Kafka為什麼這麼快?
Kafka 是一個基於釋出-訂閱模式的訊息系統,它可以在多個生產者和消費者之間傳遞大量的資料。Kafka 的一個顯著特點是它的高吞吐率,即每秒可以處理百萬級別的訊息。那麼 Kafka 是如何實現這樣高得效能呢?本文將從七個方面來分析 Kafka 的速度優勢。
- 零拷貝技術
- 僅可追加紀錄檔結構
- 訊息批次處理
- 訊息批次壓縮
- 消費者優化
- 未重新整理的緩衝寫入
- GC 優化
以下是對本文中使用得一些英文單詞得解釋:
Broker:Kafka 叢集中的一臺或多臺伺服器統稱 broker
Producer:訊息生產者
Consumer:訊息消費者
zero copy:零拷貝
1. 零拷貝技術
零拷貝技術是指在讀寫資料時,避免將資料在核心空間和使用者空間之間進行拷貝,而是直接在核心空間進行資料傳輸。對於 Kafka 來說,它使用了零拷貝技術來加速磁碟檔案的網路傳輸,以提高讀取速度和降低 CPU 消耗。下圖說明了資料如何在生產者和消費者之間傳輸,以及零拷貝原理。
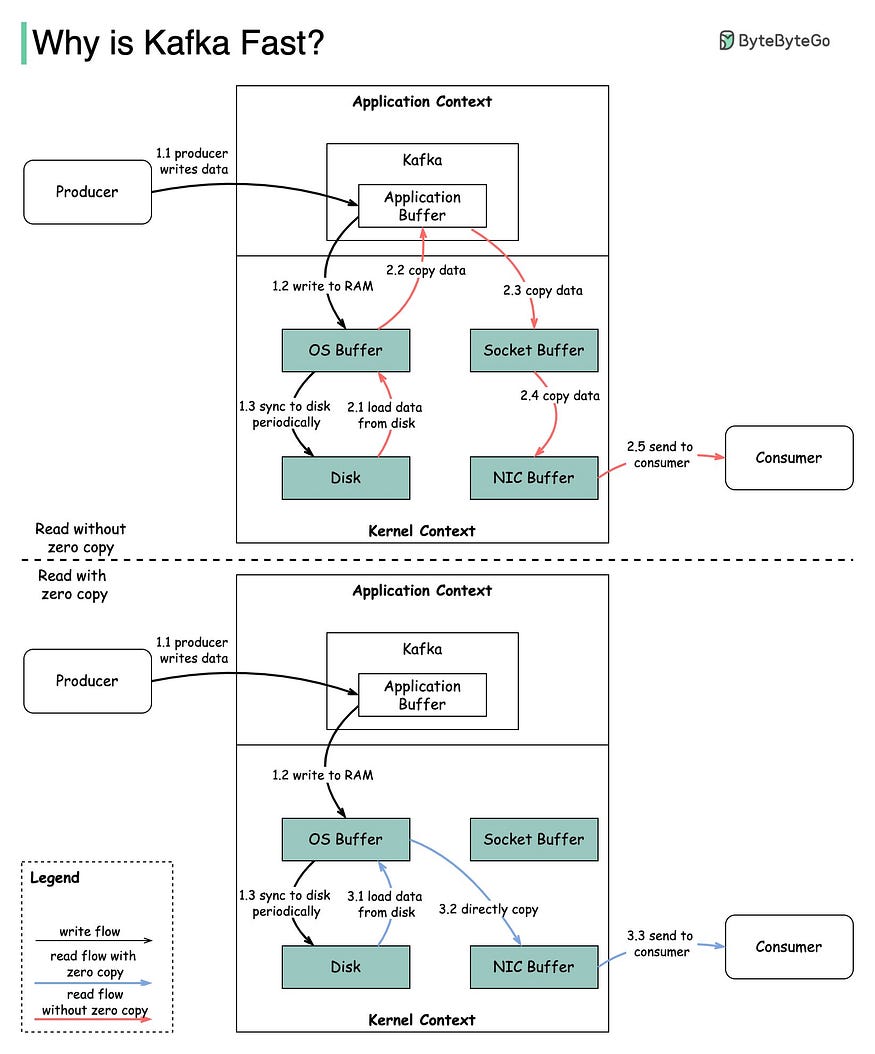
步驟 1.1~1.3:生產者將資料寫入磁碟
步驟 2:消費者不使用零拷貝方式讀取資料
2.1:資料從磁碟載入到 OS 快取
2.2:將資料從 OS 快取複製到 Kafka 應用程式
2.3:Kafka 應用程式將資料複製到 socket 緩衝區
2.4:將資料從 socket 緩衝區複製到網路卡
2.5:網路卡將資料傳送給消費者
步驟 3:消費者以零拷貝方式讀取資料
3.1:資料從磁碟載入到 OS 快取
3.2:OS 快取通過 sendfile() 命令直接將資料複製到網路卡
3.3:網路卡將資料傳送到消費者
可以看到,零拷貝技術避免了多餘得兩步操作,資料直接從OS 快取複製到網路卡再到消費者。這樣做的好處是極大地提高了I/O效率,降低了CPU和記憶體的消耗。
推薦博主開源的 H5 商城專案waynboot-mall,這是一套全部開源的微商城專案,包含三個專案:運營後臺、H5 商城前臺和伺服器端介面。實現了商城所需的首頁展示、商品分類、商品詳情、商品 sku、分詞搜尋、購物車、結算下單、支付寶/微信支付、收單評論以及完善的後臺管理等一系列功能。 技術上基於最新得 Springboot3.0、jdk17,整合了 MySql、Redis、RabbitMQ、ElasticSearch 等常用中介軟體。分模組設計、簡潔易維護,歡迎大家點個 star、關注博主。
github 地址:https://github.com/wayn111/waynboot-mall
2. 僅可追加紀錄檔結構
Kafka 中存在大量的網路資料持久化到磁碟(生產者到代理)和磁碟檔案通過網路傳送(代理到消費者)的過程。這一過程的效能會直接影響 Kafka 的整體吞吐量。為了優化 Kafka 的資料儲存和傳輸,Kafka 採用了一種僅可追加紀錄檔結構方式來持久化資料。僅可追加紀錄檔結構是指將資料以順序追加(append-only)的方式寫入到檔案中,而不是進行隨機寫入或更新。這樣做的好處是可以減少磁碟 I/O 的開銷,提高寫入速度。
