Pandas 使用教學 JSON
2023-08-28 12:00:38
Pandas 可以很方便的處理 JSON 資料
demo.json
[
{
"name":"張三",
"age":23,
"gender":true
},
{
"name":"李四",
"age":24,
"gender":true
},
{
"name":"王五",
"age":25,
"gender":false
}
]
JSON 轉換為 CSV
非常方便,只要通過 pd.read_json 讀出JSON資料,再通過 df.to_csv 寫入 CSV 即可
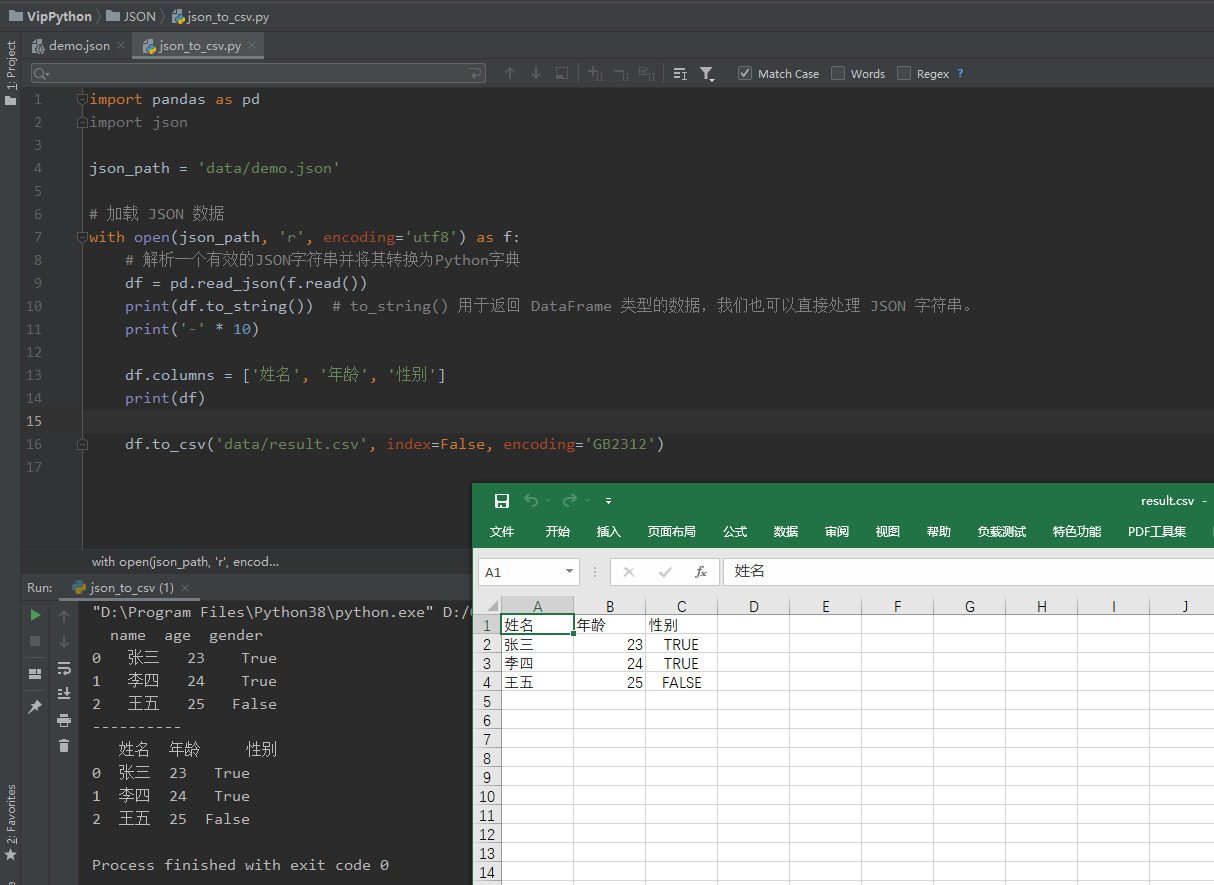
import pandas as pd
json_path = 'data/demo.json'
# 載入 JSON 資料
with open(json_path, 'r', encoding='utf8') as f:
# 解析一個有效的JSON字串並將其轉換為Python字典
df = pd.read_json(f.read())
print(df.to_string()) # to_string() 用於返回 DataFrame 型別的資料,我們也可以直接處理 JSON 字串。
print('-' * 10)
# 重新定義標題
df.columns = ['姓名', '年齡', '性別']
print(df)
df.to_csv('data/result.csv', index=False, encoding='GB2312')
簡單 JSON
從 URL 中讀取 JSON 資料:
import pandas as pd
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL) # 和讀檔案一樣
print(df)
輸出:
id name url likes
0 A001 菜鳥教學 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘寶 www.taobao.com 45
字典轉化為 DataFrame 資料
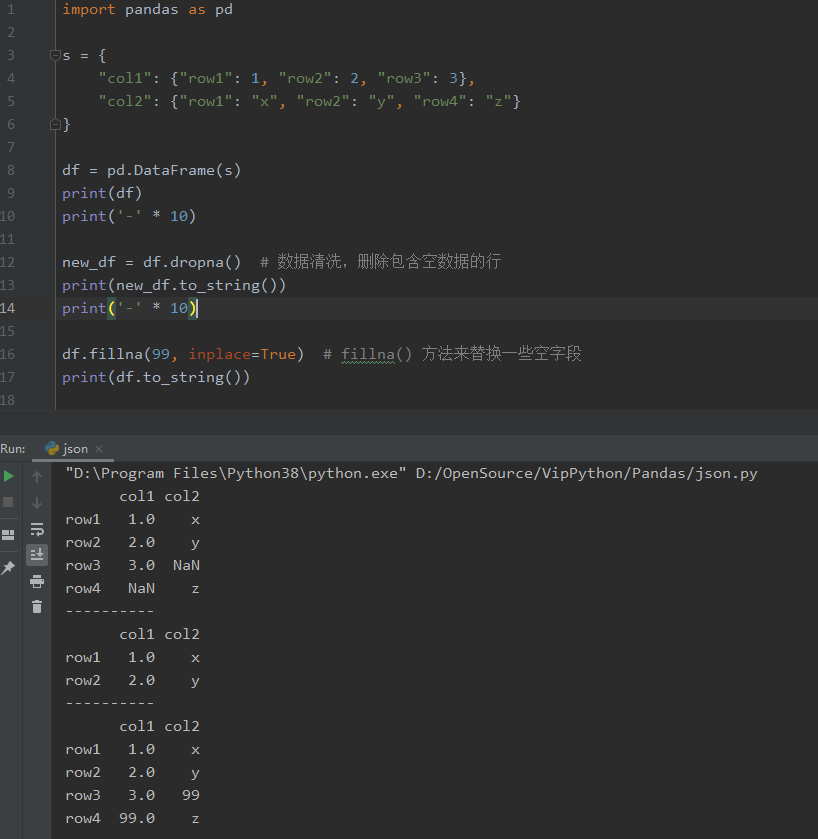
import pandas as pd
s = {
