一次Java記憶體佔用高的排查案例,解釋了我對記憶體問題的所有疑問
原創:扣釘日記(微信公眾號ID:codelogs),歡迎分享,非公眾號轉載保留此宣告。
問題現象
7月25號,我們一服務的記憶體佔用較高,約13G,容器總記憶體16G,佔用約85%,觸發了記憶體報警(閾值85%),而我們是按容器記憶體60%(9.6G)的比例設定的JVM堆記憶體。看了下其它服務,同樣的堆記憶體設定,它們記憶體佔用約70%~79%,此服務比其它服務記憶體佔用稍大。

那為什麼此服務記憶體佔用稍大呢,它存在記憶體洩露嗎?
排查步驟
1. 檢查Java堆佔用與gc情況
jcmd 1 GC.heap_info

jstat -gcutil 1 1000
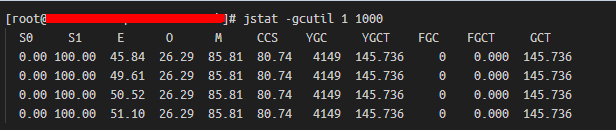
可見堆使用情況正常。
2. 檢查非堆佔用情況
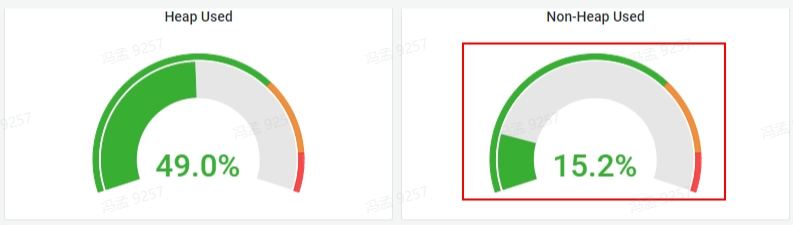
檢視監控儀表盤,如下:
arthas的memory命令檢視,如下:
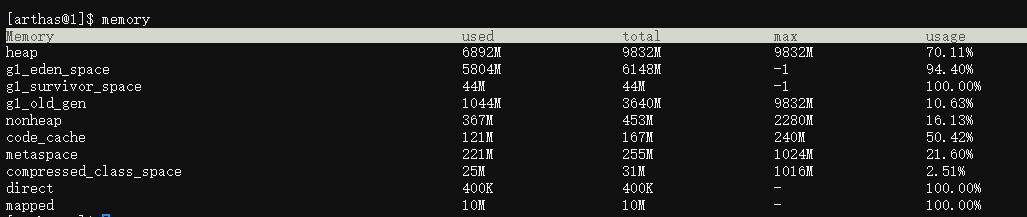
可見非堆記憶體佔用也正常。
3. 檢查native記憶體
Linux程序的記憶體佈局,如下:
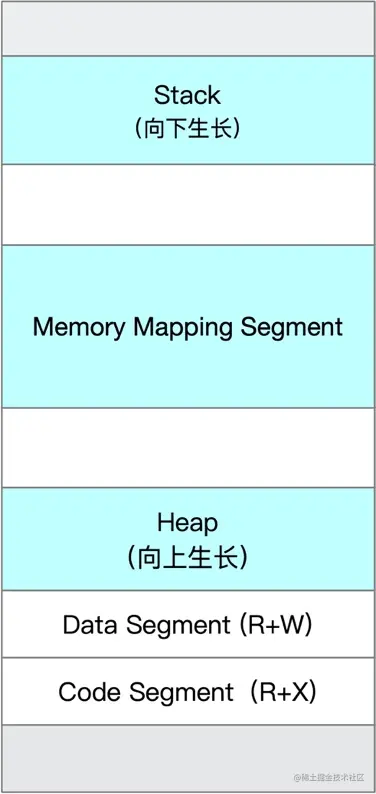
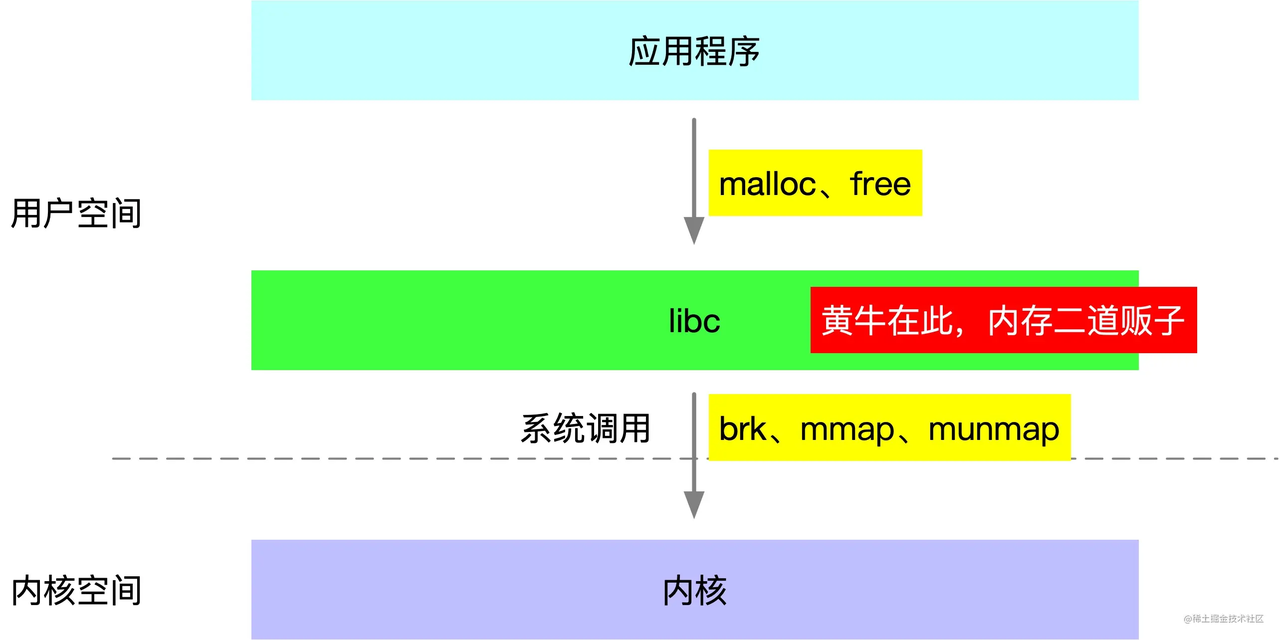