人們普遍認為磁碟的讀寫速度很慢,但實際上儲存媒介(尤其是旋轉媒介)的效能很大程度上取決於存取模式。常見的 7,200 RPM SATA 磁碟上的隨機 I / O 的效能要比順序 I / O 慢 3 ~ 4 個數量級。此外,現代作業系統提供了預讀和延遲寫入技術,可以預先取出大塊的資料,並將較小的邏輯寫入組合成較大的物理寫入。因此,即使在快閃記憶體和其他形式的固態非易失性媒介中,隨機 I/O 和順序 I/O 的差異仍然很明顯,儘管與旋轉媒介相比,這種差異性已經很小了。
3. 訊息批次處理
Kafka 的高吞吐率設計的核心要點之一是批次處理,即 Kafka 在訊息傳送端和接收端都引入了一個緩衝區,將多條訊息打包成一個批次(Batch),然後一次性傳送或接收。這樣做的好處是可以減少網路請求的次數,減少了網路壓力,提高了傳輸效率。
Kafka 的訊息批次處理優化主要涉及以下幾個方面:
傳送端(Producer)
Kafka 的 Producer 只提供了單條傳送的 send()方法,並沒有提供任何批次傳送的介面。當呼叫 send()方法傳送一條訊息之後,無論是同步還是非同步傳送,這條訊息不會立即傳送出去,而是先放入到一個雙端佇列中,然後 Kafka 使用一個非同步執行緒從佇列中成批傳送訊息。
Kafka 提供了以下幾個引數來控制傳送端的批次處理策略:
- batch.size:指定每個批次可以收集的訊息數量的最大值。預設是 16KB。
- buffer.memory:指定每個 Producer 可以使用的緩衝區記憶體的總量。預設是 32MB。
- linger.ms:指定每個批次可以等待的時間的最大值。預設是 0ms。
- compression.type:指定是否對每個批次進行壓縮,以及使用哪種壓縮演演算法。預設是 none。
接收端(Broker)
Kafka 的 Broker 在接收到 Producer 傳送過來的批次後,不會把批次再還原成多條訊息,而是直接將整個批次寫入到磁碟中。這樣做的好處是可以減少磁碟 I/O 的開銷,提高寫入速度。
Kafka 利用了作業系統提供的記憶體對映檔案(memory mapped file)功能,將檔案對映到記憶體中,使得對檔案的讀寫操作就相當於對記憶體的讀寫操作。這樣就避免了使用者空間和核心空間之間的資料拷貝,也避免了系統呼叫的開銷。
消費端(Consumer)
Kafka 的 Consumer 在從 Broker 拉取資料時,也是以批次為單位進行傳遞的。Consumer 從 Broker 拉到一批訊息後,使用者端把批次解開,再一條一條交給使用者程式碼處理。
Kafka 提供了以下幾個引數來控制消費端的批次處理策略:
- fetch.min.bytes:指定每次拉取請求至少要獲取多少位元組的資料。預設是 1B。
- fetch.max.bytes:指定每次拉取請求最多能獲取多少位元組的資料。預設是 50MB。
- fetch.max.wait.ms:指定每次拉取請求最多能等待多長時間。預設是 500ms。
- max.partition.fetch.bytes:指定每個分割區每次拉取請求最多能獲取多少位元組的資料。預設是 1MB。
4. 訊息批次壓縮
訊息批次壓縮通常與訊息批次處理一起使用。Kafka 會將多個訊息打包成一個批次(Batch),並對批次進行壓縮(例如使用 gzip 或 snappy 演演算法),然後再傳送給消費者。這樣做的好處是可以節省網路頻寬,提高傳輸效率。
