迴圈神經網路RNN完全解析:從基礎理論到PyTorch實戰
在本文中,我們深入探討了迴圈神經網路(RNN)及其高階變體,包括長短時記憶網路(LSTM)、門控迴圈單元(GRU)和雙向迴圈神經網路(Bi-RNN)。文章詳細介紹了RNN的基本概念、工作原理和應用場景,同時提供了使用PyTorch構建、訓練和評估RNN模型的完整程式碼指南。
作者 TechLead,擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
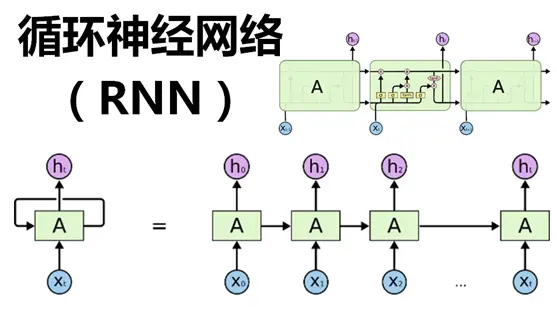
一、迴圈神經網路全解
1.1 什麼是迴圈神經網路
迴圈神經網路(Recurrent Neural Network, RNN)是一類具有內部環狀連線的人工神經網路,用於處理序列資料。其最大特點是網路中存在著環,使得資訊能在網路中進行迴圈,實現對序列資訊的儲存和處理。
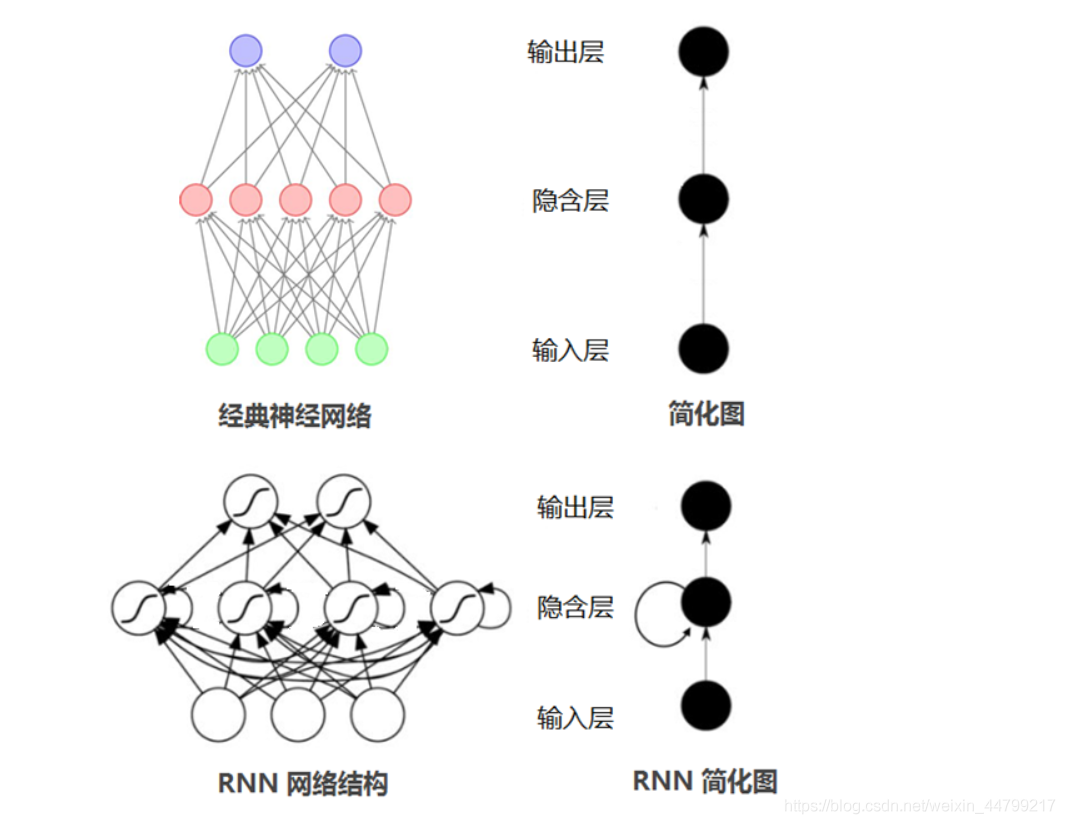
網路結構
RNN的基本結構如下:
# 一個簡單的RNN結構範例
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
def forward(self, x):
out, _ = self.rnn(x)
return out
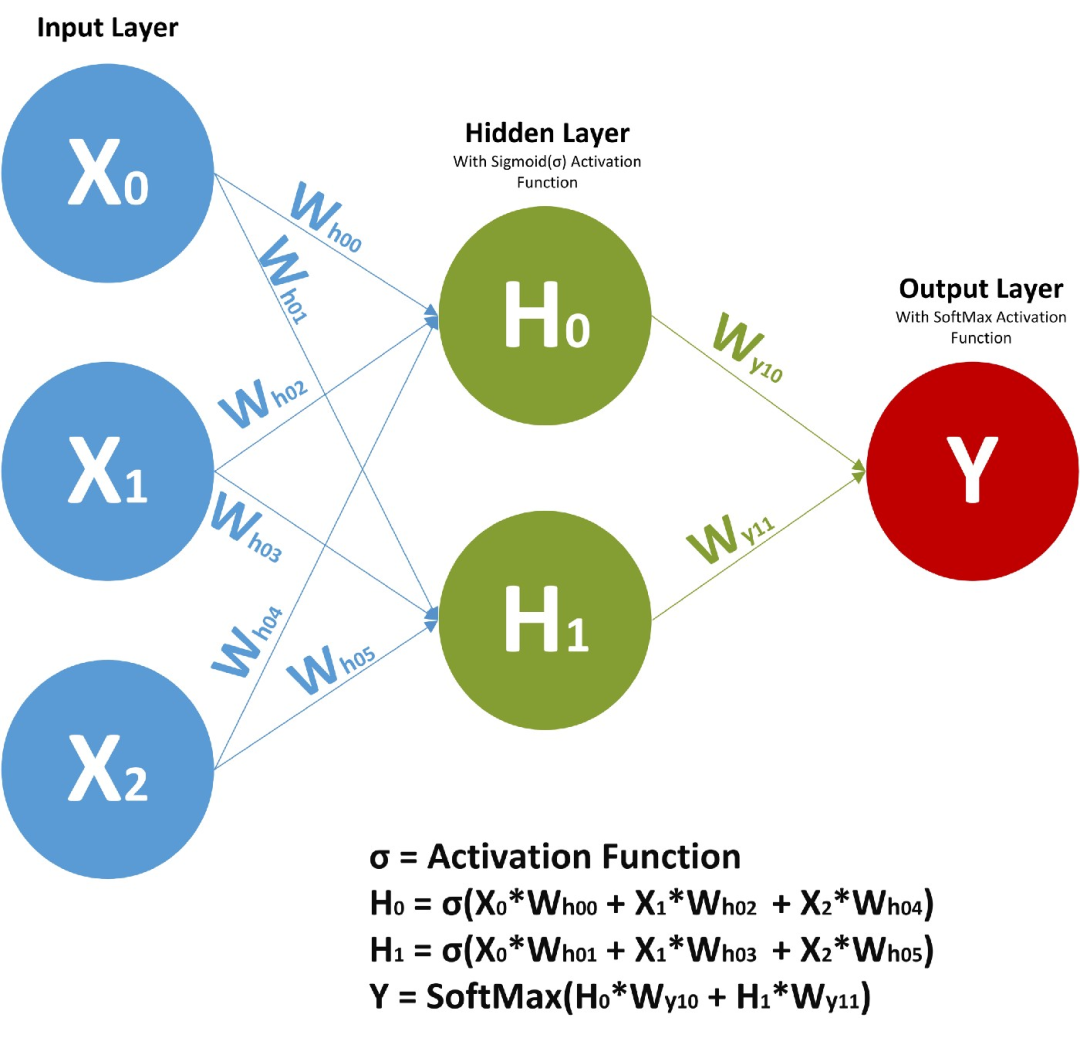
工作原理
-
輸入層:RNN能夠接受一個輸入序列(例如文字、股票價格、語音訊號等)並將其傳遞到隱藏層。
-
隱藏層:隱藏層之間存在迴圈連線,使得網路能夠維護一個「記憶」狀態,這一狀態包含了過去的資訊。這使得RNN能夠理解序列中的上下文資訊。
-
輸出層:RNN可以有一個或多個輸出,例如在序列生成任務中,每個時間步都會有一個輸出。
數學模型
RNN的工作原理可以通過以下數學方程表示:
- 輸入到隱藏層的轉換:[ h_t = \tanh(W_{ih} \cdot x_t + b_{ih} + W_{hh} \cdot h_{t-1} + b_{hh}) ]
- 隱藏層到輸出層的轉換:[ y_t = W_{ho} \cdot h_t + b_o ]
其中,( h_t ) 表示在時間 ( t ) 的隱藏層狀態,( x_t ) 表示在時間 ( t ) 的輸入,( y_t ) 表示在時間 ( t ) 的輸出。
RNN的優缺點
優點:
- 能夠處理不同長度的序列資料。
- 能夠捕捉序列中的時間依賴關係。
缺點:
- 對長序列的記憶能力較弱,可能出現梯度消失或梯度爆炸問題。
- 訓練可能相對複雜和時間消耗大。
總結
迴圈神經網路是一種強大的模型,特別適合於處理具有時間依賴性的序列資料。然而,標準RNN通常難以學習長序列中的依賴關係,因此有了更多複雜的變體如LSTM和GRU,來解決這些問題。不過,RNN的基本理念和結構仍然是深度學習中序列處理的核心組成部分。
