聯邦學習中的安全多方計算
聯邦學習中的安全多方計算
Secure Multi-party Computation in Federated Learning
什麼是安全多方計算
安全多方計算就是許多參與方需要共同工作完成一個計算任務或者執行一個數學函數,每個參與方針對這個執行構建自己的資料或份額,但不想洩露自己的資料給其他參與方。
在安全多方計算中的定義包括以下幾個方面:
- 一組有私有輸入的參與者,對他們的輸入執行一些聯合功能。
- 參與者希望保留一些安全屬性,例如,選舉協定中的隱私性和正確性。
- 安全性必須在面對某些參與者或外部各方的敵對行為時保持不變。
研究人員通常利用真實/理想的模型正規化來探索安全協定的安全性。
- 在理想的模型中,安全性是絕對的,例如伺服器是絕對可靠和可信的,並且對伺服器進行成功攻擊的概率為零。
- 在真實模型中,我們也可以通過各種方式來實現理想模型的安全性。任何可以從真實模型中學習或獲得的資訊敵手也可以從理想模型中學習或獲得。換句話說,安全性在理想模型和真實模型之間是不可區分的。
舉個例子:在理想模型中,假設有一個可信伺服器能夠聚合各參與方並且產生正確預期輸出;在真實模型中,不存在可信伺服器,參與方可以通過對等方式交換輸入和資訊來達到這種形式。
安全多方計算中有三個安全模型:
- 半誠實敵手模型:被腐化的參與方忠實執行既定協定;而敵手儘可能收集所有資訊以獲得額外的機密資訊
- 惡意敵手模型(強安全模型):腐化參與方可能在任何時候根據敵手指示違背協定。
- 隱蔽對手模型:介於上述兩極端模型之間
安全多方計算的基礎元件
不經意傳輸(茫然傳輸,Oblivious Transfer,OT)
不經意傳輸(OT):傳送者S想傳送n個訊息中的一個給接受者R,目標是S不知道哪個訊息被R接收,而且R沒有獲得S傳送的其他n-1個訊息中的任何資訊。
一個標準的二選一函數被描述為\(F_{ot}\)如下:
- 輸入:
- 傳送方\(S\)輸入兩個訊息\(m_1\), \(m_2\).
- 接收方輸入一個隨機位元\(\sigma \in [0,1]\).
- 輸出:
- 傳送方\(S\)沒有輸出.
- 接收方\(R\)獲得\(m_\sigma\),並且沒有獲得關於\(m_{1-\sigma}\)的任何知識.
實現OT協定的方法有很多,例如RAS或基於離散對數問題的方法。
混淆電路
雙方將共同共同作業實現:一方將設計一個邏輯電路,另一方將檢查並使用該邏輯電路。
祕密共用
祕密共用(Secret Sharing, SS)是密碼學中的一個重要元素。對稱或非對稱加密更側重於兩方之間的祕密共用。然而某些時候,例如在聯邦學習中則需要在多個參與者之間共用一個祕密,此時就需要祕密共用。
一般來說,有三種型別的祕密共用協定:算術祕密共用、Shamir祕密共用和Goldreich-Micali-Wigderson(GMW)共用。算術祕密共用是利用數論的特徵在兩方之間共用一個祕密,而GMW共用主要使用XOR來隱藏私有值,而Shamir祕密共用可能是實踐中最流行的祕密分享的原語。
在Shamir祕密共用中,一個祕密\(s\)將被分割成\(n\)個份額,這樣任何\(t\)個份額都可以用來重建祕密\(s\);然而,任何小於\(t\)的份額都不能獲得關於\(s\)的資訊。
\((t,n)\)門限Shamir祕密共用方案:

由於每個參與者\(P_i\)都知道一對\((x_i,y_i)\),因此,當我們有\(t\)對\((x_i,y_i)\)時就可以獲得祕密值\(K\)。然而,對於任意\(t-1\)對\((x_i,y_i)\),我們則不能確定\(K\)(給定一個很大的素數\(p\)有很多可能性)。
另一種流行的祕密共用方法是使用拉格朗日插值法。我們用一個簡單的例子來說明這項技術。假設\(t=3\),那麼我們找到一個階數為3的多項式如下:
,其中\(d=f(0)\)是祕密值。
分配者可以在\(X\)軸上隨機選擇\(n\)個點,如\(x_1,x_2,...,x_n\)。根據\(a\)、\(b\)、\(c\)、\(d\)的知識,分配者可以輕鬆獲得\(n\)對資料\((x_1,f(x_1)),(x_2,f(x_2)),...,(x_n,f(x_n))\)。然後他將把\(n\)對祕密份額分配給\(n\)個祕密持有人。
兩種方法的主要區別:
- Shamir祕密共用是\(x_1\)到\(x_n\)是隨機選取且公開的,之後隨機選取\(t-1\)個多項式係數,求得y值進行分配,祕密份額是y值。需要分配方分發兩次,一次公開的,一次祕密份額。
