有多個 Build 端,一個 Probe 端。執行過程也很類似,先彙總所有 Build 端 TiKV 掃描上來的 RowID,再去 Probe 端上根據這些 RowID 精確地讀取 TiKV 上的資料。Build 端是IndexFullScan或IndexRangeScan型別的運算元,Probe 端是TableRowIDScan型別的運算元。
運算元的執行順序
運算元的結構是樹狀的,但在查詢執行過程中,並不嚴格要求子節點任務在父節點之前完成。TiDB 支援同一查詢內的並行處理,即子節點「流入」父節點。父節點、子節點和同級節點可能並行執行查詢的一部分。
在以上範例中,
├─IndexRangeScan_8(Build)運算元為a(a)索引所匹配的行查詢內部 RowID。└─TableRowIDScan_9(Probe)運算元隨後從表中檢索這些行。Build 總是先於 Probe 執行,並且 Build 總是出現在 Probe 前面。即如果一個運算元有多個子節點,子節點 ID 後面有 Build 關鍵字的運算元總是先於有 Probe 關鍵字的運算元執行。TiDB 在展現執行計劃的時候,Build 端總是第一個出現,接著才是 Probe 端。
範圍查詢
在
WHERE/HAVING/ON條件中,TiDB 優化器會分析主鍵或索引鍵的查詢返回。如數位、日期型別的比較符,如大於、小於、等於以及大於等於、小於等於,字元型別的LIKE符號等。若要使用索引,條件必須是 "Sargable" (Search ARGument ABLE) 的。例如條件
YEAR(date_column) < 1992不能使用索引,但date_column < '1992-01-01就可以使用索引。推薦使用同一型別的資料以及同一型別的字串和排序規則進行比較,以避免引入額外的
cast操作而導致不能利用索引。可以在範圍查詢條件中使用
AND(求交集)和OR(求並集)進行組合。對於多維組合索引,可以對多個列使用條件。例如對組合索引(a, b, c):- 當
a為等值查詢時,可以繼續求b的查詢範圍。 - 當
b也為等值查詢時,可以繼續求c的查詢範圍。 - 反之,如果
a為非等值查詢,則只能求a的範圍。
Task 簡介