"col1": {"row1": 1, "row2": 2, "row3": 3},
"col2": {"row1": "x", "row2": "y", "row4": "z"}
}
df = pd.DataFrame(s)
print(df)
print('-' * 10)
new_df = df.dropna() # 資料淨化,刪除包含空資料的行
print(new_df.to_string())
print('-' * 10)
df.fillna(99, inplace=True) # fillna() 方法來替換一些空欄位
print(df.to_string())
輸出:不同的行會用 NaN 填充
col1 col2
row1 1.0 x
row2 2.0 y
row3 3.0 NaN
row4 NaN z
----------
col1 col2
row1 1.0 x
row2 2.0 y
----------
col1 col2
row1 1.0 x
row2 2.0 y
row3 3.0 99
row4 99.0 z
內嵌的 JSON 資料
nested_list.json 巢狀的JSON資料
{
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}
]
}
執行程式碼
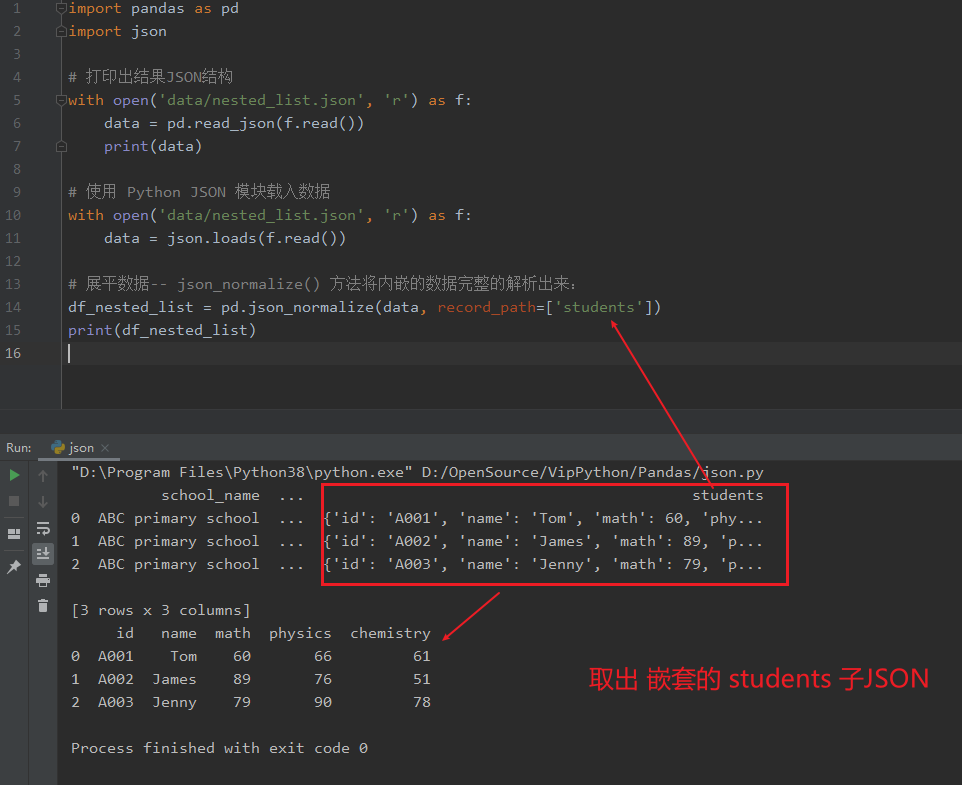
data = json.loads(f.read()) 使用 Python JSON 模組載入資料。
json_normalize() 使用了引數 record_path 並設定為 ['students'] 用於展開內嵌的 JSON 資料 students。
import pandas as pd
import json
# 列印出結果JSON結構
with open('data/nested_list.json', 'r') as f:
data = pd.read_json(f.read())
print(data)
# 使用 Python JSON 模組載入資料
with open('data/nested_list.json', 'r') as f:
data = json.loads(f.read())