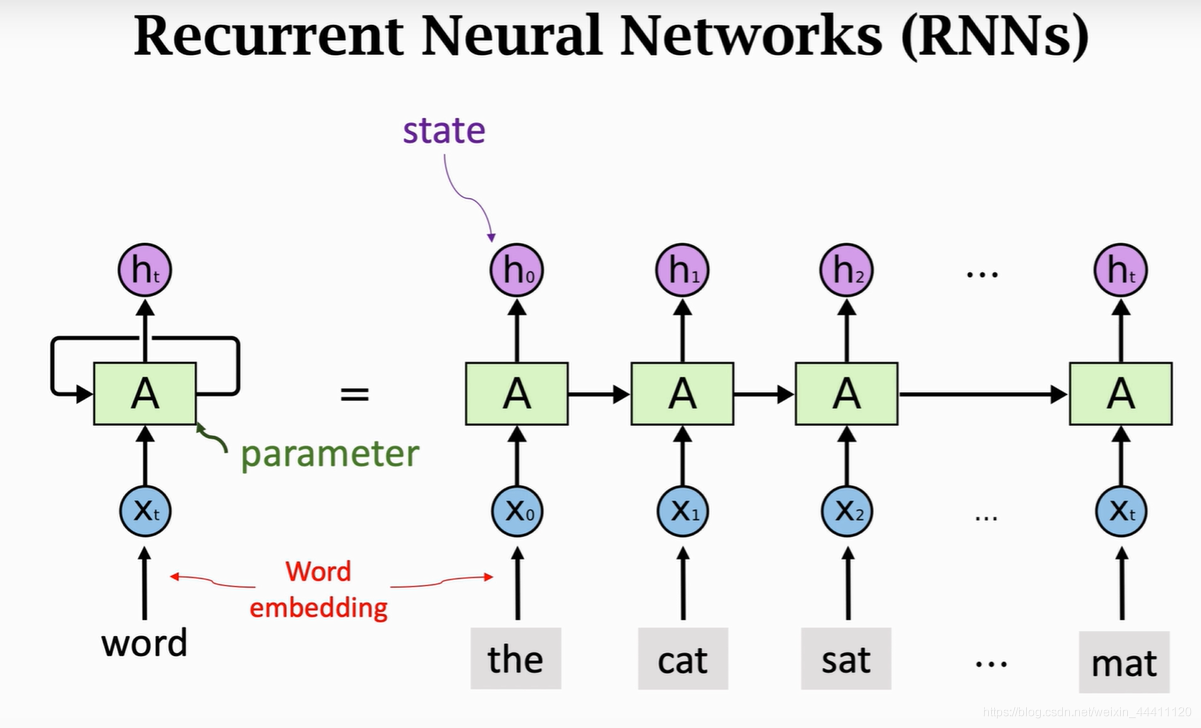
1.2 迴圈神經網路的工作原理
迴圈神經網路(RNN)的工作原理是通過網路中的環狀連線捕獲序列中的時間依賴關係。下面我們將詳細解釋其工作機制。
RNN的時間展開
RNN的一個重要特點是可以通過時間展開來理解。這意味著,雖然網路結構在每個時間步看起來相同,但我們可以將其展開為一系列的網路層,每一層對應於序列中的一個特定時間步。
數學表述
RNN可以通過下列數學方程描述:
- 隱藏層狀態:[ h_t = \sigma(W_{hh} \cdot h_{t-1} + W_{ih} \cdot x_t + b_h) ]
- 輸出層狀態:[ y_t = W_{ho} \cdot h_t + b_o ]
其中,( \sigma ) 是一個啟用函數(如tanh或ReLU),( h_t ) 是當前隱藏狀態,( x_t ) 是當前輸入,( y_t ) 是當前輸出。權重和偏置分別由( W_{hh}, W_{ih}, W_{ho} ) 和 ( b_h, b_o ) 表示。
資訊流動
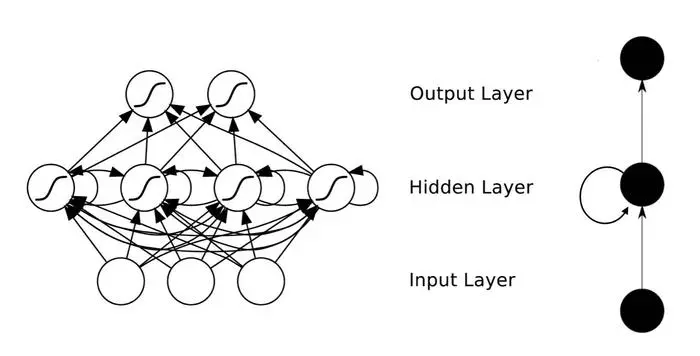
-
輸入到隱藏:每個時間步,RNN從輸入層接收一個新的輸入,並將其與之前的隱藏狀態結合起來,以生成新的隱藏狀態。
-
隱藏到隱藏:隱藏層之間的迴圈連線使得資訊可以在時間步之間傳播,從而捕捉序列中的依賴關係。
-
隱藏到輸出:每個時間步的隱藏狀態都會傳遞到輸出層,以生成對應的輸出。
實現範例
# RNN的PyTorch實現
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, h_0):
out, h_n = self.rnn(x, h_0) # 運用RNN層
out = self.fc(out) # 運用全連線層
return out
梯度問題:梯度消失和爆炸
由於RNN的迴圈結構,在訓練中可能會出現梯度消失或梯度爆炸的問題。長序列可能會導致訓練過程中的梯度變得非常小(消失)或非常大(爆炸),從而影響模型的學習效率。
總結
迴圈神經網路的工作原理強調了序列資料的時間依賴關係。通過時間展開和資訊的連續流動,RNN能夠理解和處理序列中的複雜模式。不過,RNN的訓練可能受到梯度消失或爆炸的挑戰,需要採用適當的技術和結構來克服。
1.3 迴圈神經網路的應用場景
迴圈神經網路(RNN)因其在捕獲序列資料中的時序依賴性方面的優勢,在許多應用場景中都得到了廣泛的使用。以下是一些主要應用領域的概述:
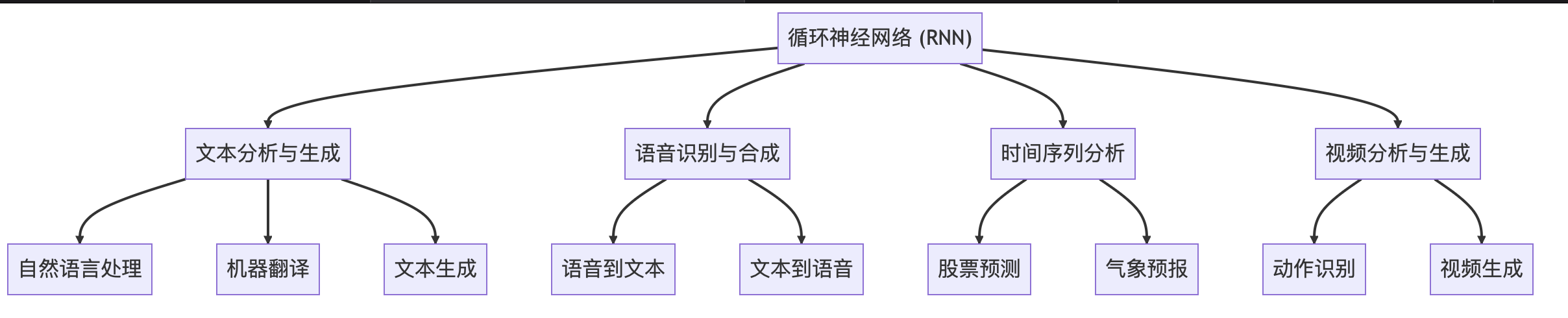
文字分析與生成
1.3.1 自然語言處理
RNN可用於詞性標註、命名實體識別、句子解析等任務。通過捕獲文字中的上下文關係,RNN能夠理解並處理語言的複雜結構。