目前 TiDB 的計算任務分為兩種不同的 task:cop task 和 root task。Cop task 是指使用 TiKV 中的 Coprocessor 執行的計算任務,root task 是指在 TiDB 中執行的計算任務。
SQL 優化的目標之一是將計算儘可能地下推到 TiKV 中執行。TiKV 中的 Coprocessor 能支援大部分 SQL 內建函數(包括聚合函數和標量函數)、SQL
LIMIT操作、索引掃描和表掃描。operator info結果EXPLAIN返回結果中operator info列可顯示諸如條件下推等資訊。本文以上範例中,operator info結果各欄位解釋如下:range: [1,1]表示查詢的WHERE字句 (a = 1) 被下推到了 TiKV,對應的 task 為cop[tikv]。keep order:false表示該查詢的語意不需要 TiKV 按順序返回結果。如果查詢指定了排序(例如SELECT * FROM t WHERE a = 1 ORDER BY id),該欄位的返回結果為keep order:true。stats:pseudo表示estRows顯示的預估數可能不準確。TiDB 定期在後臺更新統計資訊。也可以通過執行ANALYZE TABLE t來手動更新統計資訊。
EXPLAIN執行後,不同運算元返回不同的資訊。你可以使用 Optimizer Hints 來控制優化器的行為,以此控制物理運算元的選擇。例如/*+ HASH_JOIN(t1, t2) */表示優化器將使用 Hash Join 演演算法。詳細內容見 Optimizer Hints。TIDB優化器
TIDB SQL優化
關鍵模組
-
邏輯優化
- 列剪裁
- 分割區剪裁
- 聚合消除
- Max/Min 優化
- 投影消除
- 外連線消除
- 子查詢關聯
- 運算元下推
- 外連線轉內連線
- 謂詞下推
- 連線順序調整
-
Max/Min 優化有序
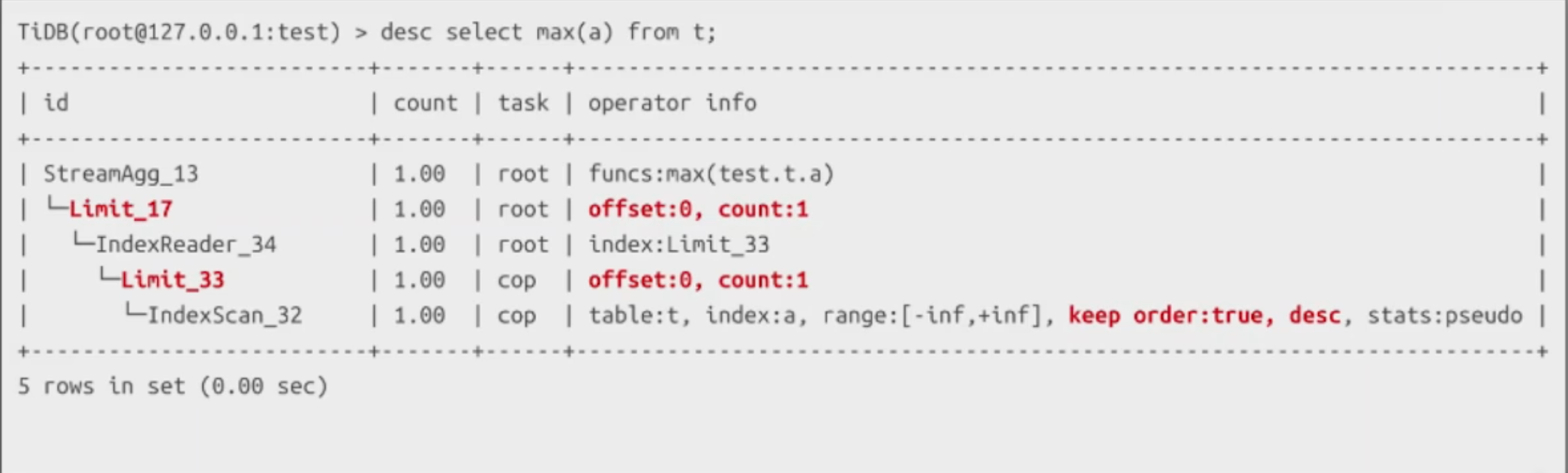
-
Max/Min 優化無序
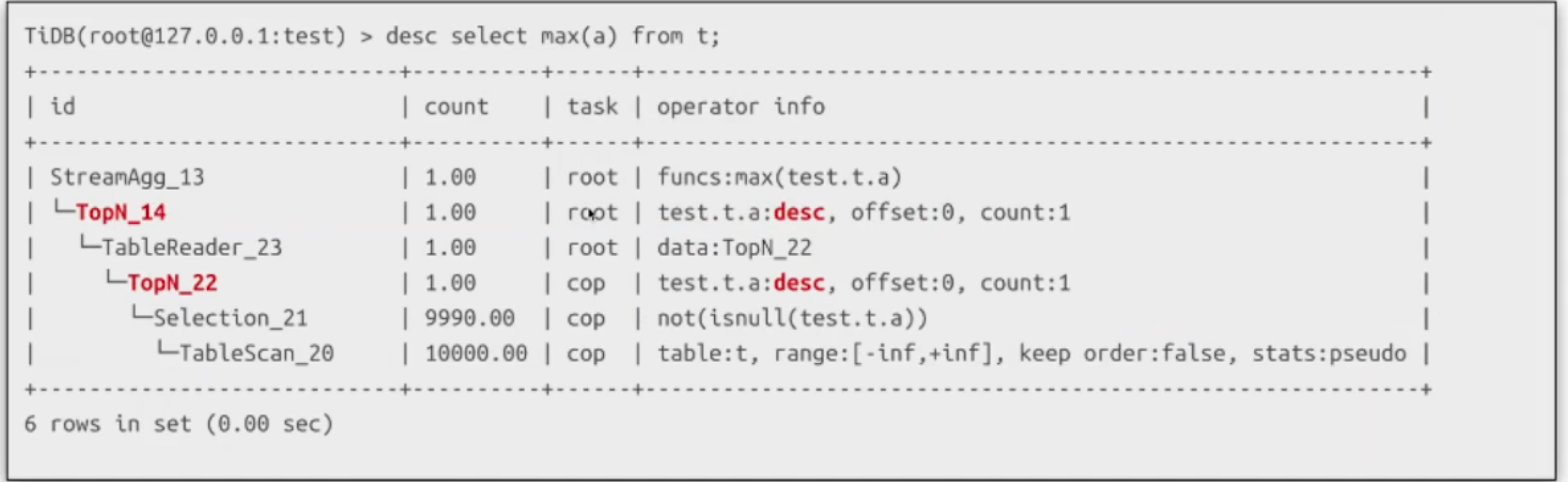
-
外連線轉內連線 & 謂詞下推
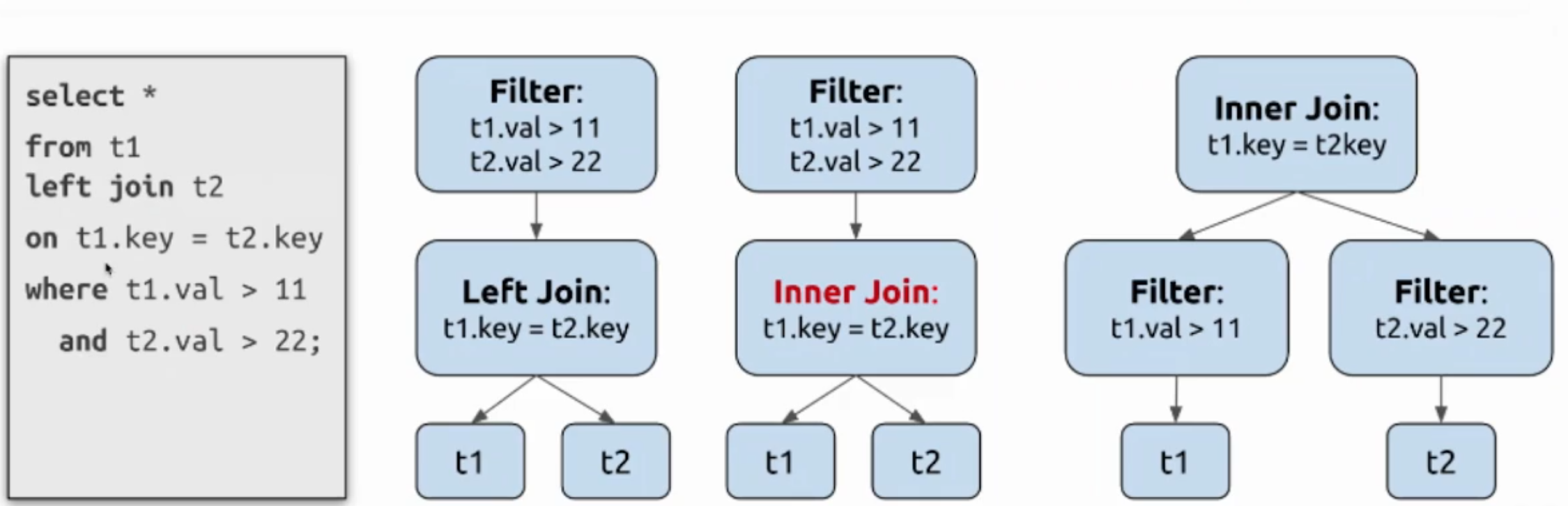
-
連線順序調整
- 提取參與連線的輸入運算元
- 計算各運算元的統計資訊