當然,壓縮也有一定的代價,即需要消耗 CPU 資源來進行壓縮和解壓縮。但是對於 Kafka 這樣的高吞吐量的系統來說,網路頻寬往往是更大的瓶頸,所以壓縮是值得的。
Kafka 還提供了一種靈活的壓縮策略,即可以讓生產者、代理和消費者之間協商壓縮格式和級別。生產者可以選擇是否對訊息進行壓縮,以及使用哪種壓縮演演算法;代理可以選擇是否保留生產者壓縮的訊息,或者對其進行重新壓縮;消費者可以選擇是否對收到的訊息進行解壓縮。這樣可以根據不同的場景和需求來平衡效能和資源的消耗。
5. 消費者優化
Kafka 的消費者是基於拉模式(pull)的,即消費者主動向伺服器請求資料,而不是伺服器主動推播資料給消費者。這樣做的好處是可以讓消費者自己控制消費的速度和時機,也可以減輕伺服器的負擔,提高整體的吞吐量。
Kafka 的消費者所實現的功能是比較簡潔的,即它們不需要維護太多的狀態和資源,也不需要和伺服器進行復雜的互動。Kafka 的消費者只需要做以下幾件事:
- 訂閱一個或多個主題(topic),並加入一個消費者組(consumer group)。
向群組協調器(group coordinator)傳送心跳,表明自己還活著,並參與分割區再均衡(partition rebalance)。 - 向分割區所在的代理(broker)傳送拉取請求(fetch request),獲取訊息資料。
- 提交自己消費到的偏移量(offset),以便在出現故障時恢復消費位置。
可以看到,Kafka 的消費者並不需要儲存訊息資料,也不需要對訊息進行確認或回覆,也不需要處理重試或重複的問題。這些都由伺服器端來負責。Kafka 的消費者只需要關注如何從伺服器獲取資料,並進行業務處理即可。
6. 未重新整理的緩衝寫入
Kafka 在寫入資料時,使用了一種未重新整理(flush)的緩衝寫入技術,即它不會立即將資料寫入硬碟,而是先寫入記憶體快取中,然後由作業系統在適當的時候重新整理到硬碟上。這樣做的好處是可以提高寫入速度,減少磁碟 I/O 的開銷。
Kafka 利用了作業系統提供的記憶體對映檔案(memory mapped file)功能,將檔案對映到記憶體中,使得對檔案的讀寫操作就相當於對記憶體的讀寫操作。這樣就避免了使用者空間和核心空間之間的資料拷貝,也避免了系統呼叫的開銷。
當生產者向 Kafka 傳送訊息時,Kafka 會將訊息追加到記憶體對映檔案中,並返回一個確認給生產者。此時訊息並沒有真正寫入硬碟,而是由作業系統負責將記憶體中的資料重新整理到硬碟上。作業系統會根據一些策略來決定何時重新整理資料,例如定期重新整理、快取滿了重新整理、系統空閒時重新整理等。
當然,這種技術也有一定的風險,即如果作業系統在重新整理資料之前發生崩潰或斷電,那麼記憶體中未重新整理的資料就會丟失。為了解決這個問題,Kafka 提供了一些引數來控制重新整理策略,例如:
- log.flush.interval.messages:指定多少條訊息後強制重新整理資料。
- log.flush.interval.ms:指定多少毫秒後強制重新整理資料。
- producer.type:指定生產者是同步還是非同步模式。同步模式下,生產者會等待伺服器重新整理資料後再返回確認;非同步模式下,生產者不會等待伺服器重新整理資料,而是立即返回確認。
7. GC 優化