1.3.2 機器翻譯
RNN能夠理解和生成不同語言的句子結構,使其在機器翻譯方面特別有效。
1.3.3 文字生成
利用RNN進行文字生成,如生成詩歌、故事等,實現了機器的創造性寫作。
語音識別與合成
1.3.4 語音到文字
RNN可以用於將語音訊號轉換為文字,即語音識別(Speech to Text),理解聲音中的時序依賴關係。
1.3.5 文字到語音
RNN也用於文字到語音(Text to Speech)的轉換,生成流暢自然的語音。
時間序列分析
1.3.6 股票預測
通過分析歷史股票價格和交易量等資料的時間序列,RNN可以用於預測未來的股票走勢。
1.3.7 氣象預報
RNN通過分析氣象資料的時間序列,可以預測未來的天氣情況。
視訊分析與生成
1.3.8 動作識別
RNN能夠分析視訊中的時序資訊,用於識別人物動作和行為模式等。
1.3.9 視訊生成
RNN還可以用於視訊內容的生成,如生成具有連續邏輯的動畫片段。
總結
RNN的這些應用場景共同反映了其在理解和處理具有時序依賴關係的序列資料方面的強大能力。無論是自然語言處理、語音識別、時間序列分析,還是視訊內容分析,RNN都已成為實現這些任務的重要工具。其在捕獲長期依賴、理解複雜結構和生成連續序列方面的特性,使其成為深度學習中處理序列問題的首選方法。
迴圈神經網路的主要變體
2.1 長短時記憶網路(LSTM)
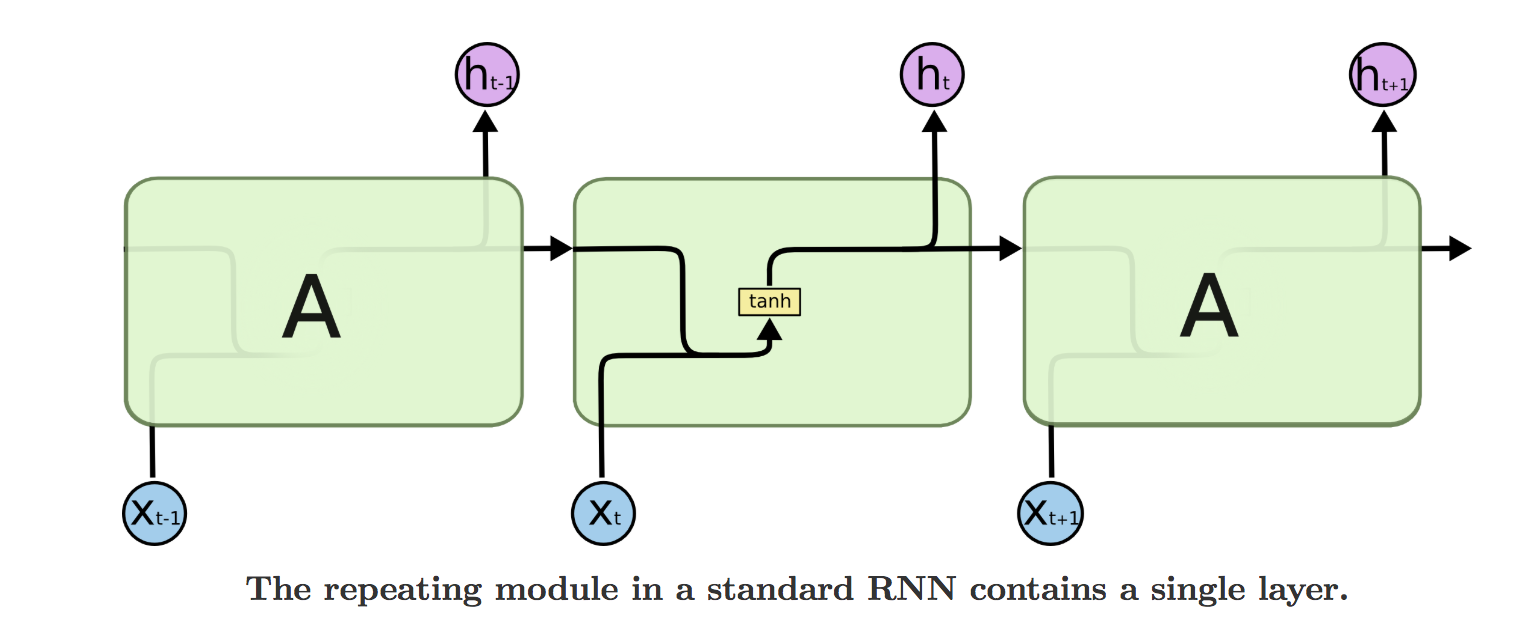

長短時記憶網路(Long Short-Term Memory,LSTM)是一種特殊的RNN結構,由Hochreiter和Schmidhuber在1997年提出。LSTM旨在解決傳統RNN在訓練長序列時遇到的梯度消失問題。
LSTM的結構
LSTM的核心是其複雜的記憶單元結構,包括以下元件:
2.1.1 遺忘門
控制哪些資訊從單元狀態中被丟棄。
2.1.2 輸入門
控制新資訊的哪些部分要儲存在單元狀態中。
2.1.3 單元狀態
儲存過去的資訊,通過遺忘門和輸入門的調節進行更新。
2.1.4 輸出門
控制單元狀態的哪些部分要讀取和輸出。
數學表述
LSTM的工作過程可以通過以下方程表示:
-
遺忘門:
[ f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ] -
輸入門:
[ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) ] -
候選單元狀態:
[ \tilde{C}t = \text{tanh}(W_C \cdot [h, x_t] + b_C) ] -
更新單元狀態:
[ C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t ] -
輸出門:
[ o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ] -
隱藏狀態:
[ h_t = o_t \cdot \text{tanh}(C_t) ]
其中,( \sigma ) 表示sigmoid啟用函數。
LSTM的實現範例
# LSTM的PyTorch實現
import torch.nn as nn
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTM, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, (h_0, c_0)):
out, (h_n, c_n) = self.lstm(x, (h_0, c_0)) # 運用LSTM層
out = self.fc(out) # 運用全連線層
return out
LSTM的優勢和挑戰
LSTM通過引入複雜的門控機制解決了梯度消失的問題,使其能夠捕獲更長的序列依賴關係。然而,LSTM的複雜結構也使其在計算和引數方面相對昂貴。
總結
長短時記憶網路(LSTM)是迴圈神經網路的重要擴充套件,具有捕獲長序列依賴關係的能力。通過引入門控機制,LSTM可以精細控制資訊的流動,既能記住長期的依賴資訊,也能忘記無關的細節。這些特性使LSTM在許多序列處理任務中都得到了廣泛的應用。
2.2 門控迴圈單元(GRU)
門控迴圈單元(Gated Recurrent Unit,GRU)是一種特殊的RNN結構,由Cho等人於2014年提出。GRU與LSTM相似,但其結構更簡單,計算效率更高。
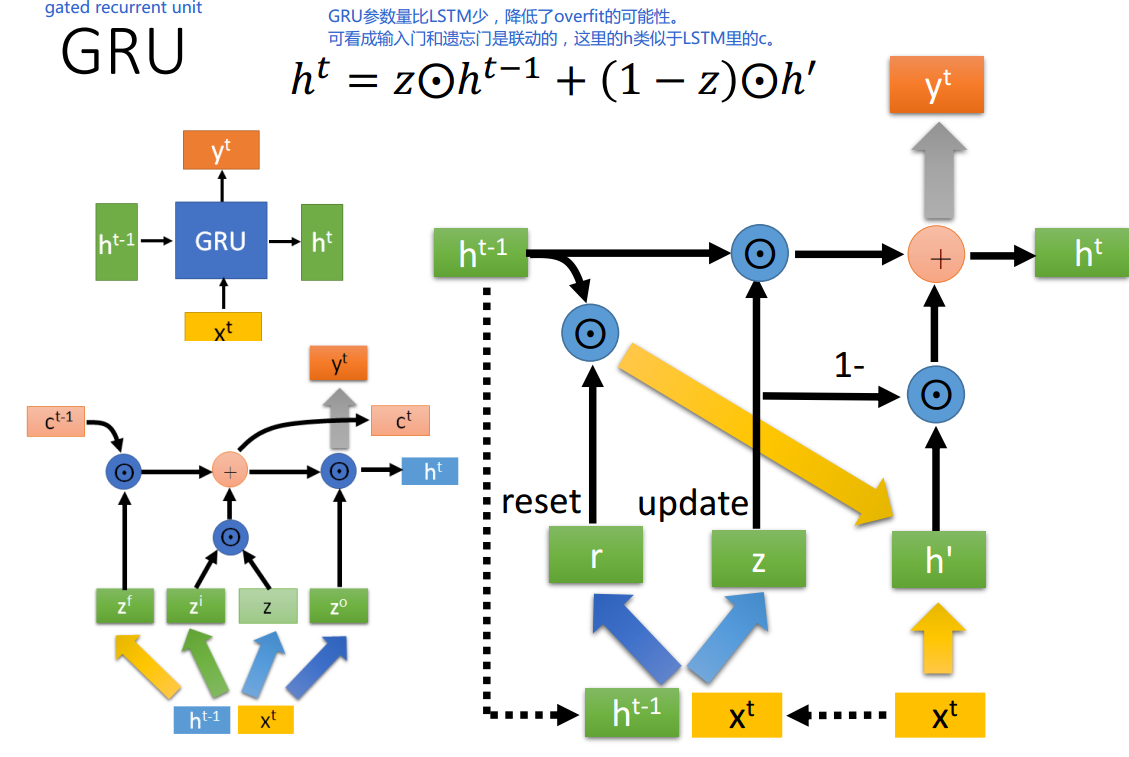
GRU的結構
GRU通過將忘記和輸入門合併,減少了LSTM的複雜性。GRU的結構主要由以下元件構成:
2.2.1 重置門
控制過去的隱藏狀態的哪些資訊應該被忽略。
2.2.2 更新門
控制隱藏狀態的哪些部分應該被更新。
2.2.3 新的記憶內容
計算新的候選隱藏狀態,可能會與當前隱藏狀態結合。
數學表述
GRU的工作過程可以通過以下方程表示:
-
重置門:
[ r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r) ] -
更新門:
[ z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z) ] -
新的記憶內容:
[ \tilde{h}t = \text{tanh}(W \cdot [r_t \odot h, x_t] + b) ] -
最終隱藏狀態:
[ h_t = (1 - z_t) \cdot h_{t-1} + z_t \cdot \tilde{h}_t ]
其中,( \sigma ) 表示sigmoid啟用函數,( \odot ) 表示逐元素乘法。