- 對小規模連線用動態規劃求解最優連線順序
- 對大規模連線用貪婪演演算法求解最優連線順序
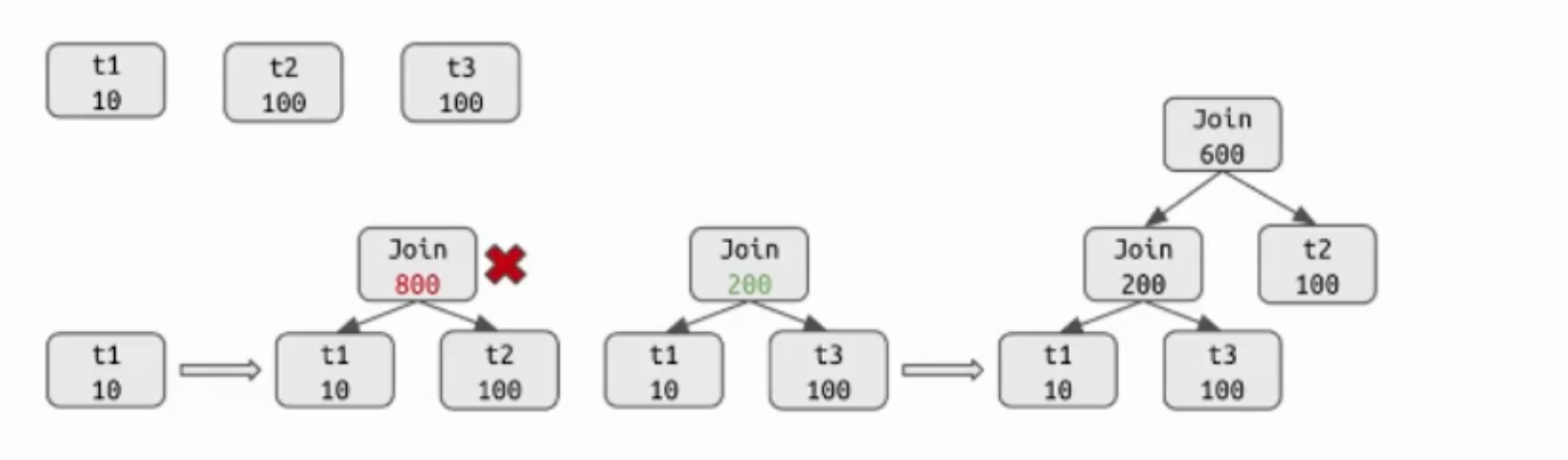
-
物理優化
-
統計資訊
索引使用
CREATE TABLE `books` ( `id` bigint(20) AUTO_RANDOM NOT NULL, `title` varchar(100) NOT NULL, `type` enum('Magazine', 'Novel', 'Life', 'Arts', 'Comics', 'Education & Reference', 'Humanities & Social Sciences', 'Science & Technology', 'Kids', 'Sports') NOT NULL, `published_at` datetime NOT NULL, `stock` int(11) DEFAULT '0', `price` decimal(15,2) DEFAULT '0.0', PRIMARY KEY (`id`) CLUSTERED ) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;建立索引的最佳實踐
- 建立你需要使用的資料的所有列的組合索引,這種優化技巧被稱為覆蓋索引優化 (covering index optimization)。覆蓋索引優化將使得 TiDB 可以直接在索引上得到該查詢所需的所有資料,可以大幅提升效能。
- 避免建立你不需要的二級索引,有用的二級索引能加速查詢,但是要注意新增一個索引是有副作用的。每增加一個索引,在插入一條資料的時候,就要額外新增一個 Key-Value,所以索引越多,寫入越慢,並且空間佔用越大。另外過多的索引也會影響優化器執行時間,並且不合適的索引會誤導優化器。所以索引並不是越多越好。
- 根據具體的業務特點建立合適的索引。原則上需要對查詢中需要用到的列建立索引,目的是提高效能。下面幾種情況適合建立索引:
- 區分度比較大的列,通過索引能顯著地減少過濾後的行數。例如推薦在人的身份證號碼這一列上建立索引,但不推薦在人的性別這一列上建立索引。
- 有多個查詢條件時,可以選擇組合索引,注意需要把等值條件的列放在組合索引的前面。這裡舉一個例子,假設常用的查詢是