linux程序啟動時,有程式碼段、資料段、堆(Heap)、棧(Stack)及記憶體對映段,在執行過程中,應用程式呼叫malloc、mmap等C庫函數來使用記憶體,C庫函數內部則會視情況通過brk系統呼叫擴充套件堆或使用mmap系統呼叫建立新的記憶體對映段。
而通過pmap命令,就可以檢視程序的記憶體佈局,它的輸出樣例如下:
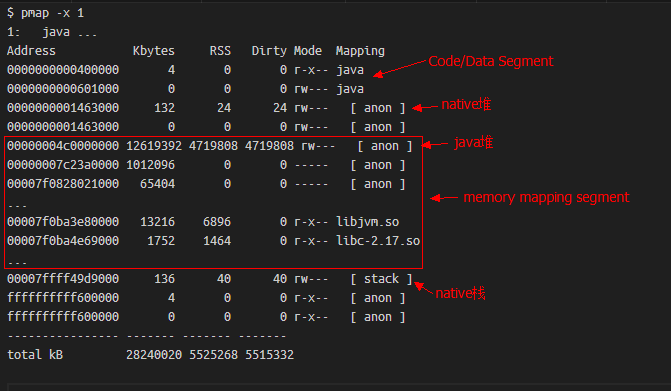
可以發現,程序申請的所有虛擬記憶體段,都在pmap中能夠找到,相關欄位解釋如下:
- Address:表示此記憶體段的起始地址
- Kbytes:表示此記憶體段的大小(ps:這是虛擬記憶體)
- RSS:表示此記憶體段實際分配的實體記憶體,這是由於Linux是延遲分配記憶體的,程序呼叫malloc時Linux只是分配了一段虛擬記憶體塊,直到程序實際讀寫此記憶體塊中部分時,Linux會通過缺頁中斷真正分配實體記憶體。
- Dirty:此記憶體段中被修改過的記憶體大小,使用mmap系統呼叫申請虛擬記憶體時,可以關聯到某個檔案,也可不關聯,當關聯了檔案的記憶體段被存取時,會自動讀取此檔案的資料到記憶體中,若此段某一頁記憶體資料後被更改,即為Dirty,而對於非檔案對映的匿名記憶體段(anon),此列與RSS相等。
- Mode:記憶體段是否可讀(r)可寫(w)可執行(x)
- Mapping:記憶體段對映的檔案,匿名記憶體段顯示為anon,非匿名記憶體段顯示檔名(加-p可顯示全路徑)。
因此,我們可以找一些記憶體段,來看看這些記憶體段中都儲存的什麼資料,來確定是否有洩露。但jvm一般有非常多的記憶體段,重點檢查哪些記憶體段呢?
