機器學習從入門到放棄:我們究竟是怎麼教會機器自主學習的?
一、前言簡介
我相信你一定聽過一個說法,那就是機器學習模型可以被視為函數的一種表示方式。它們通常是由多個函陣列成的,這些函數通過引數連線在一起。我們讓機器從資料中提取模式、規律和關聯,然後使用這些資訊來做出預測、分類、聚類等任務。所以從本質上來說,在機器學習中我們其實就是要找一個超級函數,我們已知的資料就是輸入的引數,它通過演演算法和統計方法使計算機能夠從大量的資料中學習,通過逼近擬合真實的超級函數,來根據學習到的知識做出決策或執行任務。
以 classification(分類)任務來說,機器學習就是通過一堆訓練集,然後根據 loss function 來查詢到最擬合逼近真實函數的求解函數 func(),從而實現分類的輸出。
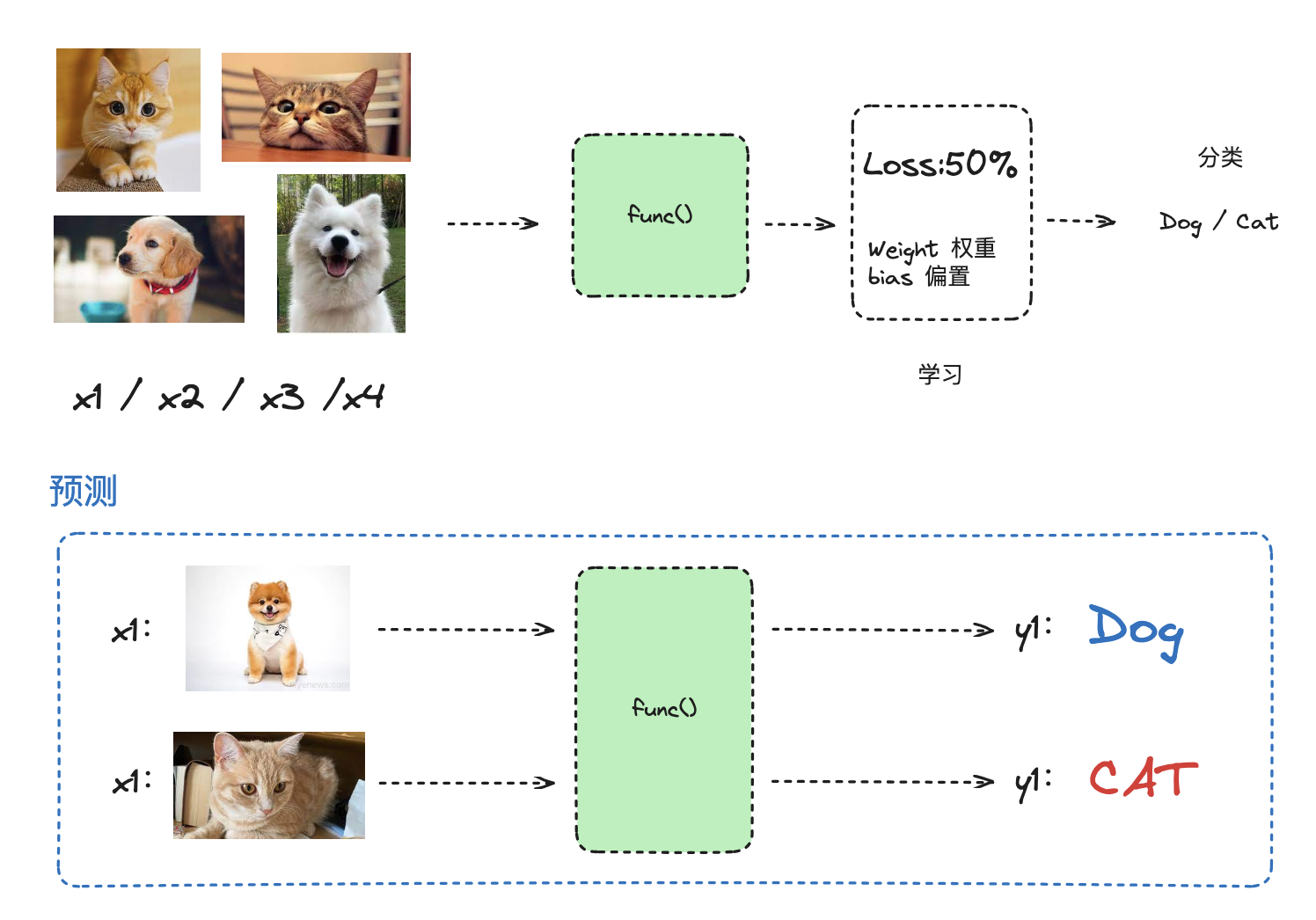
所以說嘛,機器學習也沒有那麼難~(bushi,你可以秒懂它。
二、Logitic Regression(邏輯迴歸)和 Neuron Network(神經元網路)
我們還是以上面的分類問題類進行舉例,在分類方法中,需要了解邏輯迴歸的概念。邏輯迴歸(Logistic Regression)雖然名字中帶有"迴歸"一詞,但實際上它是一種用於分類問題的統計學習方法,而不是迴歸問題。邏輯迴歸用於預測二分類問題,即將輸入資料分為兩個類別中的一個。
邏輯迴歸通過將線性函數的輸出對映到一個介於0和1之間的概率值,來表示輸入資料屬於某個類別的概率。這個對映使用了邏輯函數(也稱為sigmoid函數),它具有S形的曲線,這使得模型的輸出在0和1之間變化。邏輯迴歸的公式如下:
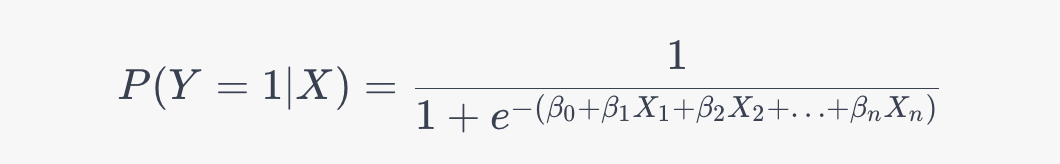
其中,P(Y=1|X) 是給定輸入特徵 X 條件下屬於類別 1 的概率,beta_0, beta_1, beta_n 是模型的引數,X_1, X_2, X_n 是輸入特徵。模型的目標是通過調整引數,使得預測的概率儘可能接近實際觀測值。在訓練過程中,邏輯迴歸使用最大似然估計等方法來找到最佳的引數值,以使模型的預測結果與實際觀測值之間的差異最小化。一旦訓練好了邏輯迴歸模型,它可以用於預測新的資料點所屬的類別。
那這個分類模型函數中怎麼求解引數 beta_0, beta_1....beta_n 的呢?這裡其實就是模型訓練方法的求解,一般來說針對邏輯迴歸問題都是使用最大似然估計,來進行擬合確定曲線。
舉個