微服務15:微服務治理之超時
2023-08-28 15:13:26
★微服務系列
微服務1:微服務及其演進史
微服務2:微服務全景架構
微服務3:微服務拆分策略
微服務4:服務註冊與發現
微服務5:服務註冊與發現(實踐篇)
微服務6:通訊之閘道器
微服務7:通訊之RPC
微服務8:通訊之RPC實踐篇(附原始碼)
微服務9:服務治理來保證高可用
微服務10:系統服務熔斷、限流
微服務11:熔斷、降級的Hystrix實現(附原始碼)
微服務12:流量策略
微服務13:雲基礎場景下流量策略實現原理
微服務14:微服務治理之重試
1 介紹
在複雜的網際網路場景中,不可避免的會因為一些內在或者外在的因素,導致出現請求超時的情況。
而典型的業務超時場景主要有如下:
- 網路延遲或者抖動或者丟包,從而導致響應時間變長。
- 容器甚至雲主機資源瓶頸情況:如CPU使用率過高、記憶體使用是否正常、磁碟IO壓力情況、網路時延情況等資源使用情況異常,也可能導致響應時間變長。
- 負載均衡性問題:多範例下分配的流量不均衡,目前看雲基礎場景,這個情況不多見。
- 突發洪峰請求:大部分對內的業務基本不存在非預期的流量,突發洪峰請求主要還是程式的呼叫不合理或者程式bug(記憶體洩露、迴圈呼叫、快取擊穿等)。

單個Pod範例,長耗時容易造成佇列堆積,對資源損耗很大,快速的釋放或者排程開是一個比較好的辦法,是一種普遍可接受的降級方案,否則超時阻塞會導致服務長時間不可用。
而且這種影響是水平擴散的,同服務上的其他功能也會被爭搶資源。
2 超時的常見治理手段
2.1 採用超時重試實現故障恢復
超時重試:對服務的核心介面進行細粒度設定,具體介面超時時間應該 ≥ TP999(即滿足999‰的網路請求所需要的最低耗時)的耗時。
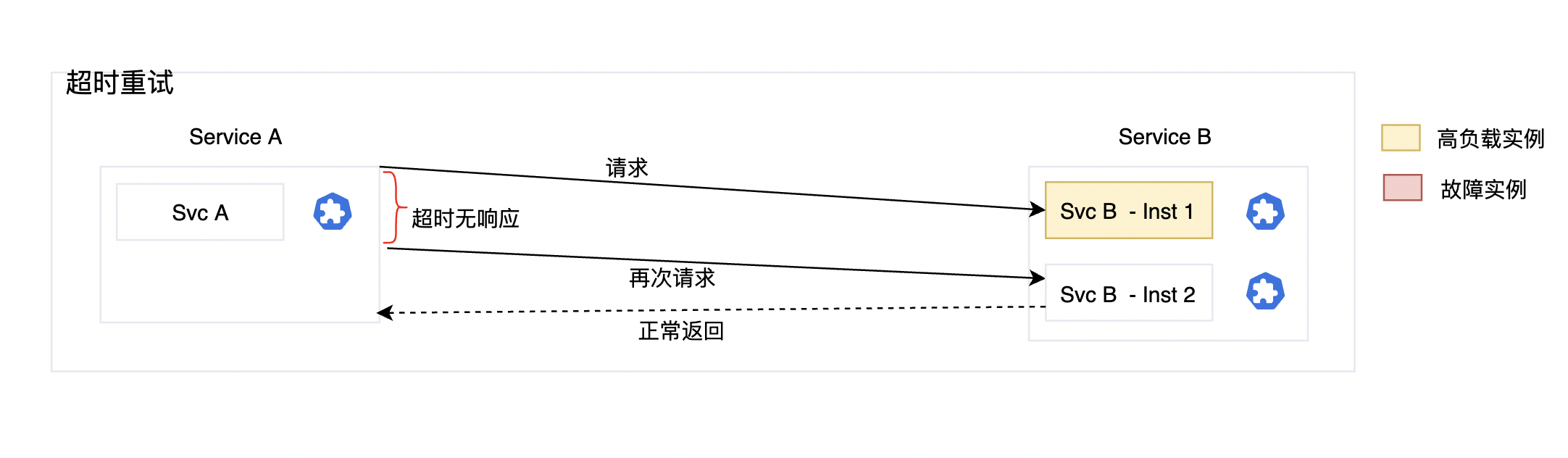
執行過程說明
- 這邊以範例服務 Svc-A 向 Svc-B 發起存取為例子。
- 第1次執行,因為SvcB-Inst1高負載,所以在規定的時間內(比如2s)沒有得到響應。
- 當請求方(Svc A)感知到超時無響應的時候,再次發起請求。
- 因為負載均衡策略,被請求方發生了變動,說明排程到新的範例(Svc-B-Instance1 到 Svc-B-Instance2)。
- 第二次請求返回正常的 200 。
2.1 採用超時斷連實現系統保護
超時斷連:通過指定超時時間對請求進行斷連,達到降級的目的。避免長時間佇列阻塞,導致雪崩沿呼叫向上傳遞,造成整個鏈路崩潰。
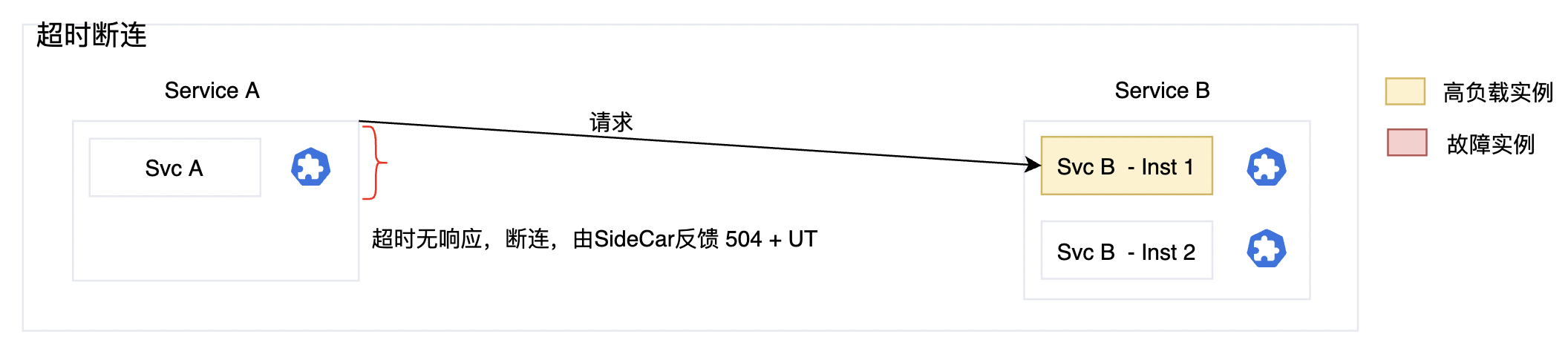