有兩種思路,如下:
- 檢查那些佔用記憶體較大的記憶體段,如下:
pmap -x 1 | sort -nrk3 | less
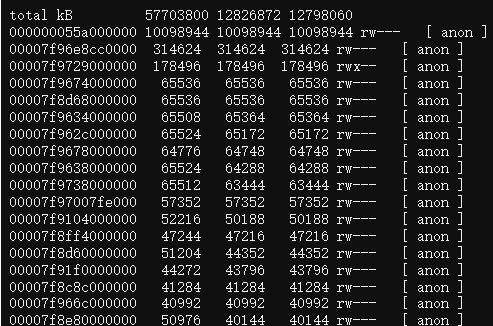
可以發現我們程序有非常多的64M的記憶體塊,而我同時看了看其它java服務,發現64M記憶體塊則少得多。
- 檢查一段時間後新增了哪些記憶體段,或哪些變大了,如下:
在不同的時間點多次儲存pmap命令的輸出,然後通過文字對比工具檢視兩個時間點記憶體段分佈的差異。
pmap -x 1 > pmap-`date +%F-%H-%M-%S`.log

icdiff pmap-2023-07-27-09-46-36.log pmap-2023-07-28-09-29-55.log | less -SR
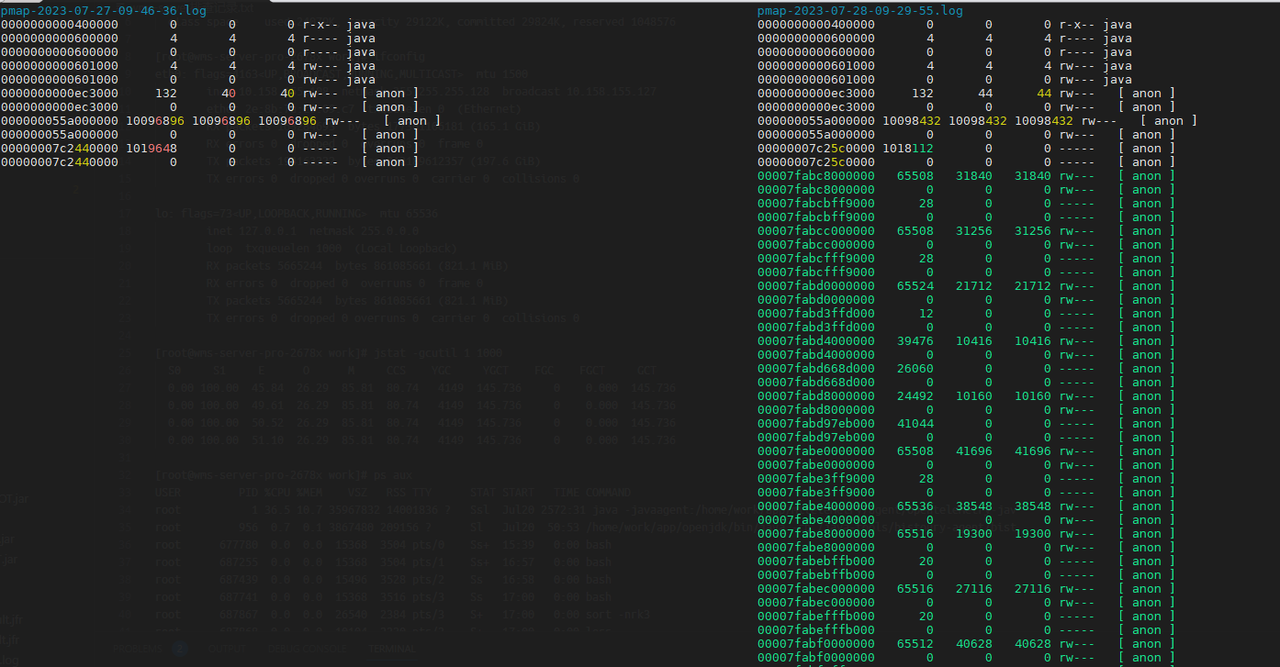
可以看到,一段時間後,新分配了一些記憶體段,看看這些變化的記憶體段裡存的是什麼內容!
tail -c +$((0x00007face0000000+1)) /proc/1/mem|head -c $((11616*1024))|strings|less -S
說明:
- Linux將程序記憶體虛擬為偽檔案/proc/$pid/mem,通過它即可檢視程序記憶體中的資料。
- tail用於偏移到指定記憶體段的起始地址,即pmap的第一列,head用於讀取指定大小,即pmap的第二列。
- strings用於找出記憶體中的字串資料,less用於檢視strings輸出的字串。
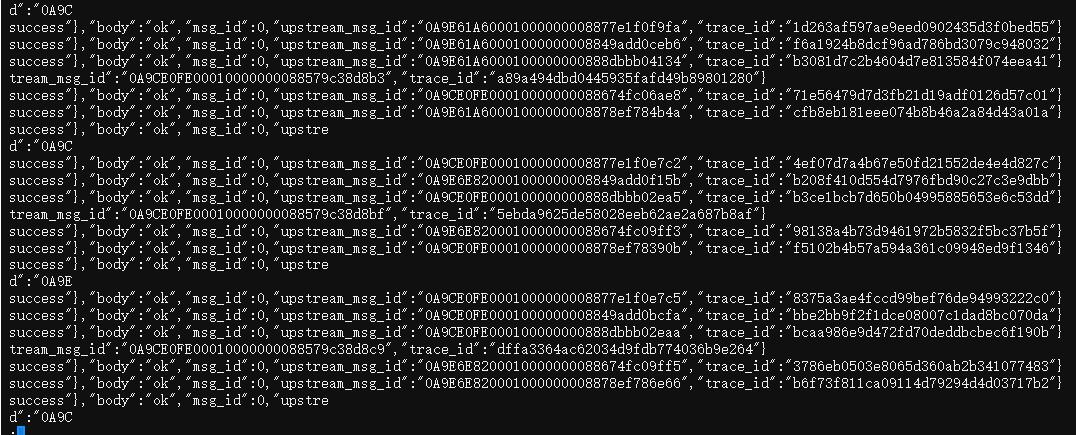
通過檢視各個可疑記憶體段,發現有不少類似我們一自研訊息佇列的響應格式資料,通過與訊息佇列團隊合作,找到了相關的訊息topic,並最終與相關研發確認了此topic訊息最近剛遷移到此服務中。
4. 檢查發http請求程式碼
由於傳送訊息是走http介面,故我在工程中搜尋呼叫http介面的相關程式碼,發現一處程式碼中建立的流物件沒有關閉,而GZIPInputStream這個類剛好會直接分配到native記憶體。
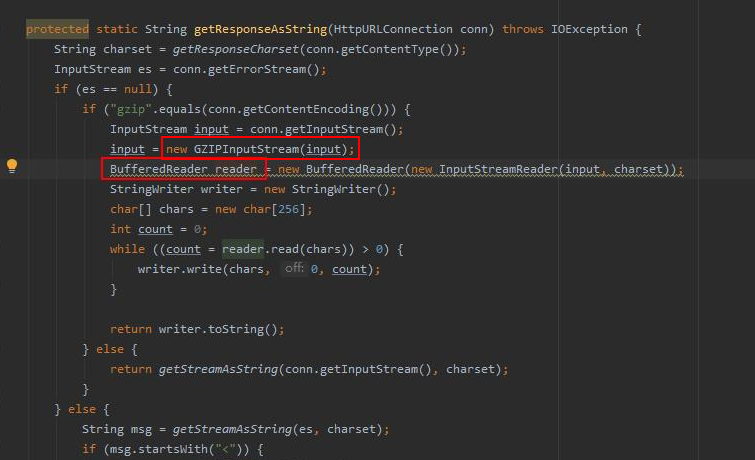
其它方法