GRU的實現範例
# GRU的PyTorch實現
import torch.nn as nn
class GRU(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(GRU, self).__init__()
self.gru = nn.GRU(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, h_0):
out, h_n = self.gru(x, h_0) # 運用GRU層
out = self.fc(out) # 運用全連線層
return out
GRU的優勢和挑戰
GRU提供了與LSTM類似的效能,但結構更簡單,因此在計算和引數方面相對更有效率。然而,這種簡化可能會在某些任務中犧牲一些表現力。
總結
門控迴圈單元(GRU)是一種有效的RNN結構,旨在捕獲序列資料中的時序依賴關係。與LSTM相比,GRU具有更高的計算效率,同時仍保持了良好的效能。其在許多序列處理任務中的應用,如自然語言處理、語音識別等,進一步證明了其作為一種重要的深度學習工具的地位。
2.3 雙向迴圈神經網路(Bi-RNN)
雙向迴圈神經網路(Bidirectional Recurrent Neural Network,Bi-RNN)是一種能夠捕獲序列資料前後依賴關係的RNN架構。通過結合正向和反向的資訊流,Bi-RNN可以更全面地理解序列中的模式。
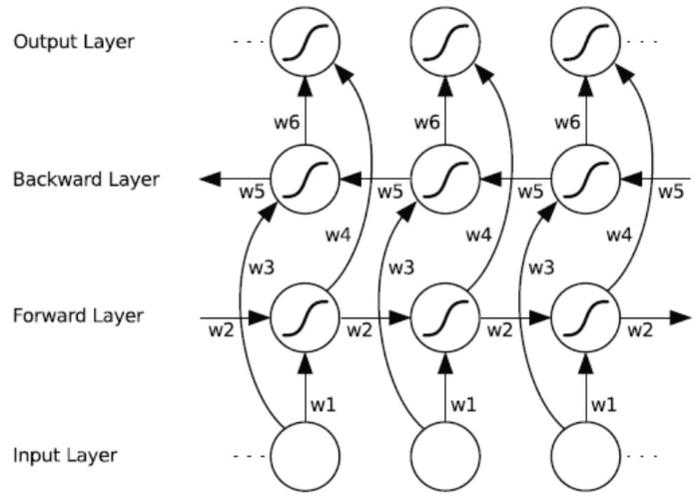
Bi-RNN的結構
Bi-RNN由兩個獨立的RNN層組成,一個正向層和一個反向層。這兩個層分別處理輸入序列的正向和反向版本。
2.3.1 正向層
處理輸入序列從第一個元素到最後一個元素。
2.3.2 反向層
處理輸入序列從最後一個元素到第一個元素。
資訊合併
正向和反向層的隱藏狀態通常通過連線或其他合併方式結合在一起,以形成最終的隱藏狀態。
Bi-RNN的實現範例
以下程式碼展示了使用PyTorch構建Bi-RNN的方法:
# Bi-RNN的PyTorch實現
import torch.nn as nn
class BiRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(BiRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True, bidirectional=True)
self.fc = nn.Linear(hidden_size * 2, output_size)
def forward(self, x):
out, _ = self.rnn(x) # 運用雙向RNN層
out = self.fc(out) # 運用全連線層
return out
Bi-RNN的應用