- 拉格朗日插值法是先找一個多項式,再隨機選\(n\)個點,這樣每個點(即\(x\)值和\(y\)值)共同作為祕密份額,\(x_1\)到\(x_n\)不公開。分配方只需要分發一次。
同態加密
目前同態加密的效能有很大挑戰,阻礙了實踐中的部署。
聯邦學習中的安全多方計算
成對掩蔽技術(pairwise masking)資料聚合
假設我們有兩個使用者端\(u\)和\(v\),他們分別想將\(x_u\)和\(x_v\)上傳到聯邦學習伺服器。為了不向伺服器洩露他們的原始祕密值,\(u\)和\(v\)將協定產生一個虛擬資料\(s_{uv}\),其中一個使用者端會將虛擬資料新增到真實資料中來輸出,例如,\(y_u = x_u + s_{uv}\),而另一個使用者端將輸出\(y_v = x_v − s_{uv}\)。在伺服器端,誠實但好奇的伺服器通過將接收到的\(y_u\)和\(y_v\)相加,即可得到正確的聚合結果\(x_u + x_v\),與此同時伺服器無法從接收到的訊息中得到\(x_u\)和\(x_v\)。
對掩蔽方法進一步推廣:假設有多個使用者端參與該任務,使用使用者端集合\(\mathcal{U}\)表示。我們將對集合中的每一對使用者端\((u,v)\)生成一個共用的虛擬向量\(s_{uv}\)。此外我們還需要一個規則來決定誰將新增或減去共用的虛擬向量。一種解決方案是,我們隨機地給每個使用者端分配一個順序,我們得到一個有序的使用者列表\(1,2,...,|\mathcal{U}|\)。對於列表中的使用者\(i\),他將新增使用者\(1,2,...,i−1\)的共用虛擬向量,並減去與使用者\(i + 1,i + 2,...,|\mathcal{U}|\)共用的虛擬向量。換句話說,使用者\(u\)的掩碼輸出是:
我們注意到,上述掩蔽的正項或負項的數量是動態的,並取決於使用者\(u\)在有序列表中的位置(每個不同位置的使用者端正項和負項的數量都是不同的,但最後總和一定是互相抵消的,因為每個加減是成對出現的,例如使用者端1要減掉其與使用者端2共用的虛擬向量,使用者端2要加上這個虛擬向量)。在伺服器端,聚合的方式如下:
這裡貼一下我理解的成對掩碼加減的示意圖,以便於理解:
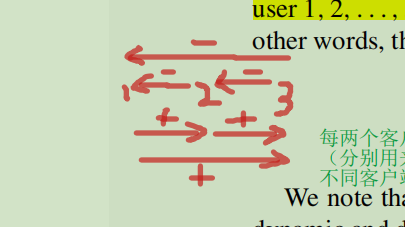
此外注意:這裡的每對使用者端之間生成的虛擬向量應該是不儲存的,直接加在真實值上面,因此如果發生掉線情況,就會出問題。
由於掩碼是成對出現的,所以如果出現參與方掉線的情況就聚合之後的總和會出現問題,因此最重要的就是解決參與方掉線的問題。
聯邦學習中的祕密共用
根據前文,可以使用祕密共用來解決使用者端掉線問題。
在系統啟動階段,一個給定使用者\(u\)將利用一個祕密共用方案來分發他的每個祕密值的\(t\)份額共用(\(u\)與其他使用者之間有一個祕密值\(s_{uv},u \neq v\))。在掩蔽方案中,只有當所有預期的參與方都成功地上傳了其所掩蔽的資料時,才能正確地完成聚合。否則,僅有部分參與方參與求和就遠遠不能得到正確的答案,因為一個缺失的參與者可能會導致很大的差異。
也就是說如果有一個使用者端\(u\)掉線,那麼與之相關的有\(n-1\)個祕密需要被恢復。而針對於使用者\(u\)相關的其中一個祕密\(s_{u,v}\)來說,伺服器至少需要從活躍參與方收集至少\(t\)個份額。即伺服器總共需要手機\(t×(n-1)\)個份額才能完整復原所有與\(u\)有關的祕密值,從而使最終求和正確。這樣開銷顯然太大了。
這裡我本來有個疑問:此處為什麼不用與他結對的使用者端持有的值直接恢復?
我思考了一下之後覺得與它結對的使用者端並不持有這個虛擬向量(我感覺這個虛擬向量就是個一次性的亂數),虛擬向量使用完之後兩方都不儲存。兩方只是在生成之後根據這個虛擬向量值生成了祕密共用份額以備恢復它,但原始的虛擬向量值就銷燬了,加完或減完只保留\(y_u\)值,不保留\(x_u\)值和\(s_{u,v}\)。
此外有一種潛在的攻擊是伺服器可能聲稱使用者\(u\)掉線了(其實沒掉線),從而獲得使用者端\(u\)的與其他使用者端的所有\(n-1\)個祕密值(虛擬向量)。而攻擊者可以通過這\(n-1\)個虛擬向量以及各個使用者端上傳的內容求得各個使用者端持有的真實值(需要上傳的真實值):
為了應對這種攻擊,提出了一種雙掩蔽方法(待後續學習)。
為了處理掉線帶來的昂貴代價,Zheng等人提出了一個輕量級的加密解決方案:

思路類似於DH金鑰交換協定,每個使用者端生成一個私鑰和一個公鑰,每兩方通過金鑰交換得到一個公共金鑰,這個公共金鑰就作為虛擬向量,這樣子後續如果有一方掉線,而另一方知道這個公共金鑰,可以直接恢復。