SELECT * FROM t where c1 = 10 and c2 = 100 and c3 > 10,那麼可以考慮建立組合索引Index cidx (c1, c2, c3),這樣可以用查詢條件構造出一個索引字首進行 Scan。
- 請使用有意義的二級索引名,推薦你遵循公司或組織的表命名規範。如果你的公司或組織沒有相應的命名規範,可參考索引命名規範。
使用索引的最佳實踐
-
建立索引的目的是為了加速查詢,所以請確保索引能在一些查詢中被用上。如果一個索引不會被任何查詢語句用到,那這個索引是沒有意義的,請刪除這個索引。
-
使用組合索引時,需要滿足最左字首原則。
例如假設在列
title, published_at上新建一個組合索引索引:CREATE INDEX title_published_at_idx ON books (title, published_at);下面這個查詢依然能用上這個組合索引:
SELECT * FROM books WHERE title = 'database';但下面這個查詢由於未指定組合索引中最左邊第一列的條件,所以無法使用組合索引:
SELECT * FROM books WHERE published_at = '2018-08-18 21:42:08'; -
在查詢條件中使用索引列作為條件時,不要在索引列上做計算,函數,或者型別轉換的操作,會導致優化器無法使用該索引。
例如假設在時間型別的列
published_at上新建一個索引:CREATE INDEX published_at_idx ON books (published_at);但下面查詢是無法使用
published_at上的索引的:SELECT * FROM books WHERE YEAR(published_at)=2022;可以改寫成下面查詢,避免在索引列上做函數計算後,即可使用
published_at上的索引:SELECT * FROM books WHERE published_at >= '2022-01-01' AND published_at < '2023-01-01';也可以使用表示式索引,例如對查詢條件中的