本次問題,通過檢查記憶體中的資料找到了問題,還是有些碰運氣的。這需要記憶體中剛好有一些非常有代表性的字串,因為非字串的二進位制資料,基本無法分析。
如果檢視記憶體資料無法找到關鍵線索,還可嘗試以下幾個方法:
5. 開啟JVM的NMT原生記憶體追蹤功能
新增JVM引數-XX:NativeMemoryTracking=detail開啟,使用jcmd檢視,如下:
jcmd 1 VM.native_memory
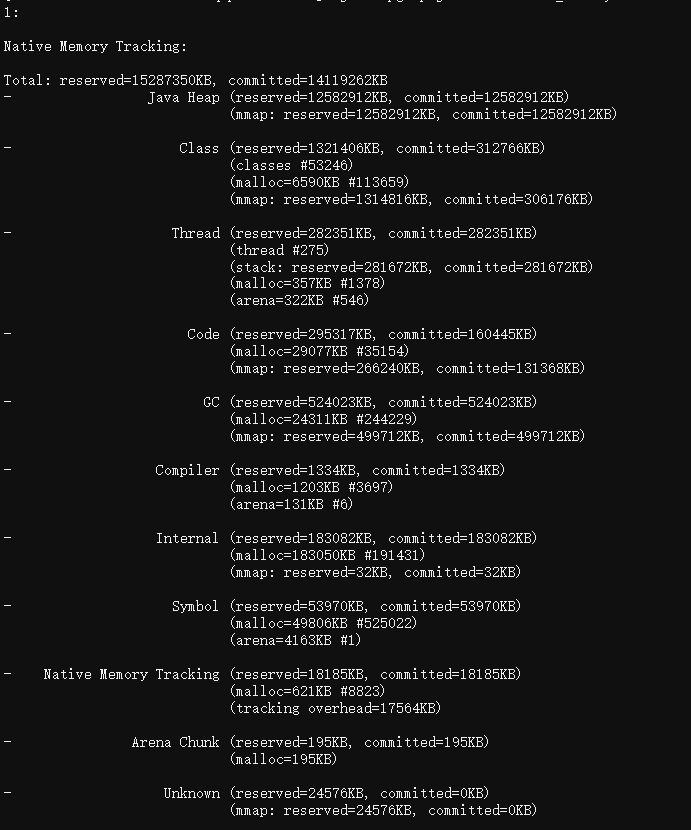
NMT只能觀察到JVM管理的記憶體,像通過JNI機制直接呼叫malloc分配的記憶體,則感知不到。
6. 檢查被glibc記憶體分配器快取的記憶體
JVM等原生應用程式呼叫的malloc、free函數,實際是由基礎C庫libc提供的,而linux系統則提供了brk、mmap、munmap這幾個系統呼叫來分配虛擬記憶體,所以libc的malloc、free函數實際是基於這些系統呼叫實現的。
由於系統呼叫有一定的開銷,為減小開銷,libc實現了一個類似記憶體池的機制,在free函數呼叫時將記憶體塊快取起來不歸還給linux,直到快取記憶體量到達一定條件才會實際執行歸還記憶體的系統呼叫。
所以程序佔用記憶體比理論上要大些,一定程度上是正常的。
malloc_stats函數
通過如下命令,可以確認glibc庫快取的記憶體量,如下:
# 檢視glibc記憶體分配情況,會輸出到程序標準錯誤中
gdb -q -batch -ex 'call malloc_stats()' -p 1
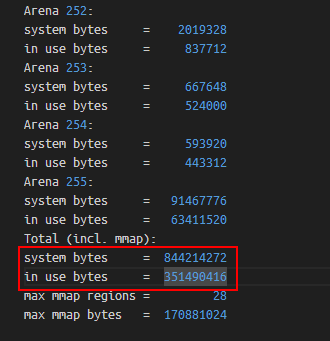
如上,Total (incl. mmap)表示glibc分配的總體情況(包含mmap分配的部分),其中system bytes表示glibc從作業系統中申請的虛擬記憶體總大小,in use bytes表示JVM正在使用的記憶體總大小(即呼叫glibc的malloc函數後且沒有free的記憶體)。
可以發現,glibc快取了快500m的記憶體。
注:當我對jvm程序中執行malloc_stats後,我發現它顯示的in use bytes要少得多,經過檢查JVM程式碼,發現JVM在為Java Heap、Metaspace分配記憶體時,是直接通過mmap函數分配的,而這個函數是直接封裝的mmap系統呼叫,不走glibc記憶體分配器,故in use bytes會小很多。