# 展平資料-- json_normalize() 方法將內嵌的資料完整的解析出來:
df_nested_list = pd.json_normalize(data, record_path=['students'])
print(df_nested_list)
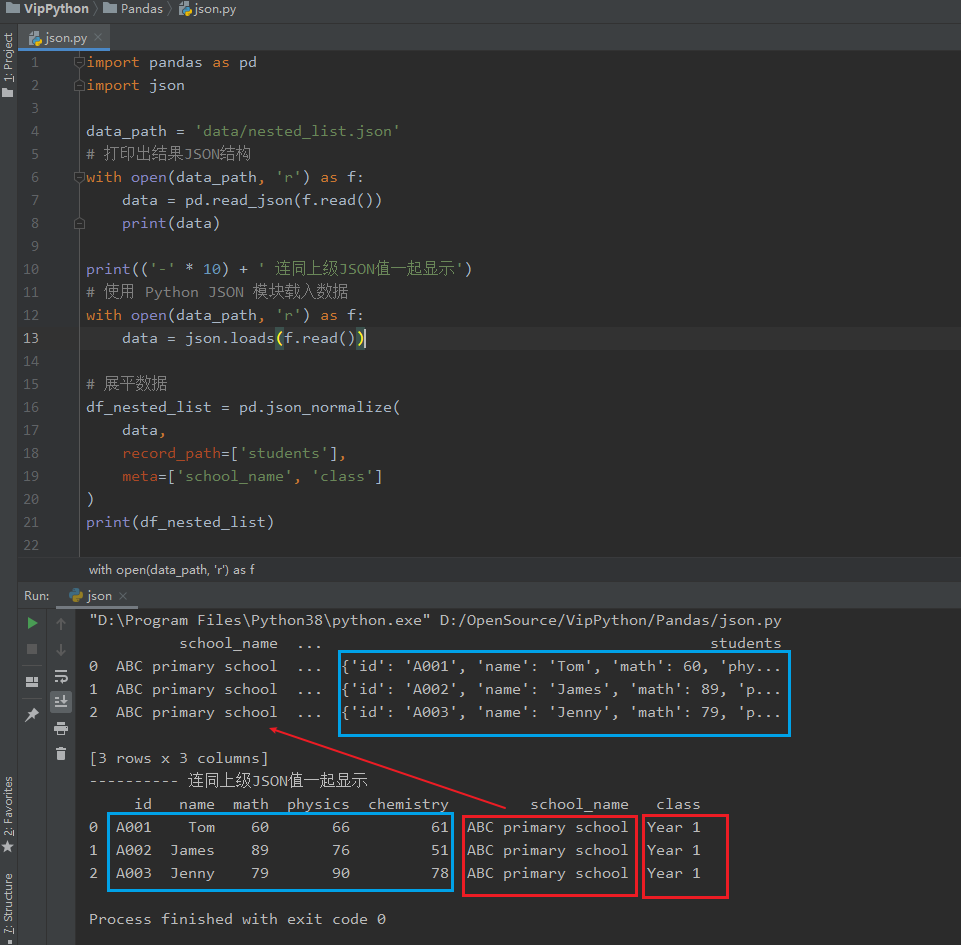
import pandas as pd
import json
data_path = 'data/nested_list.json'
print(('-' * 10) + ' 連同上級JSON值一起顯示')
# 使用 Python JSON 模組載入資料
with open(data_path, 'r') as f:
data = json.loads(f.read())
# 展平資料
df_nested_list = pd.json_normalize(
data,
record_path=['students'],
meta=['school_name', 'class']
)
print(df_nested_list)
複雜 JSON
該資料巢狀了列表和字典,資料檔案 nested_mix.json 如下
nested_mix.json
{
"school_name": "local primary school",
"class": "Year 1",
"info": {
"president": "John Kasich",
"address": "ABC road, London, UK",
"contacts": {
"email": "[email protected]",
"tel": "123456789"
}
},
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
import pandas as pd
import json
# 使用 Python JSON 模組載入資料
with open('data/nested_mix.json', 'r') as f:
data = json.loads(f.read())
df = pd.json_normalize(
data,
record_path=['students'],
meta=[
'class',
['info', 'president'], # 類似 info.president