Bi-RNN在許多涉及序列分析的任務中非常有效,例如:
- 自然語言處理:通過捕獲上下文資訊,增強了對句子結構的理解。
- 語音識別:通過分析語音訊號的前後依賴關係,提高了識別準確性。
Bi-RNN與其他RNN結構的結合
Bi-RNN可以與其他RNN結構(例如LSTM和GRU)相結合,進一步增強其能力。
總結
雙向迴圈神經網路(Bi-RNN)通過同時分析序列的前向和反向資訊,實現了對序列資料更深入的理解。其在諸如自然語言處理和語音識別等複雜任務中的成功應用,顯示了Bi-RNN作為一種強大的深度學習模型的潛力和靈活性。
三、從程式碼實現迴圈神經網路
3.1 環境準備和資料預處理
為了成功實現迴圈神經網路,需要首先準備開發環境,並對資料進行適當的預處理。下面將詳細介紹每個階段的步驟。
3.1.1 環境準備
環境準備主要包括選擇合適的程式語言、深度學習框架、硬體環境等。
- 程式語言:Python是深度學習中廣泛使用的語言,有豐富的庫和社群支援。
- 深度學習框架:PyTorch是一種流行的開源框架,具有強大的靈活性和易用性。
- 硬體要求:GPU加速通常可以顯著提高訓練速度。
# 安裝PyTorch
!pip install torch torchvision
3.1.2 資料預處理
資料預處理是機器學習專案中的關鍵步驟,可以顯著影響模型的效能。
- 資料載入:首先載入所需的資料集。
- 資料淨化:刪除或替換缺失、重複或錯誤的值。
- 文字分詞:如果是NLP任務,需要對文字進行分詞處理。
- 序列填充:確保輸入序列具有相同的長度。
- 歸一化:對特徵進行標準化處理。
- 資料分割:將資料分為訓練集、驗證集和測試集。
以下是資料預處理的範例程式碼:
# 用於資料預處理的PyTorch程式碼
from torch.utils.data import DataLoader
from torchvision import transforms
# 定義轉換
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5]),
])
# 載入資料集
train_dataset = CustomDataset(transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
總結
環境準備和資料預處理是迴圈神經網路實現過程中的基礎階段。選擇合適的工具和硬體,並對資料進行適當的清洗和轉換,是確保專案成功的關鍵。與此同時,使用合適的資料預處理技術可以顯著提高模型的效能和穩定性。通過本節的介紹,讀者應能夠理解並實現迴圈神經網路所需的環境準備和資料預處理步驟。
3.2 使用PyTorch構建RNN模型
PyTorch是一種流行的深度學習框架,廣泛用於構建和訓練神經網路模型。在本節中,我們將介紹如何使用PyTorch構建基本的RNN模型。
3.2.1 定義RNN結構