malloc_trim函數
glibc實現了malloc_trim函數,通過brk或madvise系統呼叫,歸還被glibc快取的記憶體,如下:
# 回收glibc快取的記憶體
gdb -q -batch -ex 'call malloc_trim(0)' -p 1


可以發現,執行malloc_trim後,RSS減少了約250m記憶體,可見記憶體佔用高並不是因為glibc快取了記憶體。
注:通過gdb呼叫C函數,會有一定概率造成jvm程序崩潰,需謹慎執行。
7. 使用tcmalloc或jemalloc的記憶體洩露檢測工具
glibc的預設記憶體分配器為ptmalloc2,但Linux提供了LD_PRELOAD機制,使得我們可以更換為其它的記憶體分配器,如業內比較成熟的tcmalloc或jemalloc。
這兩個記憶體分配器除了實現了記憶體分配功能外,還提供了記憶體洩露檢測的能力,它們通過hook程序的malloc、free函數呼叫,然後找到那些呼叫了malloc後一直沒有free的地方,那麼這些地方就可能是記憶體洩露點。
HEAPPROFILE=./heap.log
HEAP_PROFILE_ALLOCATION_INTERVAL=104857600
LD_PRELOAD=./libtcmalloc_and_profiler.so
java -jar xxx ...
pprof --pdf /path/to/java heap.log.xx.heap > test.pdf
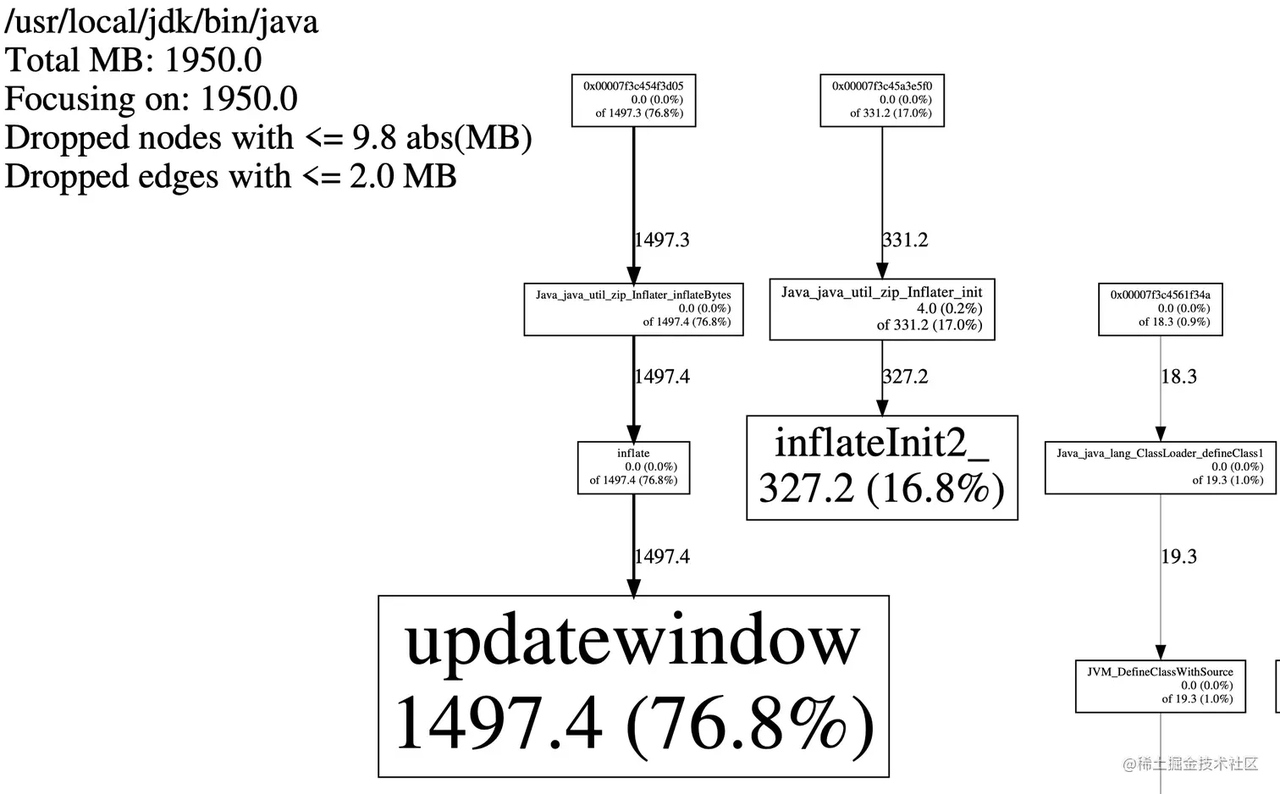
tcmalloc下載地址:https://github.com/gperftools/gperftools
如上,可以發現記憶體洩露點來自Inflater物件的init和inflateBytes方法,而這些方法是通過JNI呼叫實現的,它會申請native記憶體,經過檢查程式碼,發現GZIPInputStream確實會建立並使用Inflater物件,如下:

而它的close方法,會呼叫Inflater的end方法來歸還native記憶體,由於我們沒有呼叫close方法,故相關聯的native記憶體無法歸還。