YEAR(published_at)建立一個表示式索引:CREATE INDEX published_year_idx ON books ((YEAR(published_at)));然後通過
SELECT * FROM books WHERE YEAR(published_at)=2022;查詢就能使用published_year_idx索引來加速查詢了。注意
表示式索引目前是 TiDB 的實驗特性,需要在 TiDB 組態檔中開啟表示式索引特性,詳情可以參考表示式索引檔案。
-
儘量使用覆蓋索引,即索引列包含查詢列,避免總是
SELECT *查詢所有列的語句。例如下面查詢只需掃描索引
title_published_at_idx資料即可獲取查詢列的資料:SELECT title, published_at FROM books WHERE title = 'database';但下面查詢語句雖然能用上組合索引
(title, published_at),但會多一個回表查詢非索引列資料的額外開銷,回表查詢是指根據索引資料中儲存的參照(一般是主鍵資訊),到表中查詢相應行的資料。SELECT * FROM books WHERE title = 'database'; -
查詢條件使用
!=,NOT IN時,無法使用索引。例如下面查詢無法使用任何索引:SELECT * FROM books WHERE title != 'database'; -
使用
LIKE時如果條件是以萬用字元%開頭,也無法使用索引。例如下面查詢無法使用任何索引:SELECT * FROM books WHERE title LIKE '%database'; -
當查詢條件有多個索引可供使用,但你知道用哪一個索引是最優的時,推薦使用優化器 Hint 來強制優化器使用這個索引,這樣可以避免優化器因為統計資訊不準或其他問題時,選錯索引。
例如下面查詢中,假設在列
id和列title上都各自有索引id_idx和title_idx,你知道id_idx的過濾性更好,就可以在 SQL 中使用USE INDEXHint 來強制優化器使用id_idx索引。SELECT * FROM t USE INDEX(id_idx) WHERE id = 1 and title = 'database'; -
查詢條件使用
IN表示式時,後面匹配的條件數量建議不要超過 300 個,否則執行效率會較差。