RNN模型由輸入層、隱藏層和輸出層組成。以下是構建RNN的程式碼範例:
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
out = self.fc(out)
return out
這裡,input_size表示輸入特徵的數量,hidden_size表示隱藏層神經元的數量,output_size表示輸出層神經元的數量。
3.2.2 初始化模型
初始化模型涉及設定其引數和選擇優化器與損失函數。
model = SimpleRNN(input_size=10, hidden_size=20, output_size=1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
3.2.3 訓練模型
訓練模型包括以下步驟:
- 前向傳播:通過模型傳遞輸入資料並計算輸出。
- 計算損失:使用預測輸出和實際目標計算損失。
- 反向傳播:根據損失計算梯度。
- 優化器步驟:更新模型權重。
# 訓練迴圈範例
for epoch in range(epochs):
for batch in train_loader:
inputs, targets = batch
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
3.2.4 模型評估和儲存
通過在驗證集或測試集上評估模型,您可以瞭解其泛化效能。一旦滿意,可以儲存模型供以後使用。
# 儲存模型
torch.save(model.state_dict(), 'model.pth')
總結
使用PyTorch構建RNN模型涉及多個步驟,包括定義模型結構、初始化、訓練和評估。本節通過詳細的程式碼範例和解釋為讀者提供了一個全面的指南,可以用來構建自己的RNN模型。在理解了基本的RNN之後,讀者還可以進一步探索更復雜的變體,如LSTM、GRU和雙向RNN。
三、從程式碼實現迴圈神經網路

3.3 訓練和評估模型
訓練和評估模型是深度學習工作流程的核心部分。本節將詳細介紹如何使用PyTorch進行RNN模型的訓練和評估。
3.3.1 訓練模型
3.3.1.1 訓練迴圈
訓練迴圈是重複的過程,包括前向傳播、損失計算、反向傳播和優化權重。以下是典型的訓練迴圈程式碼:
for epoch in range(epochs):
for batch in train_loader:
inputs, targets = batch
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')
3.3.1.2 監控訓練進度
通常使用驗證集監控模型的訓練進度,並使用如TensorBoard等工具視覺化訓練和驗證損失。
3.3.2 評估模型
3.3.2.1 驗證集評估
在驗證集上評估模型可以瞭解模型在未見過的資料上的效能。