可以發現,tcmalloc的洩露檢測只能看到native棧,如想看到Java棧,可考慮配合使用arthas的profile命令,如下:
# 獲取呼叫inflateBytes時的呼叫棧
profiler execute 'start,event=Java_java_util_zip_Inflater_inflateBytes,alluser'
# 獲取呼叫malloc時的呼叫棧
profiler execute 'start,event=malloc,alluser'
如果程式碼不修復,記憶體會一直漲嗎?
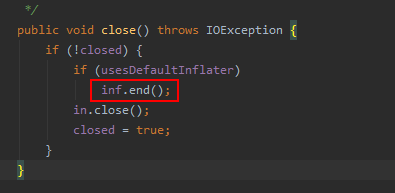
經過檢視程式碼,發現Inflater實現了finalize方法,而finalize方法呼叫了end方法。
也就是說,若GC時Inflater物件被回收,相關聯的原生記憶體是會被free的,所以記憶體會一直漲下去導致程序被oom kill嗎?maybe,這取決於GC觸發的閾值,即在GC觸發前JVM中會保留的垃圾Inflater物件數量,保留得越多native記憶體佔用越大。
但我發現一個有趣現象,我通過jcmd強行觸發了一次Full GC,如下:
jcmd 1 GC.run
理論上native記憶體應該會free,但我通過top觀察程序rss,發現基本沒有變化,但我檢查malloc_stats的輸出,發現in use bytes確實少了許多,這說明Full GC後,JVM確實歸還了Inflater物件關聯的原生記憶體,但它們都被glibc快取起來了,並沒有歸還給作業系統。
於是我再執行了一次malloc_trim,強制glibc歸還快取的記憶體,發現程序的rss降了下來。
編碼最佳實踐
這個問題是由於InputStream流物件未關閉導致的,在Java中流物件(FileInputStream)、網路連線物件(Socket)一般都關聯了原生資源,記得在finally中呼叫close方法歸還原生資源。
而GZIPInputstream、Inflater是JVM堆外記憶體洩露的常見問題點,review程式碼發現有使用這些類時,需要保持警惕。
JVM記憶體常見疑問
為什麼我設定了-Xmx為10G,top中看到的rss卻大於10G?