['info', 'contacts', 'tel']
]
)
print(df)
id name math ... class info.president info.contacts.tel
0 A001 Tom 60 ... Year 1 John Kasich 123456789
1 A002 James 89 ... Year 1 John Kasich 123456789
2 A003 Jenny 79 ... Year 1 John Kasich 123456789
[3 rows x 8 columns]
讀取內嵌資料中的一組資料
nested_deep.json
{
"school_name": "local primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"grade": {
"math": 60,
"physics": 66,
"chemistry": 61
}
},
{
"id": "A002",
"name": "James",
"grade": {
"math": 89,
"physics": 76,
"chemistry": 51
}
},
{
"id": "A003",
"name": "Jenny",
"grade": {
"math": 79,
"physics": 90,
"chemistry": 78
}
}]
}
這裡我們需要使用到 glom 模組來處理資料套嵌,glom 模組允許我們使用 . 來存取內嵌物件的屬性。
第一次使用我們需要安裝 glom:
pip3 install glom -i https://pypi.tuna.tsinghua.edu.cn/simple
import pandas as pd
from glom import glom
df = pd.read_json('nested_deep.json')
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
print(data)
輸出:
0 60
1 89
2 79
本文來自部落格園,作者:VipSoft 轉載請註明原文連結:https://www.cnblogs.com/vipsoft/p/17657189.html