model.eval()
with torch.no_grad():
for batch in val_loader:
inputs, targets = batch
outputs = model(inputs)
val_loss += criterion(outputs, targets).item()
print(f'Validation Loss: {val_loss/len(val_loader)}')
3.3.2.2 測試集評估
在測試集上的評估為您提供了模型在實際應用場景下可能的效能。
3.3.2.3 模型指標
除了損失外,還可以計算其他重要指標,例如準確率、精確度、召回率等。
3.3.3 超引數調優
超引數調優涉及使用諸如Grid Search或Random Search的技術來找到最佳超引數組合。
總結
訓練和評估模型是深度學習專案的核心階段。本節詳細介紹瞭如何使用PyTorch進行訓練迴圈、監控訓練進度、評估模型、計算效能指標以及超引數調優。通過了解這些關鍵概念和技術,讀者可以有效地訓練和評估RNN模型,為實際應用做好準備。
四、總結

在本系列部落格中,我們詳細探討了迴圈神經網路(RNN)的各個方面。以下是重要內容的總結:
4.1 迴圈神經網路(RNN)
我們介紹了RNN的基本結構和工作原理,以及它如何捕捉序列資料中的時間依賴關係。然後,我們深入瞭解了各種RNN的應用場景,涵蓋了自然語言處理、時間序列分析等領域。
4.2 RNN的高階變體
- 長短時記憶網路(LSTM):解決了RNN長序列訓練中的梯度消失和爆炸問題。
- 門控迴圈單元(GRU):與LSTM相似,但結構更簡單。
- 雙向迴圈神經網路(Bi-RNN):通過同時考慮過去和未來的資訊,增強了序列建模的能力。
4.3 程式碼實現
- 環境準備和資料預處理:介紹瞭如何準備資料和環境。
- 使用PyTorch構建RNN模型:詳細解釋瞭如何使用PyTorch構建和訓練RNN模型。
- 訓練和評估模型:描述了完整的訓練和評估流程,包括超引數調優和模型效能評估。
4.4 結語
通過深入瞭解RNN及其變體、理解它們的工作原理、掌握使用PyTorch進行實現的技巧,讀者可以充分利用RNN在複雜序列資料分析方面的強大功能。這種知識不僅可用於當前的專案,還為未來的研究和開發工作奠定了堅實的基礎。迴圈神經網路是深度學習中的一個重要分支,通過不斷探索和學習,我們可以繼續推動這一領域的創新和進展。
作者 TechLead,擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
個人微信公眾號:【TechLead】分享AI與雲服務研發的全維度知識,談談我作為TechLead對技術的獨特洞察。
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。