你能看到這個漢字麼「 」 ?關於Unicode的私人使用區(PUA) 和瀏覽器端顯示處理
如果你現在使用的是chrome檢視那麼你是看不到我標題中的漢字的,顯示為一個小方框,但是你使用edge檢視的話,這個字就能正常的顯示出來,不信你試試!
本故事源於我在做資料過程中遇到Unicode編碼中的私人使用區PUA編碼的漢字,然後匯入到產品端後他們說有些漢字是亂碼無法顯示,然後針對這個問題進行了排查。
首先在我標題中的漢字是如下漢字:

Unicode
其實我之前的文章都提到過很多編碼的問題,平時對編碼問題也比較瞭解,所以拿到這個問題首先我這邊資料處理用的utf-8,關於utf-8和unicode的關係就不贅述了。因為我這邊能正常在sqlserver裡面看到這個字,所以可以確定它不是一個亂碼,至少是一個符合規範的unicode編碼。然後我用工具檢視了這個字的編碼為 U+E188。檢視文字的unioncode編碼也可以使用線上工具https://symbl.cc/cn/
關於Unicode的分割區:
在Unicode中,碼位的總範圍為\x0到\x10FFFF,共1,114,112個碼位。2048個用於編碼代理(UTF-16),66個非字元碼位(例如BOM),137,468個預留給私人使用,最終剩餘974,530用於普通字元分配。
碼位的最大值為\x10FFFF,對應二進位制有21位,將216個值分為一組,Unicode總共可以分為17份,每一份稱之為平面(Plane),每一個平面有65,536(216)個碼位。
為什麼Unicode的最大值為\x10FFFF?因為對於UTF16編碼,雙位元組最多可編碼220個字元,單位元組可編碼216個字元,加起來共17個平面的字元數。
| 平面編號 | 碼位範圍 | 名稱簡寫 | 名稱描述 |
|---|---|---|---|
| Plane 0 | 0000–FFFF | BMP | 基礎多語言平面(Basic Multilingual Plane) |
| Plane 2 | 10000–1FFFF | SMP | 補充多語言平面(Supplementary Multilingual Plane) |
| Plane 2 | 20000–2FFFF | SIP | 補充表意語言平面(Supplementary Ideographic Plane) |
| Plane 3 | 30000–3FFFF | TIP | 第三表意語言平面(Tertiary Ideographic Plane) |
| Planes 4–13 | 40000–DFFFF | - (未分配) | - (未分配) |
| Plane 14 | E0000–EFFFF | SSP | 補充特殊用途平面(Supplementary Special-purpose Plane) |
| Planes 15–16 | F0000–10FFFF | SPUA-A/B | 補充私有使用區平面(Supplementary Private Use Area planes) |
通過這個平面表我們可以看到該字的編碼在BMP中,Unicode中,私人使用區(PUA)是一系列程式碼點,根據定義,Unicode 聯盟不會為其分配字元,定義了二個私人使用區域:一個位於基本多語言平面( U+E000-U+F8FF),一個位於並幾乎覆蓋平面 15 和 16(U+F0000-U+FFFFD ,U+ 100000-U+10FFFD )即SPUA。這些區域中的程式碼點不能被視為 Unicode 本身的標準化字元。
字元集和字型
Windows 允許 在雙位元組字元集中 (DBCS) 和 Unicode 中對非標準字元進行本地定義。 對於 DBCS,這些非標準字元稱為終端使用者定義字元, (EUDC) 。 Unicode 通過其專用區域 (PUA) 提供類似的功能。 應用程式通過使用關聯的 DBCS 或 Unicode 字元值來標識指定的字元。
可以分配的 DBCS 字元值取決於指定的字元集。 每個東亞 Windows 內碼錶 至少有一個保留值範圍用作 EUDC。 範圍由 EUDCCodeRange 登入檔項定義。 用於此目的的 Unicode 值始終來自 Unicode PUA,值 U+E000 到 U+F8FF,U+F0000 到 U+FFFFD,U+100000 到 U+10FFFD。
若要建立 EUDC 或 PUA 字元,使用者選擇指定範圍內的字元值,並將 字形 新增到與該字元值相對應的條目中的字型中。 使用者使用 EUDC 編輯器或使用從字型供應商處購買的字型包建立字形。 任何 DBCS 字型都可以包含 EUDC,任何 Unicode 字型都可以包含 PUA 字元。 如果字型僅包含 EUDC/PUA,則稱為「獨立」EUDC/PUA 字型。 如果字型包含標準字元和 EUDC,則為「整合」EUDC/PUA 字型。
系統預設的 EUDC/PUA 字型是作業系統自動與所有 DBCS 和 Unicode 字型關聯的字型,但具有顯式關聯的 EUDC/PUA 字型的字型除外。 應用程式通過在 EUDC 登入檔項下設定 SystemDefaultEUDCFont 名稱的值來設定系統預設 的 EUDC /PUA 字型。 同樣,應用程式可以通過在 EUDC 鍵下指定字型名稱和關聯的字型檔案,將單獨的 EUDC/PUA 字型與相應的字型相關聯。 作業系統始終首先嚐試查詢當前所選字型中的 EUDC/PUA。 如果未找到該字型,則作業系統將在關聯的 EUDC/PUA 字型中查詢字元(如果已為當前所選字型定義了一個字型)。 如果仍然找不到字元,作業系統將在系統預設的 EUDC/PUA 字型中查詢它。
TrueType 字型可以安裝為 .ttf 檔案或 .tte 檔案。 由於作業系統隱藏 .tte 檔案,因此應用程式無法使用 GDI API 函數列舉或以其他方式檢查已安裝的字型。 在許多作業系統上,系統預設的 EUDC/PUA 字型和單獨的 EUDC/PUA 字型作為 .tte 檔案安裝。 EUDC 編輯器和控制面板等應用程式必須使用登入檔項來新增、修改和刪除此類字型
上面描述摘自微軟檔案https://learn.microsoft.com/zh-cn/windows/win32/intl/character-sets-and-fonts
EUDC 登入檔項包含一個或多個子項,這些子項包含的值定義與給定內碼錶 的終端使用者定義字元關聯的字型 (EUDC) 。 它具有以下登入檔位置:
HKEY_CURRENT_USER\EUDC
EUDCCodeRange 登入檔項 (EUDC) 程式碼範圍 (字元集) 定義終端使用者定義字元。 它僅由建立 EUDC 的工具使用,對歐盟發展委員會使用者沒有直接關係。