Kafka 作為一個 Java 編寫得高效能的分散式訊息系統,它需要處理大量的資料讀寫和網路傳輸。這些操作都會涉及到 Java 虛擬機器器(JVM)的記憶體管理和垃圾回收(GC)機制。如果 GC 不合理或不及時,就會導致 Kafka 的效能下降,甚至出現記憶體溢位或頻繁的停頓。為了幫助使用者優化 GC,Kakfa 有如下建議。
堆記憶體大小
堆記憶體是 JVM 用來儲存物件範例的記憶體區域,它會受到 GC 的管理和回收。堆記憶體的大小會影響 Kafka 的效能和穩定性,如果堆記憶體太小,就會導致頻繁的 GC,影響吞吐量和延遲;如果堆記憶體太大,就會導致 GC 時間過長,影響響應速度和可用性。
通常來說,Kafka 並不需要設定太大的堆記憶體,因為它主要依賴於作業系統的檔案快取(page cache)來快取和讀寫資料,而不是將資料儲存在堆記憶體中。因此 Kafka 建議將堆記憶體大小設定為 4GB 到 6GB 之間。
堆外記憶體大小
堆外記憶體是 JVM 用來儲存非物件範例的記憶體區域,它不會受到 GC 的管理和回收。堆外記憶體主要用於網路 I/O 緩衝區、直接記憶體對映檔案、壓縮庫等。
Kafka 在進行網路 I/O 時,會使用堆外記憶體作為緩衝區,以減少資料在使用者空間和核心空間之間的拷貝。同時,Kafka 在進行資料壓縮時,也會使用堆外記憶體作為臨時空間,以減少 CPU 資源的消耗。
因此,堆外記憶體對於 Kafka 的效能也很重要,如果堆外記憶體不足,就會導致緩衝區分配失敗或壓縮失敗,影響吞吐量和延遲。通常來說,Kafka 建議將堆外記憶體大小設定為 8GB 左右。
GC 演演算法和引數
GC 演演算法是 JVM 用來回收無用物件佔用的堆記憶體空間的方法,它會影響 Kafka 的停頓時間和吞吐量。GC 演演算法有多種選擇,例如序列 GC、並行 GC、CMS GC、G1 GC 等。
不同的 GC 演演算法有不同的優缺點和適用場景,例如序列 GC 適合小型應用和低延遲場景;並行 GC 適合大型應用和高吞吐量場景;CMS GC 適合大型應用和低停頓時間場景;G1 GC 適合大型應用和平衡停頓時間和吞吐量場景等。
通常來說,Kafka 建議使用 G1 GC 作為預設的 GC 演演算法,因為它可以在保證較高吞吐量的同時,控制停頓時間在 200ms 以內。同時,Kafka 還建議根據具體情況調整一些 GC 引數,例如:
- -XX:MaxGCPauseMillis:指定最大停頓時間目標,預設是 200ms。
- -XX:InitiatingHeapOccupancyPercent:指定觸發並行標記週期的堆佔用百分比,預設是 45%。
- -XX:G1ReservePercent:指定為拷貝存活物件預留的空間百分比,預設是 10%。
- -XX:G1HeapRegionSize:指定每個堆區域的大小,預設是 2MB。
本文參考
- https://medium.com/swlh/why-kafka-is-so-fast-bde0d987cd03
- https://blog.bytebytego.com/p/why-is-kafka-fast
- https://blog.csdn.net/csdnnews/article/details/104471147
總結
最後感謝大家閱讀,希望本文能對你有所幫助.
關注公眾號【waynblog】每週分享技術乾貨、開源專案、實戰經驗、高效開發工具等,您的關注將是我的更新動力!