根據上面的介紹,JVM記憶體佔用分佈大概如下:
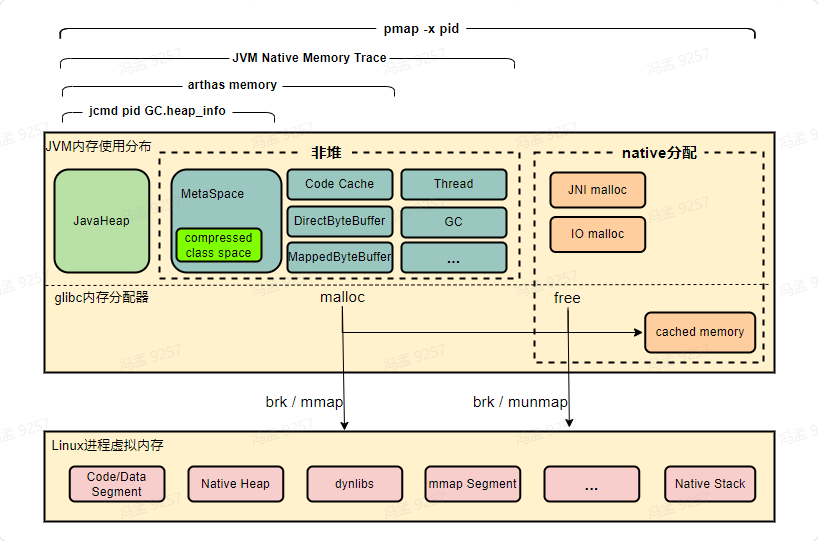
可以發現,JVM記憶體佔用主要包含如下部分:
- Java堆,-Xmx選項限制的就是Java堆的大小,可通過jcmd命令觀測。
- Java非堆,包含Metaspace、Code Cache、直接記憶體(DirectByteBuffer、MappedByteBuffer)、Thread、GC,它可通過arthas memory命令或NMT原生記憶體追蹤觀測。
- native分配記憶體,即直接呼叫malloc分配的,如JNI呼叫、磁碟與網路io操作等,可通過pmap命令、malloc_stats函數觀測,或使用tcmalloc檢測洩露點。
- glibc快取的記憶體,即JVM呼叫free後,glibc庫快取下來未歸還給作業系統的部分,可通過pmap命令、malloc_stats函數觀測。
所以-Xmx的值,一定要小於容器/物理機的記憶體限制,根據經驗,一般設定為容器/物理機記憶體的65%左右較為安全,可考慮使用比例的方式代替-Xms與-Xmx,如下:
-XX:MaxRAMPercentage=65.0 -XX:InitialRAMPercentage=65.0 -XX:MinRAMPercentage=65.0
top中VIRT與RES是什麼區別?
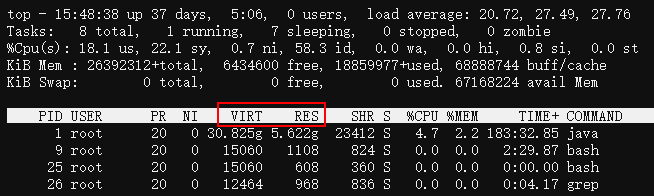
- VIRT:程序申請的虛擬記憶體總大小。
- RES:程序在讀寫它申請的虛擬記憶體頁面後,會觸發Linux的記憶體缺頁中斷,進而導致Linux為該頁分配實際記憶體,即RSS,在top中叫RES。
- SHR:程序間共用的記憶體,如libc.so這個C動態庫,幾乎會被所有程序載入到各自的虛擬記憶體空間並使用,但Linux實際只分配了一份記憶體,各個程序只是通過記憶體頁表關聯到此記憶體而已,注意,RSS指標一般也包含SHR。
通過top、ps或pidstat可查詢程序的缺頁中斷次數,如下:
top中可以通過f互動指令,將mMin、mMaj列顯示出來。
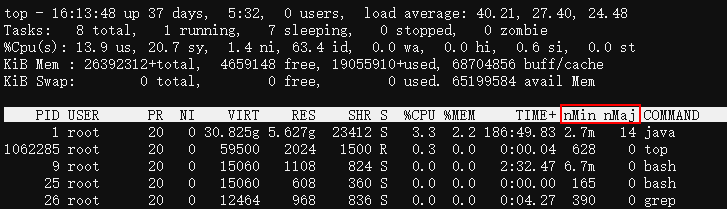

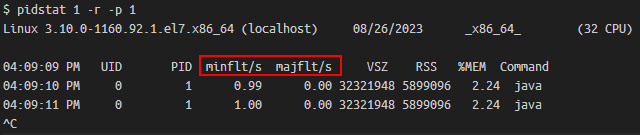
minflt表示輕微缺頁,即Linux分配了一個記憶體頁給程序,而majflt表示主要缺頁,即Linux除了要分配記憶體頁外,還需要從磁碟中讀取資料到記憶體頁,一般是記憶體swap到了磁碟後再存取,或使用了記憶體對映技術讀取檔案。
為什麼top中JVM程序的VIRT列(虛擬記憶體)那麼大?
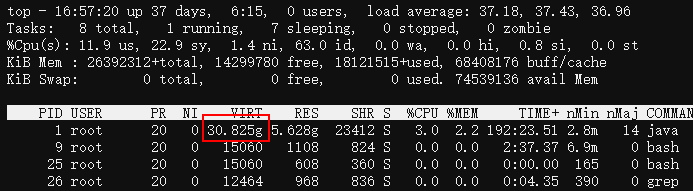
可以看到,我們一Java服務,申請了約30G的虛擬記憶體,比RES實際記憶體5.6G大很多。
這是因為glibc為了解決多執行緒記憶體申請時的鎖競爭問題,建立了多個記憶體分配區Arena,然後每個Arena都有一把鎖,特定的執行緒會hash到特定的Arena中去競爭鎖並申請記憶體,從而減少鎖開銷。
但在64位元系統裡,每個Arena去系統申請虛擬記憶體的單位是64M,然後按需拆分為小塊分配給申請方,所以哪怕執行緒在此Arena中只申請了1K記憶體,glibc也會為此Arena申請64M。
64位元系統裡glibc建立Arena數量的預設值為CPU核心數的8倍,而我們容器執行在32核的機器,故glibc會建立32*8=256個Arena,如果每個Arena最少申請64M虛擬記憶體的話,總共申請的虛擬記憶體為256*64M=16G。

然後JVM是直接通過mmap申請的堆、MetaSpace等記憶體區域,不走glibc的記憶體分配器,這些加起來大約14G,與走glibc申請的16G虛擬記憶體加起來,總共申請虛擬記憶體30G!