顯示
所以為啥微軟系的應用能夠顯示這個字呢,上面字元集和字型描述可以看到自己可以定義EUDC,在微軟字元對映表中有一類叫做「專用字元」,而這個專用字元就是我們自己可以定義的PUA區域。
我們找到系統的字元對映表:
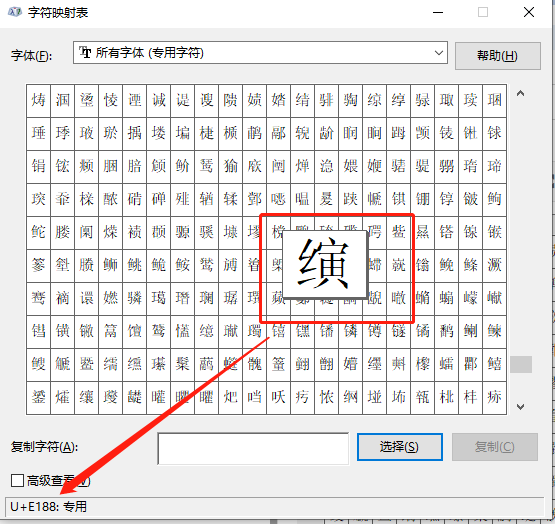
可以看到這個字剛好對應U+E188。
我們找到登入檔,並檢視上面表格中codePage中對應的936為中文簡體,看到字型檔案位置。
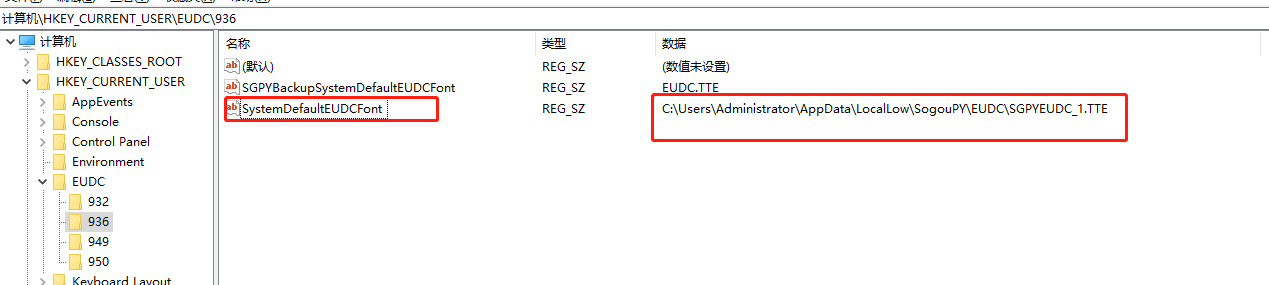
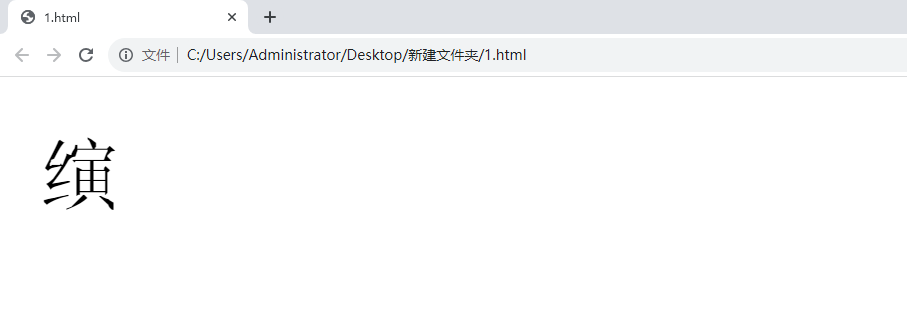
找到對應的字型檔案,並引入到html中,我們就能在任何瀏覽器看到這個字了。

簡單的寫一個html:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<style>
@font-face {
font-family: "SGPYEUDC";
src: url("SGPYEUDC_1.TTE") format("truetype");
}
</style>
</head>
<body style="font-family:Microsoft YaHei,SGPYEUDC">
<p></p>
</body>
</html>
作者:孫泉
出處:https://www.cnblogs.com/SunSpring/p/17662967.html
如果你喜歡文章歡迎點選推薦,你的鼓勵對我很有用!
本文版權歸作者所有,轉載需在文章頁面明顯位置給出原文連結。