執行過程說明
- 這邊以範例服務 Svc-A 向 Svc-B 發起存取為例子。
- 第1次執行,因為SvcB-Inst1高負載,所以在規定的時間內(比如2s)沒有得到響應。
- 當請求方(Svc A)感知到超時無響應的時候,直接進行斷連,不再發起請求。
- 如果使用Service Mesh 做微服務治理,則會由SideCar進行斷連,並Response給請求方
- 504 代表 504 Gateway Time-out,flag = UT 代表 Upstream request timeout in addition to 504 response code。
3 策略實現(Service Mesh方案)
註釋比較清晰了,這邊就不解釋了。
# VirtualService
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: xx-svc-b-vs
namespace: kube-ns-xx
spec:
hosts:
- svc_b.google.com # 治理髮往 svc-b 服務的流量
http:
- match: # 匹配條件的流量進行治理
- uri:
prefix: /v1.0/userinfo # 匹配路由字首為 /v1.0/userinfo 的,比如 /v1.0/userinfo/1305015
retries:
attempts: 1 # 重試一次
perTryTimeout: 1s # 首次呼叫和每次重試的超時時間
timeout: 2.5s # 請求整體超時時間為2.5s,無論重試多少次,超過該時間就斷開。
route:
- destination:
host: svc_b.google.com
weight: 100
- route: # 其他未匹配的流量預設不治理,直接流轉
- destination:
host: svc_c.google.com
weight: 100
4 總結
雲基礎場景下的治理手段各種各樣,這邊講解了初級版的超時重試和超時熔斷方案,讓使用者有一個更優良的使體驗。
同時在系統大面積崩潰的時候,進行系統保護,不至於全面崩塌。
在後續的章節我們逐一瞭解下故障注入、熔斷限流、異常驅逐等高階用法。

架構與思維·公眾號:撰稿者為bat、位元組的幾位高階研發/架構。不做廣告、不賣課、不要打賞,只分享優質技術
★ 加公眾號獲取學習資料和麵試集錦
碼字不易,歡迎關注,歡迎轉載
作者:翁智華
本文采用「CC BY 4.0」知識共用協定進行許可,轉載請註明作者及出處。