當然,不必驚慌,這些只是虛擬記憶體而已,它們多一些並沒有什麼影響,畢竟64位元程序的虛擬記憶體空間有2^48位元組那麼大!
為什麼jvm啟動後一段時間內記憶體佔用越來越多,存在記憶體洩露嗎?
如下,是我們一服務重啟後執行快2天的記憶體佔用情況,可以發現記憶體一直從45%漲到了62%,8G的容器,上漲記憶體大小為1.36G!
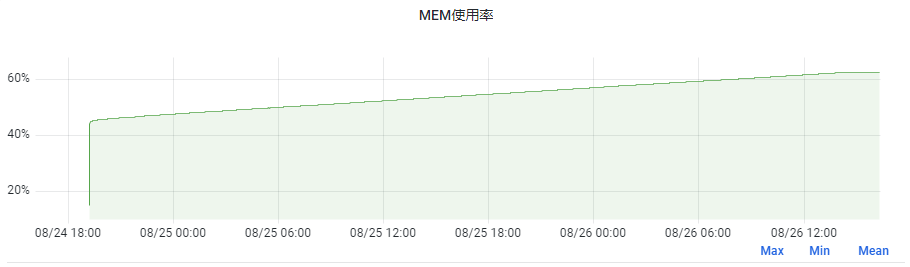
但我們這個服務其實沒有記憶體洩露問題,因為JVM為堆申請的記憶體是虛擬記憶體,如4.8G,但在啟動後JVM一開始可能實際只使用了3G記憶體,導致Linux實際只分配了3G。
然後在gc時,由於會複製存活物件到堆的空閒部分,如果正好複製到了以前未使用過的區域,就又會觸發Linux進行記憶體分配,故一段時間內記憶體佔用會越來越多,直到堆的所有區域都被touch到。
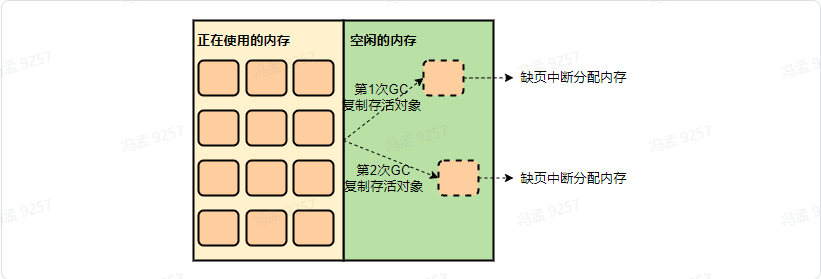
而通過新增JVM引數-XX:+AlwaysPreTouch,可以讓JVM為堆申請虛擬記憶體後,立即把堆全部touch一遍,使得堆區域全都被分配實體記憶體,而由於Java程序主要活動在堆內,故後續記憶體就不會有很大變化了,我們另一服務新增了此引數,記憶體表現如下:
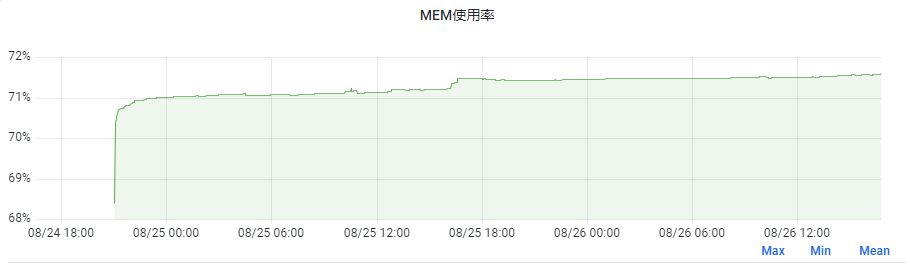
可以看到,記憶體上漲幅度不到2%,無此引數可以提高記憶體利用度,加此引數則會使應用執行得更穩定。
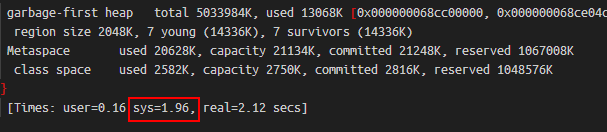
如我們之前一服務一週內會有1到2次GC耗時超過2s,當我新增此引數後,再未出現過此情況。這是因為當無此引數時,若GC存取到了未讀寫區域,會觸發Linux分配記憶體,大多數情況下此過程很快,但有極少數情況下會較慢,在GC紀錄檔中則表現為sys耗時較高。
參考文章
https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/
https://juejin.cn/post/7078624931826794503
https://juejin.cn/post/6903363887496691719